はじめに
こんにちは。Hironsanです。
3月から4月にかけてLine, Facebook, Microsoftと各社がBot開発用プラットフォームを発表して以来、爆発的な数のBotが登場しています。実にFacebook Messengerだけに限っても2016年7月時点で1万1000超のBotが稼働しています。
しかし、これらのBotのほとんどは単純な一問一答型のシステムであり、対話システムと言えるものではありません。これでは徐々にユーザの嗜好を聞き出すような対応を行うことはできません。
そこで今回は、対話の履歴を考慮したレストラン検索対話システムを作り、最終的にはBotに組み込んでみたいと思います。完成イメージとしては以下のアニメーションのようなものを作ることができます。
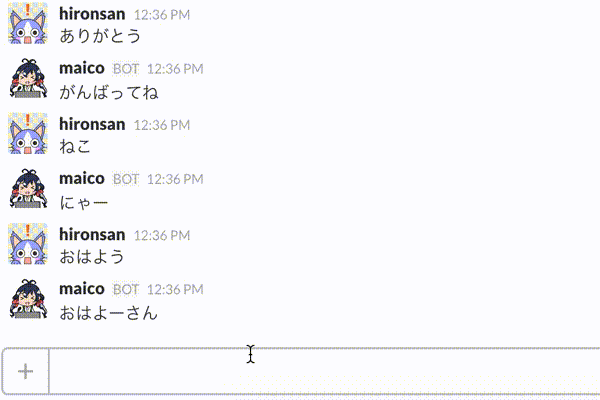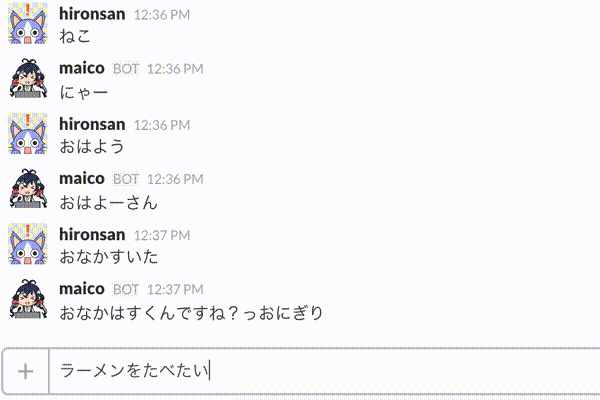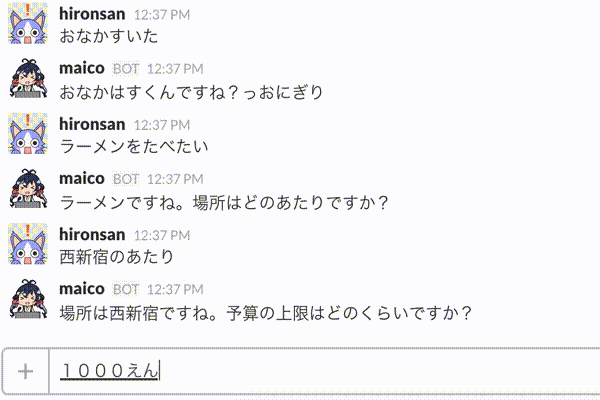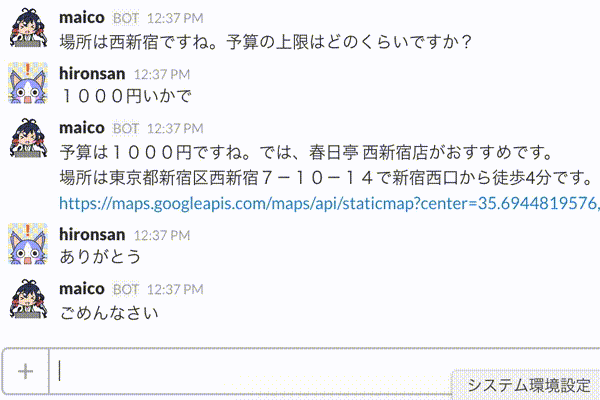
具体的には以下のステップで作成します。
- 簡単なパターンマッチ
- おうむ返し
- 対話状態を保持したレストラン検索対話システム
また、レストラン検索だけでなく雑談も行うことができます。これらのBotの作成を通じて、基本的な対話システムの作成方法について理解することを目的とします。
対象読者
- Pythonの基礎的な文法を理解している人
- 対話システムを作ってみたい人
- 対話システムの資料を読んだ人
準備
Python環境の構築
今回作る対話システムはPython3系を用いて構築します。そのため公式サイトからPython3系をダウンロード後、インストールしてください。
ハンズオン用リポジトリのClone
今からハンズオン用リポジトリを用意します。以下の手順に従って用意してください。
- https://github.com/Hironsan/HotPepperGourmetDialogue
- 右上にある「fork」というボタンから、本リポジトリをfork(=コピー)してください。
- forkしたリポジトリを、git cloneによって手元の端末に取ってきてブランチを切り替えます。これで準備は完了です。
