経緯
最近、機械学習を使った転倒者検知について触れる機会があり、最新の転倒者検知にはどのような方法が用いられているのか興味をもったので、調べてみた結果を共有します。
arxivでfall person detectionなどと調べると、いくつか興味深い論文が出てきたのですが、一番面白そうだったSSHFD: Single Shot Human Fall Detection with Occluded Joints Resilienceという論文をご紹介します。2D pose estimationと3D pose estimationを転倒者検知に使っていて面白いと思いました。pose estimationについてはこちらにまとめてあります。基本的に論文の和訳を書いていますが、所々自分の解釈でまとめています。重要でないと思った箇所は省いてます。
ざっくりとはどんな論文?(忙しい方へ)
- 単一カメラからの2D画像のみで転倒者検知ができるよ
- 3D pose estimationも使うことによって、学習データにはないカメラの視点や背景の違い、オクルージョンにも強いよ
- OJR (Occluded Joints Resilience)を使うことによって、身体の一部しか映ってなくても検出できるよ
0. 要約
既存のビジョンベースの転倒検出システムは、外見の変化やカメラの視点の多様さ、オクルージョン、背景の乱雑さなどの障害により、未知データへの精度が低いです。この論文では、上記の課題を克服する方法を探り、単一画像からの転倒者検知のためのディープラーニングベースのフレームワークであるSingle Shot Human Fall Detector (SSHFD)を紹介します。
これは、2つの重要なイノベーションによって達成されます。1つ目は、人の見た目上の特徴に不変な、転倒の際の人間のポーズを提示します。次に3D姿勢推定と、転倒認識のためのニューラルネットワークモデルを提示します。これらは、身体の一部が見えない場合にも耐性があります。
1. 導入
既存の方法は、動画データから抽出された外見に基づく特徴を使用して、転倒の表現を学習します。ただし、外見ベースの性能は、外見の大きな変化(身体の大きさ、服の違いなど)、カメラの視点の違い、背景の乱雑さが原因で、実際の環境での汎用性が不十分です。
さらに、大規模なpublicの転倒データセットが利用できないため、既存の転倒者検知のほとんどは、シミュレートされた環境または制限されたデータセットを使用して学習および評価されます(プライバシーの問題のため、publicに共有することはできません)。 したがって、既存の手法は、未知の実際の環境での転倒検知の汎化性能が低いです。 この論文では、上記の課題を克服する方法を探り、未知の現実の環境での正確な転倒者検知のための「Single Shot Human Fall Detector(SSHFD)」と呼ばれるディープラーニングフレームワークを紹介します。 この論文の主な貢献は次のとおりです。
