LookeはBIではない ?
「Lookerはデータプラットフォームです」みたいな話はアチコチで聞くがいまいちよくわからん。
プラットフォーム、、、プラットフォームってなんだろう? 謎。
しかし巷ではLookerはシリコンバレー発の新しいコンセプトのクールなデータプラットフォーム(??)という噂である。謎を解明する為、実際に使ってみようと思い理由を考えて仕事で使ってみる。
色々と触ってわかった事。
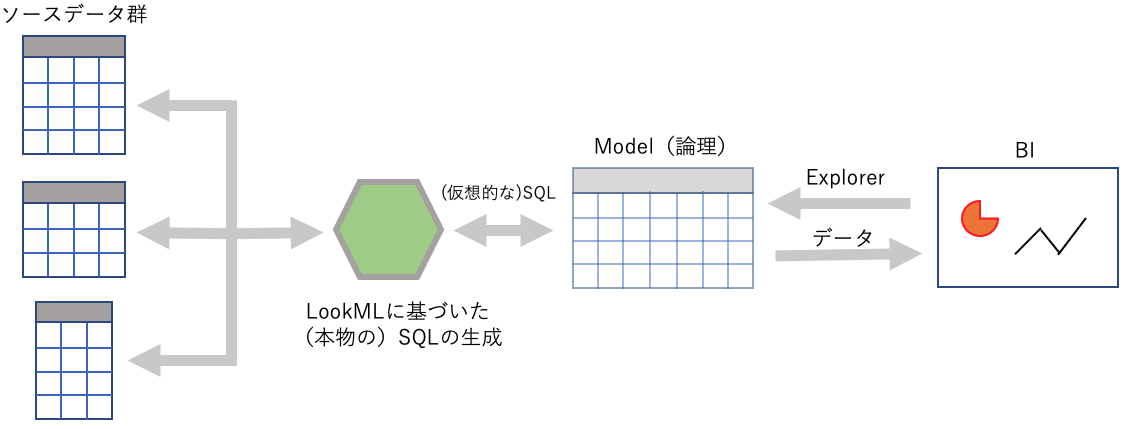
「Model」は大きな仮想テーブル
Lookerの世界ではLookMLというDSLを書いて「Model」と呼ばれる論理構造を構築できる。
LookMLは、データベース上のたくさんのテーブルを全部結合して、集計の定義をたくさん書く感じ、なんというか、巨大なSQLをバラして書く感じだ。
Modelというのは「一つの巨大な情報全部入りの非正規化テーブル」みたいなものだ。これがLookMLによって論理的に(viewの感じに似てる)定義される。
Exploreは仮想SQL(造語だ)を操作するGUI
このModelを操作するのがExploreというLookerのキラー・アプリである。
Exploreはディメンションという集計キー/軸/単位と、メジャーと呼ばれる集計値/項目、を選択したり、フィルタを設定する事で先ほどのModel(仮想テーブル)からデータを取得できる。
ディメンションはGroupingに、メジャーは集計関数に、フィルタはWhereに、、といった具合に__Exploreの操作は単純なSQLに喩えて考える事が可能__であり、これは仮想的なSQLとして考える事ができる。
仮想的なSQLを仮想的なテーブルに発射して集計処理を簡略化しよう、というのがLookerの世界だ。
ちなみに、ExploreだけでなくAPI(SQLに似たセマンティクスを持つ)でもModelを操作できる。このあたりの設計思想に「プラットフォーム」感がある。
Lookerの正体は動的ビュー管理システム+BI(Lookerは単なるBIツールではない!!)
ところで、これらは全部仮想的なもので、実際に行われている事は仮想SQL(つまりExploreの操作)をLookMLの定義によって複雑なSQLに変換し実行する事である。
必要なテーブル、必要な結合、必要な計算は「仮想的SQL」の内容によりLookerのランタイムにより動的に決まる。これは動的ビュー(造語その2)みたいなもので、Lookerを処理系として見ると「SQLをSQLに変換するもの」そのように見える。
DWH今昔物語
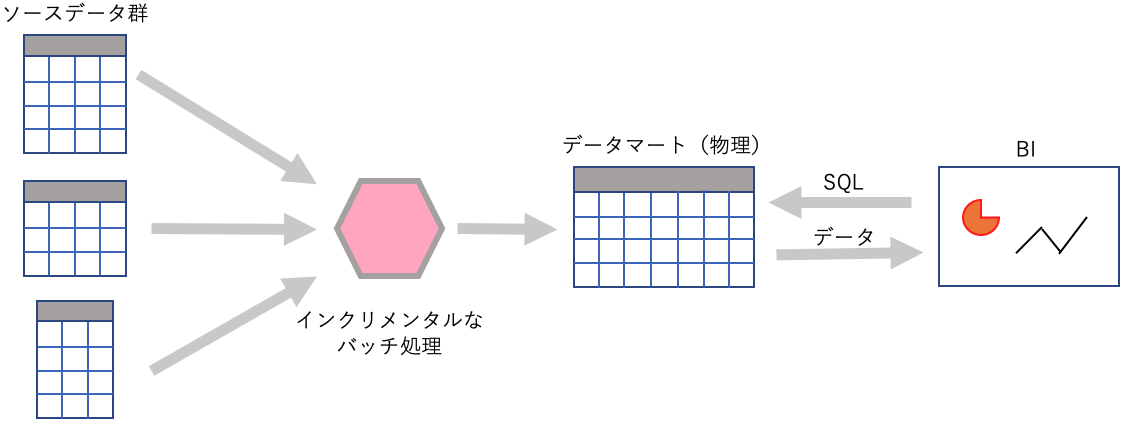
たくさんのテーブルデータを非正規化して巨大なテーブルにしたものをデータマートと呼んだ時代があった。
データマートはディメンションの主要な組み合わせ毎に作成される事が多く、これは計算時間を短くする為の工夫だった。
昔は巨大なバッチ処理を一晩中サーバーでグルグルと回して実際にデータを実際に加工(それでもその日のデータを処理するのがやっとだった)してた。そのように作られ日々累積していくデータマートの管理は慎重に恭しく行われた。LookerはこれをSQLの変換だけで、あくまで論理的・仮想的に行う。1
昔は事前に計算しないと無理だったのが、分散技術の進歩で計算能力が上がった為に事前計算の必要が無くなった、という見方もできる。(このあたり関数型言語っぽい雰囲気、、、lazyナントカ、、、を感じる)
太古(データマートという物理の時代)
現代(Lookerによる仮想Model)
データが無いと気軽にぽんぽんデプロイできるようになる
Lookerは(概念的には)データを持たないので__デプロイのコストは0に等しい__。(超重要)
昔は分析系のバックエンド処理プログラムのリリースというのは「行事」であった。集計項目を一つ追加するだけで数ヶ月かかった気がする。
ガントチャート、冪等性、ワークフロー、再計算、不整合の解消、部分的再実行、リカバリ、バックアップ、プログラムのコピー、エラー処理、入念なテスト、早朝リリース、居酒屋で打ち上げ、、、みたいな。これを数人のチームでやってた。
Lookerはデータを持たないのでデプロイのコストは数千分の一(主観による)になった。ボタンを押すだけだ。__特に考えなくぽんぽんとリリース__できるのは本当にありがたい。便利な世の中になったな〜と思う。
-
実際にはPDTと呼ばれる中間集計データを使う事も多いが、管理の仕組みが面白く、存在をあまり感じさせない?設計になっている。 ↩