$ git clone YOUR_FORK_REPOSITORY.git
$ cd HotPepperGourmetDialogue
$ git checkout -b tutorial origin/tutorial
さらに、モジュールのimportのために、HotPepperGourmetDialogueディレクトリ直下でPYTHONPATHを設定してください。ダブルクオテーション""はつけないでください。
$ export PYTHONPATH=`pwd`
コマンドプロンプト環境の場合は以下を実行してください。
$ set PYTHONPATH=%CD%
仮想環境の構築
Virtualenvの場合
Virtualenvの場合、以下のコマンドを実行して仮想環境を構築し、有効にします。
$ pip install virtualenv
$ virtualenv env
$ source env/bin/activate
Condaの場合
Condaの場合、以下のコマンドを実行して仮想環境を構築し、有効にします。
$ conda create -n env python
$ source activate env # コマンドプロンプトの場合 activate env
API Keyの取得
レストラン検索対話システムの中で使用するため、以下の2つのAPI Keyを取得してください。
docomo雑談対話APIはBotと雑談を行うために使用し、HotPepperグルメーサーチAPIはレストラン検索を行うために使用します。取得時間の目安は、HotPepperのAPI Keyは5分程度、docomo雑談対話APIは1日程度かかります。
取得するまでの間は、おうむ返しBotの作成まで進めておいてください。
Slackアカウントの作成
今回はSlack上にBotを作成していきます。そのためSlackアカウントを持っていなかったら以下から作成してください。
https://slack.com/
チーム名などはよしなに設定してください。
Slack Botアカウントの作成
まずはSlack Botアカウントを作成しましょう。
https://my.slack.com/services/new/bot
