こんにちは!
前回作成した記事では、Neural Style Transfer(NST)の原理について、Gatysらの論文を参考にまとめてきました。今回は、Pythonを用いて実際のプログラムに触れながらさらに理解を深めたいと考えています。
さて、以後では、TensorFlowを用いてNSTを実装する方法を紹介します。(復習)この手法は、任意のスタイル画像の特徴を抽出し、それを異なるコンテンツ画像に適用することで、美しいスタイル化された画像を生成する技術です。
この記事では、Inception V3という強力な畳み込みニューラルネットワーク(CNN)を使用してNSTを実現します。Inception V3は、Googleが開発した高精度な画像認識モデルで、スタイルとコンテンツの特徴を効果的に捉えることができます。
具体的な実装コードを示しながら、最終的には、任意の画像について自分好みのスタイルに変更することを目指します。
参考:Neural-Style-Transfer-with-InceptionV3
使用言語と実行環境
- 使用言語:Python
- ライブラリ:TensorFlow
- 実行環境:Google Colab
実装
(実装結果は以下のリポジトリにあります。参考までにご覧ください)
1. 画像処理関数
ここでは、Neural Style Transfer(NST)の実装に必要な画像処理関数を実装します。これらの関数は、画像の読み込み、前処理、表示、およびテンソルから画像への変換を行います。
# Function to convert a tensor to an image
def tensor_to_image(tensor):
tensor_shape = tf.shape(tensor)
number_elem_shape = tf.shape(tensor_shape)
# If the tensor has more than 3 dimensions, remove the batch dimension
if number_elem_shape > 3:
assert tensor_shape[0] == 1
tensor = tensor[0]
return tf.keras.preprocessing.image.array_to_img(tensor)
# Function to load and preprocess an image
def load_img(path_to_img):
max_dim = 512
image = tf.io.read_file(path_to_img)
image = tf.image.decode_jpeg(image)
image = tf.image.convert_image_dtype(image, tf.float32)
# Get the shape of the image and resize it maintaining the aspect ratio
shape = tf.shape(image)[:-1]
shape = tf.cast(tf.shape(image)[:-1], tf.float32)
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
image = tf.image.resize(image, new_shape)
# Add the batch dimension and convert the image to uint8
image = image[tf.newaxis, :]
image = tf.image.convert_image_dtype(image, tf.uint8)
return image
# Function to display images with optional titles
def show_images(images, titles=[]):
plt.figure(figsize=(20, 12))
for idx, (image, title) in enumerate(zip(images, titles)):
plt.subplot(1, len(images), idx + 1)
plt.xticks([])
plt.yticks([])
# If the image has more than 3 dimensions, remove the batch dimension
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
plt.title(title)
# Function to preprocess an image for InceptionV3
def preprocess_image(image):
image = tf.cast(image, dtype=tf.float32)
image = (image / 127.5) - 1.0
return image
preprocess_image関数について、 InceptionV3モデルは、入力画像のピクセル値が [-1, 1] の範囲にあることを前提としています。このステップでは、画像の各ピクセル値を以下のように変換します:
- 元のピクセル値の範囲は [0, 255] です。
- まず、ピクセル値を 127.5 で割ることで、範囲を [0, 2] に変換します。
- 次に、1.0 を引くことで、範囲を [-1, 1] に変換します。
この変換によって、ピクセル値が [-1, 1] の範囲に正規化され、InceptionV3モデルが期待する形式に整えられます。
2. InceptionV3を用いたスタイル/コンテンツの抽出
# Choosing earlier layers for extracting style features from the InceptionV3 model
style_layers = [
'conv2d',
'conv2d_1',
'conv2d_2',
'conv2d_3',
'conv2d_4',
'conv2d_5',
'conv2d_9'
]
# Choosing a deeper layer for extracting content features
content_layers = ['conv2d_88'] # Content layer 1
# Combining content and style layers into one list
content_and_style_layers = style_layers + content_layers
# Number of content and style layers
NUM_CONTENT_LAYERS = len(content_layers)
NUM_STYLE_LAYERS = len(style_layers)
このコードは、InceptionV3モデルの特定のレイヤーを選択してスタイル特徴とコンテンツ特徴を抽出する準備をしています。スタイル特徴は画像の浅いレイヤーから、コンテンツ特徴は深いレイヤーから抽出されます。これにより、Neural Style Transferのアルゴリズムがスタイルとコンテンツを効果的に融合できるようになります。
以下の関数は、事前にImageNetで訓練されたInceptionV3モデルをロードし、指定されたレイヤーの出力を取得するための新しいモデルを作成します。