- 外見や背景、明るさ、シーン内の人の位置に不変な、転倒を表す人間の姿勢を提示している。実験により、2D poseと3D poseに基づく転倒データで学習されたモデルが、転倒者検知において未知の現実の環境にも汎化されていることがわかった。
- 3D姿勢推定と転倒者検知のためのネットワークを提示する。このネットワークは、体が部分的にしか見えていない場合でも転倒者を検知することに成功した。
- 合成データのみで学習したモデルで、未知のデータでも十分な精度を挙げた
2. 関連研究
既存の手法としては、以下のようなものがあります。
- 転倒している人間のbounding boxを使用して学習する方法
- motion segmentationを使用してシーン内の人間の領域を検出し、検出された領域から視覚的外観と形状情報を組み合わせて、転倒の特徴を学習する方法。(motion segmentationは動画内で独立して動く物体を識別し、それらを背景から分離するタスクです)
- KinectからのDepth情報を使って転倒者の特徴を学習させる方法
3. Single Shot Human Fall Detector(SSHFD)について
下の図は、3つのメインモジュールを持つ私達のフレームワークの全体的なアーキテクチャを示しています。①シーンのRGB画像を入力として取り込み、2D画像空間で身体の関節位置を生成する2D pose estimation、②2D poseを入力として取り込み、3D空間で関節位置を予測する3D pose estimation、および③2D poseと3D poseのデータを組み合わせ、ターゲットクラスに関する確率を予測する転倒者検知のネットワークの3つです。以下では、フレームワークの個々のコンポーネントについて詳しく説明します。
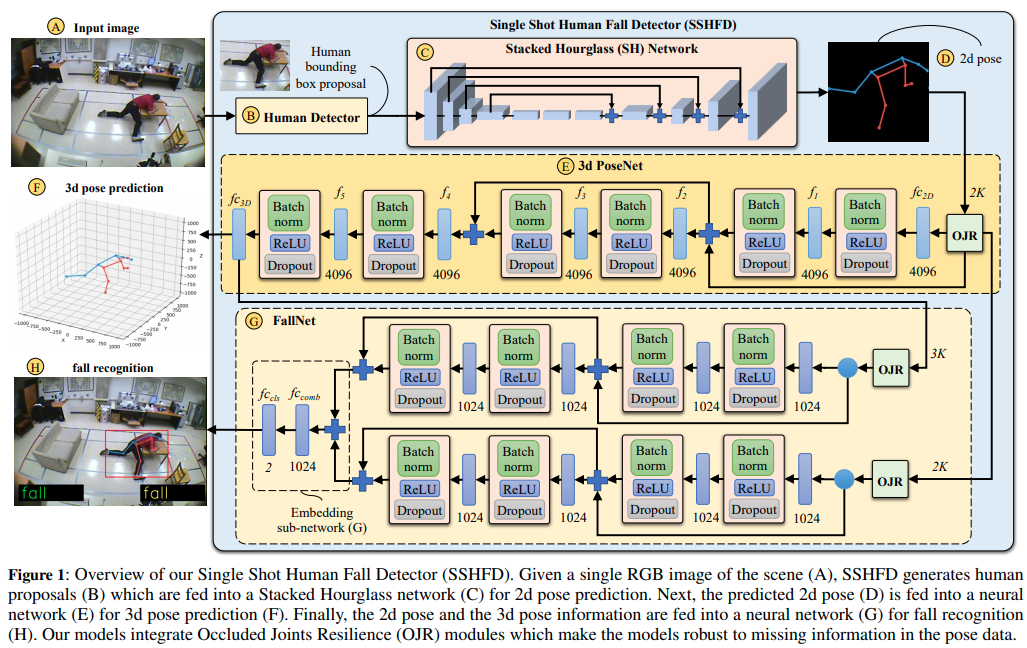
3.1 The Proposed Fall Representation
私たちの転倒の表現は、2D画像空間と3D座標空間上での関節位置に基づいています。 Figure1-D(上の図)に示すように、関節の推定値(シーン画像から予測)を224×224の画像に変換します。その2D poseを使用して、Figure1-Fに示すように、サイズが1000×1000×1000mm3の座標空間内での関節の位置を予測します。
3.2 The Proposed 2d Pose Estimation (Fig. 1)
