スキャンされたPDFファイルや画像は、通常、テキストが画像形式で保存されているため、そのままでは編集や検索ができません。この問題を解決するために、OCR(光学文字認識)技術が開発されました。OCRは画像内のテキスト領域を解析し、それを編集可能なテキストに変換することにより、情報の抽出を容易にします。現在、OCRは文書のデジタル化、データ抽出、テキスト検索など、さまざまな業界で広く活用されています。
この記事では、JavaでOCRを使用して画像やスキャンされたPDFのテキストを認識するソリューションを紹介します。
ツールとセットアップ
JavaでOCRを実行するには、適切なOCRライブラリが必要です。この記事では、Spire.OCR for Javaを使用します。このライブラリを使用する前に、以下の2つの手順を完了する必要があります。
-
ライブラリのJARファイルをプロジェクトにインポートする
公式サイトからJARファイルをダウンロードするか、以下のコードをpom.xmlファイルに追加してMavenを通じてインストールします:
<repositories> <repository> <id>com.e-iceblue</id> <name>e-iceblue</name> <url>https://repo.e-iceblue.com/nexus/content/groups/public/</url> </repository> </repositories> <dependency> <groupId>e-iceblue</groupId> <artifactId>spire.ocr</artifactId> <version>1.9.19</version> </dependency> -
Spire.OCR for Javaのモデルをダウンロードする
Spire.OCR for Javaは、Windows(64ビット)およびLinux(64ビット)システム用の事前学習済みモデルを提供しています。使用しているオペレーティングシステムに応じて適切なモデルをダウンロードし、解凍して特定のディレクトリに保存してください。
これらの手順を完了すると、Spire.OCRを使用して画像やスキャンされたPDFのテキストを認識する準備が整います。
Javaで画像のテキストを認識する方法
画像からテキストを抽出する手順は以下のとおりです:
- OcrScannerクラスのインスタンスを作成する
- ConfigureOptionsクラスのインスタンスを作成する
- ConfigureOptions.setLanguage()メソッドを使用してテキスト認識の言語を指定する。サポートされている言語には、英語、日本語、中国語、フランス語、ドイツ語、韓国語があります
- ConfigureOptions.setModelPath()メソッドでOCRモデルのパスを設定する
- OcrScanner.ConfigureDependencies()を使って設定を適用する
- OcrScanner.scan()メソッドを使用して画像からテキストを認識する
- OcrScanner.getText()メソッドを使って認識されたテキストを取得する
- 認識したテキストをテキストファイルに保存する
以下のコード例は、Javaで画像からテキストを抽出する方法を示しています:
import com.spire.ocr.ConfigureOptions;
import com.spire.ocr.OcrException;
import com.spire.ocr.OcrScanner;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractTextFromImage {
public static void main(String[] args) {
// ライセンスキーを適用してください(こちらのリンクからリクエストできます: https://www.e-iceblue.com/TemLicense.html)
com.spire.ocr.license.LicenseProvider.setLicenseKey("ライセンスキー");
// 画像からテキストを認識
String scannedText = scanTextFromImage("テスト.png", "Japan", "E:\\win-x64");
// 認識したテキストをファイルに保存
saveTextToFile(scannedText, "画像.txt");
}
/**
* メソッド:画像からテキストを認識
* @param imagePath 画像パス
* @param language OCR言語(英語、中国語、繁体字中国語、フランス語、ドイツ語、日本語、韓国語などがサポートされています)
* @param modelPath OCRモデルパス
* @return 認識されたテキスト
