はじめに###
この記事では、Tensorflow-GPUを無料で簡単にインストールして使う方法を紹介します。(グーグルクラウドで300ドルまで無料のトライアルを利用します)
グーグルクラウドは固定料金が無く、全て時間制なので、いつでもRe:ゼロから環境(インスタンス)を作り直せるのでお勧めです。
簡単3ステップ
1、CUDA9.0をインストール済みのVMインスタンスを作る。
2、cuDNNをインストールする。
3、Tensorflow-GPUをインストールする。
(基本的な流れやコードは、Tensorflowのドキュメントを参考にしています。
https://www.tensorflow.org/install/gpu?hl=ja
)
ステップ1に入る前に、一つ注意点。TensorflowとCUDA、cuDNNには、ある特定のバージョン同士でないと、エラーが出てしまうので注意しましょう。それと、Ubuntu.18.0.4は、CUDAが公式にサポートしていないので、Ubuntu.16.0.4を使います。
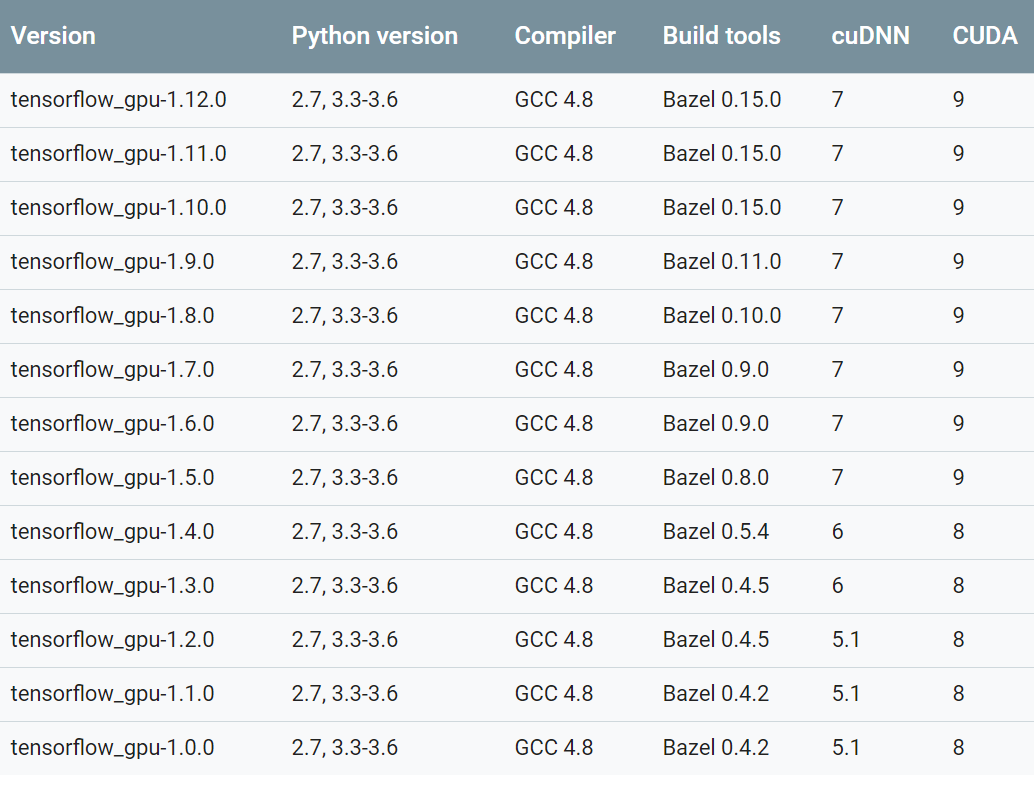
(参考:https://www.tensorflow.org/install/source#tested_source_configurations
)
CUDA9と書いてありますが、CUDA9.1は(9.0からのマイナーなアップデートで)現在Tensorflowがサポートしていないので、CUDA9.0を使ってください。
https://github.com/tensorflow/tensorflow/issues/15656
ただし、ソースから自分でビルドすれば、CUDA9.1、CUDA10でも使えるらしいので、やってみたい方はどうぞ。
私は公式に書いてある通り、CUDA9.0を使いました。
ステップ1###
