はじめに
人間の姿勢推定モデルの変遷と最新動向が分かりやすくまとまっているサイトがあったので、翻訳しました。
以下、翻訳です。↓↓
Human Pose Estimation(人間の姿勢推定)は、過去数十年間コンピュータビジョンのコミュニティで注目されてきた重要な問題です。これは、画像やビデオの中の人々を理解するための重要なステップです。この記事では、Human Pose Estimation(2D)の基本について説明し、このトピックに関する文献をレビューします。この記事は、Human Pose Estimationのチュートリアルとしても役立ち、基本的なことを学ぶのにも役立ちます。
Human Pose Estimationとは何か
Human Pose Estimationは、画像またはビデオにおける人間の関節(キーポイントともいい、肘、手首など)の場所を特定する問題として定義されます。また、どのポーズに該当するかの分類としても定義されます。

- 2D Pose Estimation - RGB画像から各ジョイントの2Dポーズ(x,y)座標を推定します。
- 3D Pose Estimation - RGB画像から各ジョイントの3Dポーズ(x,y,z)座標を推定します。

Human Pose Estimationには非常に優れたアプリケーションがあり、アクション認識、アニメーション、ゲームなどで頻繁に使用されています。たとえば、非常に人気の高いディープ・ラーニング・アプリのHomeCourtは、Pose Estimationを使用してバスケットボール・プレーヤーの動きを分析します。
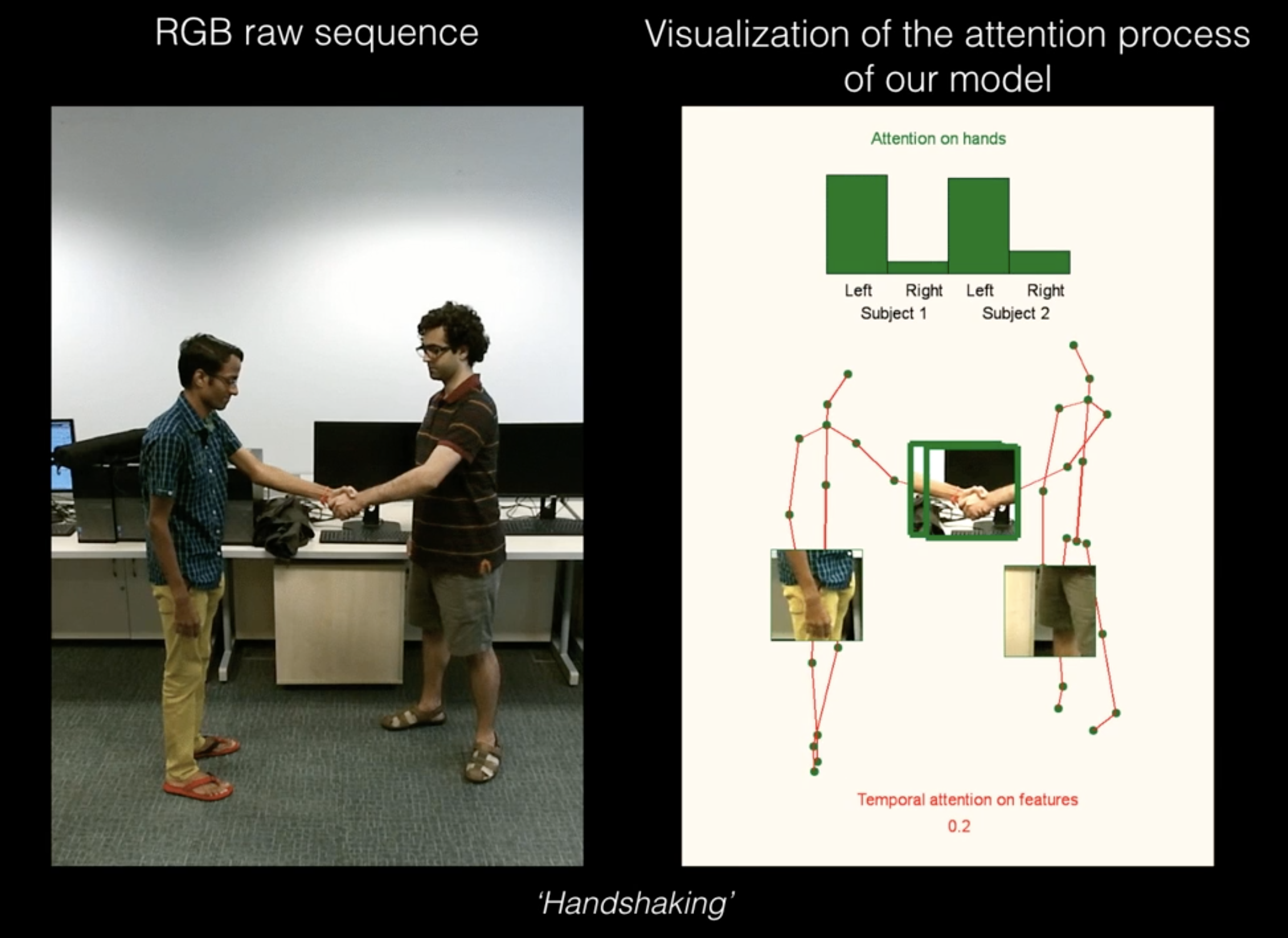
なぜ難しいのか
動きの激しい関節、小さくほとんど見えない関節、オクルージョン(何かに隠れて見えないこと)、衣服、照明の変化などがこの問題を困難にしています。

この記事では2Dの人間の姿勢を推定します。
2D Human Pose Estimationに対する異なるアプローチ
古典的なアプローチ
-
姿勢推定に対する古典的なアプローチでは、画像構造フレームワークを用います。ここでの基本的な考え方は、オブジェクトを、「パーツ(←変形可)」の集合によって表現することです。「パーツ」は、画像内でマッチングする外観テンプレートです。バネは、パーツ間の空間的な接続を示します。各パーツがピクセル位置と方向によってパラメータ化されることで、出来上がった構造は、姿勢推定に非常に関連する関節をモデル化できます。(構造化予測タスク)
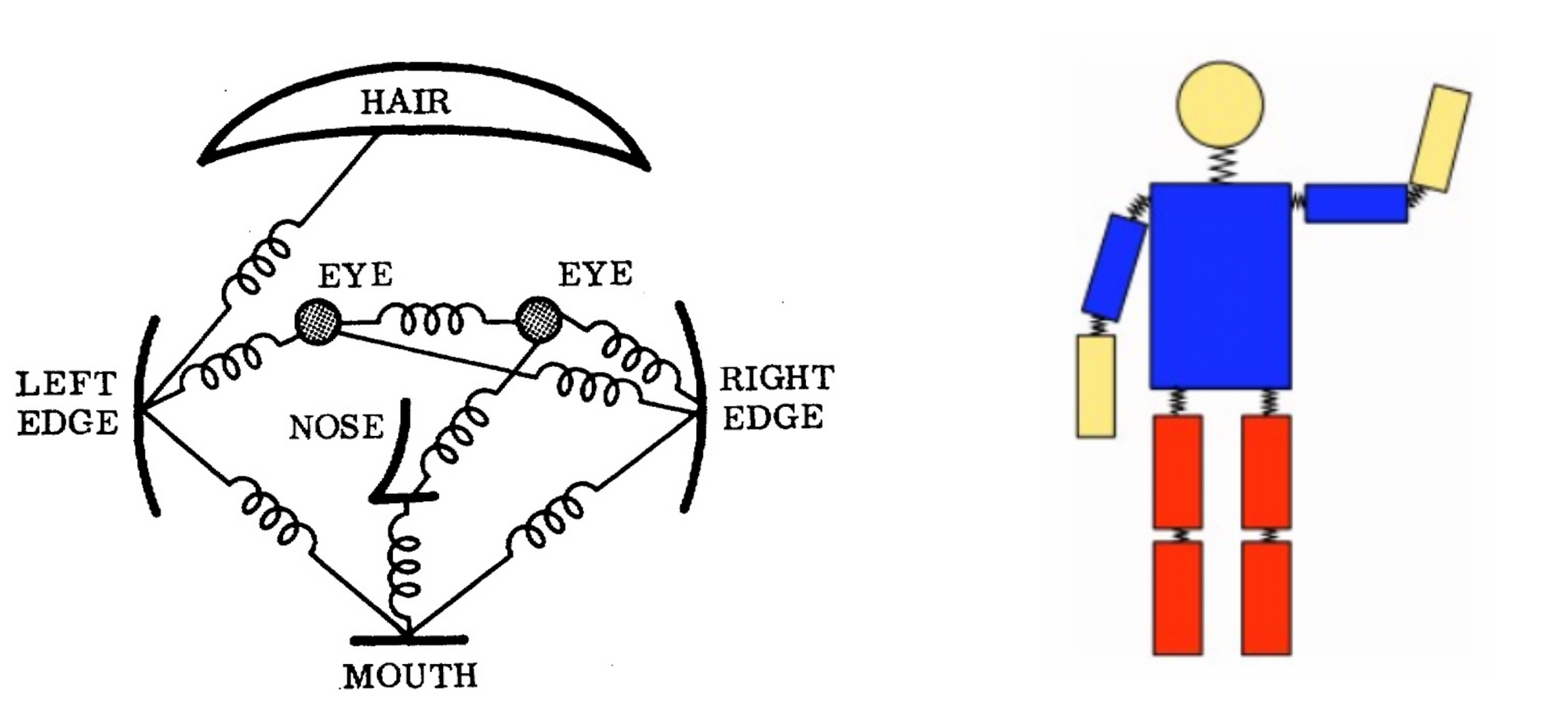
-
しかしながら、上記の方法は、常に決まったポーズを有するという制限を伴います(逆立ちや、後向きの姿勢だと正しく表現できない)。結果として、研究はモデルの表現力を豊かにすることに焦点を当てて行われました。
-