既にチームのSlackは開設済で、権限のあるユーザでログインしているものとします。その状態で、上記リンクを開くと、Botアカウントの作成画面が開きます。表示されているフォーム中にBotアカウントのユーザ名を入力して、「Add bot integration」を押してください。
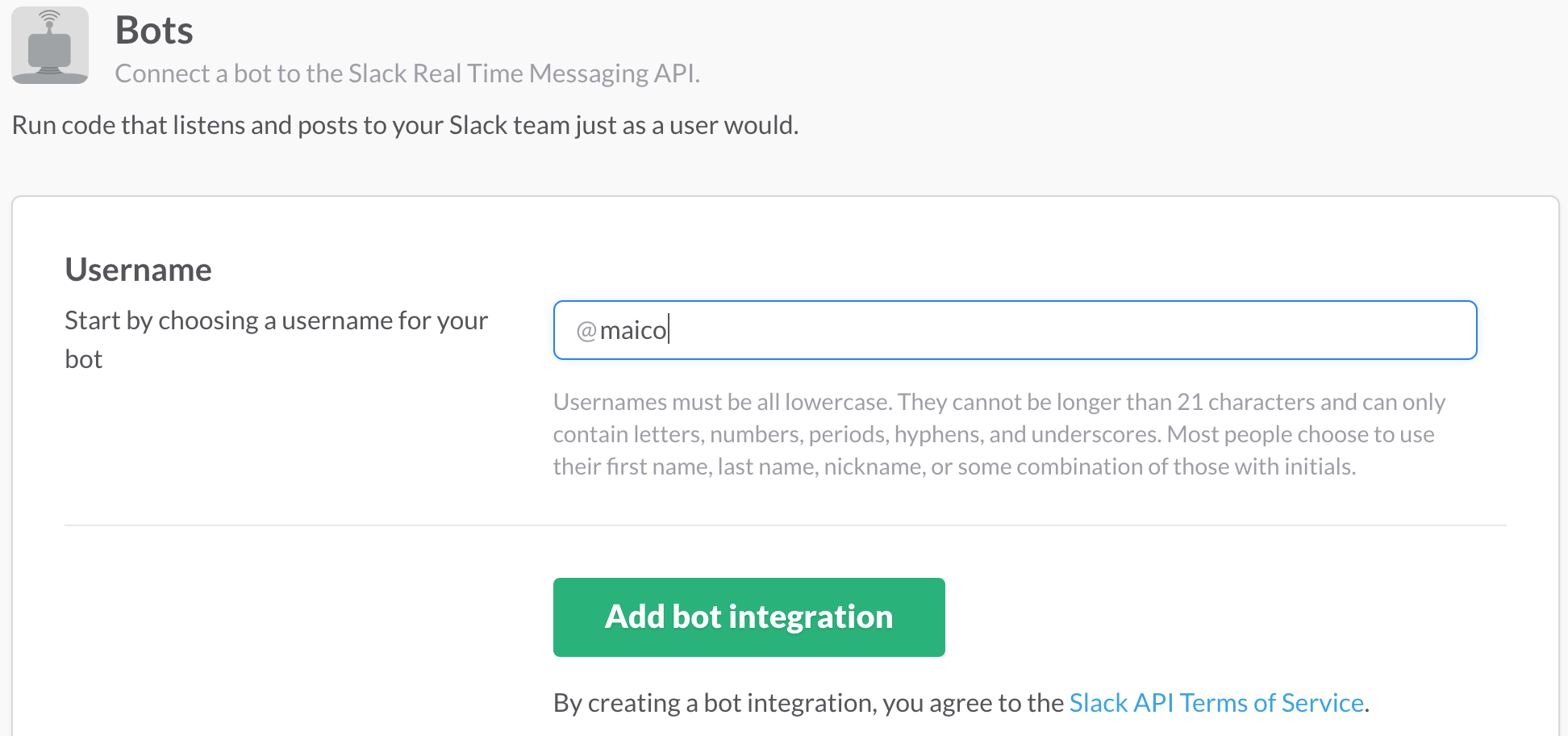
「Add bot integration」を押すと、新たにフォームが表示されます。その中の「API Token」は後で作成するBotで用いるのでメモしてください。
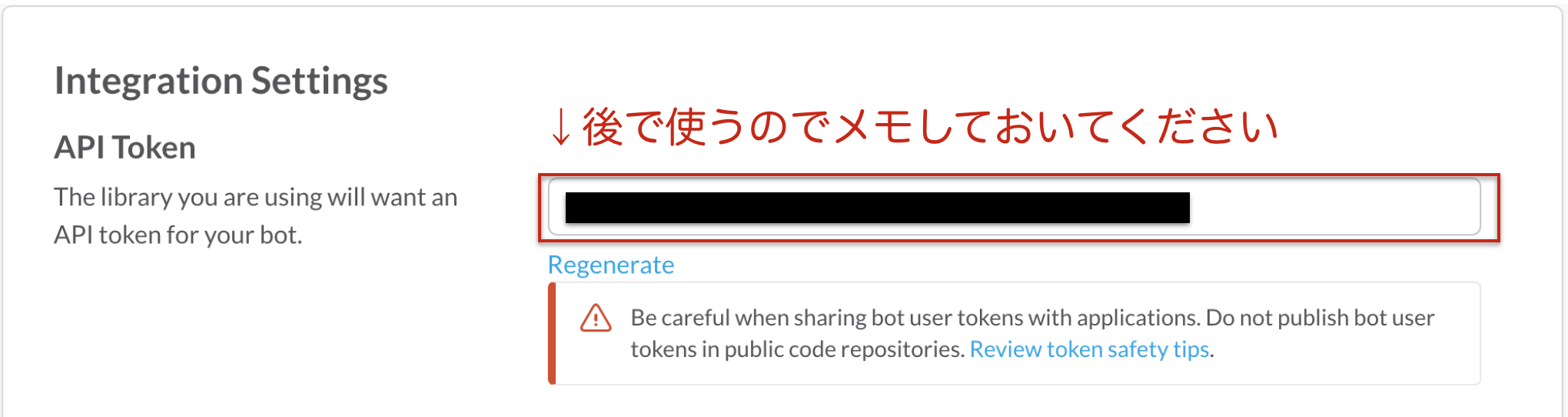
「Customize Icon」や「Customize Name」で作成したBotの名前やアイコン画像を変更できます。変更内容を「Save Integration」で保存します。
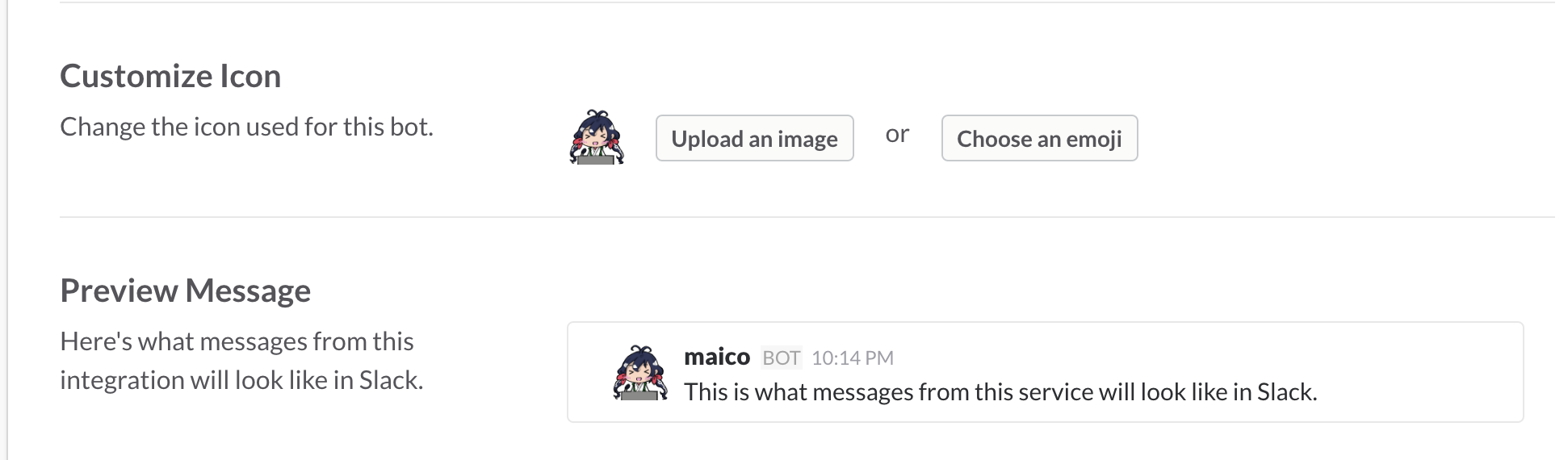
この後のテスト用にプライベートチャンネルを作成して作成したBotを登録しておきましょう。下記のように設定したら、「Create Channel」で内容を保存します。
以上でSlackの設定は完了です。ではBotの作成に入りましょう。
はじめてのBot
さて、いよいよBotの作成にとりかかります。
以下のPythonライブラリを使います。
lins05/slackbot
導入はpipで行います。
$ pip install slackbot
Slack Botを起動してみる
まずはbot用のディレクトリに移動します。
$ cd application
applicationディレクトリに移動したら、その内にある“slackbot_settings.py”にBotの設定を記述します。
# -*- coding: utf-8 -*-
import os
API_TOKEN = os.environ.get('SLACK_API_KEY', '')
default_reply = "スイマセン。其ノ言葉ワカリマセン"
ここで、API_TOKENは先ほどメモした値を環境変数から読み込んで使用します。そのため、以下のコマンドを実行して環境変数に先ほどメモした値を設定してください。
$ export SLACK_API_KEY=YOUR_API_KEY # コマンドプロンプトの場合: set SLACK_API_KEY=YOUR_API_KEY