最初に、グーグルアカウントでGCPに登録します。フリートライアルでまず登録し、その後、アカウントをアップグレードします。フリートライアルだとGPUは使えませんが、有料アカウントにアップグレードすれば、使えるようになります。ちなみに有料アカにアップグレードしても、フリートライアル分の300ドルは残っているので、例えGPUを使っても実質タダです。(グーグルさんに感謝)
グーグルアカウントの登録ができGCP内に入ったらインスタンスを生成する前に、デフォルトでGPUのユーザーへの割り当てが0に制限されているので、それを変更してくれるようにグーグルさんに頼みます。
IAM&adminのタブにある、割り当て(Quotas)というところをクリックします。
Metric内のチェックを一回全部外し、GPU(All regions)をチェック。その後、割り当てを編集(Edit Quotas)をクリックし、制限を1に変えて、グーグルに申請します。
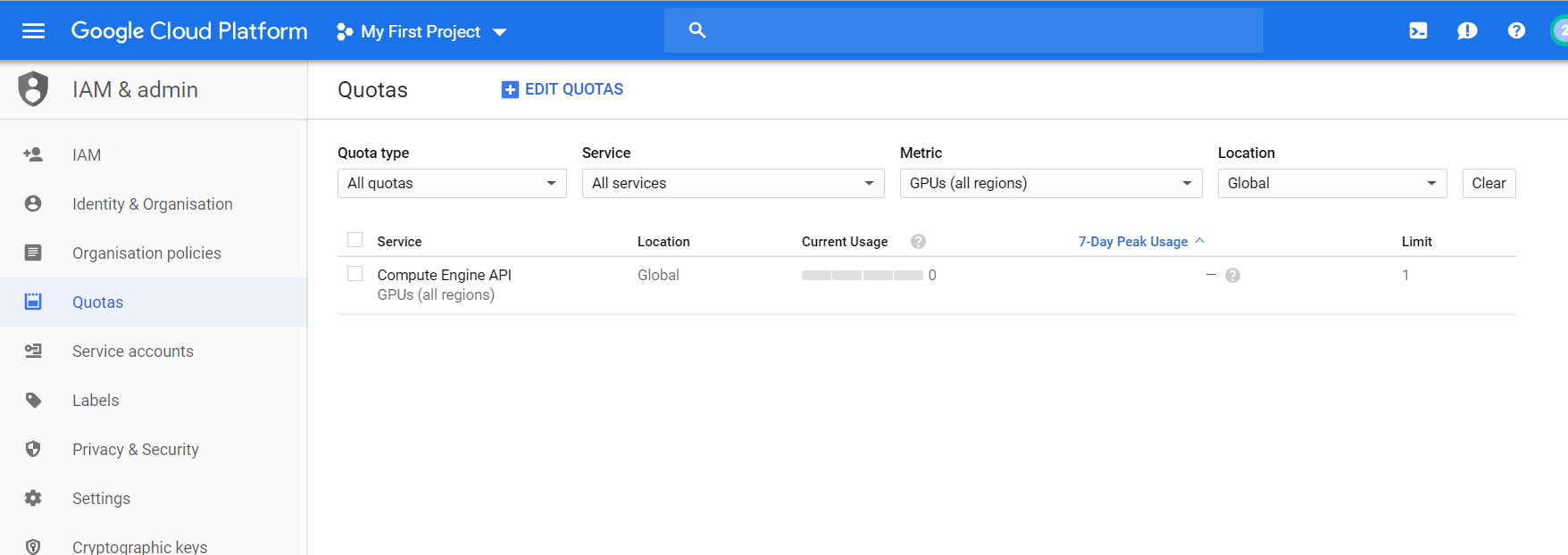
しばらく経って、認証されたら、VMインスタンスを作ります。
GCPのホーム画面から、Compute Engineをクリック。
VMインスタンスを作るをクリックします。
その後、ゾーン(a, b, c)を指定します。
(注意:ゾーンによって、GPU自体の利用や、利用できるGPUが違うことがあるので、確かめることを勧めます。)
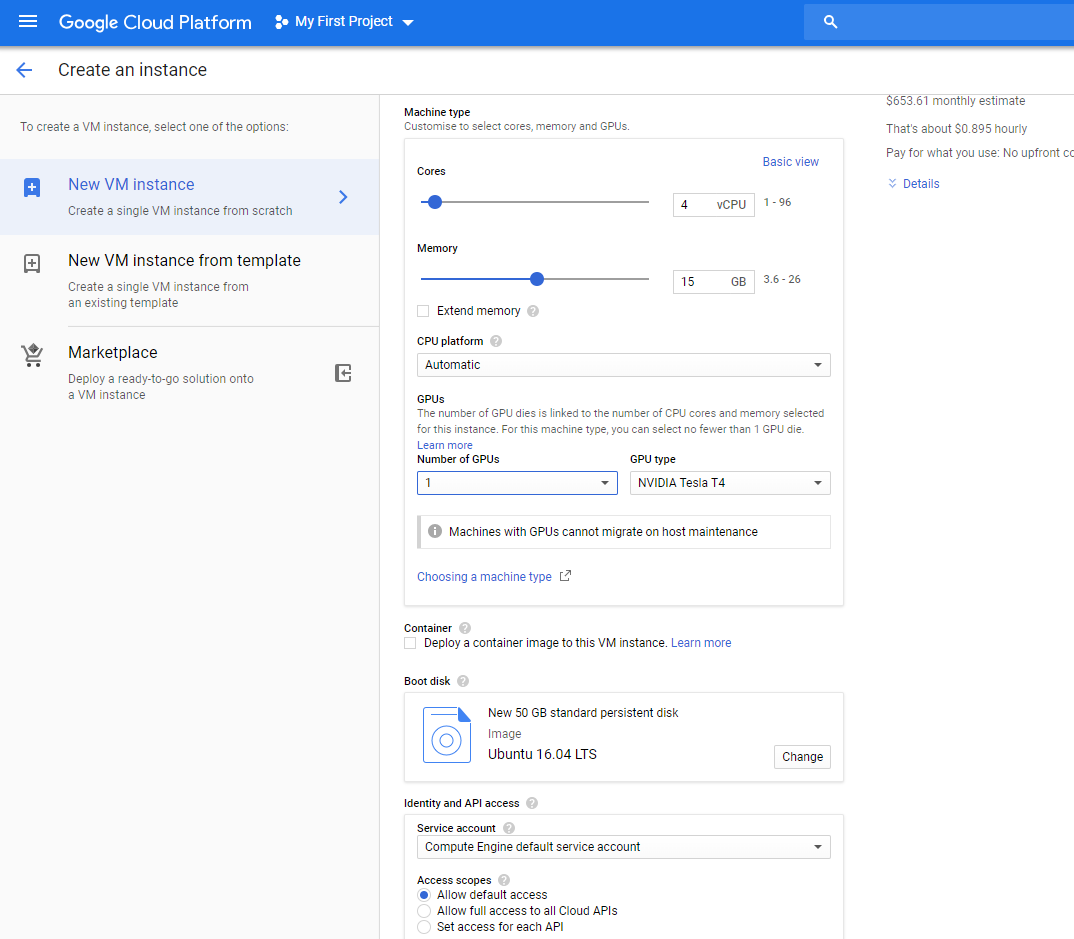
CPUのコア数は4個、15GBとします。
そして、カスタマイズをクリックして、自分の使いたいGPUを指定します。
その後、Debianとなっているところを、Ubuntu16.0.4に変更し、下のストレージがデフォルトで10GBとなっているので、自分の使うであろう分だけ増やします。私は50GBにしました。
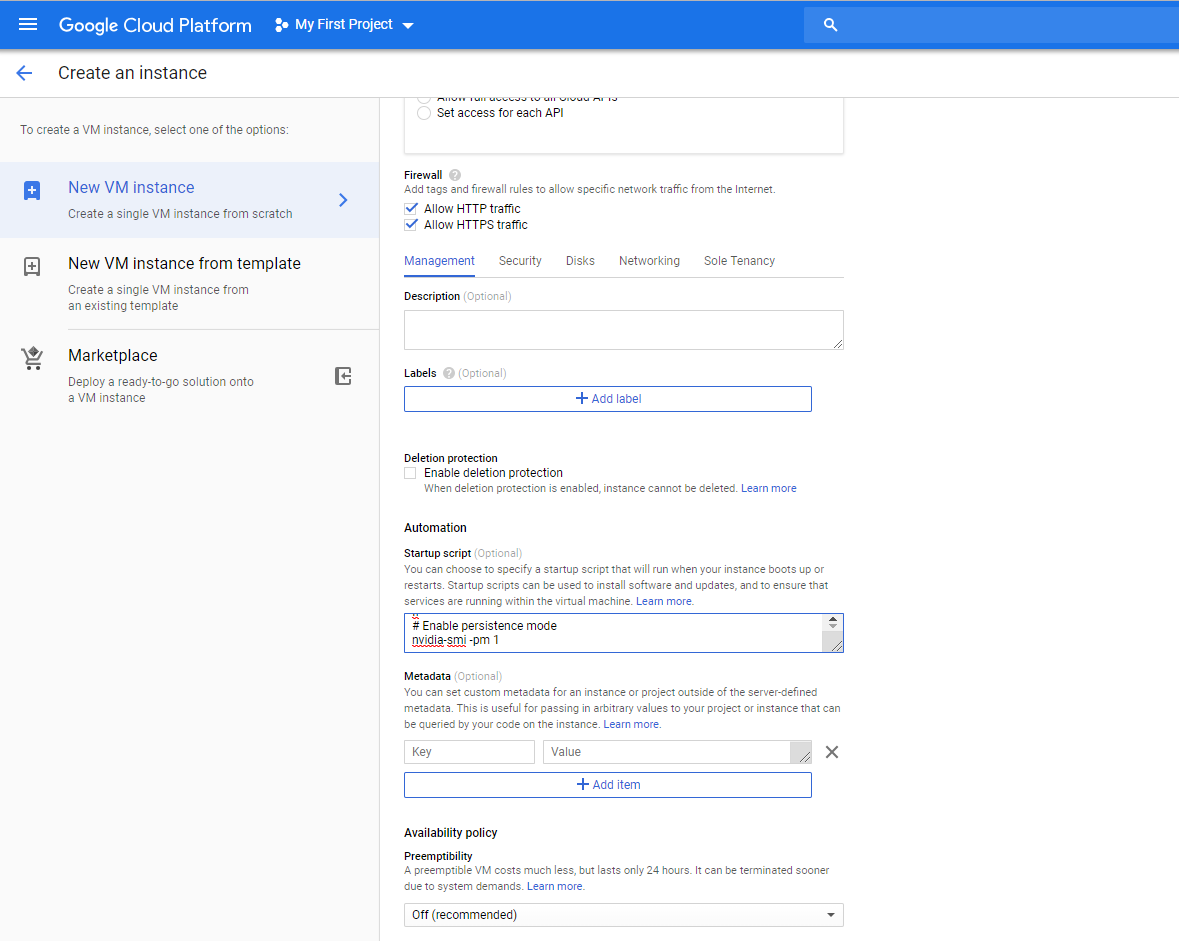
httpトラフィックとhttpsトラフィックのところをチェック。