変形可能なパーツモデル: YangとRamananは、複雑なジョイント関係を表現するパーツの混合モデルを使用しました。Deformable part modelsには、グローバルテンプレートとパーツテンプレートがあります。これらのテンプレートは、オブジェクトを認識/検出するために画像内でマッチングされます。パーツベースのモデルは、関節を適切にモデリングできます。しかし、このモデルでは豊かな表現力は犠牲にされており、また、グローバルな文脈は考慮されていませんでした。
ディープラーニングベースのアプローチ
古典的パイプラインには上記のような限界がありましたが、CNNによりPose estimationの手法が大きく転換しました。Toshevらによる"DeepPose"の導入により、Human Pose Estimationの研究は古典的アプローチからディープラーニングへと移行し始めました。最近の姿勢推定システムの多くは、その主要な構成要素としてConvNetsを採用しており、お手製だった特徴量&グラフィカルモデルに取って代わっています。そして、標準的なベンチマークを大幅に改善しました。
次のセクションでは、GoogleのDeepPose(これは完全なリストではありませんが、私が感じている論文のリストは、カンファレンス毎の最も重要な進展/最も重要なモデルを示しています。)を手始めに、Human Pose Estimationの進展を示すいくつかの論文を時系列にまとめています。
本記事で紹介する論文リスト
1. DeepPose: Human Pose Estimation via Deep Neural Networks (CVPR’14) [arXiv]
DeepPoseは、人間の姿勢推定にディープラーニングを適用した最初の主要論文です。当時の最高記録を超え、既存モデルを上回りました。このアプローチでは、姿勢推定を体関節に対するCNNベースの回帰問題として定式化しました。また、カスケード式説明変数を使用して姿勢推定を改良しました。このアプローチの重要な点の1つは、全体の整合性を取るように姿勢推定を行った点です。つまり、特定のジョイントが非表示になっていても、ポーズが全体的に合理的であれば、そのジョイントを推定することができます。論文では、CNNがこのような推論を自然に提供し、良い結果を示したと主張しました。
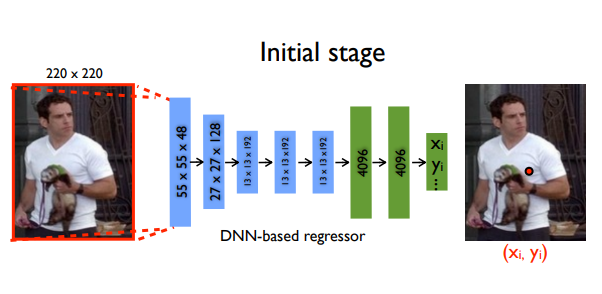
モデル概要
このモデルはAlexNetバックエンド(7層)と $2k$ 個のジョイント座標( $(x_i, y_i) * 2 $ for $i \in \lbrace 1, 2, ..., k \rbrace$ ただし、$k$はジョイント数)を出力する追加の最終レイヤから構成されています。
モデルは、回帰のためにL2損失を用いて訓練されます。
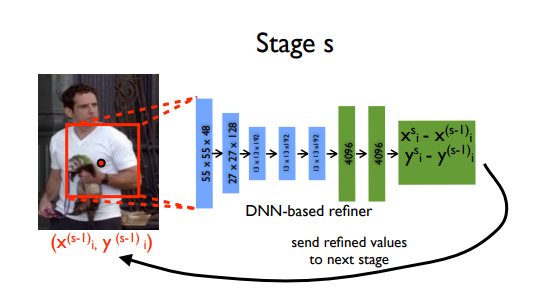
このモデルで提案された興味深いアイデアは、カスケード式説明変数を用いた予測の改良です。初期の粗い姿勢が洗練され、より良い推定値が得られます。画像は予測された関節の周りで切り取られ、次の段階に送られます。このようにして、次の説明変数としてより高解像度の画像を扱うことができ、最終的にはより高い精度をもたらすより細かいスケールのための特徴量を学習します。
結果
