はじめに
業務でデータ基盤の構築をしています。
今回はCloud Composerを用いて、BigQueryでcsvデータをロードしてみたいと思います。
使用する諸々はこちら
TerraformによるComposer環境の構築
Terraformを使用して、クラウドリソースを作成すると管理が楽です。
そのため今回はTerraformを使用して、リソース作成を行います。
サービスアカウントの作成
TerraformでComposerの構築をするために、サービスアカウントからキーを発行しておいてください
サービスアカウント キーの作成と管理
Terraformaのインストール
公式サイトからzipを落とせますが、homebrewでインストールすることも出来ます
$ brew install terraform
tfファイルの作成
次にComposerを立ち上げるための.tfファイルを作成します。
# google認証
provider "google-beta" {
credentials = "${file("account.json")}"
project = "project_id"
region = "asia-northeast1"
}
# 作成するComposerの内容
resource "google_composer_environment" "composer-environment" {
name = "sample"
project = "project_id"
region = "asia-northeast1"
config {
node_count = 3
node_config {
zone = "asia-northeast1-c"
machine_type = "n1-standard-1"
disk_size_gb = 20
}
}
}
provider.credentialsには、発行したキーファイル(.json)のパスを指定します。
ただこの状態だとファイルにセキュアな情報が記載されてしまいます。git管理するときにもめんどそうです。
そのためTerraformでも勧められているように、以下のように環境変数をセットした方が利便性が高いです。可能ならこちらを実施してください。
$ export GOOGLE_CLOUD_KEYFILE_JSON={{path}}
ちなみproviderでgoogle-betaを使用しているのは、python3をComposerで使いたかったからです。
特段こだわりなければgoogle-betaではなく、googleで問題ありません。
リソースの作成
上記で作成した.tfファイルがあるディレクトリに移動して、init > applyを行います。
$ terraform init
$ terraform apply
...
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value:
yes でリソース作成を行います。
Enter a value: yes
google_composer_environment.composer-environment: Still creating... (10s elapsed)
google_composer_environment.composer-environment: Still creating... (20s elapsed)
google_composer_environment.composer-environment: Still creating... (30s elapsed)
.
.
.
