お久しぶりです。世間一般は大学の教員って春休みは暇なんでしょ、とよく言われますが、休み期間が最も忙しいかもしれません。特に今年は(察してください)。。
前回から間が空いてしまいましたが、とりあえずコードをリファクタリングしてFPGAで動かせるようにしましょう。
高位合成で設計する対象のおさらい
今回のサンプルコードをgithubにアップしました(Inference_HLS_2に置いています)。クローンしてください。また、一部のパラメータ(weight,bias)はオンチップに置いておくため、ヘッダファイルを出力するように[スクリプト(FPGA_AI_Edge_Contest_2019/TestBenchGen/)を修正]しています。こちらを動かしてweight_l0.hとbias_l0.hを生成しておいてください。

上記のように、最初にソフトウェア(C++)でハードウェア化したい部分(HW_kernel_3.cpp)とその検証を行うテストベンチを比較してチェックを行う部分(HW_main_3.cpp)を記述します。今回は設計の手間を省くために、重みとバイアスは予めFPGAのメモリに格納しておきます。C++のヘッダファイルのインクルードでメモリ初期値をROM化しておくことが可能となり、DMAによるロードが不要になります。よって、実機の確認は入出力値のみとなり、検証が楽になります。
メモリをやたらと食う問題の解決
前回の高位合成のイントロで、ソフトウェア記述をそのまま高位合成にかけてもメモリが爆発するわ、性能見積もりが「????」になるわで散々でしたね。原因を考えて解決しましょう。

上の図をみてください。ソフトウェア記述の場合は処理を大まかなブロック単位で切り分け、(粒度の大きい)処理毎に記述していくことが多く、その結果多重ループでひとまとめになることが多くなります。今回のケースだと、
- 入力を全て受け取る
- 畳み込み演算を行う
- 全ての出力をホストに転送する
順番で処理を行っていたため、入出力を保持するバッファメモリがやたらと大きくなっていました。そこで、処理を出力1行毎に細かく分け(細粒度処理といいます)、畳み込みを1行処理する毎にDMAを使って入出力を受け取るような処理に切り分けます(右図)。そうすると、ハードウェア的には
- オンチップメモリのバッファが小さくなる
- (後日述べる予定ですが)細粒度処理を時間並列(パイプライン化)処理で高速化できる
2つのメリットが出てきます。ソフトウェアでは思いつかない記述方法ですね。これ。ほとんど教科書ないんですよ。これ。。(どうやって身に付けろっていうんだろ、、)
高位合成向けの記述
細粒度処理を入れて記述し直したハードウェア化部分のコード(HW_kernel_3.cpp)です。
# include <iostream>
# include <stdio.h>
# include <stdlib.h>
# include <time.h>
// uncomment ... C-simulation
// comment out ... HLS
# define HLS
# include "weight_l0.h"
# include "bias_l0.h"
# ifdef HLS
# include "ap_int.h"
# include "hls_half.h"
# include "hls_stream.h"
# include "ap_axi_sdata.h"
typedef float DTYPE;
struct int_s{
int data;
bool last;
};
# else
typedef float DTYPE;
# endif
void kernel(
# ifdef HLS
hls::stream<int_s>& stream_in,
hls::stream<int_s>& stream_out
# else
DTYPE *stream_in,
DTYPE *stream_out
# endif
);
// ---------------------------------------------------
// Convolution(3chx416x416) in the 1st layer
// ---------------------------------------------------
void kernel(
# ifdef HLS
hls::stream<int_s>& stream_in,
hls::stream<int_s>& stream_out
# else
DTYPE *stream_in,
DTYPE *stream_out
# endif
)
{
//(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4)) // padding zero????