次に、“slack_bot.py”にBotを起動するコードを記述します。
# -*- coding: utf-8 -*-
from slackbot.bot import Bot
def main():
bot = Bot()
bot.run()
if __name__ == "__main__":
main()
ではいよいよ、Botの起動です。
$ python slack_bot.py
メンションの特定の言葉に反応したり、チャンネルに投稿された言葉に反応したりします。
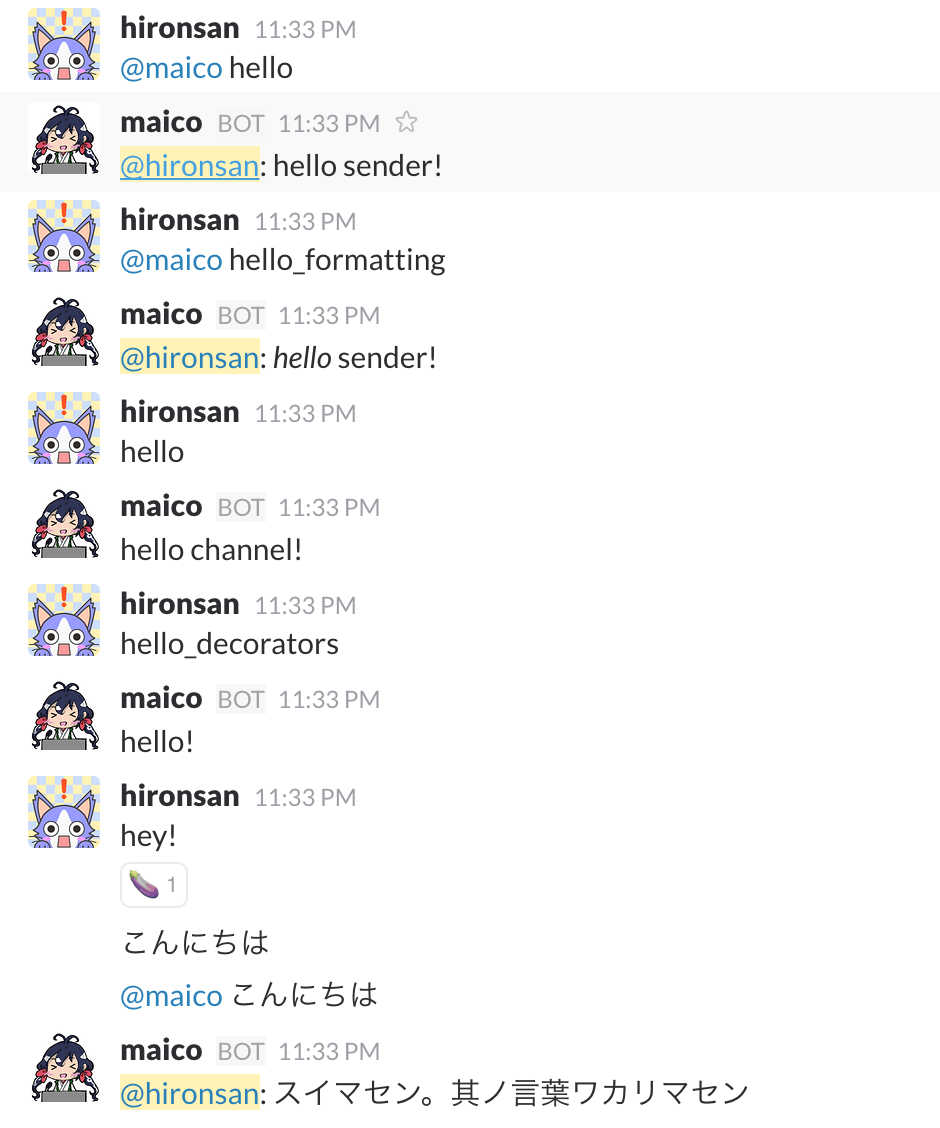
ここで行われている返答はSlackbotライブラリのデフォルトプラグインによるものです。これだけでは味気ないので自分でプラグインを登録して機能を拡張していきます。ということで、次は自分でプラグインを作成してみましょう。
はじめてのプラグイン
では次に、ユーザの「こんにちは」にたいして「こんにちは」と返すBotを作ってみましょう。
今回の記事で利用しているPythonのSlackbotライブラリはプラグインにより機能拡張を行えます。そのため、自分でプラグインを実装することで、ダイレクトメッセージやBotが参加しているチャンネル内での投稿内の特定の言葉に反応する機能を実装することができます。
まずは作成済みのBot用のディレクトリ内にあるプラグイン配置用ディレクトリに移動します。
$ cd plugins
このpluginsディレクトリには「__init__.py」が入っています。このファイルが必要な理由は、Slackbotのプラグインとして読み込ませるディレクトリはPythonパッケージである必要があるため、「__init__.py」を入れてパッケージとして認識させています。ちなみに中身は空で結構です。
さて、プラグイン配置用ディレクトリに移動したら、実際にプラグインスクリプトを作成しましょう。"slack.py"に以下のコードを記述して下さい。
from slackbot.bot import respond_to
@respond_to('こんにちは')
@respond_to('今日は')
def hello(message):
message.reply('こんにちは!')
