はじめに
最近、とあるYoutuberの方に影響されて、少し機械学習を触ってみました。
本記事は、その過程で自分が一番困った「学習コンフィグの役目」について、初心者なりに解説するものです。
初めて書く記事なので、拙い部分等あると思われますがご容赦ください。
概要
この記事では、公式ドキュメントを参考に、ML-Agentsにおける基本的なコンフィグについて、役目とその挙動を簡単に解説します。よければ最後まで見ていってください。
学習コンフィグとは?
おそらくこの記事を見ている方は、「環境構築が終わって、さあ学習だ!」という状態の方が多いのではないかと思います。
チュートリアルを終え、いよいよ自分の環境で学習を始めようというときに立ちはだかるのが、この学習コンフィグです。
しかしそんな時も大丈夫、この公式ドキュメントを見れば...?
はい、頭が爆発しますね。私はこれを全て日本語に直してWordにまとめるという暴挙に出ましたが、正直2度とやりたくないです。
そこで、第二の被害者を産まないためにも今回はここに上ののコンフィグたちが何を意味するのか、まとめておきたいと思います。
本題
前置きが長くなりましたが本題です。
必要に応じて、あとがきにあるconfigと一緒に見てください。
| 項目名称 | 説明 |
|---|---|
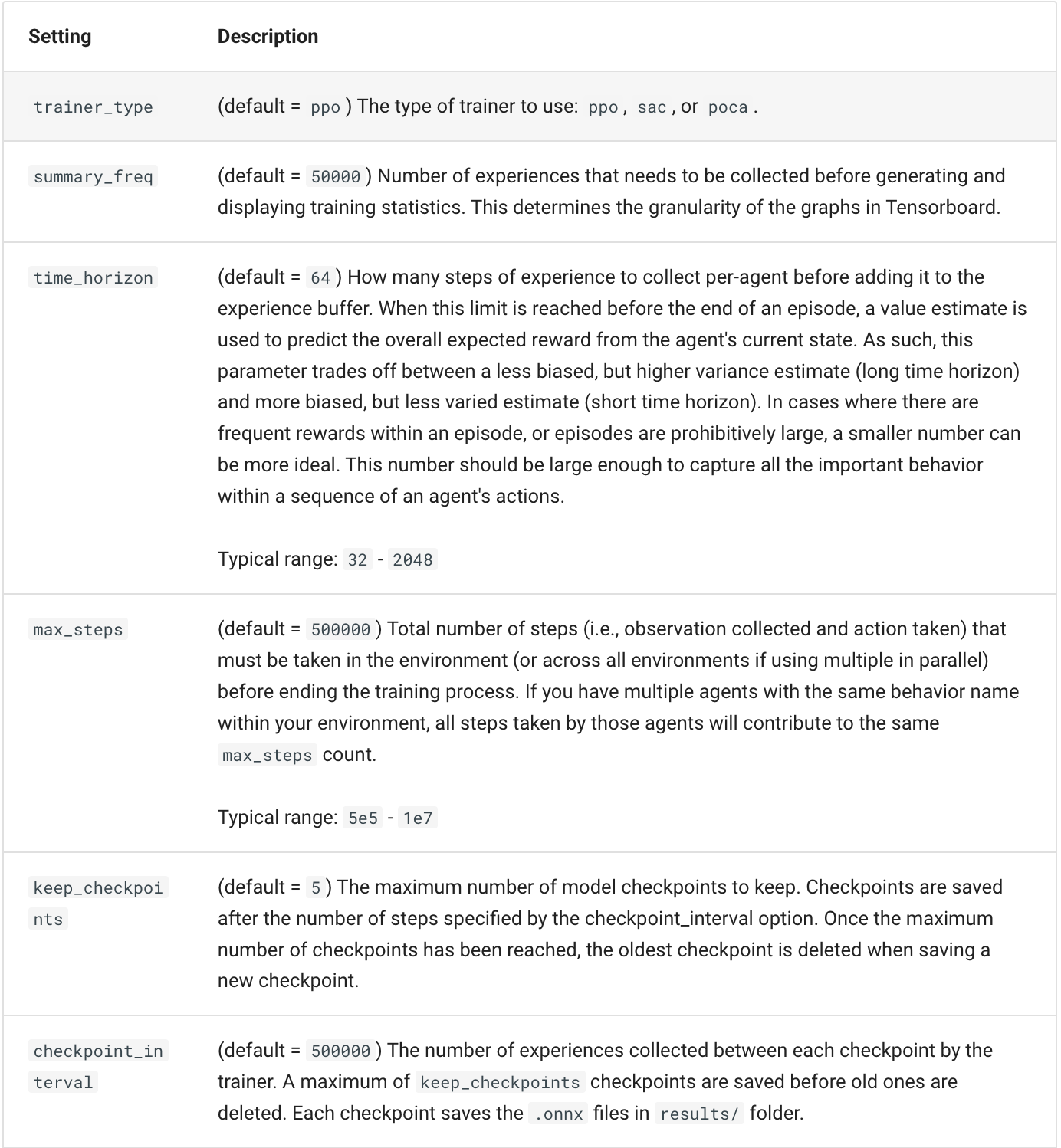
| trainer_type | 学習方法を設定する項目。PPO、SAC、POCAがあるがこれについては割愛。default=PPO
|
| summary_freq | コマンドプロンプトに何ステップごとに学習経過を表示するかの設定。自分は10000にしている。default=50000
|
| time_horizon | エージェントがどれだけ長期を見据えて行動するかの指標。大きくすればより長い目で報酬を得るように動き、小さくすればより即時的な報酬を優先するようになる。default=64
|
| max_steps | 学習を行うステップ数を指定する。default=500000
|
| keep_checkpoints | チェックポイントの保存数を指定する。後述するinit_pathで、途中から学習を再開するのに使う。default=5
|
| checkpoint_interval | チェックポイントの保存間隔をstep数で指定する。default=500000
|
| init_path | 学習を再開するチェックポイントのパスを指定する。拡張子は(.pt)。default=指定なし
|
| threaded | モデルの更新中にも学習を継続するか否か。PPOであれば変更の必要は基本ない。default=false
|
| hyperparamaters | 以下はハイパーパラメータ(以降HP)のオプションです. |
| HP-> learning_rate |
勾配降下法における、初期学習率。最適解に近づこうとする速度に相当する。大きくしすぎるとオーバーシュートするので注意。default=0.0003
|
| HP-> batch_size |
一度の学習でモデルにどれだけのデータを与えるか。 大きい→学習は早いが過学習する可能性がある。 小さい→学習に時間がかかる。 default=記載なし
|
| HP-> buffer_size |
一度のモデル更新にどれだけの経験を利用するか。 大きい→安定するが変化は遅い 小さい→変化は早いが不安定 default=10240
|
| HP-> learning_rate_schedule |
学習量と時間の関係性を表す。 liner:終盤に近づくにつれ学習量が減少する。 constant:常に一定量学習する default=linear
|
| PPO settings | 以下は、ハイパーパラーメーターのうち、PPOでのみ(?)使用される部分です。 |
| HP-> beta |
大きければ大きいほどエージェントがランダムに動く。Tensorboardから学習を観察し、エントロピーの項目が緩やかに減少するよう調整するとよい。defualt=0.005
|
| HP-> bera_schedule |
betaの値を学習時間に合わせて減少させるか否か。 linear:時間とともに減少 constant:常に一定 default=linear
|
| HP-> epsilon |
一度の学習でどれだけ変化が可能であるかの閾値。 大きい:学習は早いがあまり安定しない 小さい:安定するが学習が遅い defalut=0.2 Typical_range=0.1~0.3