LSP(Leeds sports dataset)およびFLIC(Frames Labeled In Cinema)のデータセットに対してPCPが計算されました。PCPやPCKなどの一般的な評価指標の定義については、付録を参照してください。
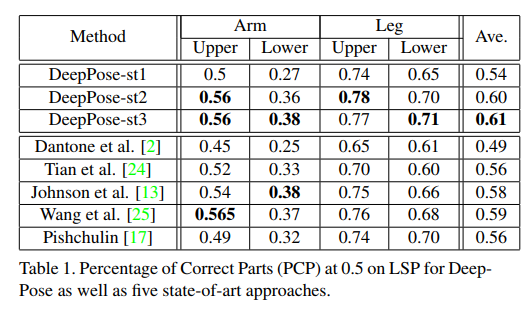
コメント
- 本論文では、人間の姿勢推定にディープラーニング(CNN)を適用し、この方向での研究の素晴らしいスタートを切りました。
- 学習の複雑さゆえに、汎化性能を弱めてしまったため、特定の領域での性能が低いです。
- 最近の手法は問題を$K$個のヒートマップ($W_0 \times H_0, \lbrace H_1, H_2, ..., H_k \rbrace$)を推定する問題に変換しています。ヒートマップ$H_k$は、$k$番目のキーポイントの位置を示します。次の論文は、この考え方を導入する上での基礎となる論文になりました。
2. Efficient Object Localization Using Convolutional Networks (CVPR’15) [arXiv]
このアプローチは、画像を複数の解像度バンクに同時並行で通しながら、様々なスケールで特徴量を同時に捉えることによって、ヒートマップを生成します。出力は、連続回帰ではなく個別のヒートマップです。ヒートマップは、各ピクセルでジョイントが発生する確率を予測します。この出力モデルは非常に成功しており、その後の多くの論文は、直接回帰ではなくヒートマップを予測しています。

モデル概要
マルチ解像度CNNアーキテクチャ(粗いヒートマップモデル)を用いて、スライディングウィンドウ検出器を実装し、粗いヒートマップを生成しました。
本論文の主なモチベーションは、初期モデルにおけるプーリングにより失われた空間精度を回復することです。これは、粗いヒートマップの位置推定結果を洗練する追加の 'pose refinement' ConvNetを使用して行います。ただし、モデルの標準カスケードとは異なり、既存の畳み込み特徴量を再利用します。これは、カスケードにおける訓練可能なパラメータの数を減らすだけでなく、粗いモデルと細かいモデルが一緒に訓練されるので、粗いヒートマップモデルの正則化器としても働きます。
基本的に、このモデルは、粗い位置推定のためのヒートマップベースのパーツモデルと、各ジョイントの指定された(x,y)位置で畳み込み特徴量をサンプリングして切り取るモジュール、およびファインチューニングのための追加の畳み込みモデルで構成されます。
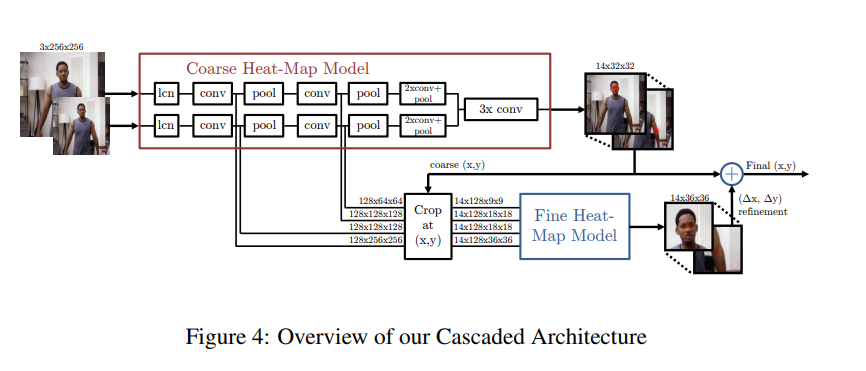
この方法の重要な特徴はConvNetとグラフィカルモデルの併用です。グラフィカルモデルは関節間の典型的な空間関係を学習します。
訓練
このモデルは、ターゲットとなるヒートマップへの予測ヒートマップの平均二乗誤差(MSE)を最小化することにより訓練されます。 (ターゲットは、ground-truthを中心とする一定分散(σ≒1.5画素)の2D Gaussianです。)
結果