# Function to create an InceptionV3 model that outputs the specified layers
def inception_model(layer_names):
# Load the InceptionV3 model pre-trained on ImageNet, excluding the top fully connected layers
inception = tf.keras.applications.InceptionV3(include_top=False, weights='imagenet')
# Freeze the model to prevent the weights from being updated during training
inception.trainable = False
# Extract the outputs of the specified layers
outputs = [inception.get_layer(name).output for name in layer_names]
# Create a new model that takes the same input as InceptionV3 but outputs the specified layers
model = tf.keras.Model(inputs=inception.input, outputs=outputs)
return model
# Instantiate the InceptionV3 model with the specified content and style layers
inceptionv3 = inception_model(content_and_style_layers)
# Display the model architecture
inceptionv3.summary()
補足
この関数は、事前にImageNetで訓練されたInceptionV3モデルをロードし、指定されたレイヤーの出力を取得するための新しいモデルを作成します。
-
InceptionV3モデルのロード:
inception = tf.keras.applications.InceptionV3(include_top=False, weights='imagenet')-
include_top=False:トップ(完全結合)レイヤーを除外してモデルをロードします。これにより、特徴抽出に使用できる畳み込み層のみが含まれます。 -
weights='imagenet':ImageNetデータセットで事前訓練された重みを使用します。
-
-
モデルの重みを凍結:
inception.trainable = False- モデルの重みが訓練中に更新されないようにします。これにより、事前訓練された特徴抽出機能を保持します。
なんで凍結するんだっけ?に対する回答
NSTでは、既存の深層学習モデル(この場合、InceptionV3)の事前訓練された特徴抽出機能を使用します。重みを凍結することで、これらの特徴抽出機能を保持し、スタイルとコンテンツの特徴を安定して抽出することができます。
NSTの目的は、スタイル画像とコンテンツ画像の特徴を抽出し、それをもとに新しい画像を生成することです。この生成画像の更新は、生成画像自体のピクセル値を最適化することで行われ、特徴抽出モデルの重みを変更する必要はありません。生成画像のピクセル値は、重みを凍結したモデルを通して計算された損失を最小化するために更新されます。
:
-
指定されたレイヤーの出力を抽出:
outputs = [inception.get_layer(name).output for name in layer_names]-
layer_namesリストに含まれる各レイヤーの出力を取得します。
-
-
新しいモデルを作成:
model = tf.keras.Model(inputs=inception.input, outputs=outputs)- InceptionV3モデルと同じ入力を持ち、指定されたレイヤーの出力を返す新しいモデルを作成します。
変更したInceptionV3モデルのインスタンス化とモデル構造の表示
# Instantiate the InceptionV3 model with the specified content and style layers
inceptionv3 = inception_model(content_and_style_layers)
# Display the model architecture
inceptionv3.summary()
-
inception_model(content_and_style_layers)を呼び出して、新しいInceptionV3モデルを作成します。このモデルは、指定されたスタイルレイヤーとコンテンツレイヤーの出力を返します。 -
inceptionv3.summary()を呼び出して、モデルの構造を表示します。これにより、モデルの各レイヤーの詳細が確認できます。
3. Loss Function
以下のコードは、Neural Style Transferのためのスタイル損失とコンテンツ損失を計算し、それらを組み合わせて総損失を計算するための関数を定義しています。これにより、生成画像がスタイル画像の特徴とコンテンツ画像の特徴を両方持つように調整されます。
# Function to compute style loss
def get_style_loss(features, targets):
# Calculate mean squared error (MSE) between features and targets to get the style loss
style_loss = tf.reduce_mean(tf.square(features - targets))
return style_loss
# Function to compute content loss
def get_content_loss(features, targets):
# Calculate the sum of squared differences between features and targets to get the content loss
content_loss = 0.5 * tf.reduce_sum(tf.square(features - targets))
return content_loss
# Function to compute the Gram matrix
def gram_matrix(input_tensor):
# Compute the Gram matrix using Einstein summation convention
gram = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
# Get the shape of the input tensor
input_shape = tf.shape(input_tensor)
height = input_shape[1] # Height of the tensor