次に、 Management, security, disks, networking, sole tenancyとかいうところを下に広げて、Start Scriptのところで、次のコードを書きます。
# !/bin/bash
echo "Checking for CUDA and installing."
# Check for CUDA and try to install.
if ! dpkg-query -W cuda-9-0; then
# The 16.04 installer works with 16.10.
curl -O http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_9.0.176-1_amd64.deb
dpkg -i ./cuda-repo-ubuntu1604_9.0.176-1_amd64.deb
apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub
apt-get update
apt-get install cuda-9-0 -y
fi
# Enable persistence mode
nvidia-smi -pm 1
(元:https://cloud.google.com/compute/docs/gpus/add-gpus
のGUPドライバのインストール)
スタートスクリプトを書くことで、シェルが起動したときに、自動でCUDAをインストールしてくれます。もちろん、手動でインストールすることもできますが、こちらの方が簡単なのでお勧めします。
インスタンス作成が完了したらgcloud SDKをローカルマシーンにダウンロードします。そしてローカルマシーンのコマンドから
gcloud init
を実行しconfigurationを作成。その後、VM Instance の画面に行き View gcloud commandをクリックします。
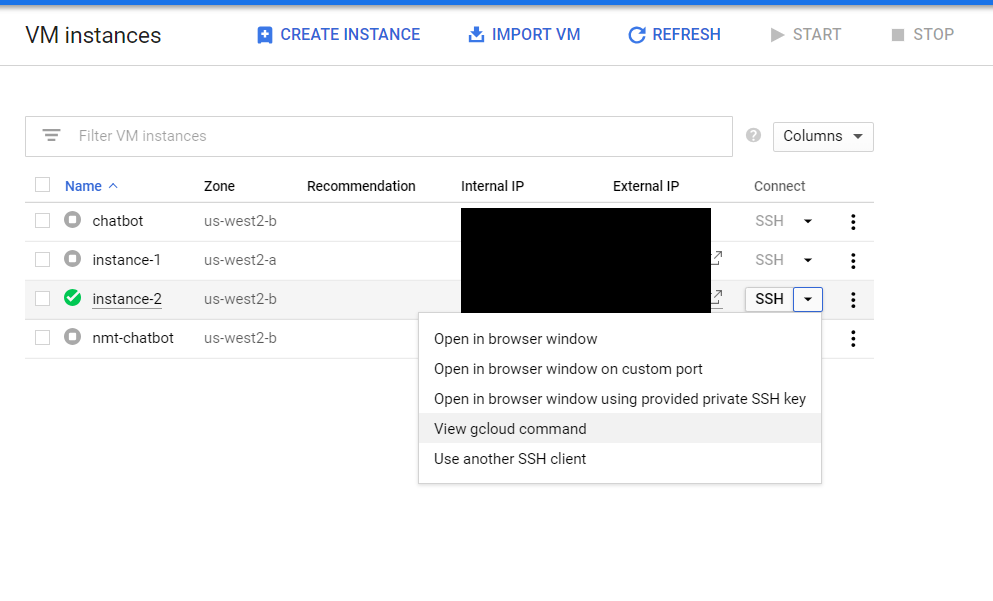