2D pose推定は、2つの主要なモジュールで構成されています。①入力画像から人間のbounding boxの検出をするHuman Detector(Figure1のB)と、②身体の関節の2D位置とそのconfidence scoreを予測するStacked Hourglass(SH)network(Figure1のC)です。SH networkは、W×H×K次元ヒートマップでラベル付けされた正解データを使用して学習されます。WおよびHはヒートマップの幅と高さを表し、Kは関節の数を表します。Human detectorで使用されている形式に従って、K = 17 jointタイプを使用しました。関節k ∈ {1, ..., K}のヒートマップ(Hk)は、関節のピクセル位置(xk、yk)の周りのガウス分布をとることによって生成されます。それは以下によって与えられます。
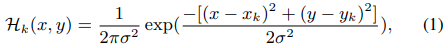
ここでσはハイパーパラメータで、今回はσ=4として実験を行っています。
補足: ヒートマップについて
姿勢推定のアノテーションデータは身体の部位情報が特定ピクセルの座標で示されています。そのため、そのピクセルから1ピクセルでもズレると間違いとなります。しかし、部位情報のアノテーション座標はアノテーションをする人によって少しは異なるはずです。よって、アノテーション情報のピクセル座標を中心としたガウス分布で部位情報のアノテーションデータを作り直し、中心のピクセルの周辺もその部位である確率を高くします。この部位情報のアノテーションのことをヒートマップといいます。

また、SH networkの目的関数は以下のように定義されます。
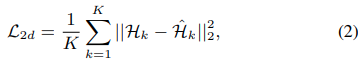
予測されたヒートマップ(後ろのHk)と正解のヒートマップ(前のHk)の誤差をとっています。
3.3 The Proposed 3D Pose Estimation (Fig. 1-E)
入力として2Dポーズ画像を取り、3D空間での関節の位置を予測します。目的関数は以下の式で定義されます。
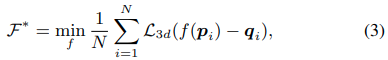
ここでL3dはMSE loss(平均二乗誤差)を表しています。N個のdataset(pose)において、2D画像から3Dでの予測誤差を最小化していきます。3D pose estimationにおいて、今回使われているのは3D PoseNetというものです。Fig.1のEにあたる部分です。

f1~f5の5つの層によって構成され、residual conectionsも使ってモデルの精度を上げています。この3D PoseNetにより2D画像から3次元での座標を推定できるようになりました。
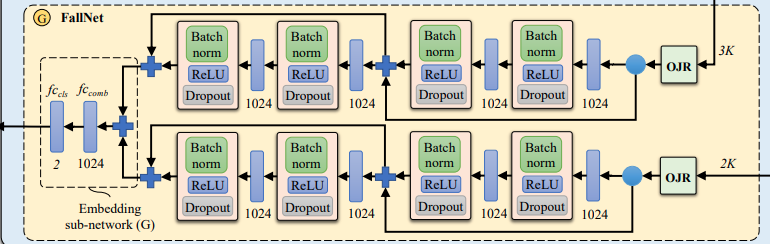