関数”hello”に対して、”respond_to”というデコレータが付与されています。
“respond_to”デコレータの引数にマッチするキーワードを指定することでプラグインロード時に関数がBotに対するメンションに反応するように登録されます。キーワードの指定は正規表現で行うことも可能です。また、今回のサンプルのようにデコレータを複数付与することで複数キーワードに対応させることもできます。
最後に、プラグインロードが行われるように“slackbot_settings.py”に以下を追記します。
PLUGINS = [
'plugins',
]
Slackbotを起動して、メンションを送ってみましょう。@をつけてくださいね。
$ python slack_bot.py

今回作成したBotが意図した通りに反応しているのがわかります。
おうむ返しBot
では次に、正規表現を使ってユーザの発言内容を取得してみましょう。さきほどの、"slack.py"を以下のように改造してみてください。
# -*- coding: utf-8 -*-
from slackbot.bot import respond_to, listen_to
@listen_to('私は(.*)です')
@listen_to('わたしは(.*)です')
def hello(message, something):
message.reply('こんにちは!{0}さん。'.format(something))
Slackbotを起動して、投稿してみましょう。@はつけないでくださいね。
$ python slack_bot.py

ユーザの発言内容を取得できていることがわかると思います。
前回のhello関数と今回のhello関数には大きく2つの違いがあります。
まず第一に、今回は"listen_to"デコレータを使用しています。“listen_to”デコレータの引数にマッチする言葉を指定することで、Botが参加しているチャンネルへの投稿に反応するようになります。
もう一つがデコレータ内の"(.*)"です。こちらは正規表現を使っており、"(.*)"を指定することで任意の文字列にマッチさせることができます。また、マッチした内容は第2引数のsomethingに格納されています。そのため、somethingを使用することで発言内容を送り返すことができたわけです。
ユーザの発言を単におうむ返しするBotはさらに簡単です。以下のようにコードを書くだけです。
@respond_to('(.*)')
def refrection(message, something):
message.reply(something)
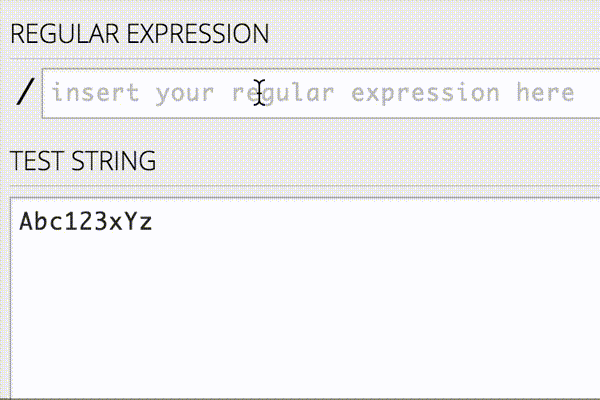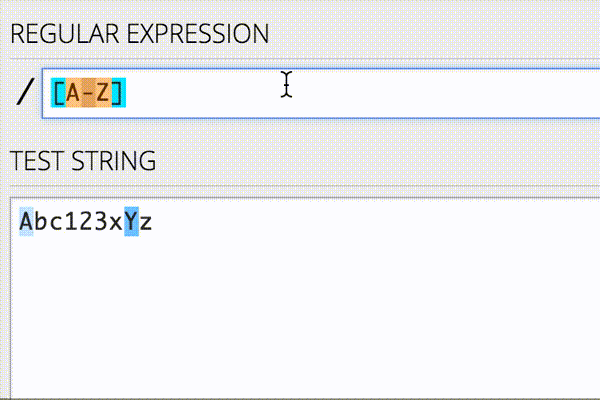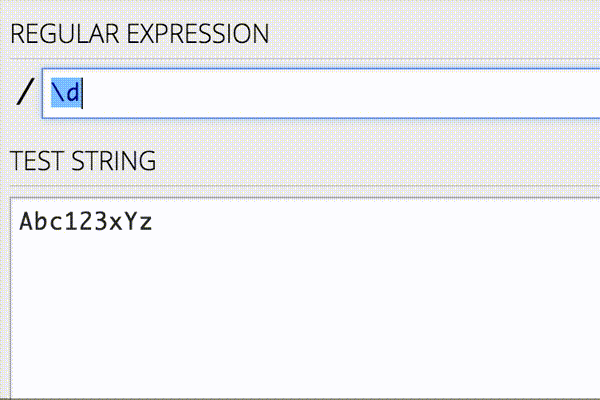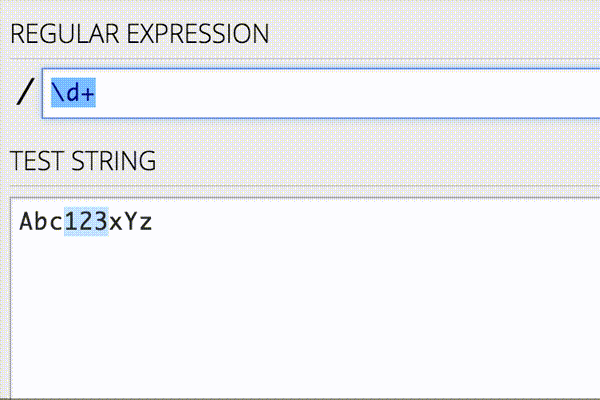