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
Composerが作成されるまで10分ほど掛かります。気長に待ちましょう!
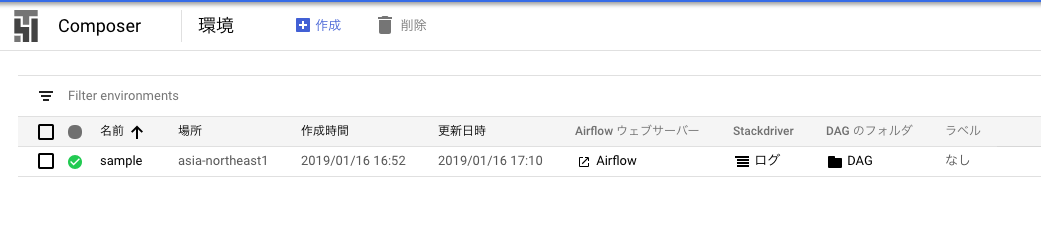
作成されるとGCPのコンソールから「Composer」を選択すると、下記のように環境が作成されているのを確認できます。
Dagファイルの作成
Composer (Airflow)では、ワークフローの定義をDagファイルというものに記載します。ただのpythonファイルです。
今回はgcsにあるcsvファイルをBigQueryに投入するだけのタスクを持つ、ワークフローを作成します。
やりたいことはBigQueryにデータを投入することなので、DataflowをComposerから呼び出すような実装にします。
DataflowはGCPで用意されている、フルマネージドなデータ処理サービスです。
Dataflowにはgoogle側でいくつかテンプレートが用意されており、今回はgcsにあるcsvをBigQueryへロードするため、Text Files on Cloud Storage to BigQueryを使います。
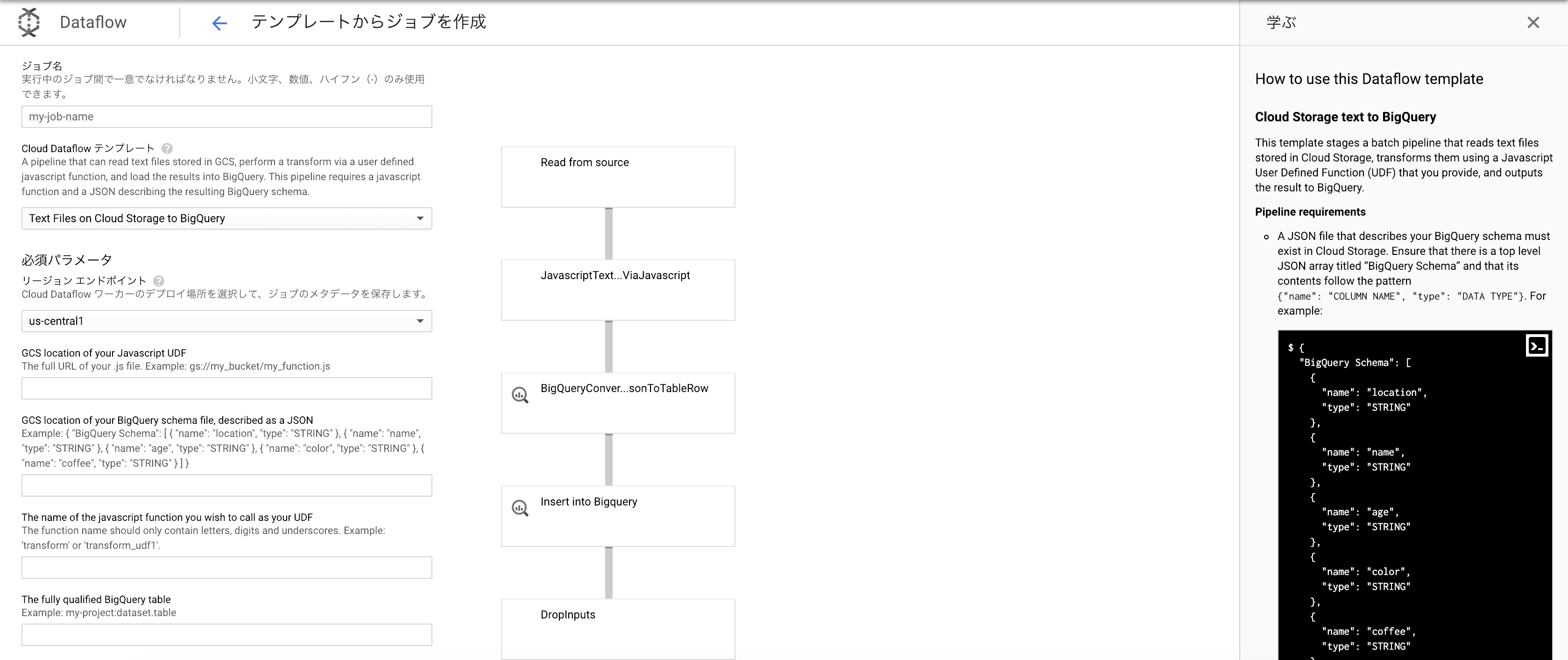
上記のテンプレートをComposerから呼び出して、データのインポート作業はDataflowに任せます。
Dagファイルは以下のようになります。
from airflow import DAG
from airflow.contrib.operators.dataflow_operator import DataflowTemplateOperator
from datetime import datetime, timedelta
from airflow import models
# gcpのプロジェクトID
PROJECT_ID = models.Variable.get('project_id')
# gcsのパス
BUCKET_NAME = models.Variable.get('gcs_bucket_name')
# dag名
DAG_NAME = 'csv_to_bigquery'
yesterday = datetime.combine(
datetime.today() - timedelta(days=1) + timedelta(hours=9),
datetime.min.time()
)
default_dag_args = {
'owner': 'HagaSpa',
'start_date': yesterday,
'project_id': PROJECT_ID,
'dataflow_default_options': {
'project': PROJECT_ID,
}
}
with models.DAG(
dag_id=DAG_NAME,
schedule_interval="@once",
default_args=default_dag_args) as dag:
t1 = DataflowTemplateOperator(
task_id='task1',
template='gs://dataflow-templates/latest/GCS_Text_to_BigQuery',
parameters={
# udf.jsファイルにある呼び出したいメソッド名
'javascriptTextTransformFunctionName': 'transform',
# bqのスキーマ定義ファイルのgcsパス
'JSONPath': 'gs://{}/composer/schema/schema.json'.format(BUCKET_NAME),
