機械学習、データサイエンス分野ではおなじみのkaggleですが、MNISTやタイタニック号の記事は多数あり、賞金獲得の可能性のあるコンペティションをリアルタイムに進行している様子(コンペティション中はソースコードを公開できないので事後ではあります)を記事に書いてみようと思いました。
結論から言いますと、全然思うようにはいきませんでした。
私自身初めてのkaggleなので粗末なところがありますがご容赦ください。
| 実行環境 | |
|---|---|
| python | 3.6.5 |
| Anaconda | 4.5.1 |
| chainer | 4.2.0 |
1日目
Kaggleにサインアップ〜Competitionに登録
Googleアカウントなどがあれば簡単にアカウントは作成できます。Competitionに参加するまでは以下の記事が参考になったので掲載させていただきます。
Kaggle事始め
https://qiita.com/taka4sato/items/802c494fdebeaa7f43b7
↓ログイン後のトップページ
↓コンペティション一覧ページ
コンペを選んで「Join Competition」をクリックし、規約に同意すると参加完了です。
参加した「Home Credit Default Risk Competition」は、2018/8/29 11:59 PM (UTC)が最終締め切りでした。
https://www.kaggle.com/c/home-credit-default-risk
データの取得/概要
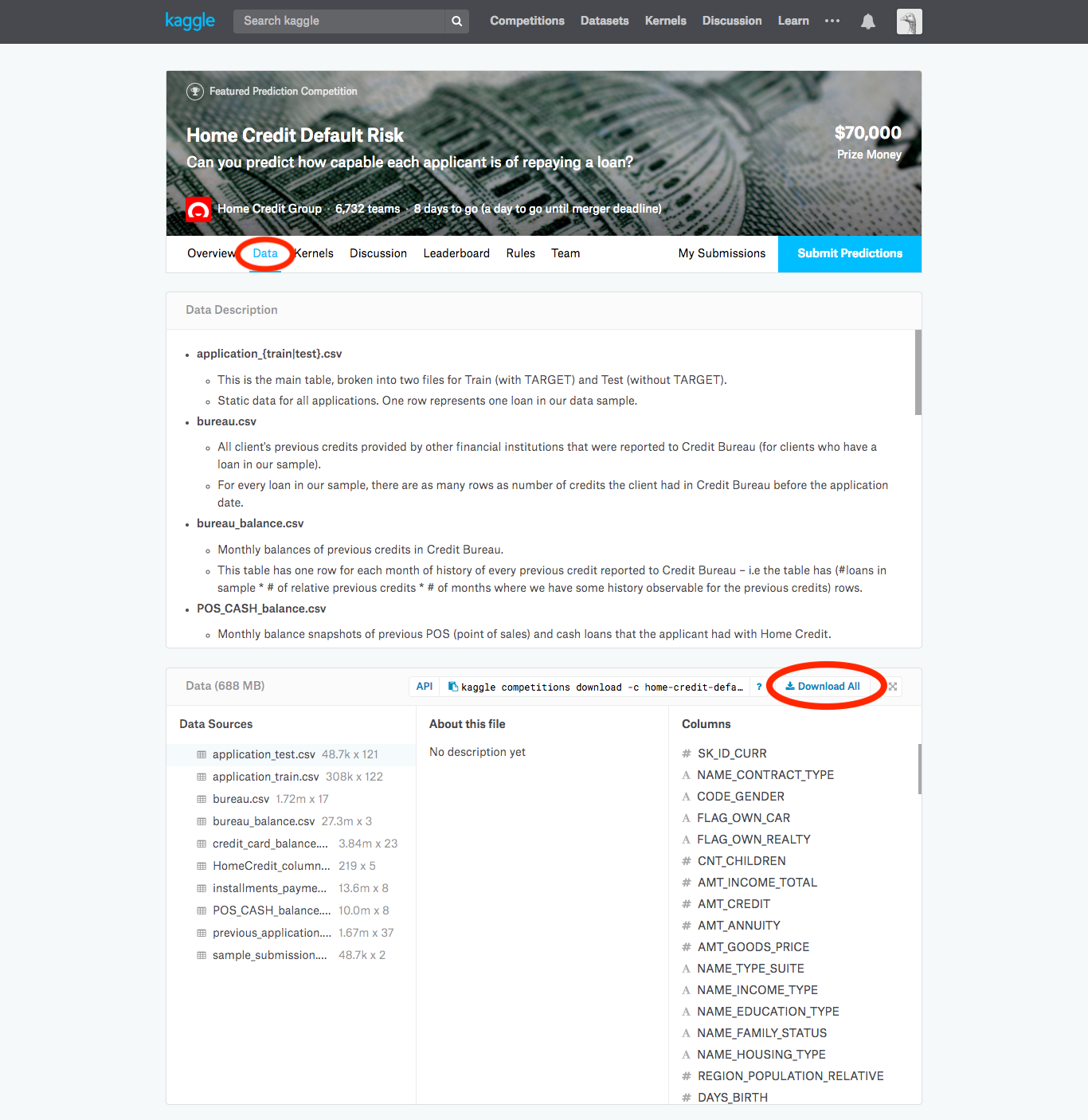
コンペのページのDataタブから、Download allをクリックするとcsvファイルがダウンロードできます。重いので時間がかかりました。
今回行ったHome Credit Default Riskのデータは、大雑把に説明すると、ある顧客がローンを支払い出来るか出来ないかを予測するという問題です。顧客の家族が何人、車は所有しており何年目、ローンのサービスを何度利用したか、などが複数のファイルに分かれて記録されていました。以下が各ファイルの関係性です。
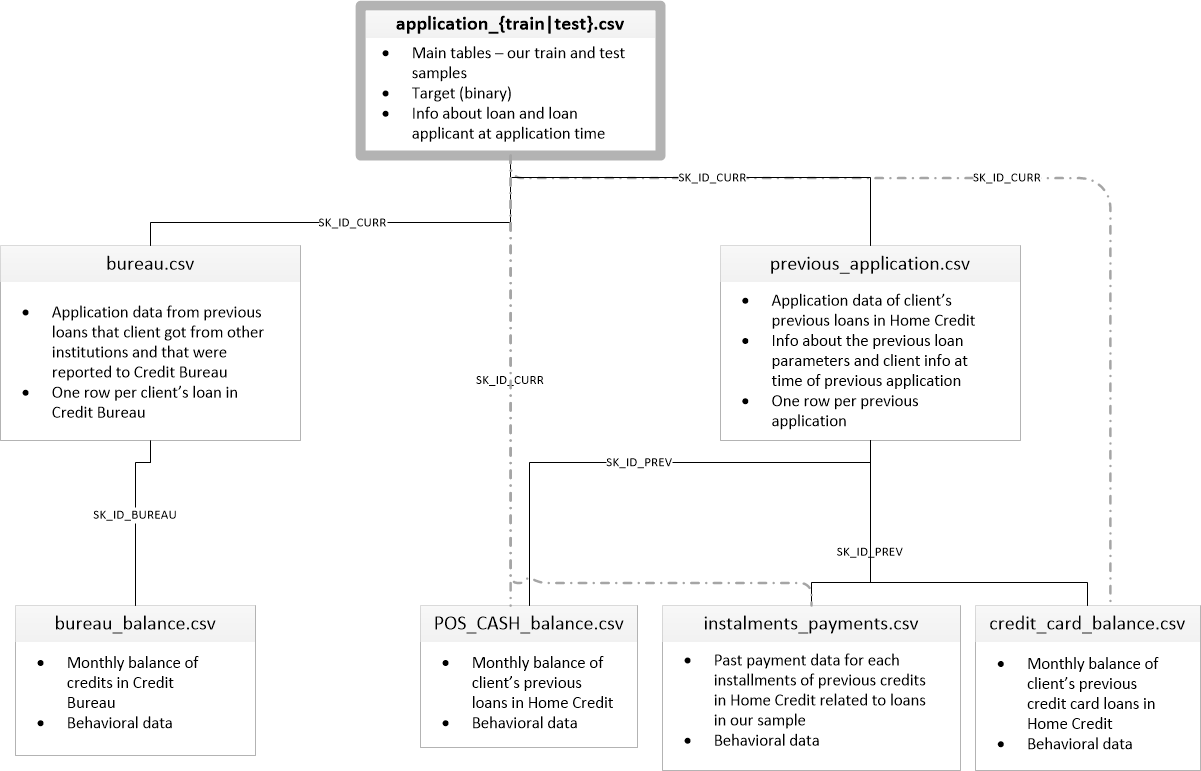
application_train.csvには顧客一人一人の主要な情報(性別や家族の人数、ローンのタイプ(現金or資産運用など?)、資産額、車の有無など)と、ある期間までにローンの支払いができたら0、できなかったら1のラベルがついています。application_test.csvにはラベルが無く、このファイルのデータの予測を提出するということでありました。