すると下記のような形式のコマンドが見れますので、それをコピー。
gcloud compute --project "プロジェクト名" ssh --zone "ゾーン" "インスタンス名"
そしてローカルマシーンでペーストして実行。これによりVirtual Machine(Instance)にSSH接続できます。
接続出来たら/usr/local/のパスに行き、CUDAフォルダがちゃんとあるか確認します。もし無い場合は、スタートスクリプトを再起動します。
sudo google_metadata_script_runner --script-type startup
(参考:https://cloud.google.com/compute/docs/startupscript#rerunthescript
)
ステップ2###
その後、https://developer.nvidia.com/rdp/cudnn-archive
に行き、cuDNNをローカルマシーンにダウンロードします。(ディベロッパーメンバーの登録なんちゃらがあるので、それを最初にします)
ディベロッパーアカウントを登録できたら、https://developer.nvidia.com/rdp/cudnn-download
cuDNN Download に行き、 I Agree To the Terms of the cuDNN Software License Agreementをチェック。最新のDownload cuDNN v7.4.1 (Dec 14, 2018), for CUDA 9.0の中の、cuDNN Library for Linuxをダウンロードします。
先ほどSSH接続したインスタンス内のコマンドプロンプトではなく、ローカルマシーンのコマンドプロンプトを開きます。
そしてこのコードを実行。
gcloud compute scp /Users/Desktop/cudnn-9.0-linux-x64-v7.1.tgz