# udf.jsファイルのgcsパス
'javascriptTextTransformGcsPath': 'gs://{}/composer/udf/udf.js'.format(BUCKET_NAME),
# bqへ投入するcsvファイルのgcsパス
'inputFilePattern': 'gs://{}/composer/csv/sample.csv'.format(BUCKET_NAME),
# 保存するbqのプロジェクトid:データセット名.テーブル名
'outputTable': '{}:my_dataset.sample'.format(PROJECT_ID),
# bqへのロード中のtempディレクトリ
'bigQueryLoadingTemporaryDirectory': 'gs://{}/composer/temp'.format(BUCKET_NAME),
},
)
-
まず
PROJECT_ID = models.Variable.get('project_id')ですが、model.VariablesはAirflowで定義できる環境変数のことです。プロジェクトIDやgcsのバケット名など、外だししておく方が運用が楽な値は環境変数に定義します。
各値は自身の環境に合わせて、Airflowの環境変数をセットして下さい。
「環境変数はどうやって定義すんのや?」って方はこちらを参照ください。 -
with models.DAG()がairflowにおける、1つのDagになります。
SubDag?とか使えば、複数記載が出来るようですが今回はこれだけになります。 -
DataflowTemplateOperator()が、Dataflowのテンプレートを呼び出している箇所になります。
parametersに記載している内容は、Dataflowのテンプレート(GCS_Text_to_BigQuery)を使用する上で必須なものです。
Dataflowによるものです。 -
udf.jsは、「ユーザが定義した関数ファイル」です。具体的には「ファイルの行を引数とした、jsファイル」となっており、BigQueryへcsvファイルを取り込む際のカラム名とフィールド値をマッピングします。
function transform(line) {
var values = line.split(',');
var obj = new Object();
obj.id = values[0];
obj.name = values[1];
obj.age = values[2];
var jsonString = JSON.stringify(obj);
return jsonString;
}
// id,name,age
1,hagaspa,26
2,anyone,99
3,hoge,17
上記2ファイルをDagファイルに記載された、gcsのパスに配置してください。
その後Composerのコンソールから「Dag のフォルダ」をクリックし、表示されたgcsにDagファイルをアップロードしてください。
Dagの起動
Dagファイルをアップロードしてから、しばらく経つとAirflowの画面に以下のようにDagが表示されます。
(おそらく初回は自動的に開始されているはずです。開始されていない場合は、右側のRunをクリックして下さい。)
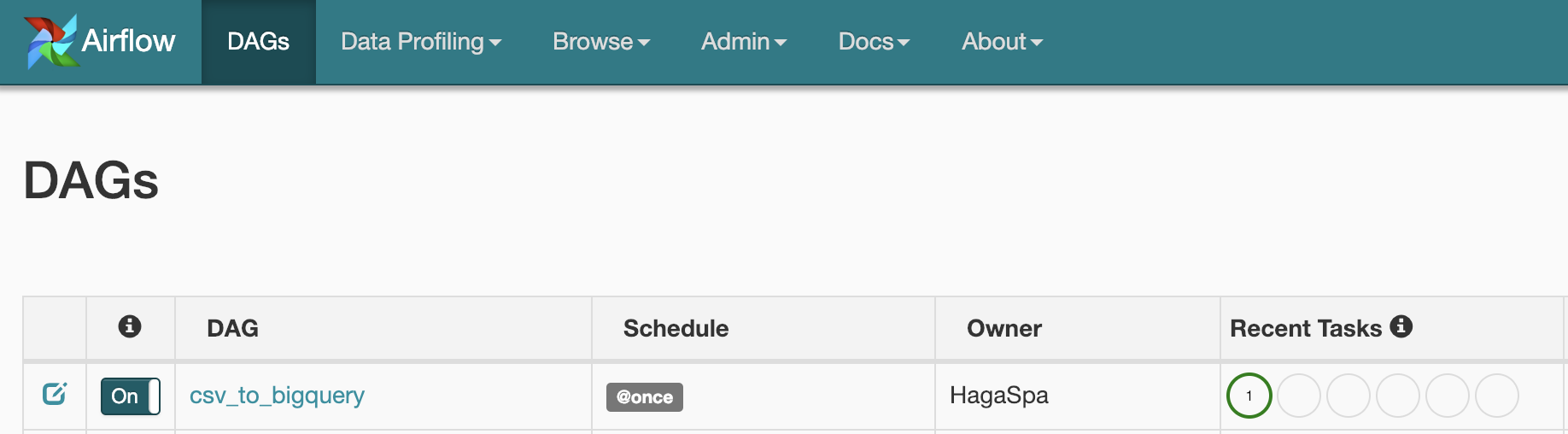
Recent Tasksがグリーンになると成功です。
AirflowがDataflowを起動し、BigQueryへデータをインポートしているか確認しましょう!