|
| HP-> epsilon_schedule |
epsilonの値を学習時間に合わせて減少させるか否か。 linear:時間とともに減少 constant:常に一定 default=linear
|
| HP-> num_epoch |
モデルにおいてデータの学習を何回反復するかの設定。 小さい→学習は早いが不安定 大きい→学習は長引くが安定 default=3
|
| HP-> shared_critic |
自身があまり理解できていないため割愛。default=false
|
| network_settings | これより下はニューラルネットワークの設定(以降NS)になります。 |
| NS-> hidden_units |
ニューラルネットワークにおける、中間層のユニットの数。単純な問題なら少なく、複雑な問題なら大きくすると良い。default=128
|
| NS-> num_layers |
ニューラルネットワークにおける、中間層の数。default=2
|
| NS-> normalize |
ネットワークに対する入力に正規化を行うかどうか。default=false
|
| NS-> vis_encode_type |
映像情報で学習を行う際、画像をどれくらい分割して学習させるかを指定する。 simple=20x20 nature_cnn=36x36 resnet=15x15 match3=5x5 fully_connected=0x0(サイズなし) 分割を行うことで、例えば欠けた画像も認識できるようになる。 default=simple
|
| NS-> conditioning_type |
ニューラルネットワークにおいて、「重み」を最適化しながら学習するか否か。default=hyperしないならnone
|
| reward_signals | これより下は報酬設定(以下RS)の項目です |
| RS-> strength |
スクリプトから設定した報酬を、エージェントがどれだけ重視するかの項目。特に変える必要は無い。default=1
|
| RS-> gamma |
エージェントが将来の報酬に対しどれほど気を配るか、に相当する値。この値は1未満でなければならない。default=0.99 Typical_range=0.8~0.995
|
ここまで読み切った方々、お疲れ様でした。
「色々な項目があって難しそうだ」と感じるかもしれませんが、実のところmax_stepsとsummary_freqを変えるだけでも、わりかし快適に学習ができます。
また、上に書いた全てを覚える必要は全くありません。スクショなどに残すか、必要になればまた見にいらしてください。
終わりに
今後機械学習を始めるにあたり、役に立つであろうデフォルト値のコンフィグを置いておきます。上の表と照らし合わせつつ見るのがおすすめです。
behaviors:
Agent:
# トレーナー種別
trainer_type: ppo
# 基本設定
summary_freq: 10000
time_horizon: 64
max_steps: 1500000
keep_checkpoints: 5
checkpoint_interval: 500000
# init_path: デフォルトでは設定なし
threaded: false
# 学習設定
hyperparameters:
# PPO、SAC共通
learning_rate: 0.0003
batch_size: 512 # デフォルトが載ってなかったのでとりあえず512にしておく
buffer_size: 10240
learning_rate_schedule: linear
# PPO専用
beta: 0.005
beta_schedule: linear
epsilon: 0.2
epsilon_schedule: linear
num_epoch: 3
shared_critic: false
# ニューラルネットワークの設定
network_settings:
hidden_units: 128
num_layers: 2
normalize: true
vis_encode_type: simple
conditioning_type: hyper
# 報酬設定
reward_signals:
extrinsic:
strength: 1
gamma: 0.99
あとがき
拙い文章ではありますが、皆様のお役に立てれば幸いです。ありがとうございました。
参考文献