正規表現では任意の文字列に一致させる以外にも、数字だけに一致させたり、大文字だけに一致させたりすることができます。詳しくは以下を参照してください。
また、正規表現を書く際にはオンラインエディタを使ってリアルタイムに確認しながら行うと、今書いている正規表現がどんなパターンにマッチするのかがすぐわかるので、作業が捗ります。
レストラン検索システム
ここまででslackbotライブラリを用いたSlackbotの作り方はわかりました。ここからはPythonを使ってレストラン検索を行う対話システムを構築していきます。そして、構築した対話システムをSlack上に組み込んでSlackbotの作成を行います。
完成イメージは以下の通りです。
このボットは対話を通じてレストラン検索を行うことができます。また、それだけでは味気ないので雑談も行うことができるようになっています。それでは完成図もわかったところで作成していきましょう。まずは準備からです。
準備
レストラン検索Bot内で使用するライブラリをインストールします。以下のコマンドを実行してライブラリをインストールしてください。
$ pip install requests
$ pip install pyyaml
$ pip install doco
※Windowsでdocoをインストールする際にUnicodeDecodeErrorが出た場合
- https://github.com/heavenshell/py-docoからリポジトリをダウンロード
- setup.pyの18行目を以下のように編集して、インストール
open(rst, 'r', encoding='utf-8')
$ python setup.py install
また、docomo雑談対話APIとHotPepperグルメサーチAPIで取得したAPIキーを環境変数に設定してください。
$ export DOCOMO_DIALOGUE_API_KEY=YOUR_DOCOMO_API_KEY
$ export HOTPEPPER_API_KEY=YOUR_HOTPEPPER_API_KEY
コマンドプロンプト環境の場合は以下で設定してください。
$ set DOCOMO_DIALOGUE_API_KEY=YOUR_DOCOMO_API_KEY
$ set HOTPEPPER_API_KEY=YOUR_HOTPEPPER_API_KEY
システム構成
システム構成は以下の通りです。基礎的な対話システムの構成に従っています。
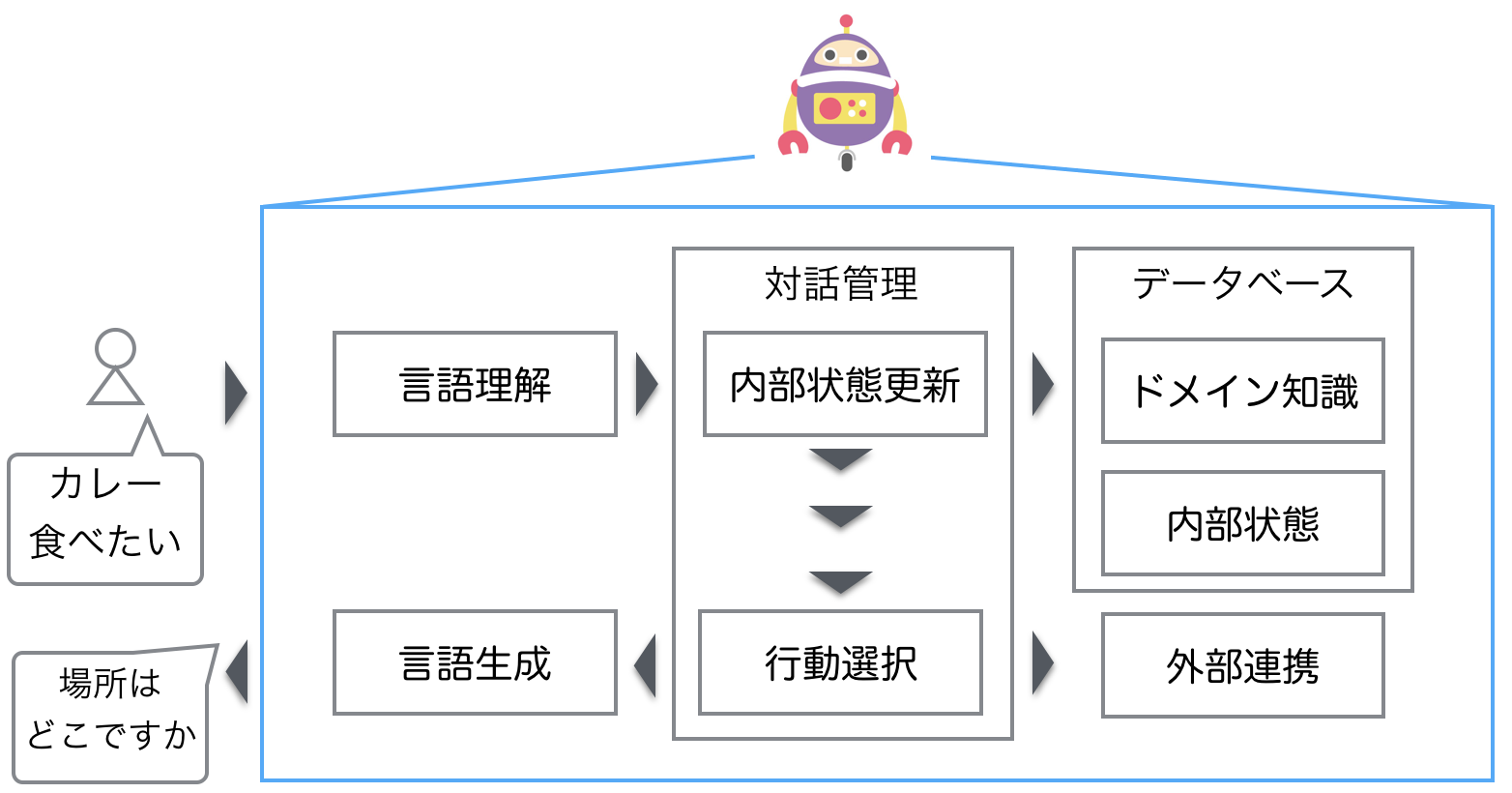
ディレクトリ構成
ディレクトリ構成は以下のようになっています。システム構成に対応したディレクトリ構成になっています。
.
