ChatGPTをはじめとする、生成系AIは活用されていますか?
・下記のコードのエラー箇所を指摘してください。
・EC2の特徴について教えてください。
ソースコードの推敲や、サービスの特徴をまとめてもらったりと、何かと便利な生成系AIですが、下記のような質問では正しい回答を得られないことが多いです。
・出勤打刻を漏らした際に必要な申請について教えてください。
・○○システムにおける××の運用ルールについて。
これは、生成系AI(ChatGPT)のインプットデータがWebページや書籍・学術論文を主としており、世間的に回答が一致する内容は得意ですが、組織やシステムごとにルールや仕様が異なる内容についての回答はニガテであるためです。
逆に言えば、インプットデータを組織内のデータに制限することができれば、各組織やシステムに関する回答が可能になるのではないでしょうか。
それを実現するのが、本記事で紹介する検索拡張生成(RAG)になります。
使用する機能
Amazon Bedrock

生成AIの基盤モデルをAPIを通じて利用できるようにするサービス。
AWS上でChatGPTの利用を可能にするサービスのようなイメージ。
Amazon Kendra

機械学習を利用した高精度な文書検索サービス。
BedRockにインプットするデータを、指定したデータソースのデータに限定する役割で使用。
データソースにはS3やRDS、SharePointが指定可能。
データストレージ(S3)

BedRockにインプットするデータの保存先として使用。
予め、S3にインプットするデータを格納しておく。(今回は社内で開催されたライトニングトーク会の内容についてのデータを格納)