# pragma HLS INTERFACE axis port=stream_in
# pragma HLS INTERFACE axis port=stream_out
# pragma HLS INTERFACE s_axilite port=return
// buffer
# ifdef HLS
DTYPE in_img_buf[3*416*11];
DTYPE out_fmap_buf[64*102*1];
# else
DTYPE *in_img_buf = (float *)malloc(3*416*11*sizeof(float));
DTYPE *out_fmap_buf = (float *)malloc(64*102*1*sizeof(float));
# endif
// -----------------------------------------
// Convolutional operation
// -----------------------------------------
int dst_y;
int dst_x;
dst_y = 0;
CONV_Y: for( int y = 0; y < 416 - 11; y += 4){
// load the next data to a line buffer
# ifdef HLS
int_s tmp_din, tmp_dout;
int i;
i = 0;
LOAD_IMG: do{
# pragma HLS LOOP_TRIPCOUNT min=13728 max=13728 // 13728=416x3x11
tmp_din = stream_in.read();
in_img_buf[i] = (DTYPE)(tmp_din.data) / 1024.0; // (Y,X,CH)
i++;
}while( tmp_din.last == 0);
# else
for( int buf_ch = 0; buf_ch < 3; buf_ch++){
for( int tmp_y = 0; tmp_y < 11; tmp_y++){
for( int buf_x = 0; buf_x < 416; buf_x++){
in_img_buf[buf_ch*11*416 + tmp_y*416 + buf_x]
= stream_in[buf_ch*416*416 + (y+tmp_y)*416 + buf_x];
}
}
}
# endif
// perform convolution
CONV_OCH: for( int och = 0; och < 64; och++){
dst_x = 0;
CONV_X: for( int x = 0; x < 416 - 11; x+= 4){
float tmp = 0;
CONV_ICH: for( int ich = 0; ich < 3; ich++){
CONV_KY: for( int ky = 0; ky < 11; ky++){
CONV_KX: for( int kx = 0; kx < 11; kx++){
tmp += in_img_buf[ich*11*416+(ky)*416+(x+kx)]
* weight_l0[och*3*11*11+ich*11*11+ky*11+kx];
}
}
}
out_fmap_buf[och*102 + dst_x] = tmp + bias_l0[och];
dst_x++;
}
}
// data write to the host processor
# ifdef HLS
WB: for(int j = 0; j < 64*102; j++){
# pragma HLS pipeline
tmp_dout.data = (int)(out_fmap_buf[j] * 1024.0);
tmp_dout.last = 0;
stream_out.write( tmp_dout);
}
tmp_dout.data = 0;
tmp_dout.last = 1;
stream_out.write( tmp_dout);
# else
for( int och = 0; och < 64; och++){
for( int x = 0; x < 102; x++){
stream_out[och*102*102 + dst_y*102 + x]
= out_fmap_buf[och*102 + x];
}
}
# endif
// update destination y address
dst_y++;
}
}
いくつか新しい概念が出てきましたので説明すると、
# include "weight_l0.h"
# include "bias_l0.h"
ヘッダファイルで初期値を読み込むことでROM化、すなわちFPGAのメモリの初期値を与えることができます。
DMA通信の方法がかなり厄介ですが、順を追って説明すると
# include "hls_stream.h"
# include "ap_axi_sdata.h"
struct int_s{
int data;
bool last; // stop signal
};
DMAストリーム転送用のヘッダをインクルードして、DMA転送したいデータに終端信号(last)をバンドルした構造体を定義しておきます。そして、ハードウェア化したい部分の関数の引数を
void kernel(
# ifdef HLS
hls::stream<int_s>& stream_in,
hls::stream<int_s>& stream_out
# else
DTYPE *stream_in,
DTYPE *stream_out
# endif
);
プリプロセッサを駆使してソフトウェア記述の検証を残しつつ、hls::stream<>&を使って宣言します。さらに、HLSツールに「この信号はDMAストリーム転送だよ」ということを教えるためにプラグラマ#pragmaを使って指示します。
# pragma HLS INTERFACE axis port=stream_in
# pragma HLS INTERFACE axis port=stream_out
# pragma HLS INTERFACE s_axilite port=return
#pragma HLS INTERFACE s_axilite port=returnはAXI Liteプロトコルといって、単純な制御信号を宣言するための記述でこれは必須です(ハードウェアを制御する信号が必要ですからね)。
ここまで記述すればようやくデータを受信できるようになりまして、do-while文で
LOAD_IMG: do{
# pragma HLS LOOP_TRIPCOUNT min=13728 max=13728 // 13728=416x3x11
tmp_din = stream_in.read();
in_img_buf[i] = (DTYPE)(tmp_din.data) / 1024.0; // (Y,X,CH)
i++;
}while( tmp_din.last == 0);
と記述できます。#pragma HLS LOOP_TRIPCOUNTはHLSツールに「このループは○○回ループするよ」と教える役割があります。前回の性能見積もりで「????」と表示された対策ですね。設計者は入力画像(416ピクセルx11ラインx3チャネル)一度に転送することが予めわかっているので指示できます。
余談(記述する必然性はない)ですが、ループの先頭にラベル(上記のコードではLOAD_IMG:)をつけておくと、合成後の解析でどのループだったか判別しやすくなります。つけておきましょう。
ホストへデータをDMA転送するにはfor文で
WB: for(int j = 0; j < 64*102; j++){
# pragma HLS pipeline
tmp_dout.data = (int)(out_fmap_buf[j] * 1024.0);
tmp_dout.last = 0;
stream_out.write( tmp_dout);
}
tmp_dout.data = 0;
tmp_dout.last = 1;
stream_out.write( tmp_dout);
と記述します。注意しておくことは、DMA転送には終端信号(今回はlastを構造体で宣言した)が必要なので、転送したいサイズ+1個のデータがホストに送られることに注意してください!
コードを読んでいくと「あれ?」と思うことがあるはずです。不自然な。
in_img_buf[i] = (DTYPE)(tmp_din.data) / 1024.0; // (Y,X,CH)
tmp_dout.data = (int)(out_fmap_buf[j] * 1024.0);
DMAでデータをやり取りするときにわざわざint32bitにキャストしていますね。本来だったらfloat32でやり取りすべきですが。これは深層学習の多くのデータ処理が固定ビットで十分であるため、近い将来固定ビット化して最適化するための布石です!
