これなに?
F81アドベントカレンダー二日目担当の長谷川です。
BQMLに新たに追加されたTRANSFORM句についての解説します。2019/12/2時点で、まだ日本語の公式ドキュメントが存在しないことから、記事にしようと思いました。なお、現時点ではまだこの機能はBetaです。英語の公式ドキュメントは存在するので、興味があれば、こちらも参考することをお勧めします。
今回の記事では、BigQuery(ML)の基本事項は一切説明しません。BQMLで使用できる関数などについては前記事を参照してください。
TRANSFORM句とは?
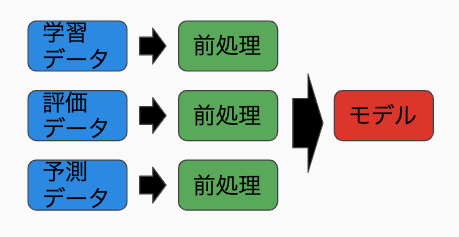
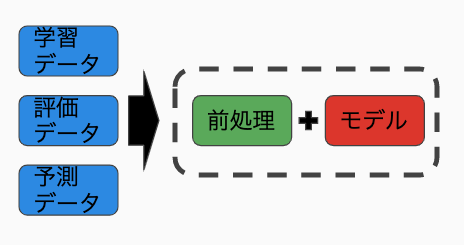
行いたい前処理をモデル構築時に定義し、予測、評価時に自動的に実行するためにしようするSQLの句(clause)です。
これにより、BQMLで作成するアルゴリズムとそれに伴う前処理を一体化させ、モデルを構築することができます。
前処理をモデルの中に集約し、隠蔽できるので、モデルを使う側は行われる前処理について何も知らなくても良くなります。
イメージはこんなかんじ
- 使わない場合
- 使う場合
具体例
今回は例として、bigquery-public-data.samples.natality 配下にある、新生児のデータを使用し、出産時の体重を目的変数とするモデルを構築してみたいと思います
SELECT
weight_pounds, -- 目的変数
is_male, --性別
plurality,--出産で生まれた子供の数
gestation_weeks, -- 妊娠期間
alcohol_use,-- 母親が飲酒してたか
cigarette_use -- 母親がタバコを吸っていたか
FROM
`bigquery-public-data.samples.natality`
LIMIT
5
| weight_pounds | is_male | plurality | gestation_weeks | alcohol_use | cigarette_use | |
|---|---|---|---|---|---|---|
| 0 | 7.625790 | True | NaN | 38 | None | None |
| 1 | 7.438397 | False | 1.0 | 38 | None | None |
| 2 | 8.437091 | False | 1.0 | 41 | None | None |
| 3 | 7.374463 | True | 1.0 | 99 | None | None |
| 4 | 5.813590 | False | 1.0 | 99 | None | None |
BQMLの場合、そのままデータを入力しても基本的な前処理は自動で行ってくれますが、自分で特徴量を作成したほうがより良い精度が期待できます。
そこで、以下のような特徴量を作成します。
- 多胎児で生まれたか否か
- 妊娠期間が(一般的な期間である)37-42週に当てはまっているかどうか
- (母親が)アルコールを摂取していたかと、タバコを吸っていたかの交差特徴量
SELECT
weight_pounds,
is_male,
IF(plurality > 1, 1, 0) AS plurality,
ML.BUCKETIZE(gestation_weeks, [37, 42]) AS gestation_weeks,
ML.FEATURE_CROSS(
STRUCT(
CAST(alcohol_use AS STRING) AS alcohol_use,
CAST(cigarette_use AS STRING) AS cigarette_use
)
) AS alcohol_cigarette_use
FROM
`bigquery-public-data.samples.natality`
LIMIT
5
| weight_pounds | is_male | plurality | gestation_weeks | alcohol_cigarette_use | |
|---|---|---|---|---|---|
| 0 | 6.311835 | False | 0 | bin_2 | {'alcohol_use_cigarette_use': 'true_true'} |
| 1 | 6.062712 | True | 0 | bin_2 | {'alcohol_use_cigarette_use': None} |
| 2 | 8.728101 | False | 0 | bin_2 | {'alcohol_use_cigarette_use': 'true_true'} |
| 3 | 6.946766 | True | 0 | bin_2 | {'alcohol_use_cigarette_use': 'true_true'} |
| 4 | 6.999677 | True | 0 | bin_2 | {'alcohol_use_cigarette_use': 'true_true'} |
上記の関数については、公式ドキュメントか、以前の記事を参照してください。
さて、問題はここからです。上記の処理をした上でモデルに食わせ、学習させる必要がありますが、そのままだと、評価、予測時に,もう一度同じ前処理を行った上でモデルに入力する必要があります。