width = input_shape[2] # Width of the tensor
num_locations = tf.cast(height * width, tf.float32) # Number of locations in the tensor
# Scale the Gram matrix by the number of locations
scaled_gram = gram / num_locations
return scaled_gram
# Function to extract style features from an image
def get_style_image_features(image):
# Get the output of the preprocessed image from the InceptionV3 model
outputs = inceptionv3(preprocess_image(image))
# Extract the outputs of the style layers
style_outputs = outputs[:NUM_STYLE_LAYERS]
# Compute the Gram matrix for each style layer
gram_style_features = [gram_matrix(style_layer) for style_layer in style_outputs]
return gram_style_features
# Function to extract content features from an image
def get_content_image_features(image):
# Get the output of the preprocessed image from the InceptionV3 model
outputs = inceptionv3(preprocess_image(image))
# Extract the outputs of the content layers
content_outputs = outputs[NUM_STYLE_LAYERS:]
return content_outputs
# Function to compute the total loss combining style and content losses
def get_style_content_loss(style_targets, style_outputs, content_targets, content_outputs, style_weight, content_weight):
# Compute the style loss for each style layer and sum them up
style_loss = tf.add_n([get_style_loss(style_output, style_target) for style_output, style_target in zip(style_outputs, style_targets)])
# Compute the content loss for each content layer and sum them up
content_loss = tf.add_n([get_content_loss(content_output, content_target) for content_output, content_target in zip(content_outputs, content_targets)])
# Scale the style loss by the weight and the number of style layers
style_loss = style_loss * style_weight / NUM_STYLE_LAYERS
# Scale the content loss by the weight and the number of content layers
content_loss = content_weight * content_loss / NUM_CONTENT_LAYERS
# Combine the style and content losses to get the total loss
total_loss = style_loss + content_loss
return total_loss
補足
スタイル損失を計算する関数
# Function to compute style loss
def get_style_loss(features, targets):
# Calculate mean squared error (MSE) between features and targets to get the style loss
style_loss = tf.reduce_mean(tf.square(features - targets))
return style_loss
この関数は、生成画像のスタイル特徴とスタイル画像のスタイル特徴の間の平均二乗誤差(MSE)を計算してスタイル損失を求めます。
-
features: 生成画像から抽出されたスタイル特徴。 -
targets: スタイル画像から抽出されたスタイル特徴。
-
tf.reduce_mean(tf.square(features - targets)): 生成画像とスタイル画像の特徴マップ間のMSEを計算。 -
style_loss: 計算されたスタイル損失を返します。
コンテンツ損失を計算する関数
# Function to compute content loss
def get_content_loss(features, targets):
# Calculate the sum of squared differences between features and targets to get the content loss
content_loss = 0.5 * tf.reduce_sum(tf.square(features - targets))
return content_loss
この関数は、生成画像のコンテンツ特徴とコンテンツ画像のコンテンツ特徴の間の二乗誤差の総和を計算してコンテンツ損失を求めます。
-
features: 生成画像から抽出されたコンテンツ特徴。 -
targets: コンテンツ画像から抽出されたコンテンツ特徴。
-
0.5 * tf.reduce_sum(tf.square(features - targets)): 生成画像とコンテンツ画像の特徴マップ間の二乗誤差の総和を計算し、0.5を掛けます(scaling factor)。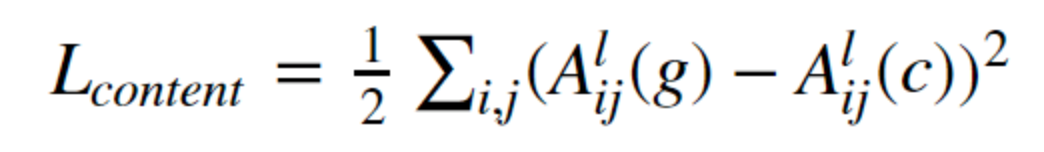
-
content_loss: 計算されたコンテンツ損失を返します。
グラム行列を計算する関数
# Function to compute the Gram matrix
def gram_matrix(input_tensor):
# Compute the Gram matrix using Einstein summation convention
gram = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
