2020.06.10 更新
配列が南北反転してしまっていたため取り急ぎの修正を追加。
はじめに
表題に記載のデータは、こちらのサイトで配布されているもの。
日本における非常に詳細かつ精度の高い標高データ(DEM)が手に入る。
ダウンロードされるのは、総務省統計局にて定義されている2次区画地域メッシュごとのzip形式ファイル。その中には、xml形式の標高データが入っている。地域メッシュについては後述する。
コードは本記事の最後にある。用例は下記の通り。
(ファイル名もメタ情報として使用しているため、ダウンロードしたままのものに適用してください)
python zdem2tif.py FG-GML-1234-56-DEM10B.zip FG-GML-6543-21-DEM5A.zip ...
各zipファイル(=2次区画地域メッシュ)ごとに1枚のgeotiff画像が出力される。
5m、10mのいずれの解像度にも対応。
python3系で動作確認をしています。gdalパッケージがインストールされている必要があります。
この度は、こちらのサイトに置かれていたコードを大いに参考にした。しかし、そのままではデータ欠損のあるケースにてバグが生じるため、修正を行ったのが本コード。
他にもいろいろとツールはあるようだが、コマンド上で実行可能、英語で書かれているため外国人にも共有が可能、zipの展開が不要、などの理由から今回のコードの作成に至った。
また、投稿後に気付いたが、qiitaでもすでに基盤地図情報とpythonに関する記事がある。ファイル形式の説明等はこちらのほうがより詳しい。
地域メッシュについて
詳細な定義はこの文書で説明されている。
空間解像度に応じて、1次から3次までの区画で地域メッシュが定義されている。
1次メッシュは4桁、2次メッシュはそれに加えて2桁、3次メッシュはさらにそれに2桁を加えた区画コードが割り当てられている。
区画コードの数字を用いて、区画の四隅の緯度経度がわかるようになっている。
ソースコードの説明
今後、配布されるデータの仕様等に変更があるかもしれないのと、筆者が確認していない地域において非対応な可能性も捨てきれないため、簡単にコードの説明を行う。
全体の流れ(convert)は、
- zipファイル名から地域メッシュ情報、DEM解像度の取得
- 出力ファイルの配列を定義(ここまで
DEMOutArray、mesh_info_from_zipname) - zipファイル内のxmlファイルについてループ(
for filename in filelist)- xmlファイルから必要な情報を取得(
XMLContents、read_xml) - xmlファイル単位でDEMの配列を生成(
DEMInArray) - 出力用配列を上書き(
update_raster)
- xmlファイルから必要な情報を取得(
- Tiff形式で保存(
save_raster)
zipファイル名から地域メッシュ情報、DEM解像度の取得
4桁の1次区画コード、さらに2桁の2次区画コードを読み取って、四隅の緯度経度を算出。
さらに、ファイル名にDEM5Xと書かれているか、DEM10Xと書かれているかで解像度を解釈。
それぞれの解像度ごとに、一つのxmlファイルの配列サイズなどを決め打ちしている(例えば、10mDEMの場合は、zip内にxmlが一つしかないことを想定している)。
出力ファイルの配列を定義
2次区画ひとつ分のサイズで事前に作成しておく。
5mDEMの場合、一つのzip内(2次区画)に最大で10×10つのxml(3次区画)が入っていることを想定している。しかし、観測がされていない地域も多いようで、10つほどしかxmlが存在しないケースがある。
xmlが存在しない領域に該当する場所には、-9999.の外れ値を使用した。
zipファイル内のxmlファイルについてループ
zipfileというデフォルトで入っているモジュールを初めて知った。
これを用いることで、いちいち解凍せずにzip内のファイルを読むことができる。
xmlファイルから必要な情報を取得
5mDEMの場合、ファイル名に記載された3次区画コードの下2桁を読み取り、出力配列内での挿入位置を決定。10mDEMの場合、先述の通り、そもそも3次区画コードの記載がなく、1つしかxmlがないことを想定している。
必要な情報を、とりあえずテキスト型で取得。xml内のタグのルールなどはコードにある通りに想定されている。ルールが異なるxmlを読ませればすぐバグとして現れるはず。
xmlファイル単位でDEMの配列を生成
xmlファイルに記載の情報を用いて配列を生成する。
ファイル仕様書に、DEMデータに関する定義の記載がある。それによると、ピクセルごとの土地区分は{地表面、表層面、海水面、内水面、データなし、その他}のいずれかであり、値が未定義の場所については-9999の数字を入れている。
もともと参照したコードでは、「地表面」か否かでDEM情報の取得を行っているものの、本コードでは、xmlにおけるDEMの値が-9999か否かで分けている(「その他」で示される地域にDEM値が存在したため。「その他」としている理由は不明)。
DEM未定義の場所については、外れ値-1を適用し、先述のxmlファイルがそもそもないケースと外れ値の使用を分けた。