3.4 The Proposed Fall Recognition (Fig. 1-G)
Fall net(Fig.1のG)では2D poseと3D poseデータを組み合わせ、ターゲットのクラスを予測します。2D情報と3D情報は、構造が同じネットワークにそれぞれ入れられます。2つのoutput featuresは合計されて、2つの層からなるembedding sub-network G(下の図の左側)に入れられて、最終的に2つのクラス(fall, no-fall)が出力されます。
目的関数は以下の式で表されます。ρi*は正解ラベルを表しています。
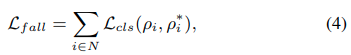
損失関数は以下のcross entropyを使います。ここで、YxはクラスラベルCが観測値xの正しい分類である場合のbinary indicatorであり、pはクラスCの観測値xのprobabilityです。
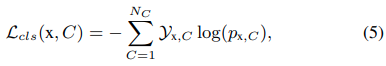
3.5 The Proposed Occluded Joints Resilience (OJR)
RGB画像により学習されたポーズ推定は、画像の不完全さやオクルージョン、背景の乱雑さ、正確ではないアノテーションにより、必然的にエラーを発生します。よって、3D PoseNetとFallNetが依存している**SH networkの結果や2d pose predictionsのエラーは、3D pose estimationとfall recognitionの質に影響を及ぼします。**この問題を克服するために、pose dataにおける不完全なデータに対して、モデルの頑健性を高める“Occluded Joints Resilience (OJR)”という手法を提案します。これを達成するために、OJRはオクルージョンパターンMiを作って、それを使って元々のpose dataをオクルージョンされたpose dataに変換します。occlusion pattern Miは次のように定義されます。
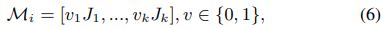
ここで、Ji =(xi、yi)は身体の関節の位置を表し、vはバイナリ変数で、k番目の関節の可視性を示します。 トレーニング中、OJRメソッドは、トレーニングサンプル間で異なるオクルージョンパターン{M}の豊富なライブラリを生成します。これにより、様々なオクルージョン状況に対するネットワークの適応性が向上します。
4. 実験
4.1 学習と実装の詳細
MS COCO Keypoints datasetを使って、SH networkを学習させました。3D pose estimationとfall recognitionを学習するために、fallかno-fallか分類されている2dと3Dのpose anotationデータを使っています。下の図はその一部です。