# Get the shape of the input tensor
input_shape = tf.shape(input_tensor)
height = input_shape[1] # Height of the tensor
width = input_shape[2] # Width of the tensor
num_locations = tf.cast(height * width, tf.float32) # Number of locations in the tensor
# Scale the Gram matrix by the number of locations
scaled_gram = gram / num_locations
return scaled_gram
この関数は、入力テンソルのグラム行列を計算します。グラム行列は画像のスタイル情報を捉えるために使用されます。
-
グラム行列 $G_{ij}^l(I)$
G_{ij}^l(I) = \sum_k A_{ik}^l(I) A_{jk}^l(I)- $G_{ij}^l(I)$ は、画像 $I$ の層 $l$ のグラム行列の要素 $(i, j)$。
- $A_{ik}^l(I)$ は、画像 $I$ の層 $l$ の特徴マップの要素 $(i, k)$。
- $A_{jk}^l(I)$ は、画像 $I$ の層 $l$ の特徴マップの要素 $(j, k)$。
$k$ は、層 $l$ の特徴マップにおけるチャンネルのインデックスです。従って、$k$ はその特徴マップのチャンネル数(デプス)にわたって変化します。具体的には、$k$ の範囲は 0 から $C^l - 1$ までです。ここで $C^l$ は、層 $l$ における特徴マップのチャンネル数です。
-
tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor): アインシュタインの縮約記法を使用してグラム行列を計算。 -
input_shape = tf.shape(input_tensor): 入力テンソルの形状を取得。 -
height = input_shape[1]: テンソルの高さを取得。 -
width = input_shape[2]: テンソルの幅を取得。 -
num_locations = tf.cast(height * width, tf.float32): 高さと幅の積を計算し、float32型にキャスト。 -
scaled_gram = gram / num_locations: グラム行列を位置の数でスケーリング。 -
scaled_gram: スケーリングされたグラム行列を返します。
スタイル画像の特徴を抽出する関数
# Function to extract style features from an image
def get_style_image_features(image):
# Get the output of the preprocessed image from the InceptionV3 model
outputs = inceptionv3(preprocess_image(image))
# Extract the outputs of the style layers
style_outputs = outputs[:NUM_STYLE_LAYERS]
# Compute the Gram matrix for each style layer
gram_style_features = [gram_matrix(style_layer) for style_layer in style_outputs]
return gram_style_features
この関数は、スタイル画像からスタイル特徴を抽出します。
-
outputs = inceptionv3(preprocess_image(image)): InceptionV3モデルを使用して前処理された画像の出力を取得。 -
style_outputs = outputs[:NUM_STYLE_LAYERS]: スタイルレイヤーの出力を取得。 -
gram_style_features = [gram_matrix(style_layer) for style_layer in style_outputs]: 各スタイルレイヤーのグラム行列を計算。 -
gram_style_features: グラム行列のリストを返します。
コンテンツ画像の特徴を抽出する関数
# Function to extract content features from an image
def get_content_image_features(image):
# Get the output of the preprocessed image from the InceptionV3 model
outputs = inceptionv3(preprocess_image(image))
# Extract the outputs of the content layers
content_outputs = outputs[NUM_STYLE_LAYERS:]
return content_outputs
この関数は、コンテンツ画像からコンテンツ特徴を抽出します。
-
outputs = inceptionv3(preprocess_image(image)): InceptionV3モデルを使用して前処理された画像の出力を取得。 -
content_outputs = outputs[NUM_STYLE_LAYERS:]: コンテンツレイヤーの出力を取得。 -
content_outputs: コンテンツ特徴のリストを返します。
スタイル損失とコンテンツ損失を組み合わせて総損失を計算する関数
# Function to compute the total loss combining style and content losses
def get_style_content_loss(style_targets, style_outputs, content_targets, content_outputs, style_weight, content_weight):
# Compute the style loss for each style layer and sum them up
style_loss = tf.add_n([get_style_loss(style_output, style_target) for style_output, style_target in zip(style_outputs, style_targets)])
# Compute the content loss for each content layer and sum them up
content_loss = tf.add_n([get_content_loss(content_output, content_target) for content_output, content_target in zip(content_outputs, content_targets)])