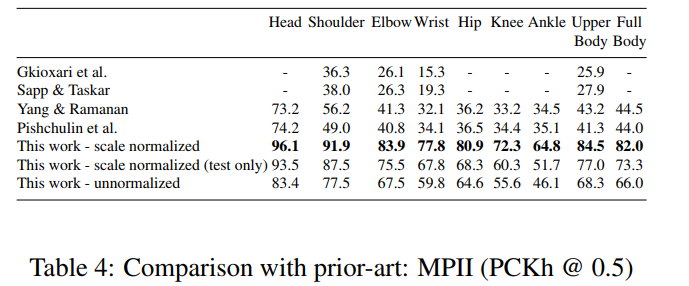
コメント
- 直接的な回帰よりもヒートマップの方が効果的
- CNNとグラフィカルモデルの併用
- しかしながら、これらの方法は構造モデリングを欠いています。人間の姿勢に関する空間は、体の各部分の比率、左右の対称性、相互貫通の制約、ジョイントの制限(例えば、肘は後ろには曲がらない)、物理的な接続性(例えば、手首は肘に堅く関連している)などにより、高度に構造化されています。この構造をモデル化することで、目に見えるキーポイントの特定が容易になり、隠れたキーポイントの推定が可能になります。次のいくつかの論文は独自の新しい方法でこれを扱っています。
3. Convolutional Pose Machines (CVPR’16) [arXiv] [code]
- これは"Pose machine"と呼ばれるものを使った面白い論文です。"Pose machine"は画像特徴計算モジュールとそれに続く予測モジュールから構成されます。Convolutional Pose Machinesは完全に差別化可能であり、その多段階アーキテクチャはEnd-to-endで訓練できます。これらは、implicit spatial modelを学習するための逐次予測フレームワークを提供し、人間の姿勢推定に対して非常に効果的に働きます。
- 本論文の主な動機の一つは、長距離での空間関係を学習することであり、これは、より大きな受容場を使用することによって達成できることを示しました。
モデルの概要
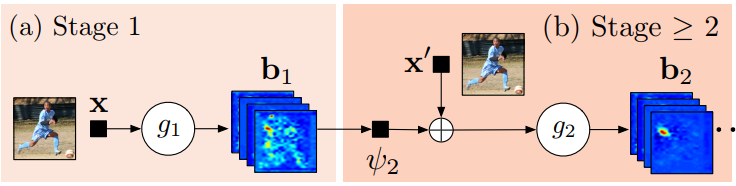
$g_1()$および$g_2()$はヒートマップ(論文では信頼性マップ)を予測します。上図は高レベルのビューです。Stage1は画像特徴計算モジュールで、Stage2は予測モジュールです。下図で、アーキテクチャの詳細を示します。受容場の大きさがどのように増大するかに注目しましょう。
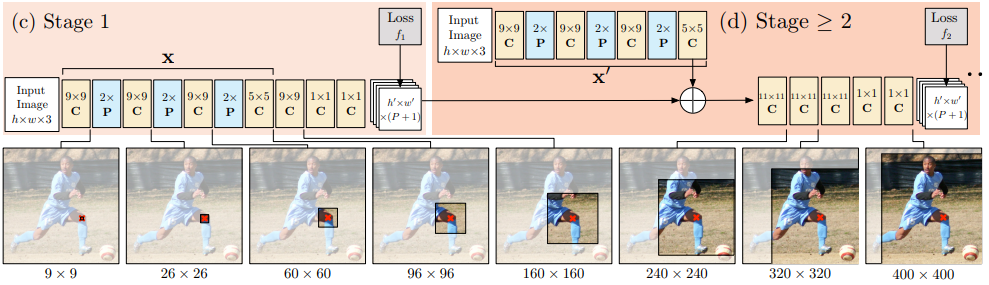
CPMは2つ以上のステージから成ることができ、ステージ数はハイパーパラメータです。(通常は3)。Stage1は固定され、Stage2以降はStage2の単なる反復です。Stage2は入力としてヒートマップと画像の証拠を取ります。入力ヒートマップは、次の段階のための空間の文脈を追加します。(論文で詳細に論じられています)
高レベルでは、CPMは、その後の段階を通じてヒートマップを洗練させていきます。
本論文では、多層構造のネットワークで一般的に見られる「勾配消失の問題」を回避するために、各ステージの後に中間監視を置きました。
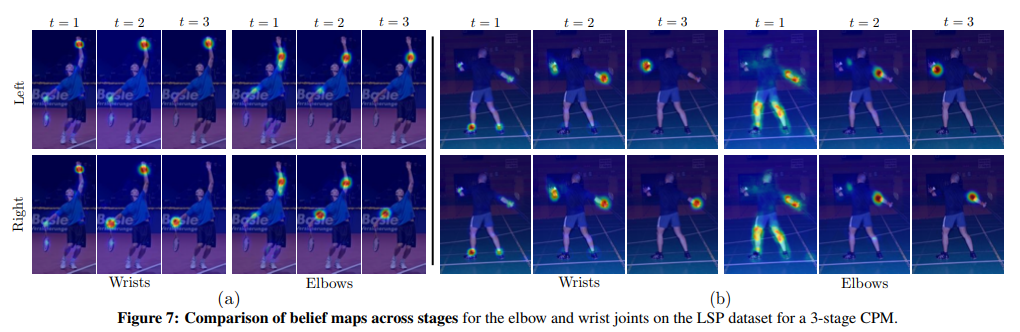
結果
- MPII: PCKh-0.5スコアは、当時の最先端記録より6.11%高い87.95%を達成し、足首に関して(最も困難な部分)は、PCKh-0.5スコアが当時の最先端記録より10.76%も高い78.28%だったことは注目に値します。
- LSP: 84.32%(MPIIトレーニングデータを追加すると90.5%)で最先端記録を達成しました。
