経緯
最近、業務で機械学習モデルを高速化させる必要があり、色々調査した結果、TensorRTを使うことにしました。ただ、TensorRTの概要を理解するのに少し時間がかかったので、自分なりのTensorRTのイメージをまとめてみました。
この記事の対象
これからTensorRTを使ってみようとしている方に向けて書いています。TensorRTって何者なんだろうって思っている方がざっくりとした理解が得られえばいいと思っています。TensorRTの詳しい機能や使い方の詳細は、公式やこちらの記事を見たほうがいいと思います。
TensorRTがやっていること
TensorRTがやっていることはたくさんありますが、大きく分けると推論エンジンの生成と推論実行があります。なので、今回はその2つについて説明します。
1. 推論エンジンの生成
TensorRTは高速化を可能にするSDKですが、高速化を可能にしているのはTensorRT用に作成する推論エンジンです。最近のネットワークは巨大化しているので、マシンの処理速度が遅くなったり、メモリ使用量が多くなるという問題が発生しています。そこでTensorRTは、その問題に対して下の図のサークル状に記述されている技術を用いて対応しています。ノードを結合して最適化したり、量子化してメモリ使用量を減らしたりしています。
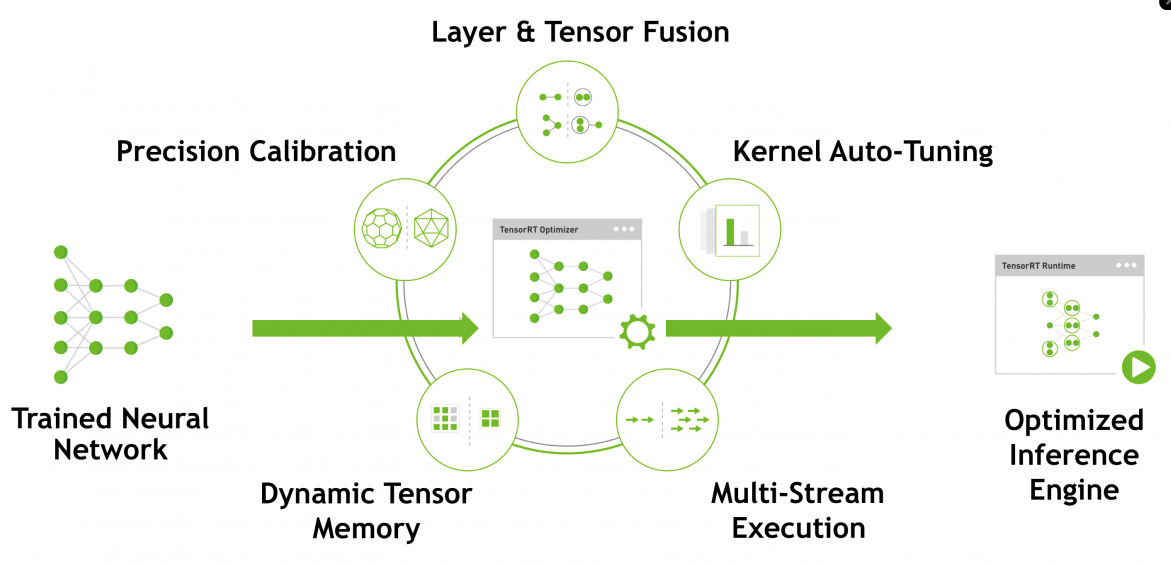
自分はyoloを使うことが多いので、yoloを例に取って説明します。yolov4の学習が終わるとyolov4.weightsのような学習済みモデルが作成されます。この中身は、それぞれの層の膨大なノードの数値などが保存されています。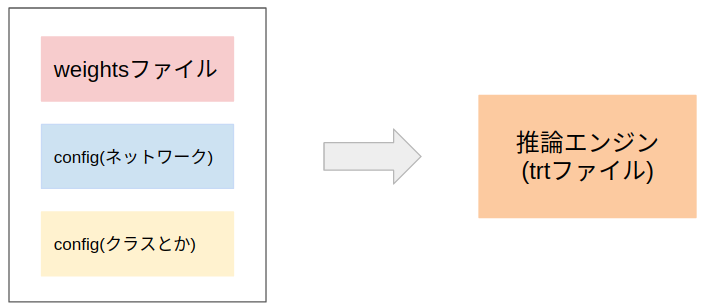
yoloはweightsファイルに加えて、ネットワークの定義(何層目にConv層、その後はBN層とか)をしているconfigファイルと、推論するクラス名とかを記述してるconfigファイルを読み込んで推論します。これらをまとめて、かつネットワークを様々な工夫により高速化したものが推論エンジン(trtファイル)です。推論エンジンの作成にはだいたい5分ぐらいかかるので、推論実行前にあらかじめ作成しておいた方がいいです。ちなみにdarknet yoloのweightsファイルのtrtファイルへの変換はこちらのリポジトリでできます。
2. 推論
推論実行時には、まず作成しておいたtrtファイルから高速化したネットワークを復元します。あとは高速化しないときと同じで、入力の画像データ等を引数として、ネットワークに渡すと推論してくれます。
まとめ
今回は、TensorRTに対する自分のイメージをまとめてみました。エッジデバイスだけでなく、デバイスの可能性を広げるための高速化ソフトウェアまで作っているNVIDIAはやっぱりすごい!
間違いや質問、ご意見等ありましたらお気軽にコメントください。頑張って答えますので(笑)。