# Scale the style loss by the weight and the number of style layers
style_loss = style_loss * style_weight / NUM_STYLE_LAYERS
# Scale the content loss by the weight and the number of content layers
content_loss = content_weight * content_loss / NUM_CONTENT_LAYERS
# Combine the style and content losses to get the total loss
total_loss = style_loss + content_loss
return total_loss
この関数は、スタイル損失とコンテンツ損失を組み合わせて総損失を計算します。
-
style_loss = tf.add_n([get_style_loss(style_output, style_target) for style_output, style_target in zip(style_outputs, style_targets)]): 各スタイルレイヤーの損失を計算し、合計。 -
content_loss = tf.add_n([get_content_loss(content_output, content_target) for content_output, content_target in zip(content_outputs, content_targets)]): 各コンテンツレイヤーの損失を計算し、合計。 -
style_loss = style_loss * style_weight / NUM_STYLE_LAYERS: スタイル損失を重みでスケーリングし、スタイルレイヤーの数で割ります。 -
content_loss = content_weight * content_loss / NUM_CONTENT_LAYERS: コンテンツ損失を重みでスケーリングし、コンテンツレイヤーの数で割ります。 -
total_loss = style_loss + content_loss: スタイル損失とコンテンツ損失を合計して総損失を計算。 -
total_loss: 総損失を返します。
4. 学習(Gradients and Optimization)
以下のコードは、NSTにおける画像の更新プロセスを実装しています。calculate_gradients 関数は、総損失に対する画像の勾配を計算し、update_image_with_style 関数は、その勾配を使用して画像を更新します。総損失はスタイル損失、コンテンツ損失、および総変動損失の組み合わせで計算されます。
def calculate_gradients(image, style_targets, content_targets,
style_weight, content_weight, var_weight=0):
with tf.GradientTape() as tape:
style_features = get_style_image_features(image)
content_features = get_content_image_features(image)
loss = get_style_content_loss(style_targets, style_features, content_targets, content_features, style_weight, content_weight)
loss += var_weight*tf.image.total_variation(image) # Total variation Loss
gradients = tape.gradient(loss, image)
return gradients
def update_image_with_style(image, style_targets, content_targets, style_weight,
var_weight, content_weight, optimizer):
gradients = calculate_gradients(image, style_targets, content_targets, style_weight, content_weight, var_weight)
optimizer.apply_gradients([(gradients, image)])
image.assign(tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=255.0))
補足
損失に対する画像の勾配を計算する関数
def calculate_gradients(image, style_targets, content_targets, style_weight, content_weight, var_weight=0):
with tf.GradientTape() as tape:
# Extract style features from the image
style_features = get_style_image_features(image)
# Extract content features from the image
content_features = get_content_image_features(image)
# Compute the total loss combining style, content, and total variation losses
loss = get_style_content_loss(style_targets, style_features, content_targets, content_features, style_weight, content_weight)
# Add total variation loss for smoothing
loss += var_weight * tf.image.total_variation(image)
# Compute the gradients of the loss with respect to the image
gradients = tape.gradient(loss, image)
return gradients
-
勾配テープの使用:
-
with tf.GradientTape() as tape: 勾配計算を記録するためにtf.GradientTapeを使用します。このブロック内で計算されたすべての操作が記録され、後で勾配計算に使用されます。
-
-
スタイル特徴の抽出:
-
style_features = get_style_image_features(image): 生成画像からスタイル特徴を抽出します。
-
-
コンテンツ特徴の抽出:
-
content_features = get_content_image_features(image): 生成画像からコンテンツ特徴を抽出します。
-
-
損失の計算:
-
loss = get_style_content_loss(style_targets, style_features, content_targets, content_features, style_weight, content_weight): スタイル損失とコンテンツ損失を組み合わせた総損失を計算します。 -