実装の詳細は以下のような感じです。
- 全結合層のweightsはzero-mean Gaussian distributions(標準偏差を0.01、バイアスを0)で初期化されている
- それぞれのネットワークは300epoch学習されている
- 開始学習率は0.01に設定され、エポックの総数の50%と75%でそれぞれ10で割っている。
- parameter decayは重みとバイアスにおいて0.0005に設定している
- dropoutのprobabilityは0.5に設定している
- 学習にはADAM optimizer、4つのNvidia Tesla K80 GPUsを使っている
4.2 テストデータセット
未知の実世界の環境でのSSHFDの汎化性能を評価するために、合成データのみでモデルを学習させ、MultiCam転倒データセットとLe2i転倒データセットでモデルをテストしました。MultiCamデータセットは、24の異なるシナリオで構成され、各シナリオは多数のアクティビティ(マットレスへの落下、ウォーキング、物を運ぶなど)を実行する人の動画で構成されます。各シナリオは、8つの異なる視点から撮影されています。このデータセットは、単一カメラによるシングルショットの転倒者検知にとって難易度が高いです。これは、異なるカメラの視点により、転倒の空間的な位置、スケール、および方向にオクルージョンと大きなバリエーションが生じるためです。Le2iデータセットには、様々な環境で転倒やその他の通常のアクティビティを実行する、様々な演者の221本の動画が含まれています。多様な照明条件とオクルージョンのため、データセットは複雑です。 SSHFDの認識パフォーマンスを定量化するために、25fpsの解像度でターゲット動画から画像フレームを切り出し、SH networkを使用して2D poseを生成しました。
次に、少なくとも1つのポーズが検出された画像フレームごとにweighted F1 score, precision, recallを計算し、対象となるデータセットの全画像フレームにわたって平均をとりました。
5. 結果
Table 1は、私達のフレームワークの異なるバリエーションについて、テストデータセットでの転倒者検知の結果を示しています。
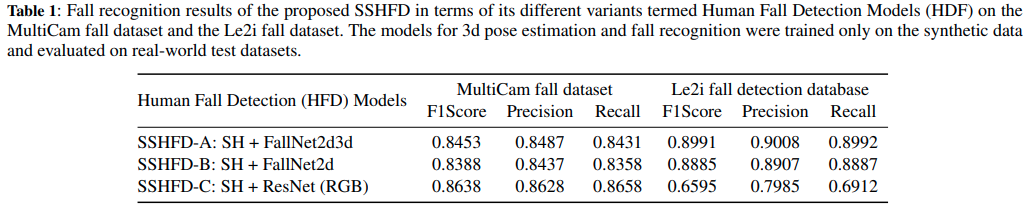
AとBはFig 1で示され、Sec 3.4で説明されたようにpose dataで学習されたニューラルネットワークを使っています。Table 1のCは人間の合成データのRGB情報を学習させたResNet18を使っています。