ユーザーネーム@インスタンス名:~/
gcloud compute scp とは 「gcloudの中のcompute engine内にあるコマンドの中で、scpというコマンドを使って、ファイルをコピーしてくれ」という意味です。ローカルマシーンからVMにファイルをコピーしたいときに使います(逆も然り)。
最初のパスが自分のローカルにダウンロードしたcudnn-9.0-linux-x64-v7.1.tgzファイルで、二番目のパスが、VMインスタンス内のパスです。
(このコードを実行したときに「ディレクトリが見つからない」などのエラーが出た場合、ローカルマシーンのcudnnファイルがあるディレクトリーで実行するとできます。)
gcloud compute scp cudnn-9.0-linux-x64-v7.1.tgz ユーザーネーム@インスタンス名:~/
これでもエラーが出る場合は、
gcloud compute scp cudnn-9.0-linux-x64-v7.1.tgz ユーザーネーム@インスタンス名:/home/
で:~/の部分を:/home/に変えてトライしてみてください。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
これでもエラーが出るようであれば、gcp内にあるストレージ機能を利用します。ストレージ機能を使えば、ローカルからクラウドストレジにファイルをアップロードして、VMインスタンスから、そのファイルをダウンロードできます。
(参考:https://cloud.google.com/storage/features/
)
クラウドストレージにファイルをアップロードできたら、インスタンス内のコマンドプロンプトで下記のコードを使ってインスタンス内にコピーします。
gsutil cp gs://自分のバケット名/cudnn-9.0-linux-x64-v7.4.2.24.tgz .
