経緯
今まで物体検出といえばRGB画像を入力とした手法が主流でした。ですが、realsenseなどのdepthデータも取れるデバイスが割と安価に手に入るようになったり、depth estimation(RGB画像から深度情報を予測)の精度が上がってきたなどの要因により、3D object detectionの研究が盛んになっています。今回は既存の2次元の物体検出フレームワークを3次元対応にしてみたときの手順を共有します。
tkDNNとは
今回自分が3次元対応させたのはtkDNNという、darknet YOLOをTensorRTを使って高速化させたフレームワークです。tkDNNでの手順を紹介しますが、他のフレームワークでもやることはほとんど同じだと思います。
3次元対応のイメージ
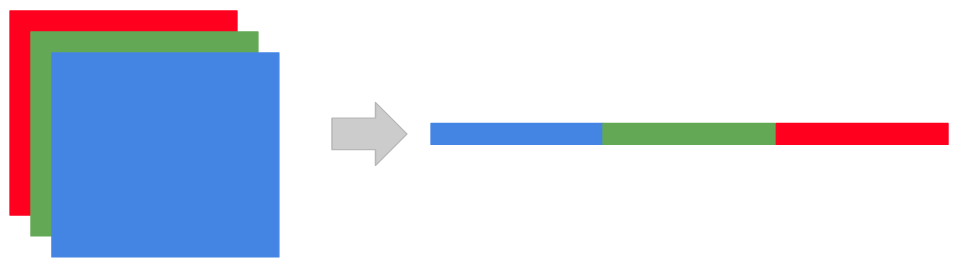
tkDNNやdarknetでのRGB画像の使い方のイメージは下のような感じです。BGRでそれぞれのチャネルごとに0~255までの数値を保持していますが、DNNに入れる前には1次元配列に変形します。このとき0~255を正規化して0~1の数値にします。
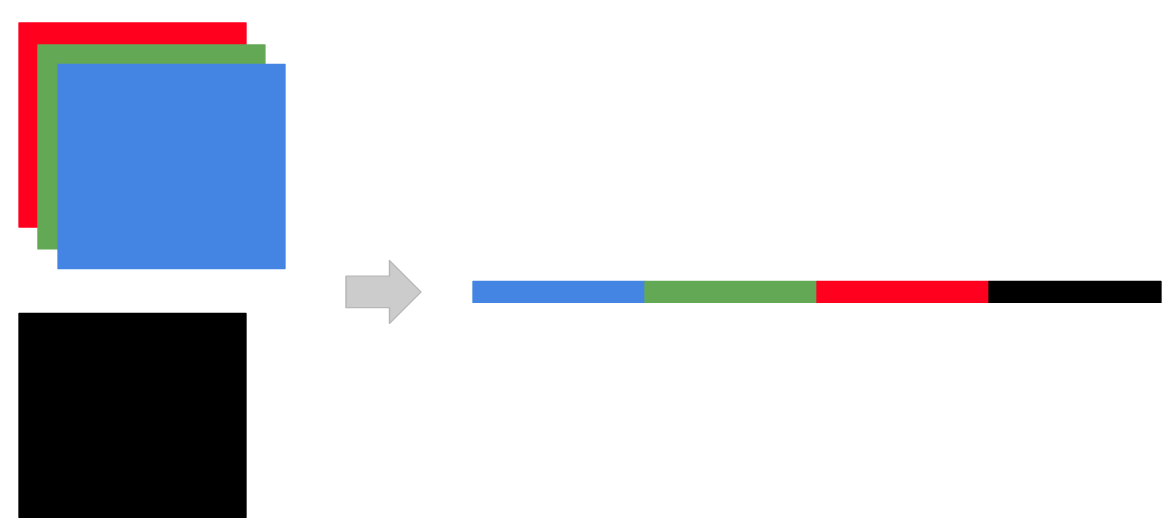
なので、BGRに加えてdepthも加えたいときは下のようなイメージになります。黒がdepthデータを表しています。
コード変更
具体的にどのようにコードを変更していくか解説します。大きく分けると2つのファイルを変更します。tkDNNの推論時にはDetectionNN.hのupdate関数がまず呼ばれます。なので、引数としてdepthデータを受け取れるように変更します。それから画像のリサイズなどの前処理を行うpreprocess関数にdepthデータを渡します。
// depthデータ(depth_frames)も受けとる
void update(std::vector<cv::Mat>& rgb_frames, std::vector<cv::Mat>& depth_frames, const int cur_batches=1, bool save_times=false, std::ofstream *times=nullptr, const bool mAP=false){
~~省略~~
if(TKDNN_VERBOSE) printCenteredTitle(" TENSORRT detection ", '=', 30);
{
TKDNN_TSTART
for(int bi=0; bi<cur_batches;++bi){
if(!frames[bi].data)
FatalError("No image data feed to detection");
originalSize.push_back(frames[bi].size());
// 前処理にdepthデータを渡す
preprocess(rgb_frames[bi], depth_frames[bi], bi);
}
TKDNN_TSTOP
if(save_times) *times<<t_ns<<";";
}
~~省略~~
}
次にyolo用の推論処理が書いてあるYolo3Detection.cppを変更します。まずrgbとdepthデータをそれぞれ正規化します。今回はdepthが16bitなので65535(2の16乗-1)で正規化しています。その後、bgrdという配列にb,g,r,dの順で格納しています。これにより、RGBデータとdepthデータを結合することが出来ました。
void Yolo3Detection::preprocess(cv::Mat &rgb_frame, cv::Mat &depth_frame, const int bi){
~~省略~~
# else
// 画像サイズをDNNの入力サイズに変更
cv::resize(rgb_frame, rgb_frame, cv::Size(netRT->input_dim.w, netRT->input_dim.h));
cv::resize(depth_frame, depth_frame, cv::Size(netRT->input_dim.w, netRT->input_dim.h));
// 32float型にして0~1に正規化
rgb_frame.convertTo(imagePreproc, CV_32FC3, 1/255.0);
depth_frame.convertTo(depthPreproc, CV_32FC1, 1/65535.0);
//split channels & merge depth
cv::split(imagePreproc,bgr);
bgrd[0] = bgr[0];
bgrd[1] = bgr[1];
bgrd[2] = bgr[2];
bgrd[3] = depthPreproc;
//write channels
for(int i=0; i<netRT->input_dim.c; i++) {
int idx = i*imagePreproc.rows*imagePreproc.cols;
int ch = netRT->input_dim.c-1 -i;
memcpy((void*)&input[idx + netRT->input_dim.tot()*bi], (void*)bgrd[ch].data, imagePreproc.rows*imagePreproc.cols*sizeof(dnnType));
}
checkCuda(cudaMemcpyAsync(input_d + netRT->input_dim.tot()*bi, input + netRT->input_dim.tot()*bi, netRT->input_dim.tot()*sizeof(dnnType), cudaMemcpyHostToDevice, netRT->stream));
# endif
}
変数の宣言などの細かい変更点は省略しましたが、大まかにはこのような感じでdepth対応が出来ます。
まとめ
tkDNNを作った人、めっちゃ優しい人です。
間違いや質問、ご意見等ありましたらお気軽にコメントください。頑張って答えますので(笑)。