はじめに##
TFLearnを使ってみました。
データセットはsuperdatascience.comのPart1からダウンロードできます。Churn_Modeling.csvという割と有名なデータセットです。
この記事の流れ
1、TFLearnの概要
2、全体のコード
3、局所のコード解説
4、考察
5、比較のためのTensorflowで書いたコード
「コード、もっとこうしたほうがいいよ!」という方がいましたら、是非ともコメント欄で教えて頂けると有難いです。変えることに基本、ウェルカムです。
TFLearnってそもそも何なのか##
公式ドキュメントによると、TFLearnは深層学習ライブラリで、Tensorflow向けのHigh-level APIです。High-level とは抽象度が高いという意味です。ニューラルネットワーク層、オプティマイザ等がビルトインされており、その他、深層学習実装のために便利な関数が用意されています。結果、Tensorflowより簡潔なコードで深層学習を行うことができます。一括りにするのはいけないですが、Kerasのようなものです。
全体コード##
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.callbacks import TensorBoard
import tflearn
from tflearn.data_utils import load_csv
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.preprocessing import StandardScaler
# from sklearn.model_selection import train_test_split
# データの前処理
def pre_processing(x):
x = x.iloc[:, 3:13].values
label_encoder_x_1 = LabelEncoder()
x[:, 1] = label_encoder_x_1.fit_transform(x[:, 1])
label_encoder_x_2 = LabelEncoder()
x[:, 2] = label_encoder_x_2.fit_transform(x[:, 2])
onehotencoder = OneHotEncoder(categorical_features = [1])
x = onehotencoder.fit_transform(x).toarray()
x = x[:, 1:]
return x
# スケール調整
def scaling(x):
sc = StandardScaler()
x = sc.fit_transform(x)
return x
# ネットワーク構築
def init_network():
net = tflearn.input_data(shape=[None, 11])
net = tflearn.fully_connected(net, 6, activation='relu')
net = tflearn.fully_connected(net, 6, activation='relu')
net = tflearn.fully_connected(net, 2, activation='softmax')
net = tflearn.regression(net, optimizer='adam', loss='categorical_crossentropy', learning_rate=0.001)
return net
x, y = load_csv('a.csv', target_column=13, categorical_labels=True, n_classes=2)
x = pd.DataFrame(x, dtype='float')
x = pre_processing(x)
x = scaling(x)
# ニューラルネットワークの初期化
net = init_network()
# モデル構築
model = tflearn.DNN(net, tensorboard_verbose=2, tensorboard_dir='log')
# トレーニング開始
model.fit(x, y, n_epoch=100, batch_size=10, show_metric=True, validation_set=0.2)
# tensorboard --logdir=./log
ついでに結果も
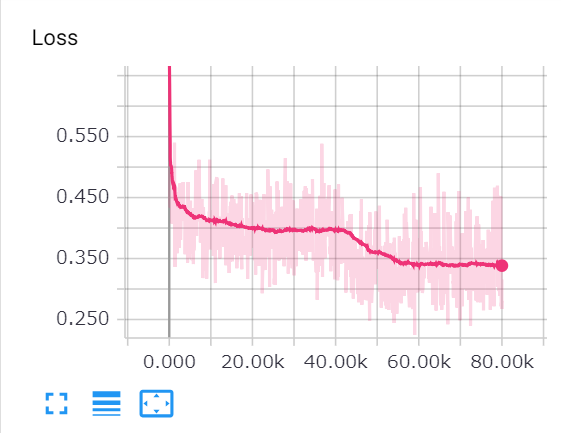
当たり前ですが、keras、tensorflow、TFLearnでも大体同じ結果になりました。Lossは0.35、Accuracyは0.85ぐらいです。パラメーターチューニングは行っていないので、悪くない結果です。
局所のコード解説##
x, y = load_csv('a.csv', target_column=13, categorical_labels=True, n_classes=2)
TFLearnでは独自のcsvを読み込む関数があります。target_columnは、どの縦列がyの値なのかを指定しています。この場合は、銀行を去ったか否か(0か1)がyの値です。またcategorical_labelsはTrueにするとyの値がバイナリ表記のベクターで返ってきます。yの値が0と1の2種類あるのでn_classesを2にします。そうするとyは[[0 1] [1 0] [1 0]]のようにyの値を[Exit NotExit]で表せます。これはSoftmaxを使うために二つのクラスが必要だからです。これを省くと[0 1 1]のように値が1つ返ってきます。
model = tflearn.DNN(net, tensorboard_verbose=2, tensorboard_dir='log')
TFLearnではDNNという既に標準の機能を持ったモデルがあります(モデルラッパー)。これはTFLearnにあるモデルクラスで、既に定義されている関数を使うことで、データの訓練や予測、モデルの保存などを容易に行うことができます。引数であるtensorboatd_verboseはレベル0でLoss, Accuracy、レベル1でLoss, Accuracy, Gradients。レベル2でLoss, Accuracy, Gradients, Weights。レベル3でLoss, Accuracy, Gradients, Weights, Activations, SparsityをそれぞれTensorboardに表示します。tensorboard_dirはお馴染みのTensorboard用のEventファイルを置く場所です。