loss += var_weight * tf.image.total_variation(image): 画像の滑らかさを保つための総変動損失を追加します。
-
-
勾配の計算:
-
gradients = tape.gradient(loss, image): 総損失に対する画像の勾配を計算します。 -
return gradients: 計算された勾配を返します。
-
計算された勾配を使用して画像を更新する関数
def update_image_with_style(image, style_targets, content_targets, style_weight, var_weight, content_weight, optimizer):
# Calculate the gradients
gradients = calculate_gradients(image, style_targets, content_targets, style_weight, content_weight, var_weight)
# Apply the gradients to the image using the optimizer
optimizer.apply_gradients([(gradients, image)])
# Clip the image values to be in the range [0, 255]
image.assign(tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=255.0))
-
勾配の計算:
-
gradients = calculate_gradients(image, style_targets, content_targets, style_weight, content_weight, var_weight): 先ほどの関数を使用して、損失に対する画像の勾配を計算します。
-
-
勾配の適用:
-
optimizer.apply_gradients([(gradients, image)]): 最適化アルゴリズム(オプティマイザ)を使用して、計算された勾配を画像に適用します。これにより、画像が更新されます。
-
-
画像のクリップ:
-
image.assign(tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=255.0)): 画像のピクセル値を [0, 255] の範囲にクリップします。これにより、ピクセル値が適切な範囲内に収まるようにします。
-
5. Style Transfer
ここまでお疲れ様でした。いよいよ、Style Transferのfittingを行う関数の実装です。
具体的な処理は、コンテンツ画像を反復的に更新してスタイル画像のスタイルに一致させるといものです。
# Function to perform style transfer by iteratively updating the content image to match the style of the style image
def fit_style_transfer(style_image, content_image, style_weight=1e-2, content_weight=1e-4, var_weight=0, optimizer='adam', epochs=1, steps_per_epoch=1, show_transition=False):
images = [] # List to store intermediate images
step = 0 # Step counter
# Extract style and content features from the style and content images
style_targets = get_style_image_features(style_image)
content_targets = get_content_image_features(content_image)
# Initialize the generated image with the content image
generated_image = tf.cast(content_image, dtype=tf.float32)
generated_image = tf.Variable(generated_image)
images.append(content_image) # Initial image is the original content image without any style
# Iterate over epochs
for n in range(epochs):
# Iterate over steps in each epoch
for m in tqdm(range(steps_per_epoch)):
step += 1
# Update the generated image with style
update_image_with_style(generated_image, style_targets, content_targets, style_weight, var_weight, content_weight, optimizer)
# Append intermediate images at intervals of 10 steps
if (m + 1) % 10 == 0:
images.append(generated_image)
# Optionally display the stylized image after each epoch
if show_transition:
display_fn(tensor_to_image(generated_image))
images.append(generated_image)
print(f"Train step: {step}")
# Convert the final generated image to uint8 data type
generated_image = tf.cast(generated_image, dtype=tf.uint8)
return generated_image, images
補足
-
関数の初期設定:
-
images = []: 中間画像を保存するリストを初期化します。 -
step = 0: ステップカウンターを初期化します。
-
-
スタイルとコンテンツの特徴を抽出:
-
style_targets = get_style_image_features(style_image): スタイル画像からスタイル特徴を抽出します。 -
content_targets = get_content_image_features(content_image): コンテンツ画像からコンテンツ特徴を抽出します。
-
-
生成画像の初期化:
-
generated_image = tf.cast(content_image, dtype=tf.float32): コンテンツ画像をfloat32型にキャストします。 -