コメント
- MPII、FLICおよびLSPデータセットのSOTA性能を示す新しいCPMフレームワークを導入しました。
4. Human Pose Estimation with Iterative Error Feedback (CVPR’16) [arXiv] [code]
これは非常に密度の高い論文であり、あまり多くを省かずに簡単に要約しようと試みました。全体的な作業は非常に単純で、現在の推定で何が間違っているのかを予測し、それを繰り返し修正します。著者の言葉を引用すると、出力を一度に直接予測する代わりに、誤差予測をフィードバックすることにより初期解を漸進的に変化させる自己修正モデルを使用しました。このプロセスは反復誤差フィードバック(Iterative Error Feedback:IEF)と呼ばれます。
モデルパイプラインの説明に移ります。
-
入力は、イメージ $I$ と前の出力 $y_{t-1}$ から構成されます。これは反復プロセスであり、同じ出力がステップごとにリファインされることに注意してください。
-
入力は、$I \oplus g(y_{t-1})$。ここで、$I$ は画像であり、$y_{t−1}$ は前回の出力です。
-
$f(x_t)$ は、補正量 $\varepsilon_t$ を出力し、これを現在の出力 $y_t$ に加算して、補正量を考慮した $y_{t+1}$ を生成します。
-
$g(y_{t+1})$ は $y_{t+1}$ の各キーポイントをヒートマップチャンネルに変換し、イメージ $I$ に重ねて、次のイテレーションの入力を形成できるようにします。この過程は、$\varepsilon_t$ の付加によってgroud-truthに近づくまで $T$ 回繰り返されます。
-
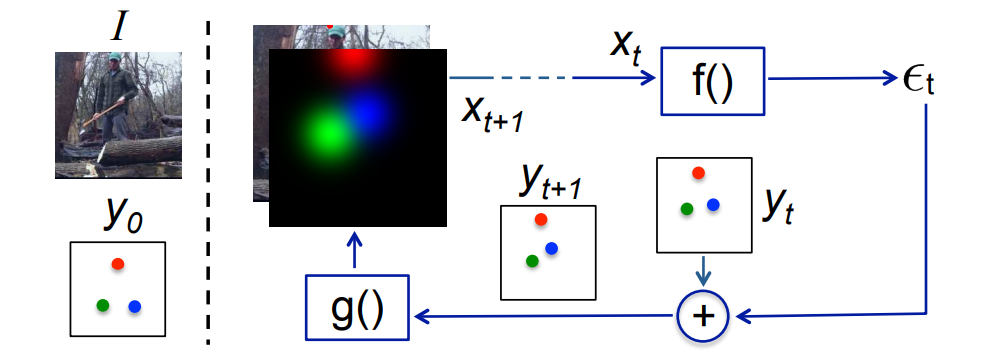
- 数学的には、
- $\varepsilon = f(x_t)$
- $y_{t+1} = y_t + \varepsilon$
- $x_{t+1} = I \oplus g(y_{t+1})$
- これを $T$ 回繰り返します。
- $f()$ と$g()$ は学習可能であり、$f()$ はCNNです。
- ここで特筆すべき重要な点は、ConvNet $f()$ は入力として $I \oplus g(y_{t+1})$ を受け取るため、入出力空間全体で特徴量を学習できるので、超クールという点です。
- パラメータ $Θ_g$および$Θ_f$は、次の方程式を最適化することにより学習されます。
- $\min_{Θ_f, Θ_g} \Sigma _{t=1}^T h\bigl(\varepsilon _t, e(y,y _t)\bigr) $
- ここで、$\varepsilon _t$ と $e(y、y_t)$ はそれぞれ、推定された補正とターゲットの補正です。関数hは、二次損失のような距離の尺度です。$T$は、モデルによって実行される補正のイテレーションの数です。
例

ご覧のように、推定姿勢は補正ステップが増えるに連れて、リファインされています。