model.fit(x, y, n_epoch=100, batch_size=10, show_metric=True, validation_set=0.2)
DNNクラス内にあるfit()関数を使ってます。fit()関数はモデルを訓練するときに使う関数です。引数にx(features)とy(label)を書きます。show_metric=Trueにすることで、訓練時にlossやaccuracyをコマンドに出力します。validation_set=0.2にすることでvalidation set、つまりy(ラベル)分のデータを全体から0.2の割合だけ取ります。
def init_network():
input = tflearn.input_data(shape=[None, 11])
layer_1 = tflearn.fully_connected(input, 6, activation='relu')
layer_2 = tflearn.fully_connected(layer_1, 6, activation='relu')
output_layer = tflearn.fully_connected(layer_2, 2, activation='softmax')
output_layer = tflearn.regression(output_layer, optimizer='adam', loss='categorical_crossentropy')
return output_layer
input_data()は一番初めのインプット層を表しています。引数に[データの数, xの要素数(feature数)]としますので、[None, 11]と書きます。Noneは「まだ決まっていないけど、どんな数でも受け入れるよ」という意味です。データの数を10ずつ処理するために、10個のデータを渡せば[None, 11]は[10, 11]に変化し、一度に処理するため1万個のデータを渡せば[None, 11]は[10000, 11]に変化します。Noneと指定したのは、データ数の受け入れに柔軟性を与えるためです。xの要素数である11は変わらないので指定します。
fully_connectedはその名の通り、全結合層(アフィン層)です。引数は(前の層から得たテンソル、ニューロンの数、活性化関数)です。ここではニューロンの数を6に指定しています(特に意味はありません)。
tflearn.regression(output_layer, optimizer='adam', loss='categorical_crossentropy', learning_rate=0.001)
ですが、これは推測層(Estimate Layer)です。ここでオプティマイザや損失関数、学習率を指定します。それぞれデフォルトの値があり、オプティマイザはAdam、損失関数はcategorical_crossentropy 学習率は0.001です。ここでは見やすさからわざと各々の値を指定しています。
ロスの引数ですがcategorical_crossentropyをここでは使います。(知っている方は読み飛ばしてもらって構いませんが)categorical_crossentropyはソフトマックス関数時に使う交差エントロピーです。カテゴリーと書いてあるのは、カテゴリーごとにソフトマックス関数が確率を出すからです。他にもbinary_crossentropyがあります。これはシグモイド関数時に使う交差エントロピーです。
考察##
使ってみた感じ、Kerasのように簡単にコードが組めます。とりあえずTensorflowとTFLearnを使ってみて感じたことをずらずら書いていきます。
1、最後の行のmodel.fit()のvalidation_setで訓練データとテストデータを分けられるのは便利。sklearnのtrain_test_split関数が必要ない。
2、tensorboardの表示がまとめられていて、lossやaccuracy等の値の確認がやりやすい。
3、バッチ処理もコードに起こさなくて便利。lossやaccuracyも簡単に表示できる。
4、DNN(モデルラッパー)を使えばデータの訓練、予測、セーブ等が簡単かつ簡潔に実装できる。
5、当たり前ですが、コードが見やすいし、簡単に何をやっているのか理解できる。
余談ですが、Kerasと比べてみるとTFLearnはTensorflowにより近いのでTensorflowとのコミュニケーションが取りやすいというのは巷でよく聞く意見です。
ただそれぞれ長所短所があり、どちらが優位というのは無いです。ソースとサポートの観点で言ってしまえば、kerasの方が断然使いやすいですが、他にも様々な利点と欠点があるようなので使いどころが少し違うのでしょう。
Tensorflowとの比較##
from __future__ import print_function
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.callbacks import TensorBoard
import tflearn
from tflearn.data_utils import load_csv
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
def pre_processing(x):
x = x.iloc[:, 3:13].values
label_encoder_x_1 = LabelEncoder()
x[:, 1] = label_encoder_x_1.fit_transform(x[:, 1])
label_encoder_x_2 = LabelEncoder()
x[:, 2] = label_encoder_x_2.fit_transform(x[:, 2])
onehotencoder = OneHotEncoder(categorical_features = [1])
x = onehotencoder.fit_transform(x).toarray()
x = x[:, 1:]
return x
def scaling(x):
sc = StandardScaler()
x = sc.fit_transform(x)
return x
def init_network():
#各々の層の設定
layer_1 = tf.add(tf.matmul(X, weights['w1']), biases['b1'])
layer_1 = tf.nn.relu(layer_1)
layer_2 = tf.add(tf.matmul(layer_1, weights['w2']), biases['b2'])
layer_2 = tf.nn.relu(layer_2)