まずapplication_train.csvのみで学習・検証を行い、どれほどの分類ができるのか試してみようと考えました。
2~3日目
データの操作
データの操作(欠損の補間、複数ファイルの結合など)は、データ処理用のライブラリであるpandasを用いました。
データの偏り
まずクラス数に偏りがあるか確かめてみると、
import pandas as pd
import matplotlib.pyplot as plt
train_df = pd.read_csv(traindata_directory)
count = pd.value_counts(train_df['TARGET'], sort = True)
count.plot(kind = 'bar', rot=0, figsize = (10,6))
plt.xticks(range(2), ["0","1"])
plt.savefig("result/target.png")
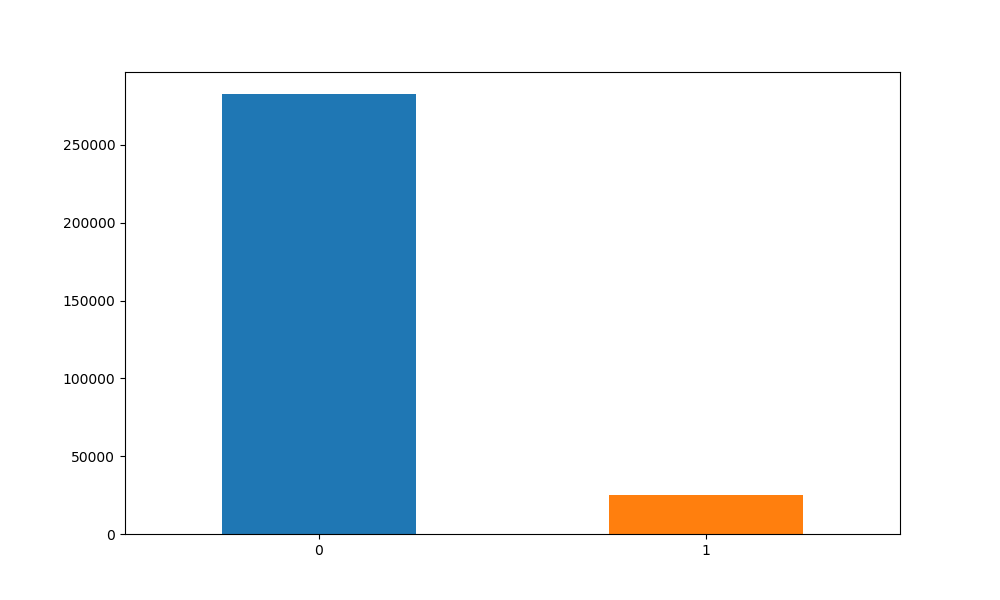
かなりターゲットとなるデータが少ないので、このまま学習するとおそらく全て0(支払いできた)を出力してしまうと考え、アンダーサンプリング(件数の多いクラスの中から一部のデータのみを学習に使用)をして、同数のデータを入力して学習しようと考えました。
データの欠損
データの欠損がみられたので補間が必要でした。欠損率が6割以上のデータは使用しないようにし、マルチラベルのデータは最頻値、それ以外の数値データは平均値で欠損部分を補間しました。
#補間・置換(train)
null_sum = 0
for col in train.columns:
#欠損の補間
null_sum = train[col].isnull().sum()
if null_sum > 0:
if null_sum/train_length >= 0.6:
drop_flag = True
else:
if train[col].dtype == object:
train[col] = train[col].fillna(train[col].mode()[0])
else:
train[col] = train[col].fillna(train[col].mean())
#不要列の削除
if drop_flag:
train = train.drop(col, axis=1)
One-Hot Encoding