出力用配列を上書き
配列の向きに関し、緯度方向が北向きで定義されていることを想定している。xmlから得られるデータでgml:sequenceRuleというものがあり、そこで'+x-y'と書かれていることが、その裏付けとなっている。ここがもし'+x+y'などとなっていれば、おそらく南向きのなのだが、そのあたりの条件分けなどは一切行っていない。
Tiff形式で保存
特にいうことはなし。
出力されたtiffの描画
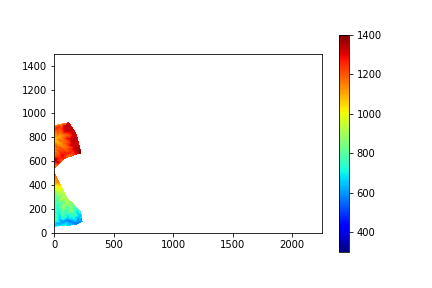
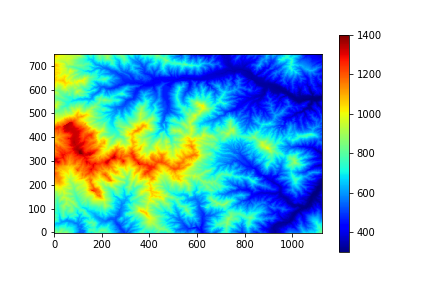
同じ2次区画地域を対象に、上が5mDEM、下が10mDEMでダウンロードしたファイルを変換したもの(軸の値などほぼ無編集)。負の値にはマスクをかけている。地域によるものの、それぞれの解像度におけるデータの存在率が異なることがわかる。
ダウンロードする前からわかればうれしいのだが、どこかに情報は落ちていないだろうか。。。
ソースコード全体
最後にコード全体です。
import os
import sys
import zipfile
import numpy as np
import xml.etree.ElementTree as et
import osgeo.gdal
import osgeo.osr
class XMLContents(object):
def __init__(self):
self.ns = {
'ns': 'http://fgd.gsi.go.jp/spec/2008/FGD_GMLSchema',
'gml': 'http://www.opengis.net/gml/3.2',
'xsi': 'http://www.w3.org/2001/XMLSchema-instance',
'xlink': 'http://www.w3.org/1999/xlink'
}
def read_xml(self, zf, filename, dem_mode):
if dem_mode == 'DEM10':
self.posix = 0
self.posiy = 0
elif dem_mode == 'DEM5':
_split = os.path.basename(filename).split('-')
self.posix = int(_split[4][1])
self.posiy = int(_split[4][0])
with zf.open(filename, 'r') as file:
self.text = file.read().decode('utf_8')
self.root = et.fromstring(self.text)
self.dem = self.root.find('ns:DEM', self.ns)
self.coverage = self.dem.find('ns:coverage', self.ns)
self.envelope = self.coverage.find(
'gml:boundedBy//gml:Envelope', self.ns)
self.lower = self.envelope.find('gml:lowerCorner', self.ns).text
self.upper = self.envelope.find('gml:upperCorner', self.ns).text
self.grid = self.coverage.find(
'gml:gridDomain//gml:Grid//gml:limits//gml:GridEnvelope', self.ns)
self.low = self.grid.find('gml:low', self.ns).text
self.high = self.grid.find('gml:high', self.ns).text
self.tuplelist = self.coverage.find(
'gml:rangeSet//gml:DataBlock//gml:tupleList', self.ns).text
self.gridfunc = self.coverage.find(
'gml:coverageFunction//gml:GridFunction', self.ns)
self.rule = self.gridfunc.find('gml:sequenceRule', self.ns)
self.start = self.gridfunc.find('gml:startPoint', self.ns).text
if self.rule.attrib['order'] != '+x-y':
print('warning sequence order not +x-y')
if self.rule.text != 'Linear':
print('warning sequence rule not Linear')
file.close()
class DEMInArray(object):
def __init__(self, contents):
self._noValue = -1.