高位合成をかけてみる
ということで説明が長くなったのですが、高位合成をかけてみましょう。まずは性能からです。
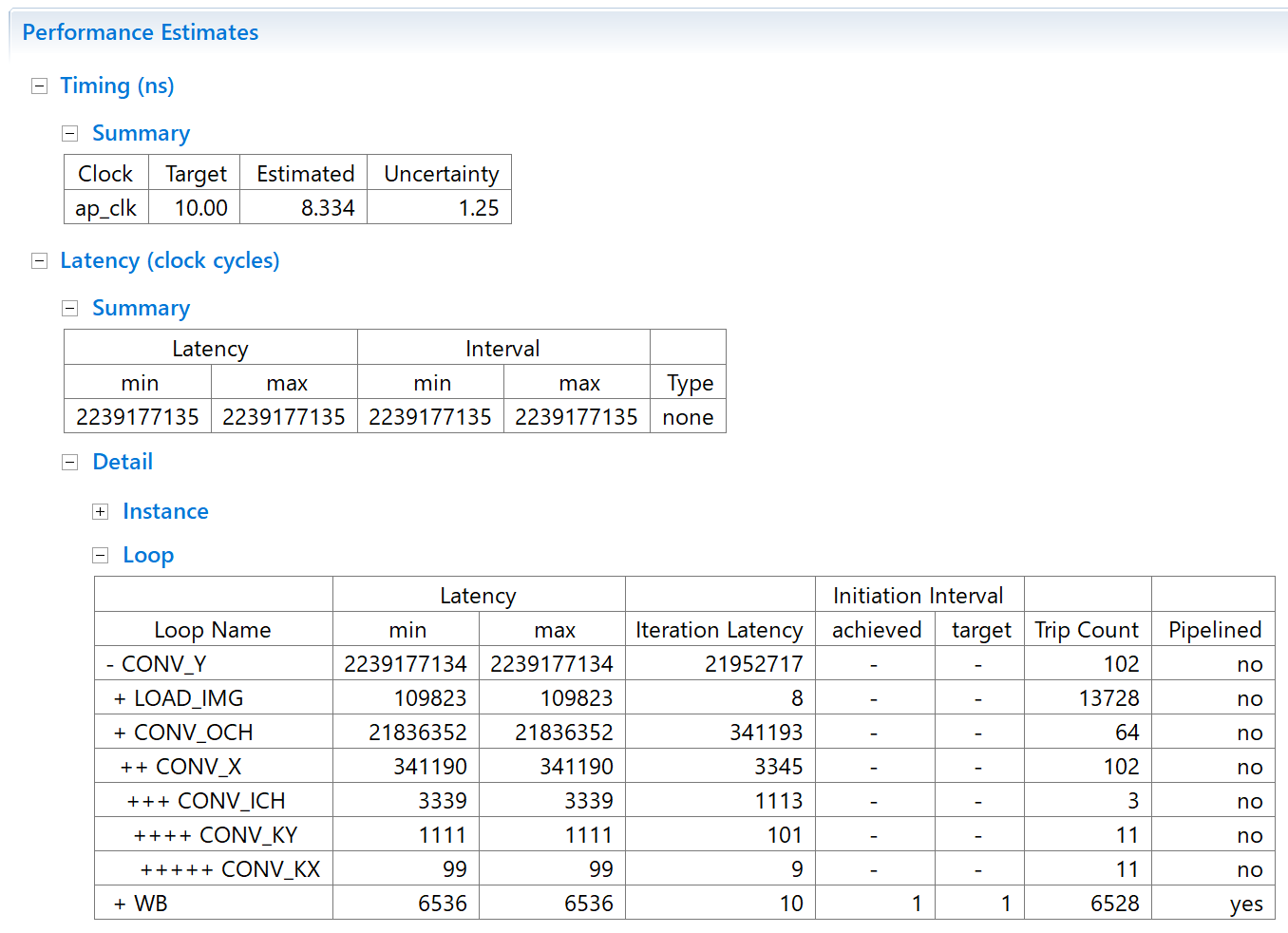
あいかわらずたったの1層のみの処理のくせに約22秒と遅いですが、とりあえず見積もり値を出してくれるようになりました。また各ループにラベルを振ったのでどこがボトルネックかわかるようになりました。うーん、やっぱり畳み込み演算が重い処理なんですねぇ。。
次に、ハードウェアリソースの利用率をみてみましょう。

おおっ、前回400%のメモリ利用率が19%と大幅に減っています。全てのリソースが100%を下回っているので、実装できるサイズになりました(遅いですが)。
いよいよ次回こそはハードウェアを動かすぞ
次回はUltra96ボードv2に設計したハードウェアを載せて動かしてみましょう。かなり手間がかかるので、記事が長くなりそうな予感。。。。とりあえず、
- Vivado2019.1 (他のバージョン、特に2019.2はダメ絶対)
をインストールしておいてください。webバージョン(ライセンス無料)で実装できます。お楽しみに!