Table 1の結果から、RGBベースの転倒者検知モデルは、MultiCamデータセットのposeベースの転倒者検知モデルに比べて高いF1 scoreを示しましたが、Le2iデータセットでは最も低いF1 scoreを示しました。これは、合成した人間の色情報に基づいて学習したRGBベースの転倒者検知モデルが、外見上の特徴のばらつきが大きく、背景が異なるLe2iデータセットのシーンに対して汎化することができなかったためです。Table 1に示すように、私達の転倒者検知モデル(SSHFD-A)は、RGBベースのモデルと比較して、MultiCamデータセットでは同等のF1 scoreを、Le2iデータセットでは優れたF1 scoreを示しました。
Fig 3は、テストデータセットのサンプル画像に対する転倒者検知の定性的な結果を示しています。

この結果から、私達の転倒者検知フレームワークは、部分的なオクルージョンや、実世界のシーンにおける転倒ポーズの空間的な位置、スケール、方向の変化にロバストであることがわかりました。これらの改善は、私達が開発したposeベースの転倒表現が外見の特徴に不変であり、実世界のシーンにおいて、異なる人間や背景の乱雑さに対してロバストなフレームワークを実現していることに起因しています。Table 1は、2Dと3Dのpose情報を組み合わせたFallNet2d3dモデルが、2Dのpose情報のみを使用したFallNet2dモデルよりも優れた性能を発揮したことも示しています。
5.1 関節の欠損に対する頑健性
5.1.1 Fall Recognition
Fig 5は、MultiCamデータセットとLe2iデータセットにおいて、OJRありとなしの場合で私達の提案したモデルのF1 scoreがどれだけ変化するか比較した結果です。図の横軸はノイズ(見えない関節)の数です。
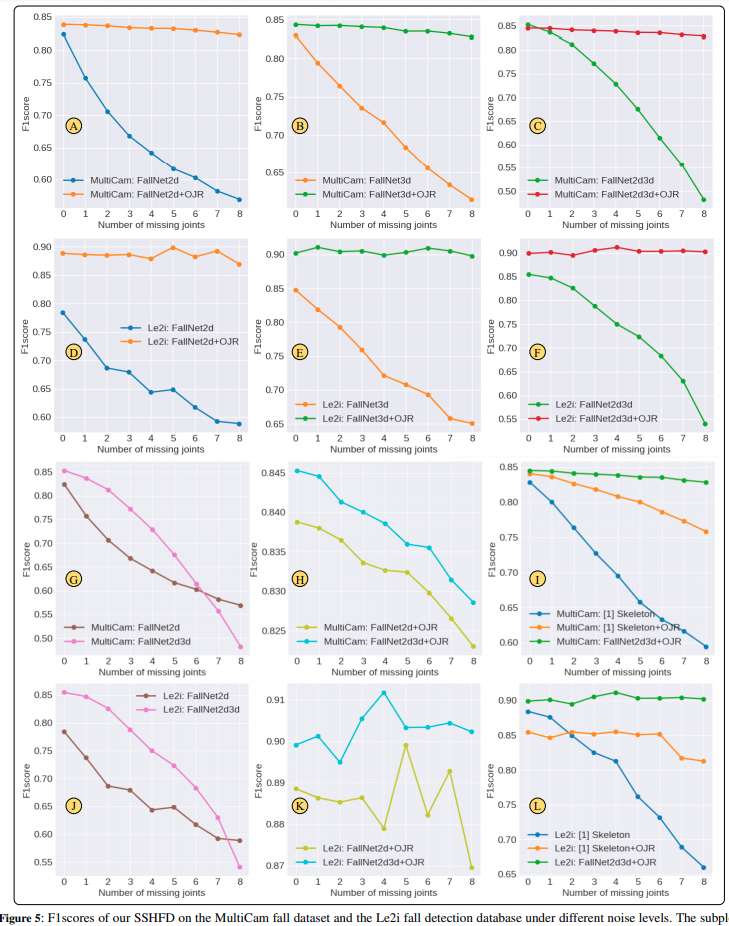
その結果、私達のOJRベースのモデルは、OJRを使用せずに学習したモデルと比較して、すべてのノイズレベルにおいて有意に高いf1 scoreを生成したことを示しています。例えば、8つの関節が欠落している入力pose dataを用いた場合、OJRを用いたモデルは、OJRを用いないモデルと比較して、MultiCamとLe2iのデータセットにおいて、それぞれ最大35%と40%のF1 scoreの改善が見られました(Fig 5-CとFig 5-Fを参照)。また、2次元骨格の視覚表現とセグメンテーション情報を用いた手法と比較する実験も行いました。これらの実験結果をFig 5-I、Fig 5-Lに示します。その結果、私達の2Dおよび3D-poseベースの転倒検知モデルの方が、特に関節データが欠落している場合に優れた転倒認識性能を発揮することが示されました。Fig 7は、不完全な2Dおよび3Dポーズデータを用いたMultiCamデータセットにおける私達のモデルの定性的な結果を示しています。