self.llat, self.llon = np.array(
contents.lower.split(' '), dtype=np.float64)
self.ulat, self.ulon = np.array(
contents.upper.split(' '), dtype=np.float64)
self.lowx, self.lowy = np.array(
contents.low.split(' '), dtype=np.int)
self.highx, self.highy = np.array(
contents.high.split(' '), dtype=np.int)
self.sizex, self.sizey = self.get_size()
self.x_init, self.y_init = np.array(
contents.start.split(' '), dtype=np.int)
self.datapoints = contents.tuplelist.splitlines()
self.raster = self.get_raster()
def get_size(self):
sizex = self.highx - self.lowx + 1
sizey = self.highy - self.lowy + 1
return sizex, sizey
def get_raster(self):
_x, _y = self.x_init, self.y_init
raster = np.zeros([self.sizey, self.sizex])
raster.fill(self._noValue)
for dp in self.datapoints:
if _y > self.highy:
print('DEM datapoints are unexpectedly too long')
break
s = dp.split(',')
if len(s) == 1:
continue
desc, value = s[0], np.float64(s[1])
# if desc == '地表面':
raster[_y, _x] = value if value > -9998 else self._noValue
_x += 1
if _x > self.highx:
_x = 0
_y += 1
return raster
class DEMOutArray(object):
def __init__(self):
self._fillValue = -9999.
def initialize_raster(self):
raster = np.zeros([self.sizey, self.sizex])
raster.fill(self._fillValue)
return raster
def get_trans(self):
# +x-y
return [self.llon, self.resx, 0, self.ulat, 0, -self.resy]
def update_raster(self, tile, posiy, posix):
xmin = posix * tile.shape[1]
ymin = posiy * tile.shape[0]
xmax = xmin + tile.shape[1]
ymax = ymin + tile.shape[0]
self.raster[ymin:ymax, xmin:xmax] = tile[::-1]
def get_size(self):
sizex = (self.highx - self.lowx + 1) * self.tilex
sizey = (self.highy - self.lowy + 1) * self.tiley
return sizex, sizey
def mesh_info_from_zipname(self, zipname):
'''
Ref: Table 4 of https://www.stat.go.jp/data/mesh/pdf/gaiyo1.pdf
'''
_split = os.path.basename(zipname).split('-')
_lat1 = int(_split[2][:2])
_lon1 = int(_split[2][2:])
_lat2 = int(_split[3][0])
_lon2 = int(_split[3][1])
self.llat = _lat1 * 0.66666666666 + _lat2 * 0.08333333333
self.llon = _lon1 + 100. + _lon2 * 0.125
self.ulat = self.llat + 0.08333333333
self.ulon = self.llon + 0.125
if _split[4][:5] == 'DEM10':
self.mode = 'DEM10'
self.tilex, self.tiley = 1, 1
self.lowx, self.lowy = 0, 0
self.highx, self.highy = 1124, 749
self.sizex, self.sizey = self.get_size()
self.resx, self.resy = 1.1111111111e-04, 1.1111111111e-04
elif _split[4][:4] == 'DEM5':
self.mode = 'DEM5'
self.tilex, self.tiley = 10, 10
self.lowx, self.lowy = 0, 0
self.highx, self.highy = 224, 149
self.sizex, self.sizey = self.get_size()
self.resx, self.resy = 5.5555555555e-05, 5.5555555555e-05
else:
raise ValueError('Unexpected definition of DEM:', _split[4])
self.raster = self.initialize_raster()
def save_raster(self, out_filename):
trans = self.get_trans()
srs = osgeo.osr.SpatialReference()
srs.ImportFromEPSG(4612)
driver = osgeo.gdal.GetDriverByName('GTiff')
output = driver.Create(out_filename, self.sizex, self.sizey,
1, osgeo.gdal.GDT_Float32)
# output.GetRasterBand(1).WriteArray(self.raster) <- 修正@2020.06.10
output.GetRasterBand(1).WriteArray(self.raster[::-1])
output.GetRasterBand(1).SetNoDataValue(self._fillValue)
output.SetGeoTransform(trans)
output.SetProjection(srs.ExportToWkt())
output.FlushCache()
def convert(in_filename, out_filename):
output_array = DEMOutArray()
output_array.mesh_info_from_zipname(in_filename)
dem_mode = output_array.mode
with zipfile.ZipFile(in_filename, 'r') as zf:
filelist = zf.namelist()
for filename in filelist:
print('loading', filename)
contents = XMLContents()
contents.read_xml(zf, filename, dem_mode)
posix, posiy = contents.posix, contents.posiy
dem_tile = DEMInArray(contents)
output_array.update_raster(dem_tile.raster, posiy, posix)
zf.close()
print('save', out_filename)
output_array.save_raster(out_filename)
def main(argv):
for i in range(1, len(argv)):
convert(argv[i], argv[i].replace('.zip', '.tif'))
if __name__ == '__main__':
main(sys.argv)