こんにちは、@Hi-kingです。普段はお仕事で、人工生命観察プロジェクト"ARTILIFE"の強化学習エンジンと、リアルワールドゲーム"テクテクテクテク"のARエンジンを開発しています。ということで、今回は、<リアルワールドデータ>をつかって<人工生命>を育ててみることにしました。
"リアル地図データを使って強化学習で街を破壊する人工生命を育てる"記事を投稿しました。リアルワールドの3DデータをWRLDライブラリを用いて取得し、その3D世界上で効率よく街を破壊する生命を育てました!昨日公開したARTILIFEのエンジン(OSS)を使ってます。 https://t.co/mfztjcC9wg #ARTILIFE pic.twitter.com/xEoVfZ3kpV
— K.Ogaki(signico) (@Hi_king) December 19, 2018
リアルワールドスケールのマップなので、ARTILIFEと違い、ほぼ無限にマップを歩き回りながら学習することができます。この動画は大体1時間くらいサンフランシスコ放浪させて育てた生命です。
ソースコードはgithubで公開してます( https://github.com/Hi-king/UnityRealWorldRLCreature )
リアルワールドデータ編
テクテクテクテクでは、地図データを元に、街区サーバーを作ったり、クライアントでの描画を実装したり、などなどによってリアルワールドゲームを達成しているわけですが、個人開発でそこまでやってられないですよね。。。
google mapを使えばunityで簡単に3Dリアルワールドゲームが作れる( https://cloud.google.com/maps-platform/gaming/ )と聞いてたんですが、いざ調べてみると、APIが公開されているわけではなく、ビジネスとしての問い合わせから始めなきゃいけないみたいで、まだ気軽に使えるものではなかったです。
そして類似サービスを探していてWRLD( https://www.wrld3d.com/ )に出会いました。なんとUnityのアセットストアにコレを使うためのアセットが置いてあり、APIキーを入れればすぐにサンプルが動く、というお手軽さでした。導入はQiitaにも記事があったのでそちらを参照ください( https://qiita.com/lycoris102/items/f9edd8728c1f2966debb )。

ゴールデンゲートブリッジなど有名な建造物はちゃんといい感じに再現されてます。
強化学習編
こちらは、ARTILIFEの基礎エンジンとなってる強化学習エンジンRLCreatureをOSSで公開してるので、基本的にはそれをそのまま使います(https://github.com/dwango/RLCreature )。ちなみにこのエンジンの売りは、学習までUnityで完結するので、サーバーなどを用意せずにそのままスマホビルドなどできるということです。
とはいえ、あくまでもエンジンなので、街を破壊するモンスターを育てるためには、強化学習のための"環境"、"報酬"、"行動"を決めなければいけません。とりあえず効率的に街を破壊してほしかったので、とにかく建物に近づくように体を動かして、触ると一撃で街区を破壊できるという雑な学習で行きます。
環境・報酬
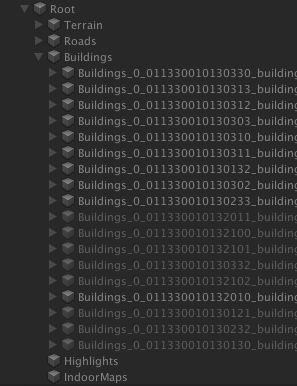