結果
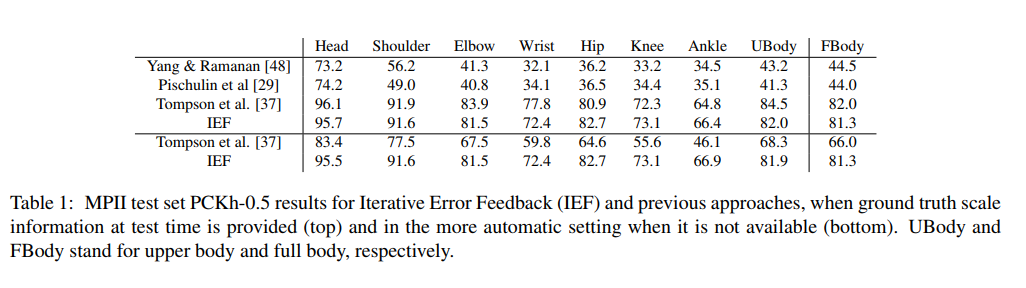
コメント
優れた新規性を導入し、非常に上手くいったエレガントな論文です。
5. Stacked Hourglass Networks for Human Pose Estimation (ECCV’16) [arXiv] [code]
斬新で直感的なアーキテクチャを導入し、以前のすべての方法を打ち負かした画期的な論文です。このネットワークは、砂時計のようなプーリング層とアップサンプリング層のステップで構成されており、これらが積み重ねられているため、スタック型砂時計ネットワークと呼ばれています。砂時計の設計は、あらゆるスケールで情報を取得するニーズから来ています。顔や手のような特徴を識別するためには局所的証拠が不可欠ですが、最終的な姿勢推定には大域的な文脈が必要です。人の向き、手足の配置、隣接する関節の関係などは、画像内のさまざまなスケールで最もよく認識される多くの手がかりになります。(解像度が低いほど、より高いレベルの機能と大域的文脈が得られます。)
ネットワークは、ボトムアップ、トップダウンのプロセスを繰り返し実行し、中間的な監視を行います。
- ボトムアップ処理(高解像度から低解像度へ)
- トップダウン処理(低解像度から高解像度へ)
このネットワークは、各解像度で空間情報を保持するための「スキップ接続」を使用し、アップサンプリングのときに未処理の空間情報を渡します。
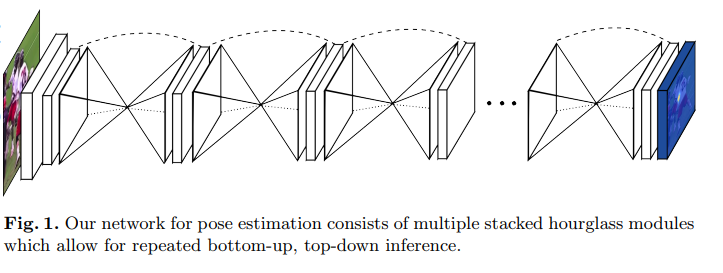

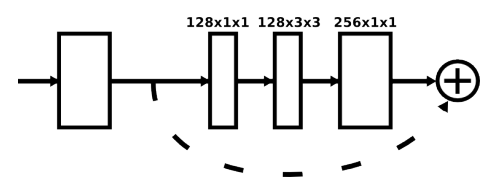
各ボックスは次の図のような残差モジュールです。
中間監督
各砂時計ステージの予測に中間監視を適用した。最終的な砂時計の予測だけでなく、スタック内の各砂時計の予測も監視されます。
結果
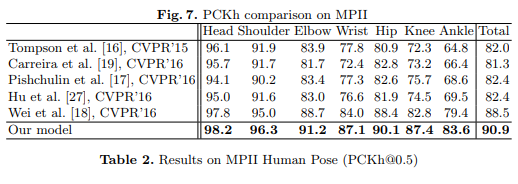
なぜこんなに上手くいくのか
砂時計構造であらゆるスケールの情報を得ることで、グローバルおよびローカルの情報を完全に取得できます。
6. Simple Baselines for Human Pose Estimation and Tracking (ECCV’18) [paper] [code]
これまでのアプローチは非常に上手くいきますが、複雑です。本論文は、シンプルなメソッドがどの程度優れているかという疑問に答えており、COCOに対しmAP73.7%の最先端記録を達成しました。
このネットワーク構造は非常に単純で、ResNet+いくつかの逆畳み込み層で構成されます。(ヒートマップを推定する最も簡単な方法)
砂時計ネットワークでは、アップサンプリングを使用してフィーチャマップの解像度を上げ、畳み込みパラメータを他のブロックに配置しますが、この方法では、それらを非常に簡単な方法で逆畳み込み層として結合します。このような単純なアーキテクチャーが、各解像度の情報を保持するスキップ接続を持つアーキテクチャーよりも優れたパフォーマンスを発揮することは、非常に驚きました。