├── application # Slackbotの作成
└── dialogue_system # 対話システム全体
├── language_generation # 言語生成部
├── language_understanding # 言語理解部
│ ├── attribute_extraction # 属性抽出
│ ├── dialogue_act_type # 対話行為タイプの推定
│ ├── language_understanding.py
│ └── utils
├── dialogue_management # 対話管理部
├── backend # 外部連携部
│ └── apis
├── knowledge # ドメイン知識
└── bot.py
それではシステムの構成部分を一つずつ作成してきましょう。
言語理解
さて、まずは言語理解部から作成しましょう。
以下の2つの処理を作っていきます。
- 属性抽出
- 対話行為タイプの推定
これらの作り方には大きく分けて以下の2つの方式があります:
- ルールベース方式
- 機械学習方式
機械学習方式を使うことで頑健なシステムを作ることができるのですが、データを用意するのがなかなか大変です。そのため、まずは学習データを必要とせず、比較的簡単に作れるルールベース方式で作ることにしましょう。
言語理解部のディレクトリ構成は以下の通りです。
.
└── language_understanding # 言語理解部
├── attribute_extraction # 属性抽出
├── dialogue_act_type # 対話行為タイプの推定
├── language_understanding.py # 属性抽出と対話行為タイプ推定の統合
└── utils # 便利関数
属性抽出
言語理解部ではユーザの入力したテキストを受け取ったら、属性抽出を行います。
今回抽出する属性は以下の3つとします。レストランを検索する際にはこれら3つの情報を使います。
- 料理ジャンル
- 場所
- 予算上限
ルールベースで属性抽出をするための方法としてキーワード抽出を行う方法があります。これはあらかじめ場所や料理ジャンルの辞書を用意しておいて、ユーザの発話中にマッチする部分を抽出する方式です。具体例としては、ユーザが「場所は新宿がいい」と発話し、また場所の辞書内に「新宿」というキーワードがあればユーザの発話から「新宿」を場所として抽出することができます。
属性抽出部分のディレクトリ構成は以下のようになっています。
.
└── attribute_extraction # 属性抽出
├── __init__.py
└── rule_based_extractor.py
rule_based_extractor.pyは以下のようなコードになります。
attribute_extraction/rule_based_extractor.py
以下のような感じで属性抽出を行えます。
from rule_based_extractor import RuleBasedAttributeExtractor
extractor = RuleBasedAttributeExtractor()
attribute = extractor.extract(text='ラーメンを食べたい')
print(attribute)
>>> {'LOCATION': '', 'GENRE': 'ラーメン', 'MAXIMUM_AMOUNT': ''}
対話行為タイプの推定
言語理解部がユーザが入力したテキストを受け取ったら、対話行為タイプの推定を行います。
今回推定する対話行為タイプは以下の4つです。
- ジャンル指定(INFORM_GENRE)
- 場所指定(INFORM_LOC)
- 上限金額指定(INFORM_MONEY)
- その他(OTHER)
対話行為タイプの推定には属性抽出の結果を利用することにします。これは属性として料理ジャンルが抽出されていたら対話行為タイプとしてジャンル指定と推定し、場所が抽出されていたら対話行為タイプとして場所指定を推定するという方式です。属性として何も抽出されていなかったら対話行為タイプとしてその他(OTHER)を推定することにします。
対話行為タイプ推定部分のディレクトリ構成は以下のようになっています。
.