WRLDでは、マップデータはTerrain,Roads,Buildings,Highlights,indoorMapsの5つのカテゴリに分かれていて、さらにその中に各カテゴリのオブジェクトが街区のような単位ではいってる構造になっています。もちろんカメラが進めばオブジェクトの追加削除が行われるので、無限に移動し続けられます。
今回は、緑に優しく、文明に厳しいモンスターを作りたかったので、"一番近いBuildingsの座標が見える"(環境)かつ"一番近いBBuildingsに近づいていけば近づいた距離だけ評価値が上がる"(報酬)という設定で学習させてみました。

結果、このようにポツンと緑の取り残された土地を生み出していくモンスターとなりました。ちなみにここはシリコンバレー、サンノゼ駅周辺だった場所です。ちなみに、森を壊せないようにしてるわけではなくて、この生命は触れるものすべてを傷つけるように設定しています。シザーハンズ。。。
ちょっとアルゴリズムの中身の話
学習アルゴリズムはRLCreatureパッケージに従ってます。詳細は解説ページと論文があるので( https://dmv.nico/ja/casestudy/rlcreature/ )そちらを参照いただきたいのですが、簡単にここにも説明を書いておきます。
強化学習でモーションを生成しているので、先程の"環境"を入力、"報酬"を最大化するように、"行動"を生成するのですが、ここで、"行動"は今回はその生命が持つ全関節の曲げ角度になります。ですが、全関節の動きを出力するのは結構高次元の出力になってしまい、学習も難しくなるので、ここでは、"行動"は"前進"・"左進"などの指示に簡単化しています。
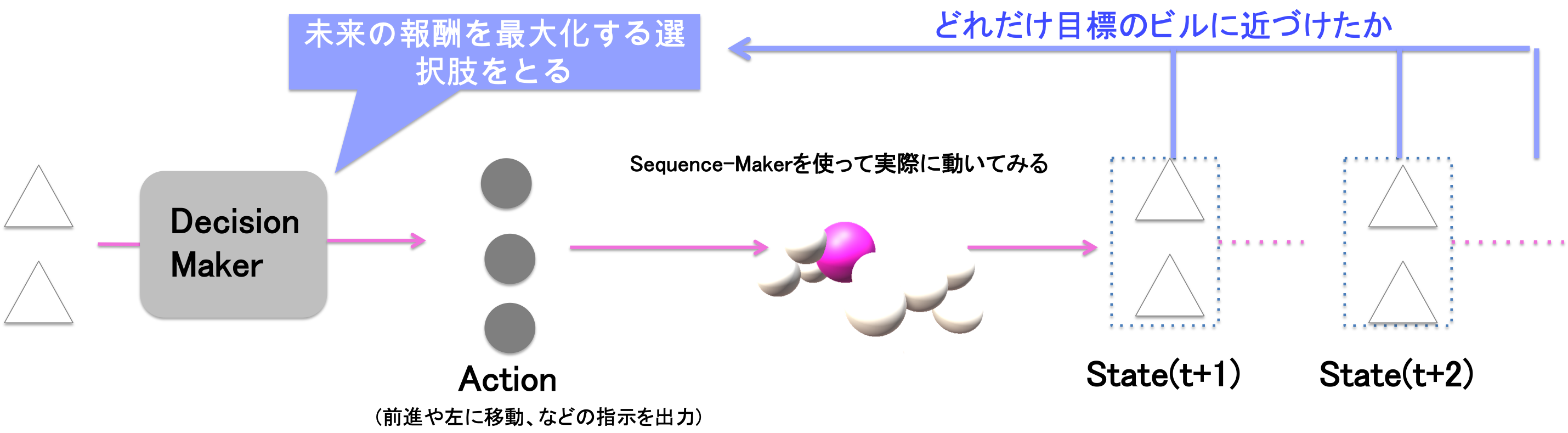
この図が、強化学習部分(DecisionMaker)の学習アルゴリズムの概念図です。目標となる破壊すべきビルに近づくためには、どのアクションをどの順番で行えばよいか、というプランニングを行います。学習アルゴリズムはDQN、ニューラルネットワークは4層の全結合モデルを用いてます。
ところで、"前進"と言う指示だけでは、実際に生命が動くことはできないので、やはりその指示を実際の関節の動きに翻訳する必要があります。ここではよりシンプルなバンディットアルゴリズムを用いています。
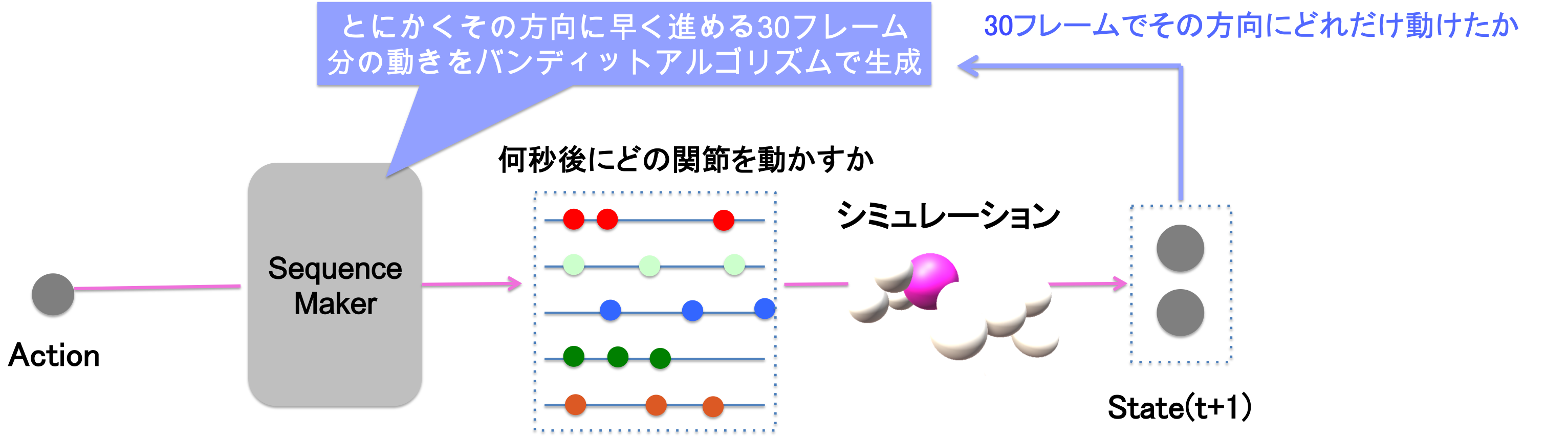
この図は、バンディットアルゴリズム部分、SequenceMakerの概念図です。全関節を、何フレーム後にどの角度に曲げるか、という高次元の出力を刷る代わりに、入力はなにも取らず(前進・後退などそれぞれ別のモデルを使っている)、最適化する目標も、その30フレームでの移動距離で、未来は考えないというように簡単化しています。
できなかったこと
WRLDに日本の3Dデータが含まれてなかったので東京大破壊ができませんでした!悔しい!
"環境"にはUnityのgameObjectの座標を入れてるのですが、実際の破壊判定は、生命と建物の接触で判定しているので、中心に空洞がある建物とかだと、ゼロ距離(空洞部)まで行ってるのに接触できないという問題が時々発生しました。ちゃんと"環境"も建物のメッシュを入力できるようにしたかった。
WRLDのデータは地形がちゃんと再現されてて坂とかがあるんで、時々崖に落ちてた。地形認識して避けるようにしたい。ちなみにARTILIFE製品版の生命は地形も認識してるので、そのへんを実装できれば楽しかったのですが。