顧客情報の性別やローンのタイプは文字でマルチラベルがついており、これをone-hotに変換して機械学習モデルに入力しようと考えました。
pandasを使えばこれも簡単にできます。
for col in train.columns:
#マルチラベルをone-hotに
if train[col].dtype == 'object':
train = pd.concat([train, pd.get_dummies(train[col], prefix=col)], axis=1)
スケーリング
所有物の有無のラベルと資産額など、データ間でスケールが異なるので、正規化処理を行いました。
scikit-learnのMinMaxScalerを用い、系列中の最小値を-1、最大値を1になるよう正規化しました。
from sklearn import preprocessing
# 正規化(alldataは、application_trainとtest)
alldata = pd.concat([train,test])
scaler = preprocessing.MinMaxScaler()
alldata[alldata.columns] = scaler.fit_transform(alldata[alldata.columns])
train = alldata[:train_length]
test = alldata[train_length:]
モデルの作成
モデルにはまず多層パーセプトロン(MLP)を用いることにしました。
class MLP(chainer.Chain):
def __init__(self):
super(MLP, self).__init__()
initialW = initializers.HeNormal()
with self.init_scope():
self.l1=L.Linear(None, 300, initialW=initialW)
self.l2=L.Linear(300, 300, initialW=initialW)
self.l3=L.Linear(300, 2, initialW=initialW)
def __call__(self, x):
h = F.relu(self.l1(x))
h = F.dropout(F.relu(self.l2(h)),ratio=.2)
h = self.l3(h)
return h
4~5日目
学習/検証
データの分割はapplication_train.csvのデータを学習用と検証用、8:2になるように分割しました。
アンダーサンプリングをした結果、学習用データ数39720件、検証用データ9930件となりました。