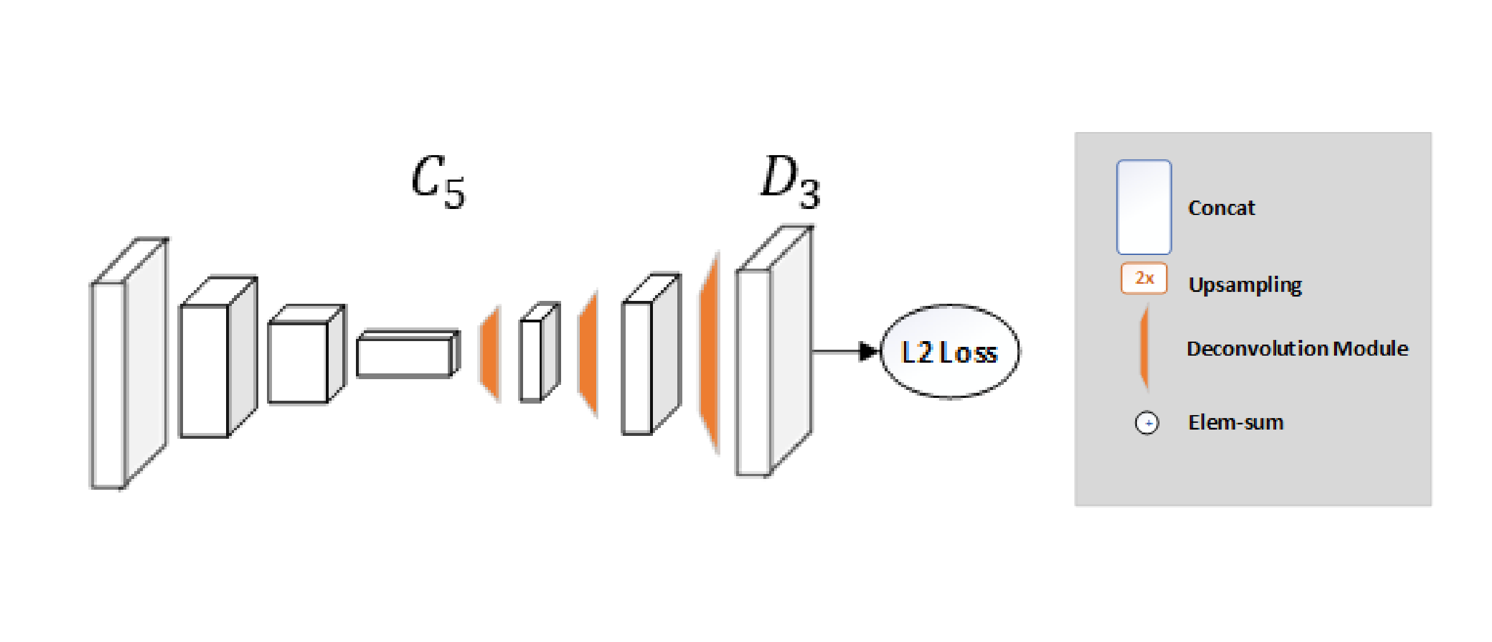
平均二乗誤差(MSE)は、予測ヒートマップとターゲットヒートマップとの間の損失として使用されます。関節 $k$ のためのターゲットのヒートマップ $H_k$ は、$k$ 番目の関節のground-truthを中心とするの2D Gaussian(σ≒1画素)を適用することによって生成されます。
結果
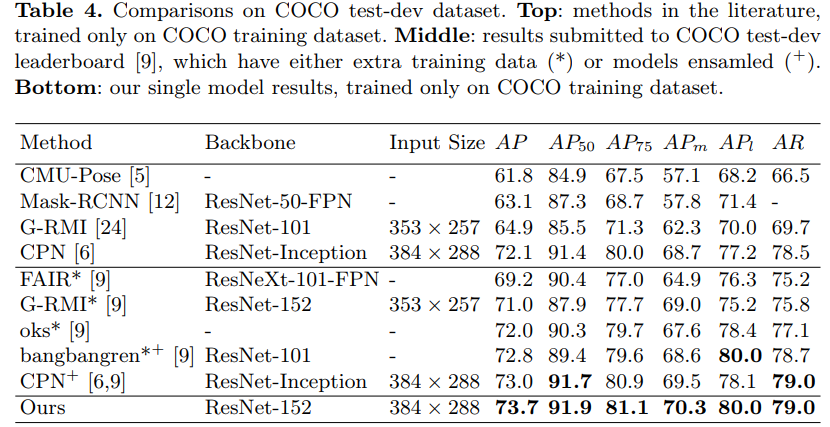
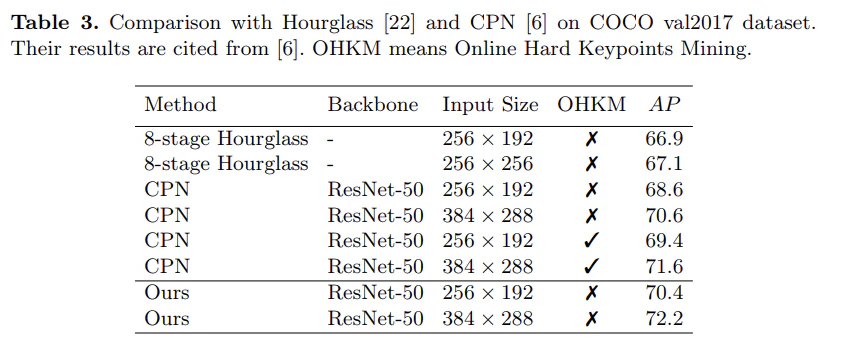
7. Deep High-Resolution Representation Learning for Human Pose Estimation 【HRNet】 (CVPR’19) [arXiv] [code]
HRNet(高解像度ネットワーク)モデルは、COCOデータセットにおけるキーポイント検出、多人数ポーズ推定およびポーズ推定タスクに関する既存のすべての方法より優れており、最新のモデルです。HRNetは非常に単純なアイデアに従います。これまでの論文の大部分は、高→低→高分解能表現でした。HRNetは、プロセス全体を通して高解像度の表現を維持しており、これが非常にうまく機能します。
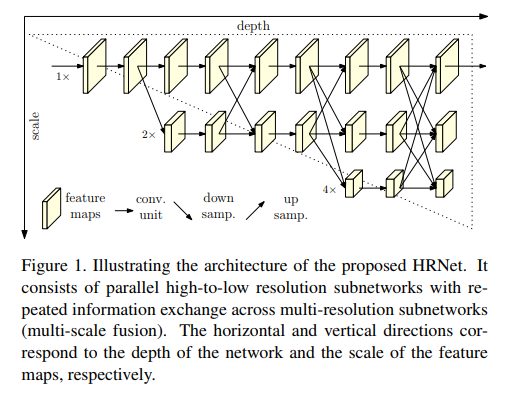
このアーキテクチャは、第一段階として高分解能サブネットワークから始まり、高〜低分解能サブネットワークを一つずつ徐々に付加し、より多くの段階を形成し、並列にマルチ解像度サブネットワークを接続します。
プロセス全体を通して並列マルチ解像度サブネットワークを介して情報を交換することにより、反復マルチスケール融合を行いました。
もう一つの長所は、このアーキテクチャはStacked Hourglassとは異なり、中間的なヒートマップ監視を行わないことです。
ヒートマップは、単純なベースラインと同様に、MSE損失を使用して回帰されます。
結果
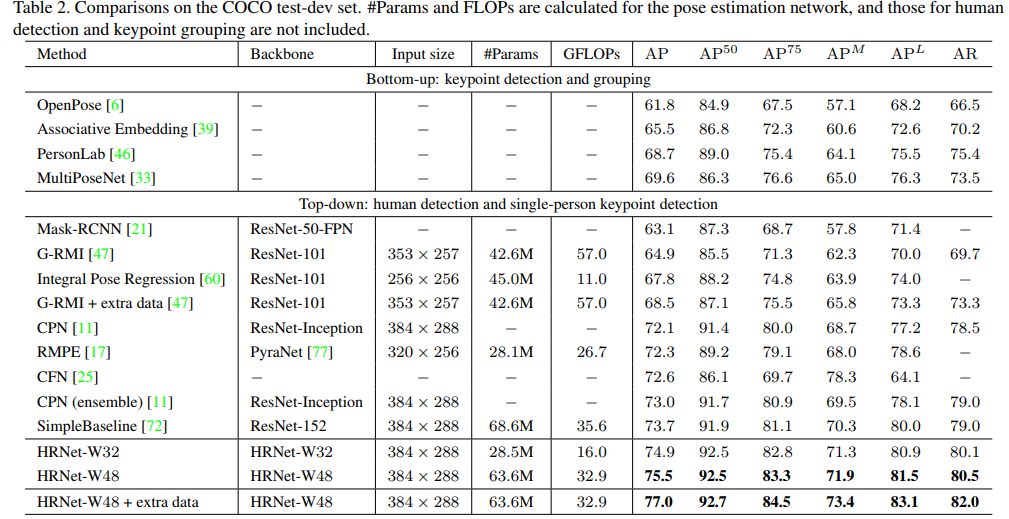
私が興味を持っている他の論文をいくつか紹介しましょう。
- Flowing ConvNets for Human Pose Estimation in Videos (ICCV’15) [arXiv]
- Learning Feature Pyramids for Human Pose Estimation (ICCV’17) [arXiv] [code]
- Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields (CVPR’17) [arXiv] [code]: 非常に人気のあるリアルタイムの多人数ポーズ推定(OpenPoseの方がよく知られている)
- Multi-Context Attention for Human Pose Estimation (CVPR’17) [arXiv] [code]
- Cascaded Pyramid Network for Multi-Person Pose Estimation (CVPR’18) [arXiv] [code]