generated_image = tf.Variable(generated_image): 生成画像をテンソル変数として初期化します。
-
-
初期画像の保存:
-
images.append(content_image): 最初の画像(スタイルが適用されていない元のコンテンツ画像)をリストに追加します。
-
-
エポックの反復:
-
for n in range(epochs): 指定されたエポック数の間、反復処理を行います。
-
-
各エポック内のステップの反復:
-
for m in tqdm(range(steps_per_epoch)): 各エポック内で指定されたステップ数の間、反復処理を行います。 -
step += 1: ステップカウンターをインクリメントします。
-
-
生成画像の更新:
-
update_image_with_style(generated_image, style_targets, content_targets, style_weight, var_weight, content_weight, optimizer): 生成画像をスタイル画像に近づけるように更新します。
-
-
中間画像の保存:
-
if (m + 1) % 10 == 0: 10ステップごとに中間生成画像を保存します。 -
images.append(generated_image): 生成画像をリストに追加します。
-
-
エポックごとの画像表示:
-
if show_transition:show_transitionがTrueの場合、各エポックの最後に生成画像を表示します。 -
display_fn(tensor_to_image(generated_image)): 生成画像を表示します。
-
-
最終生成画像の保存:
-
images.append(generated_image): 各エポックの最後に生成画像をリストに追加します。 -
print(f"Train step: {step}"): トレーニングステップを出力します。
-
-
最終生成画像の型変換:
-
generated_image = tf.cast(generated_image, dtype=tf.uint8): 最終生成画像をuint8型にキャストします。
-
-
結果の返却:
-
return generated_image, images: 最終生成画像と中間生成画像のリストを返します。
-
Example
それでは、これまでのコードを実際に実行して、任意のコンテンツ画像にNSTを適用していきましょう。パラメータの初期値は参考にしたコードのものを転用しました。
以下のコードは、スタイル転送を実行するための全体の設定を行い、実際にスタイル転送を実行します。スタイル画像とコンテンツ画像の読み込み、オプティマイザの設定、スタイル転送の実行、および結果の表示を含みます。
# Set the weights for style, content, and total variation losses
EPOCHS = 10
STEPS_PER_EPOCH = 100
STYLE_WEIGHT = 1e-1
CONTENT_WEIGHT = 1e-32
VAR_WEIGHT = 0
INITIAL_LEARNING_RATE = 80.0
DECAY_STEPS = 100
DECAY_RATE = 0.80
# Paths to the style and content images
style_path = '/content/style2.jpeg'
content_path = '/content/Steve.jpeg'
# Load the content and style images
content_image = load_img(content_path)
style_image = load_img(style_path)
# Define the Adam optimizer with exponential decay
adam = tf.optimizers.Adam(
tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=INITIAL_LEARNING_RATE, decay_steps=DECAY_STEPS, decay_rate=DECAY_RATE
)
)
# Perform style transfer
stylized_image_1, display_images_1 = fit_style_transfer(
style_image=style_image,
content_image=content_image,
style_weight=STYLE_WEIGHT,
content_weight=CONTENT_WEIGHT,
optimizer=adam,
epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
var_weight=VAR_WEIGHT,
show_transition=True
)
# Display the original and stylized images
show_images([style_image, content_image, stylized_image_1], titles=['Style Image', 'Content Image', 'Stylized Image'])
結果
上記のプログラムを実行したところ、下記のような結果(1部省略)が得られました。
元の画像の意味情報を保持しながら、スタイルをStyle Imageに近づけることができているのがわかります。すごい!

他の画像(ゴッホの「星月夜」と風景の写真)の組み合わせにも同様の処理を適用して遊んでみました。

(所感)
......なんか、コンテンツ画像の主張激しくない...?
同じ条件(重み)下では、コンテンツ画像のカラーによってスタイルの適用のされ方が変わっているように感じました。
(コンテンツ画像が前者のようなグレースケール画像であれば、後者の結果と比較して、スタイルの適用による画像の変換(見た目)が大きい。)
なので、スタイルによる画像変換におけるスタイル画像の影響を大きくしましょう!!(で、やってみたのが下図です (^~~^)/ コッチノホウガスキィェェェ)
パラメータ(重みの初期値)の変更
例えば、スタイル重み(STYLE_WEIGHT)を 1e-1 から 1e1 に増やすことで、スタイル画像の影響を大きくすることができます。

(参考)
グレースケール画像を入力(パラメータの変更はなし)
個人的にはこちらも好きです

まとめ
いかがだったでしょうか?今回は、Neural Style Transferを実装する手順を詳しく解説しました。実際に実装を行ってみた感想として、スタイル画像とコンテンツ画像の特徴を組み合わせるプロセスは非常に興味深く、深層学習の奥深さを感じました。生成された画像が徐々にスタイル画像の特徴を取り入れていく過程を見るのは、とても感動的でした。
次に挑戦してみたいこととしては、より高度なスタイル転送を実現するために、異なるモデルやアーキテクチャを試してみることです。また、リアルタイムスタイル転送の実現や、動画への適用など、さらに応用範囲を広げてみたいと考えています。皆さんもぜひ、自分なりのスタイル転送を試してみてください。
参考文献