0.概要
本記事は日本ディープラーニング協会認定の講座プログラムである「ラビット・チャレンジ」が提供している科目の1つである深層学習のレポートである。
記事タイトルに記載のとおり、Day1 Section4の勾配降下法について以下にまとめる。
1.勾配降下法の種類
- 勾配降下法(バッチ勾配降下法)
- ミニバッチ勾配降下法
- 確率的勾配降下法(SGD)
- Momentum:勾配の移動平均を出して振動を抑える(過去の勾配たちを考慮することで急な変化を抑える)。
- ネステロフの加速勾配法(NAG):勾配が正しい向き(損失を減らす方向)に向いていることを保証したモーメンタム。
- AdaGrad:次元ごとに学習率を変化させるようにしたもの。
- RMSprop:AdaGradの改良版であり、一度学習率が0に近づくとほとんど変化しなくなるAdaGradの問題を改良したもの。
- AdaDelta:RMSpropの改良版であり、次元数のミスマッチ?を解消したもの。
- Adam:Momentum+RMSprop。つまり移動平均と学習率の調整。
...etc
色々あるが基本的にどれも勾配降下法がベースとなっている。
新しければ必ずしも以前のものより良いとは限らない。
https://qiita.com/omiita/items/1735c1d048fe5f611f80
https://qiita.com/ZoneTsuyoshi/items/8ef6fa1e154d176e25b8
バッチ勾配降下法ではメモリへの展開が困難であり、確率的勾配降下法では1件ずつ与えることになるため計算効率が悪いが、データをある程度のサイズごとに分けるミニバッチ勾配降下法の場合、1つ1つを大きくしすぎなければメモリへの展開も容易であり、かつ並列で処理することで効率よく計算が可能。
基本的に深層学習においてはどのような最適化関数を使うにしてもミニバッチで行うことが基本となる。
1.1.学習率
機械学習の方でも出てきた通り、パラメータの収束のしやすさ(勾配をどれだけの勢いで降りるかのイメージ)のハイパーパラメータ。
学習率が大きすぎる場合、最小値を飛び越えてむしろ値が大きくなったりして発散してしまう。
学習率が小さすぎる場合、最小値にたどり着くまでに何度も更新するため最小値まで時間がかかる。局所解に留まってしまう可能性がある。
機械学習の講座では$\eta$だったがこの講座では$\epsilon$。
これに限ったことではないが、人や書籍等によって使われる文字が違ったりすることには注意が必要。
2.オンライン学習
データを都度都度与えて学習させる学習手法。
データを一通り用意してから一度に与えて学習させるバッチ学習の逆。
バッチ学習の場合、一度に大量データをメモリ上に展開しないといけないため、都度都度データを与えるオンライン学習の方がよく使われている。
3.エポック
データセット全てを一度与えることを1エポックと言う。
例えば同じデータセットを2回与えるなら2エポックとなる。
ミニバッチで処理するなら1エポックの中にミニバッチがn個あることになる。
4.確認テスト
4.1.確認テスト1
「1_3_stochastic_gradient_descent.ipynb」から勾配降下法の下記数式に該当するコードを抜き出せ。
w^{t+1}=w^{t}-\epsilon\Delta{E}
network[key] -= learning_rate * grad[key]
4.2.確認テスト2
オンライン学習とはなにか。
回答:
データを都度都度与えて学習させる学習手法。
データを一通り用意してから一度に与えて学習させるバッチ学習の逆。
4.3.確認テスト3
下記の数式の意味を図に書いて説明せよ。
w^{t+1}=w^{t}-\epsilon\Delta{E}
回答:
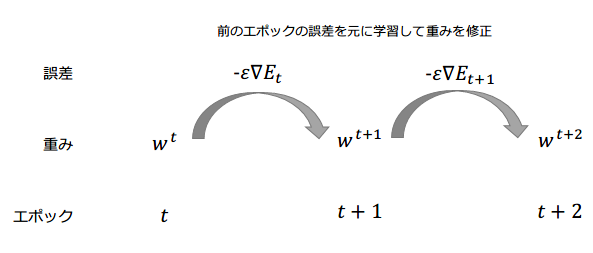
前回のエポックの誤差を元に重みを修正(学習)していくことによって、次のエポックではよりデータに適合した予測ができるようになっていく。
これを繰り返していくことになる。
X.ラビットチャレンジとは
ラビットチャレンジとは、日本ディープラーニング協会認定の講座プログラムの1つ。
E資格を受験するためにはこのラビットチャレンジ等、いずれかの講座プログラムを修了しなければならない。
ラビットチャレンジの特徴は「現場で潰しが効くディープラーニング講座」の通学講座録画ビデオを編集した教材を使用した自習スタイルであるという点。
サポートは他の講座より少なく、受け身ではなく自主的に学んでいく姿勢でなければ進められないが、その分、他の講座に比べると安価であり、手が出しやすい。
ある程度知識がある人、自力で頑張るぞというガッツのある人向けではないかと感じる。