これだと、二度同じ処理が発生するともに、うっかり学習時と違う処理をしてしまったりして、面倒なバグを生む温床になりかねません
学習(TRANSFORM句を使わない)
-- TRANSFORM句を使わない場合
CREATE MODEL `transform_tutorial.natality_model` OPTIONS (
model_type = 'linear_reg',
input_label_cols = ['weight_pounds']
) AS
SELECT
weight_pounds,
is_male,
IF(plurality > 1, 1, 0) AS plurality,
ML.BUCKETIZE(gestation_weeks, [37, 42]) AS gestation_weeks,
ML.FEATURE_CROSS(
STRUCT(
CAST(alcohol_use AS STRING) AS alcohol_use,
CAST(cigarette_use AS STRING) AS cigarette_use
)
) AS alcohol_cigarette_use
FROM
`bigquery-public-data.samples.natality`
WHERE
weight_pounds IS NOT NULL
AND RAND() < 0.001 -- 適当にサンプリング
予測
-- TRANSFORM句を使わない場合
SELECT
predicted_weight_pounds
FROM
ML.PREDICT(
MODEL `transform_tutorial.natality_model`,
(
SELECT
is_male,
-- イチイチ同じ前処理を実行しなければいけない
IF(plurality > 1, 1, 0) AS plurality,
ML.BUCKETIZE(gestation_weeks, [37, 42]) AS gestation_weeks,
ML.FEATURE_CROSS(
STRUCT(
CAST(alcohol_use AS STRING) AS alcohol_use,
CAST(cigarette_use AS STRING) AS cigarette_use
)
) AS alcohol_cigarette_use
FROM
`bigquery-public-data.samples.natality`
LIMIT
5
)
)
| predicted_weight_pounds | |
|---|---|
| 0 | 7.658442 |
| 1 | 7.385880 |
| 2 | 7.385880 |
| 3 | 7.385880 |
| 4 | 7.385880 |
同じ前処理を予測時にも行わければいけないため、メンドイですね。
TRANSFORMを使う
そこで、TRANSFORM句の出番です。モデル学習時に、以下のように行う前処理の関数とともに定義します。
学習(TRANSFORM句を使用)
CREATE MODEL `transform_tutorial.natality_model_with_trans` TRANSFORM(
-- 前処理の関数を定義
weight_pounds,
is_male,
IF(plurality > 1, 1, 0) AS plurality,
ML.BUCKETIZE(gestation_weeks, [37, 42]) AS gestation_weeks,
ML.FEATURE_CROSS(
STRUCT(
CAST(alcohol_use AS STRING) AS alcohol_use,
CAST(cigarette_use AS STRING) AS cigarette_use
)
) AS alcohol_cigarette_use
) OPTIONS (
model_type = 'linear_reg',
input_label_cols = ['weight_pounds']
) AS
SELECT
*
FROM
`bigquery-public-data.samples.natality`
WHERE
weight_pounds IS NOT NULL -- 適当にサンプリング
AND RAND() < 0.001
予測
SELECT
predicted_weight_pounds
FROM
ML.PREDICT(
MODEL `transform_tutorial.natality_model_with_trans`,
(
SELECT *
FROM
`bigquery-public-data.samples.natality`
LIMIT
5
)
)
| predicted_weight_pounds | |
|---|---|
| 0 | 7.646798 |
| 1 | 7.376921 |
| 2 | 7.376921 |
| 3 | 7.715983 |
| 4 | 7.446106 |
TRANSFORM句を使わない場合と比較すると、元のデータを読み込ませるだけで自動的に前処理が実行されるので、予測のクエリがだいぶ簡略化できますね。 また、モデルの評価のときも同様に前処理を省略できます。さらに、前処理について何も知らなくても、ただ生データを読み込ませるだけで良いので、モデルの使い勝手がいいです
最後に
BQMLはまだサービスを開始してから間もないですが、続々と新しいアルゴリズム、前処理用の関数などが出てきています。これからも新しい機能が発表されたらまたまとめてきたいです。