構成図

デモ
ChatGPT
まずはインプットデータを制限していないChatGPTにLT(ライトニングトーク)について質問してみます。

当然、インプットデータを制限していないChatGPTに質問した場合はあらゆるLTに関する回答がなされ、適切な回答を得ることができません。
RAGを実装した生成系AI
続いてインプットデータを制限した生成系AIにLTについて質問してみます。
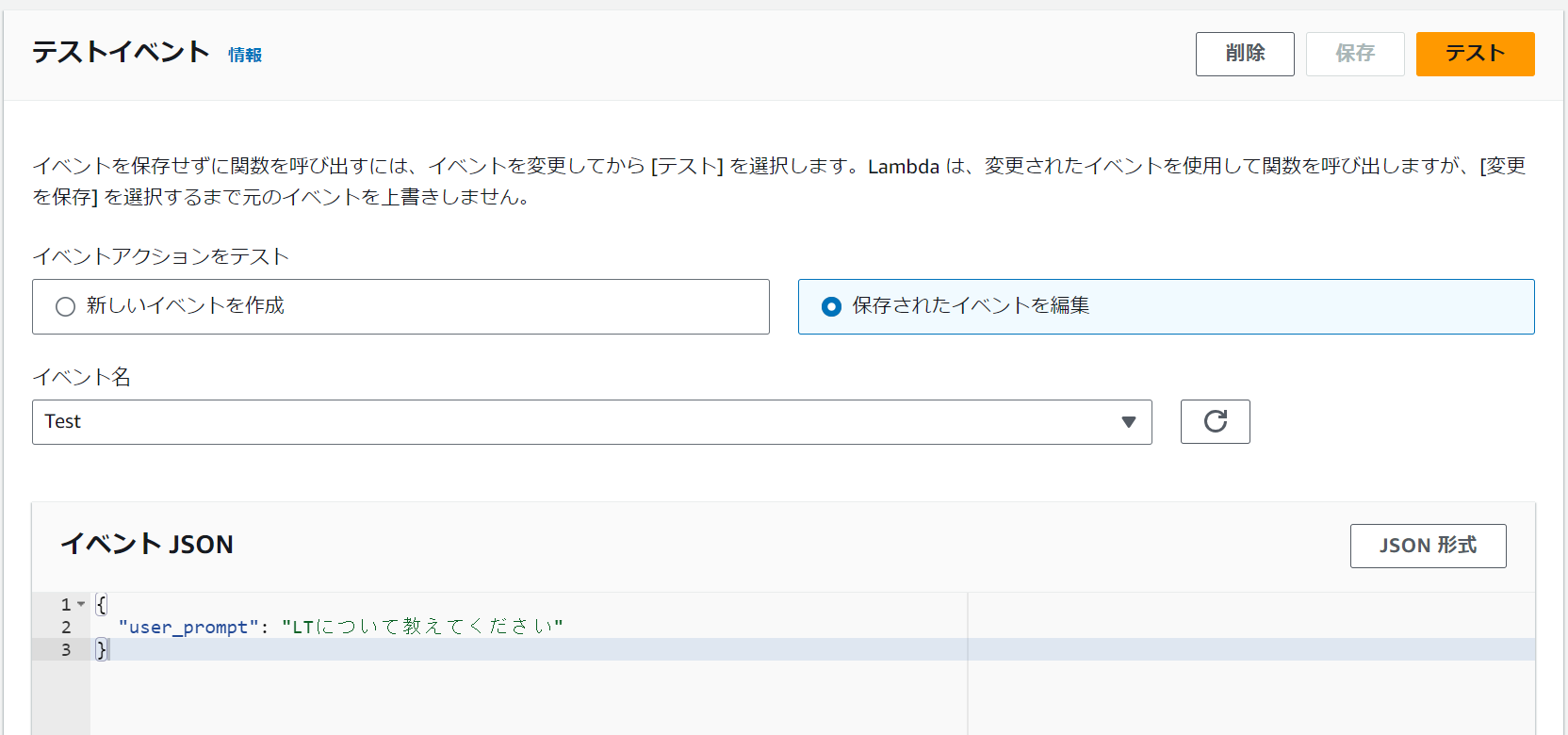
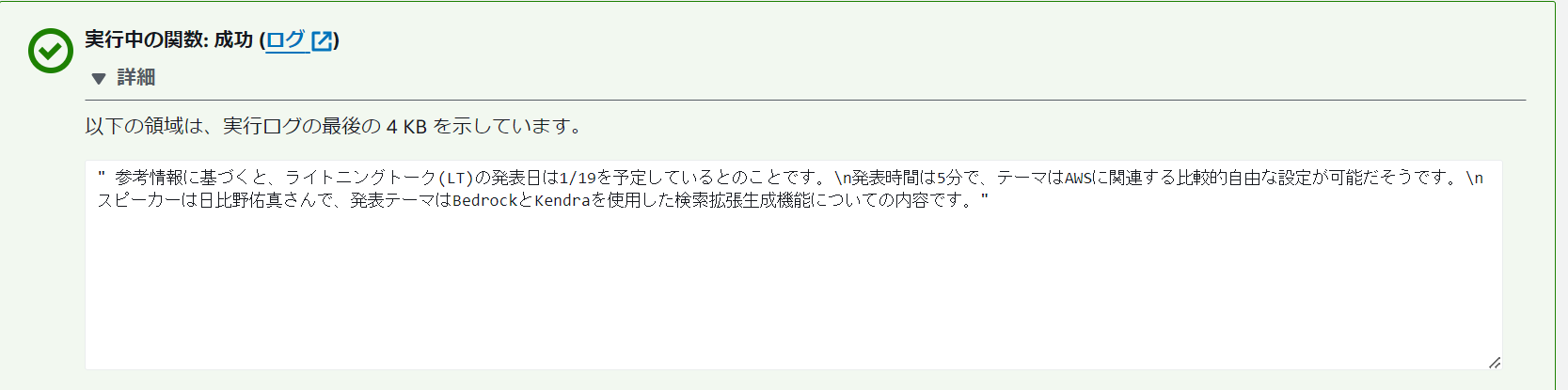
インプットデータを制限することで、LTについて適切な回答を得ることができました。
検索拡張生成を使用することで、特定の組織やプロジェクト内のルールや仕様についての回答を得ることができる、生成系AIの作成が可能になります。