学習のパラメータ
ミニバッチサイズ:1000
epoch数:100
loss関数:Softmax Cross Entropy
optimizer:Adam
評価方法
コンペによって評価方法は異なり、今回はROC(Receiver Operating Characteristic)曲線のAUC(Area Under an ROC curve)という指標による評価となります。
ROC曲線
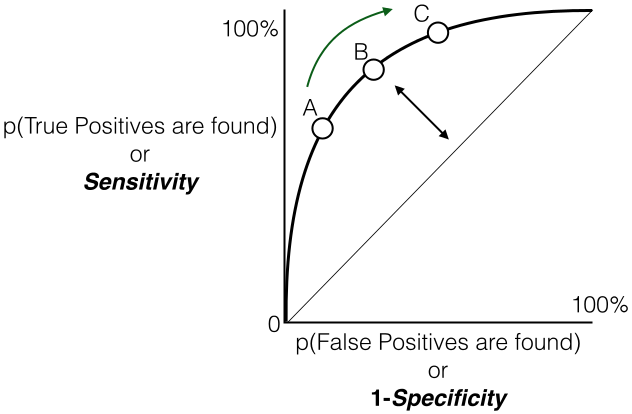
受信者操作特性 - Wikipediaより
https://ja.wikipedia.org/wiki/%E5%8F%97%E4%BF%A1%E8%80%85%E6%93%8D%E4%BD%9C%E7%89%B9%E6%80%A7
ROC曲線とは、予測結果の閾値(モデルの出力が0.7以上であれば陽性とする、など)を動かしながら、偽陽性率(陰性であるデータのうち、誤って陽性と判断したデータの割合)を横軸に、真陽性率(陽性であるもののうち、正しく陽性と判断できたデータの割合)を縦軸に置いてプロットしたものです。
この曲線の面積(AUC)が大きいと、偽陽性率が低い(でたらめに陽性と決めつけない)上に、真陽性率が高い(陽性のものは正しく検出できる)モデル、ということになります。
以下の記事が参考になりますので掲載させていただきます。
【統計学】ROC曲線とは何か、アニメーションで理解する。
https://qiita.com/kenmatsu4/items/550b38f4fa31e9af6f4f
学習結果
100epoch時点での
| 学習 | 検証 | |
|---|---|---|
| loss | 0.12066017 | 2.2431343 |
| accuracy | 0.95193857 | 0.150428 |
| AUC Score | 0.9933522934153212 | 0.6314926959790433 |
学習は出来るが未知に対して分類ができませんでした。
予測結果提出(1回目)
とりあえずtestデータを学習後モデルに入れて、提出してみました。
提出ページ
csvファイルに、顧客ID的なものとモデルの予測結果(出力層がsoftmaxなので、出力はローンを支払えない確率となります)を書き出し、ファイルをドラッグ&ドロップするだけで提出は完了です。
結果は、、、
AUCスコア:0.634
順位:6233位/6842チーム中
Leaderboardの上位50チームは0.8を超えていたので、賞金には程遠い、、
6日目
全データの結合