付録
共通の評価基準
評価基準は、人間の姿勢推定モデルの性能を測定するために必要です。
-
正解パーツの割合(Percentage of Correct Parts - PCP): 予測された2つの関節位置と実際の四肢関節位置との距離が四肢の長さの半分(一般にPCP@0.5と表記される)未満の場合、四肢が検出されたとみなされます(正しい部分)。
-
四肢の検出率を測定します。短所は、四肢が短いほど閾値が小さくなるため、四肢が短いほど不利になることです。
-
PCPが高いほど、モデルの品質が向上します。
-
-
正しいキーポイントの割合(Percentage of Correct Key-points - PCK): 予測されたジョイントと実際のジョイントとの距離が特定のしきい値以内であれば、検出されたジョイントは正しいと見なされます。しきい値は次のいずれかです。
- PCKh@0.5は、しきい値が頭部のボーンリンクの50%のときです。
- PCK@0.2は、予測されたジョイントと実際のジョイントの間の距離<0.2*胴の直径
- 150mmをしきい値とすることもあります。
- 短い四肢は胴体と頭部のボーンリンクが小さいため、短い四肢の問題が軽減されます。
- PCKは2Dおよび3D(PCK3D)に使用されます。PCKは高いほど良いです。
-
検出されたジョイントの割合(Percentage of Detected Joints - PDJ):予測されたジョイントと実際のジョイントの間の距離が胴の直径の一定の割合以内である場合、検出されたジョイントは正しいと見なされます。PDJ@0.2=予測されたジョイントと実際のジョイントの間の距離<0.2*胴の直径。
-
Object Keypoint Similarity(OKS)ベースのmAP:
- COCOキーポイントチャレンジで一般的に使用されます。
- OKS =$$\frac{∑ _i \exp(−d ^2 _i / 2s ^2 k ^2 _i)δ(v _i>0)}{∑ _i δ(v _i >0)}$$
- $d_i$ は検出されたキーポイントとそれに対応するground-truthのユークリッド距離、$v_i$はgroud-truthの可視性フラグ、$s$ はオブジェクトスケール、$k$ は減衰を制御するキーポイントごとの定数です。
- 簡単に言えば、OKSはオブジェクト検出でのIoUの役割と同じ役割を果たします。予測点とground-truth点との距離を人間のスケールで正規化して計算されます。【詳細】一般的には、標準的な平均精度と再現スコアは次のように報告されている:$AP^{50}$(AP at OKS = 0.50)、$AP^{75}$(AP at OKS = 0.75)、$AP$(10個のAPスコア平均 OKS = 0.50, 0.55, ..., 0.90, 0.95)、$AP^M$(中サイズのオブジェクトに対するスコア)、$AP^L$(大サイズのオブジェクトに対するスコア)、$AR$(平均リコール) at OKS = 0.50, 0.55, ..., 0.90, 0.95