└── dialogue_act_type # 対話行為タイプの推定
├── __init__.py
└── rule_based_estimator.py
rule_based_estimator.pyは以下のような簡単なコードになります。
dialogue_act_type/rule_based_estimator.py
動作を確認すると以下のようになります。
from rule_based_extractor import RuleBasedAttributeExtractor
from rule_based_estimator import RuleBasedDialogueActTypeEstimator
extractor = RuleBasedAttributeExtractor()
estimator = RuleBasedDialogueActTypeEstimator()
attribute = extractor.extract(text='ラーメンを食べたい')
act_type = estimator.estimate(attribute)
print(act_type)
>>> 'INFORM_GENRE'
属性抽出と対話行為タイプ推定の統合
ここまでで、属性抽出と対話行為タイプの推定は行えました。次はこれらを統合して言語理解部のコードを"language_understanding.py"に作成します。
コードは以下の通りです。
language_understanding/language_understanding.py
対話管理
対話管理部では入力理解の結果(対話行為)をもとに 以下の2つの処理を行います
- 内部状態更新
- 行動選択
対話管理部のディレクトリ構成は以下のようになります。
.
└── dialogue_management # 対話管理部
├── __init__.py
├── manager.py
└── state.py
それぞれを見ていきましょう。
内部状態更新
内部状態更新では、言語理解の結果を基に対話システムの内部状態を更新していきます。内部状態の更新は規則を用いて行います。また内部状態には様々な情報を持たせることができますが、今回は簡単のためにユーザの意図だけを持たせます。ユーザの意図とは過去に得られた属性と属性値のことです。具体的には以下の情報をもたせます。
- 料理ジャンル(GENRE)
- 場所(LOCATION)
- 予算上限(MAXIMUM_AMOUNT)
まずは保持する状態に関するクラスを書きます。こちらのクラスに状態更新のメソッドを書いてしまいます。
dialogue_management/state.py
次に対話管理を行うクラスを書いていきます。対話管理のクラスでは状態更新処理を状態クラスに委譲しています。
dialogue_management/manager.py
行動選択
行動選択部では内部状態と規則をもとに次の行動を決定します。
具体的には、対話行為タイプを出力して次の言語生成に引き渡します。
この対話行為タイプをもとに、言語生成部でテキストを生成します。必要なら外部連携部を呼び出します。
内部状態更新で書いた対話管理クラス内に行動選択のアルゴリズムを書いていきます。
以下のような方針で行動選択を行います。
| 条件 | 内容 |
|---|---|
| IF(ユーザ対話行為タイプ=OTHER) | 雑談を行う対話行為タイプ(CHAT)を出力 |
| IF(埋まっていない属性値がある) | 埋まっていない属性を聞き出す対話行為タイプを出力 |
| IF(すべての属性値が埋まっている) | レストランを提示する対話行為タイプ(INFORM_RESTAURANT)を出力 |
実際のコードは以下の通りです。
dialogue_management/manager.py
言語生成
言語生成部では、規則と対話管理部から受け取った対話行為をもとに言語生成を行います。
言語生成部のディレクトリ構成は以下のようになっています。
.
└── language_generation # 言語生成部
├── __init__.py
└── generator.py
以下のような方針で言語生成を行います。
| 条件 | 内容 |
|---|---|
| IF(対話行為タイプ=REQUEST_LOCATION) | 場所を聞く |
| IF(対話行為タイプ=REQUEST_GENRE) | ジャンルを聞く |
| IF(対話行為タイプ=REQUEST_BUDGET) | 予算を聞く |
| IF(対話行為タイプ=CHAT) | 雑談をする |
| IF(対話行為タイプ=INFORM_RESTAURANT) | レストランを提案する |
ここで、雑談をする場合はdocomoの雑談対話APIを呼び出し、レストランを提案する場合はHotPepperグルメサーチAPIを呼び出しています。
実際のコードは以下の通り。
language_generation/generator.py
Botクラスの作成
以上で、対話システムのコンポーネント作成は完了しました。これらを組み合わせたBotクラスを作ることにします。このBotクラス内部で対話システムのコンポーネントが連携し、ユーザへの応答を生成します。
dialogue_system/bot.py
Slackbotへの組み込み
作成したBotクラスをSlackbotに組み込んでいきます。新しくプラグインを作成して、以下のコードを記述します。
application/plugins/slack.py
組み込みが終わったら、slackbotを実行します。
$ python slack_bot.py
実行すると、Botが現れて対話ができるようになります。
さらに賢くするために
今回、言語理解部はキーワード抽出と規則により作成しましたが、キーワード抽出では辞書内にない単語は抽出できません。この問題に対応するために、機械学習を使って属性抽出を行うことができます。また、対話行為タイプの推定は文分類の問題と考えることができます。これもまた機械学習を用いて推定が可能です。最近は機械学習系のAPIも充実してきたので、それらを使って是非言語理解部を改善してみてください。
手前味噌ですが、以下の記事では機械学習を使った言語理解を行っています。
また、規則を用いた対話管理は簡単でわかりやすいのですが、規則の数が増えると管理・変更ができなくなってきます。その問題に対応するために強化学習を使うという方法もあります。さらに、音声対話システムの場合は入力に誤りが含まれることがあります。これに対してはPOMDPという強化学習の枠組みを使用することで入力誤りに対して対応するという研究もされています。興味がありましたら是非、強化学習を用いた対話管理も行ってみてください。
おわりに
今回はSlack上にレストラン検索対話システムを構築してみました。
以上で、ハンズオンは終了です。
いかがだったでしょうか。
ルールベースの簡単なタスク指向対話システムでしたが、SlackBot化することで様々な可能性を感じていただければ幸いです。
他のWeb APIや機械学習系のAPIと組み合わせて、より賢くする仕組みを考えてみましょう!