せっかく用意されているし、利用すれば成績が上がるのではないかと考え、他のcsvファイルをapplication_train|test.csvに結合させてネットワークに入力しようと考えました。
ここにデータフレーム結合コード添付
マージしたのち、もう一度学習、検証を行ってみると、
| 学習 | 検証 | |
|---|---|---|
| loss | 0.0034634743 | 4.164621 |
| accuracy | 0.9997986 | 0.15662135 |
| AUC Score | 1.0 | 0.6627218421582912 |
| 学習はスコアが1になり、検証も少し上がったが、完全に過学習です。この時点でのテストデータ適用結果は、 | ||
| AUCスコア:0.634 | ||
| 順位:6237位/6842チーム中 |
スコアは変化なく、順位は抜かされてしまいました。。。
7日目
主成分分析
無理矢理マージしたデータがスパースで、ノイズになっているのでは無いかと考え、主成分分析で次元数を削減してからネットワークに入力しようと考えました。
from sklearn.decomposition import PCA
pca = PCA(n_components=100)
alldata = pd.DataFrame(pca.fit_transform(alldata))
100次元まで減らし、学習してみると、
| 学習 | 検証 | |
|---|---|---|
| loss | 0.37914538 | 0.9629312 |
| accuracy | 0.8268882 | 0.14302619 |
| AUC Score | 0.9011247915576427 | 0.6000690769005039 |
AUCスコア:0.626
順位:6279位/6842チーム中
テストも下がってしまいました。
最終結果
その後、主成分分析はやめたり、アーリーストッピングを行ったりし、最終的な結果は、、、
AUCスコア:0.69927
順位:6205位/7198チーム中
せめて半分には届きたかったです、、、
まとめ・感想
pandasやscikit-learnの勉強を並行して行っていたので、スコアを上げるためにはデータに対しての考察などの時間が必要でした。ただ、一週間あればゼロからでもできることがわかりました。
kaggleのコンペ内ではkernelという、コンペ参加者間でコードの共有ができるため、それを参考にしながらだと、初めてでも取り組みやすいかなと感じました。
これからは腕を上げてまた取り組みたいと思います。