output_layer = tf.add(tf.matmul(layer_2, weights['out']), biases['out'])
return output_layer
x, y = load_csv('a.csv', target_column=13, categorical_labels=True, n_classes=2)
x = pd.DataFrame(x, dtype='float') #前処理のためにデータフレームを作る
x = pre_processing(x)
x = scaling(x)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
# パラメータ
learning_rate = 0.001
num_steps = 1000
batch_size = 10
display_step = 100
epochs = 100
# ネットワーク内のパラメータ
n_hidden_1 = 6 #1つ目の層のニューロン数
n_hidden_2 = 6 #2つ目の層のニューロン数
num_input = 11 #インプットのニューロン数
num_classes = 2 #yのクラス数 (0(Not Exit) と 1(exit))
# グラフへのインプット
X = tf.placeholder("float", [None, num_input])
Y = tf.placeholder("float", [None, num_classes])
# 重みとバイアス
weights = {
'w1': tf.Variable(tf.random_normal([num_input, n_hidden_1])),
'w2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_hidden_2, num_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'b2': tf.Variable(tf.random_normal([n_hidden_2])),
'out': tf.Variable(tf.random_normal([num_classes]))
}
logits = init_network()
prediction = tf.nn.softmax(logits)
# ロスとオプティマイザ
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=Y))
tf.summary.scalar('loss', cost)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(cost)
# モデル評価
correct_pred = tf.equal(tf.argmax(prediction, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# Tensorboard用コード
merged = tf.summary.merge_all()
# バッチ処理 (イテレータ使用)
batch_x = tf.data.Dataset.from_tensor_slices(x_train).repeat().batch(batch_size)
batch_y = tf.data.Dataset.from_tensor_slices(y_train).repeat().batch(batch_size)
iterator_x = batch_x.make_initializable_iterator()
iterator_y = batch_y.make_initializable_iterator()
next_element_x = iterator_x.get_next()
next_element_y = iterator_y.get_next()
with tf.Session() as sess:
file_writer = tf.summary.FileWriter('./logs', sess.graph)
sess.run(iterator_x.initializer)
sess.run(iterator_y.initializer)
sess.run(tf.global_variables_initializer())
for i in range(epochs):
for step in range(1, num_steps+1):
batch_x = sess.run(next_element_x)
batch_y = sess.run(next_element_y)
sess.run(train_op, feed_dict={X: batch_x, Y: batch_y})
loss, acc, summary = sess.run([cost, accuracy, merged], feed_dict={X: batch_x, Y: batch_y})
file_writer.add_summary(summary, i)
print("Epoch " + str(i) + ", Step " + str(step) + ", Loss= " + \
"{:.4f}".format(loss) + ", Training Accuracy= " + "{:.3f}".format(acc))
#lossとaccuracyの計算
print("Testing Loss:", \
sess.run(cost, feed_dict={X: x_test, Y: y_test}))
print("Testing Accuracy:", \
sess.run(accuracy, feed_dict={X: x_test, Y: y_test}))
#tensorboard --logdir=./logs
バッチ処理はこのサイトを参考にしましたが、個人的にはコードをもっと簡潔にしたいですね。
参考文献##
TFLearn 公式ドキュメント http://tflearn.org/
Tensorflow Examples (Github) https://github.com/aymericdamien/TensorFlow-Examples
バッチ処理 https://towardsdatascience.com/how-to-use-dataset-in-tensorflow-c758ef9e4428
categorical_crossentropy と bainary_crossentropy https://gombru.github.io/2018/05/23/cross_entropy_loss/