*/
private static String scanTextFromImage(String imagePath, String language, String modelPath) {
try {
// OcrScannerクラスのオブジェクトを作成
OcrScanner scanner = new OcrScanner();
// スキャナー設定を行う
ConfigureOptions configureOptions = new ConfigureOptions();
// テキスト認識に使用する言語を指定
configureOptions.setLanguage(language);
// モデルのパスを指定
configureOptions.setModelPath(modelPath);
// 設定をスキャナーに適用
scanner.ConfigureDependencies(configureOptions);
// 画像からテキストを認識
scanner.scan(imagePath);
// 認識されたテキストを取得
return scanner.getText().toString();
} catch (OcrException e) {
System.out.println("OCR 認識中にエラーが発生しました。");
e.printStackTrace();
return "";
}
}
/**
* メソッド:認識されたテキストをファイルに保存
* @param text 認識されたテキスト
* @param filePath 保存するファイルのパス
*/
private static void saveTextToFile(String text, String filePath) {
// 取得したテキストをテキストファイルに書き込む
try (FileWriter writer = new FileWriter(filePath)) {
writer.write(text);
System.out.println("テキストが正常に " + filePath + " に保存されました");
} catch (IOException e) {
System.out.println("テキストファイルの保存中にエラーが発生しました。");
e.printStackTrace();
}
}
}
以下は、元の画像と認識結果です:
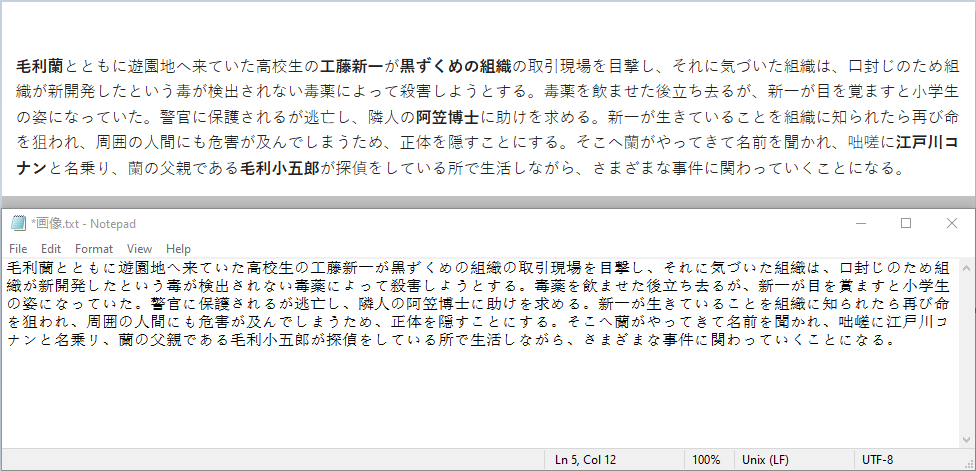
JavaでスキャンされたPDFのテキストを認識する方法
Spire.OCR for Javaは直接PDFを処理しないため、スキャンされたPDFドキュメントを画像に変換する必要があります。このタスクでは、シームレスなPDFから画像への変換を提供するSpire.PDF for Javaライブラリを使用します。画像が生成された後、Spire.OCRを使用してテキストを抽出することができます。
公式サイトからSpire.PDFをダウンロードするか、以下のコードを追加してMavenを通じてインストールします:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.10.7</version>
</dependency>
</dependencies>
以下のコード例は、JavaでスキャンされたPDFからテキストを抽出する方法を示しています:
import com.spire.ocr.ConfigureOptions;
import com.spire.ocr.OCRImageFormat;
import com.spire.ocr.OcrException;
import com.spire.ocr.OcrScanner;
import com.spire.pdf.PdfDocument;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.*;
public class ExtractTextFromScannedPDF {
public static void main(String[] args) throws OcrException {
// ライセンスキーを適用してください(こちらのリンクからリクエストできます: https://www.e-iceblue.com/TemLicense.html)
com.spire.ocr.license.LicenseProvider.setLicenseKey("ライセンスキー");
com.spire.pdf.license.LicenseProvider.setLicenseKey("ライセンスキー");
// スキャンしたPDF文書を開く
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("テスト.pdf");