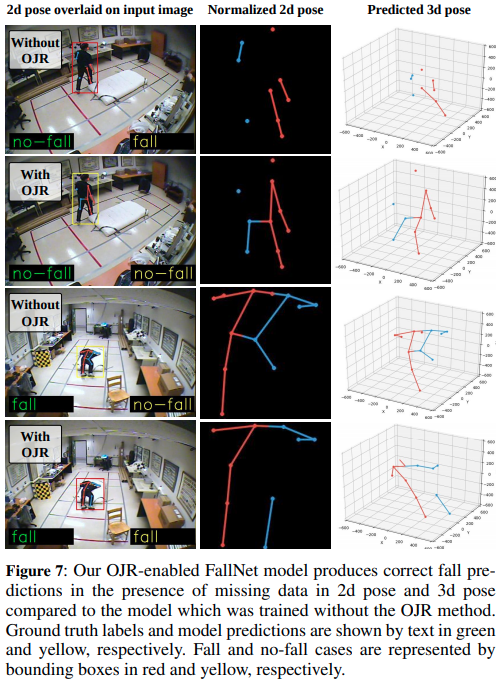
その結果、OJR法は、FallNetモデルをpose dataの欠落情報に対してロバストなものにし、2次元または3次元のポーズ誤差の下で正しい転倒予測を可能にすることを示しています。
5.1.2 3D Pose Estimation
ここでは、合成データ上で異なるレベルのノイズ(関節欠損)の下で3D PoseNetをテストしました。このために、データを70%の訓練データと30%のテストデータのサブセットにランダムに分割しました。Table 2は、テストデータセット上で私達のモデルが予測した関節位置と正解関節位置との間のユークリッド距離の平均値をミリメートル単位で示しています。
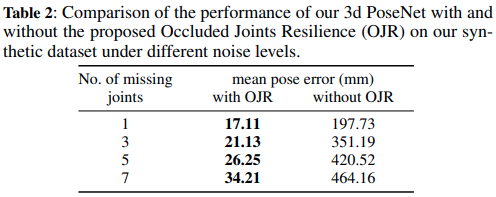
私達のOJRベースの3D PoseNetが、テストデータセットのすべてのレベルのノイズについて、OJRなしのモデルと比較して、一貫して低いポーズ誤差であることがわかります。Fig 4はOJRを用いた場合と、用いない場合の合成データに対する3D PoseNetの定性的な結果を示しています。
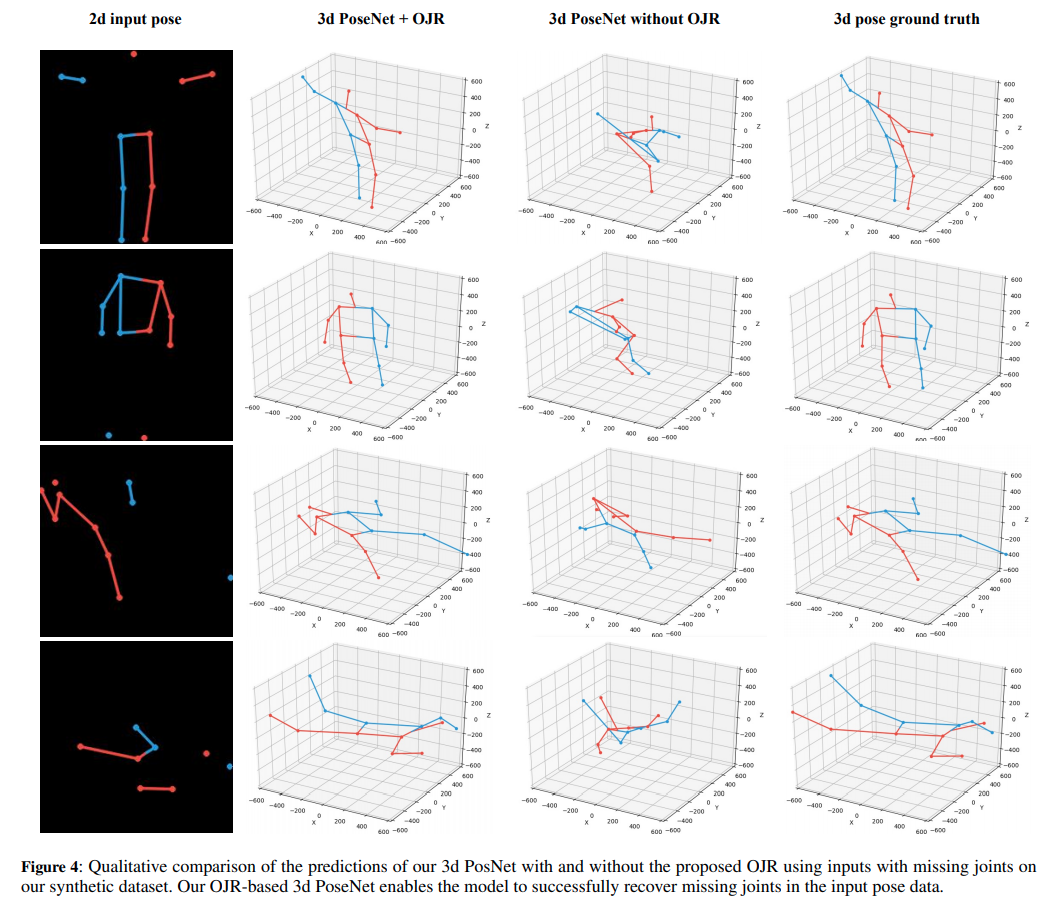
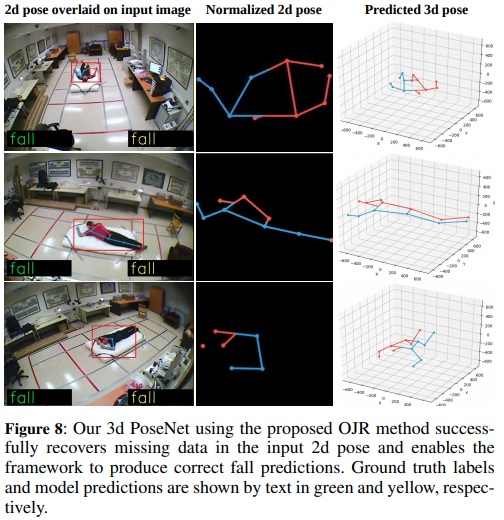
この結果から提案されたOJRによって、3D PoseNetが不完全な2D pose入力から3D 関節情報を正常に復元することを可能にしていることがわかります。これにより、Fig 8に示すように、2次元のpose errorの下でも正しい転倒予測を行うことが可能となっています。
6. 結論と今後の展望
この論文では、単一の画像から人間の転倒を検出するためのディープラーニングフレームワークであるSingle Shot Human Fall Detector(SSHFD)を紹介しました。SSHFDは、2次元画像空間と3次元座標空間における人間の関節位置に基づいて転倒表現を学習します。私達の転倒表現は、外見や背景に不変であり、純粋な合成データから得た情報のみで、未知の実世界のデータに対する転倒認識への汎化を可能にしています。将来的には、他の動きを認識するためにフレームワークを拡張していく予定です。
個人的な感想
人間の動きを認識するためにpose estimationをうまく使っている論文だなと思いました。ただ、Depthカメラも思ったより安いことを最近知ったので、3D pose estimationのところは、depthカメラの情報使ってもいいのかなと思いました。
間違いや質問、ご意見等ありましたらお気軽にコメントください。頑張って答えますので(笑)。