# gsutil cp gs://forcudnn/cudnn-10.0-linux-x64-v7.4.2.24.solitairetheme8 .
/home/にコピーする場合は sudo gsutil cp~が必要です。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
その後エラー無く、インスタンス内にファイルをアップロードできたら
tar -xzvf cudnn-9.0-linux-x64-v7.4.2.24.tgz
# tar -xzvf cudnn-10.0-linux-x64-v7.4.2.24.solitairetheme8
パスが/home/なら、ユーザー権限の問題があるのでsudo tar~ とsudoを使います。
でファイルをインスタンス内に展開します。
そして、
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
を実行。(元:https://docs.nvidia.com/deeplearning/sdk/cudnn-install/index.html)
もし、このコードで「ディレクトリーが見つからない」などのエラーが出た場合は、
インスタンス内にある/home/username/cuda/include/のパスまで行って、コードを実行してください。(結構多発するエラーのようです)
sudo cp cudnn.h /usr/local/cuda/include
sudo cp libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
この一連の流れは、cudnnを展開したあとに生成されたCUDAファイル等の情報を、元々ダウンロードしていた/usr/local/cuda/にコピーしています。これにより、CUDAにcuDNNのライブラリを渡すことができます。
その後、次のコードを実行し、home直下のnanoエディタに入り、環境変数を追加します。
nano ~/.bashrc
bashrcとはbashという私たちが使っているシェルの設定ファイルのようなものです。
一番下の行まで↓矢印キーを押し続けます。
そしてこのコードを追加して、環境変数を設定します。
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/extras/CUPTI/lib64
export CUDA_HOME=/usr/local/cuda
1行目がCUDA内にあるCUPTIための環境変数。2行目は念のためにCUDA自体の環境変数を追加しています。
Ctrl+Xで保存して、変更するかどうか聞かれるので、Yを押して、その後はEnter。
そして、もう一度、nanoエディタに入って、ちゃんと入っているか、確認します
もし環境変数を入れるのに失敗した場合は、コマンドからも追加できます。(こっちの方が楽かも)
echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/extras/CUPTI/lib64' >> ~/.bashrc
echo 'export CUDA_HOME=/usr/local/cuda' >> ~/.bashrc
あるのを確認した後、リロードします。
source ~/.bashrc
ステップ3###
その後、python3-devとpython3-pipをインストールします。(Tensorflowドキュメントから https://www.tensorflow.org/install/pip
)
sudo apt-get update
sudo apt install python3-dev python3-pip
Tensorflow-gpuをインストール。
pip3 install --user --upgrade tensorflow-gpu
これができたら、他にも使いそうなpipパッケージをインストールします。
pip3 install numpy scipy matplotlib ipython pandas matplotlib sklearn keras
おしまい
追記: (Tensorflow-gpu 1.13.1~)###
新しいバージョンのTensorflow-gpu 1.13.1はCUDA10対応なので、CUDA10のstart scriptを取ってきてください。またCuDNNもCUDA10対応のバージョンをダウンロードしてください。
# !/bin/bash
echo "Checking for CUDA and installing."
# Check for CUDA and try to install.
if ! dpkg-query -W cuda-10-0; then
# The 16.04 installer works with 16.10.
curl -O http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_10.0.130-1_amd64.deb
dpkg -i ./cuda-repo-ubuntu1604_10.0.130-1_amd64.deb
apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub
apt-get update
apt-get install cuda-10-0 -y
fi
# Enable persistence mode
nvidia-smi -pm 1
フォルダのアップロード
gsutil cp -r gs://bucket_name/folder .
自分用
gsutil cp gs://forcudnn/cudnn-10.0-linux-x64-v7.4.2.24.solitairetheme8 .
tar -xzvf cudnn-10.0-linux-x64-v7.4.2.24.solitairetheme8
sudo cp cudnn.h /usr/local/cuda-10.0/include
sudo cp libcudnn* /usr/local/cuda-10.0/lib64
sudo cp cudnn.h /usr/local/cuda/include
sudo cp libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda-10.0/include/cudnn.h /usr/local/cuda-10.0/lib64/libcudnn*
echo 'export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-10.0/extras/CUPTI/lib64' >> ~/.bashrc
echo 'export CUDA_HOME=/usr/local/cuda-10.0' >> ~/.bashrc
source ~/.bashrc
sudo apt-get update
sudo apt install python3-dev python3-pip
pip3 install --user --upgrade tensorflow-gpu
pip3 install numpy scipy matplotlib ipython pandas matplotlib sklearn keras