// FileWriterを作成し、追加モードで開く
try (FileWriter writer = new FileWriter("スキャンPDF.txt", true)) {
// スキャンしたPDF文書からテキストを認識し、結果をテキストファイルに保存
for (int pageIndex = 0; pageIndex < pdf.getPages().getCount(); pageIndex++) {
BufferedImage image = convertPdfPageToImage(pdf, pageIndex);
String scannedText = recognizeTextFromImage(image, "Japan", "E:\\win-x64");
// 認識したテキストをファイルに保存(追加モード)
writer.write("ページ " + (pageIndex + 1) + ":\n");
writer.write(scannedText);
writer.write("\n\n"); // 各ページの内容の間に改行を2つ挿入
}
System.out.println("テキストが「スキャンPDF.txt」に正常に保存されました");
} catch (IOException e) {
System.out.println("テキストファイルの保存中にエラーが発生しました。");
e.printStackTrace();
}
}
/**
* メソッド:PDFページを画像に変換
* @param pdf PDF文書オブジェクト
* @param pageIndex ページ番号インデックス(0から始まる)
* @return 変換されたBufferedImageオブジェクト
* @throws IOException 変換中にI/Oエラーが発生した場合
*/
private static BufferedImage convertPdfPageToImage(PdfDocument pdf, int pageIndex) throws IOException {
return pdf.saveAsImage(pageIndex);
}
/**
* メソッド:画像からテキストを認識
* @param image 認識するBufferedImageオブジェクト
* @param language OCR言語(英語、中国語、繁体字中国語、フランス語、ドイツ語、日本語、韓国語などがサポートされています)
* @param modelPath OCRモデルのパス
* @return 認識されたテキスト
* @throws OcrException OCR認識中にエラーが発生した場合
* @throws IOException BufferedImageをInputStreamに変換する際にI/Oエラーが発生した場合
*/
private static String recognizeTextFromImage(BufferedImage image, String language, String modelPath) throws OcrException, IOException {
// BufferedImageをInputStreamに変換
ByteArrayOutputStream os = new ByteArrayOutputStream();
ImageIO.write(image, "PNG", os);
InputStream inputStream = new ByteArrayInputStream(os.toByteArray());
// OCRスキャナを設定して初期化
OcrScanner scanner = new OcrScanner();
ConfigureOptions configureOptions = new ConfigureOptions();
configureOptions.setLanguage(language); // OCRの言語設定
configureOptions.setModelPath(modelPath); // OCRモデルのパス設定
scanner.ConfigureDependencies(configureOptions); // 設定を適用
// テキストを認識
scanner.Scan(inputStream, OCRImageFormat.Png);
return scanner.getText().toString(); // 認識されたテキストを返す
}
}
以下は、元のPDFと認識結果です:
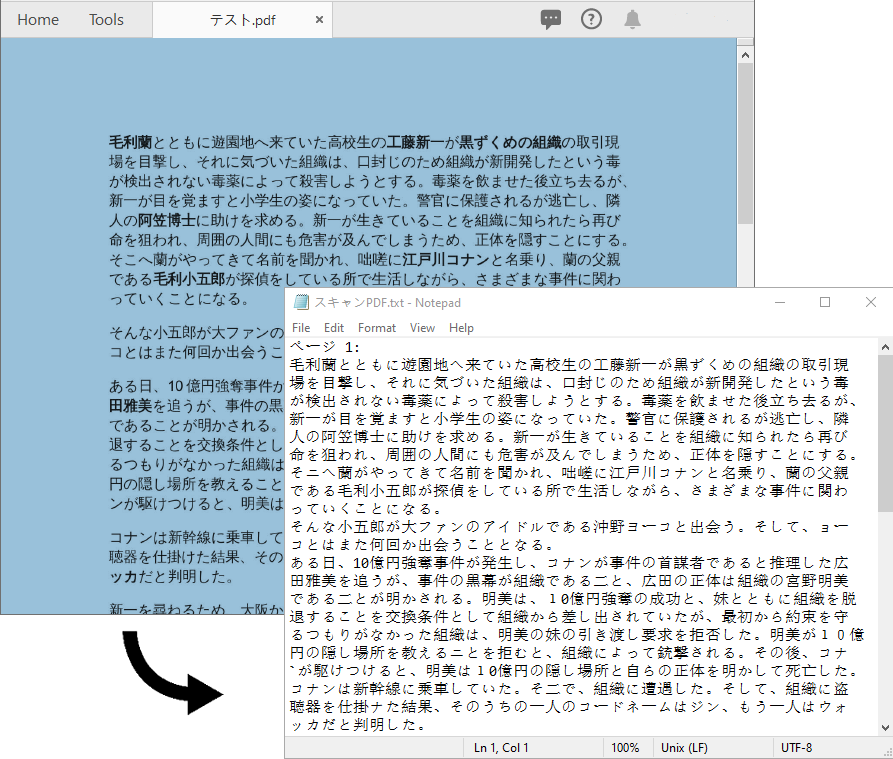
補足
OCRの精度は、画像の品質によって大きく影響されます。鮮明で高コントラストな、ぼやけや歪みのない画像を使用すると、認識精度が向上します。さらに、認識精度を最適化するために、正しい言語パラメータを選択することも重要です。