まずはDataflowですが、成功していると下記のようになっているはずです。
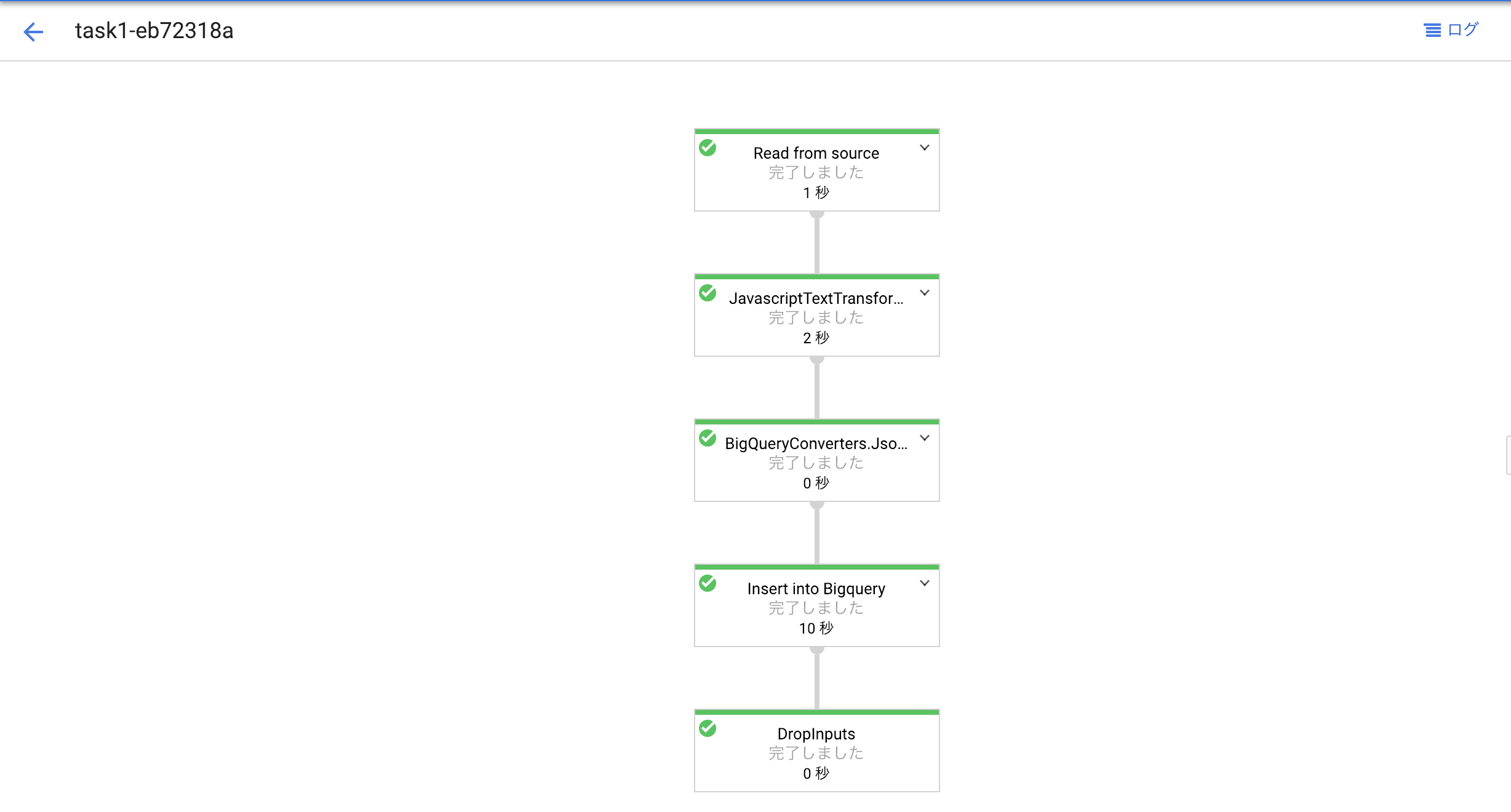
基本的にオールグリーンになっていれば成功ですが、ありがちなミスとしてgcsのファイル名を間違えているとエラーにならずに0KBを読み取るということをするので、Read from sourceのフェーズは要チェックしましょう。
最後にBigQueryにデータをインポート出来ているか確認します。
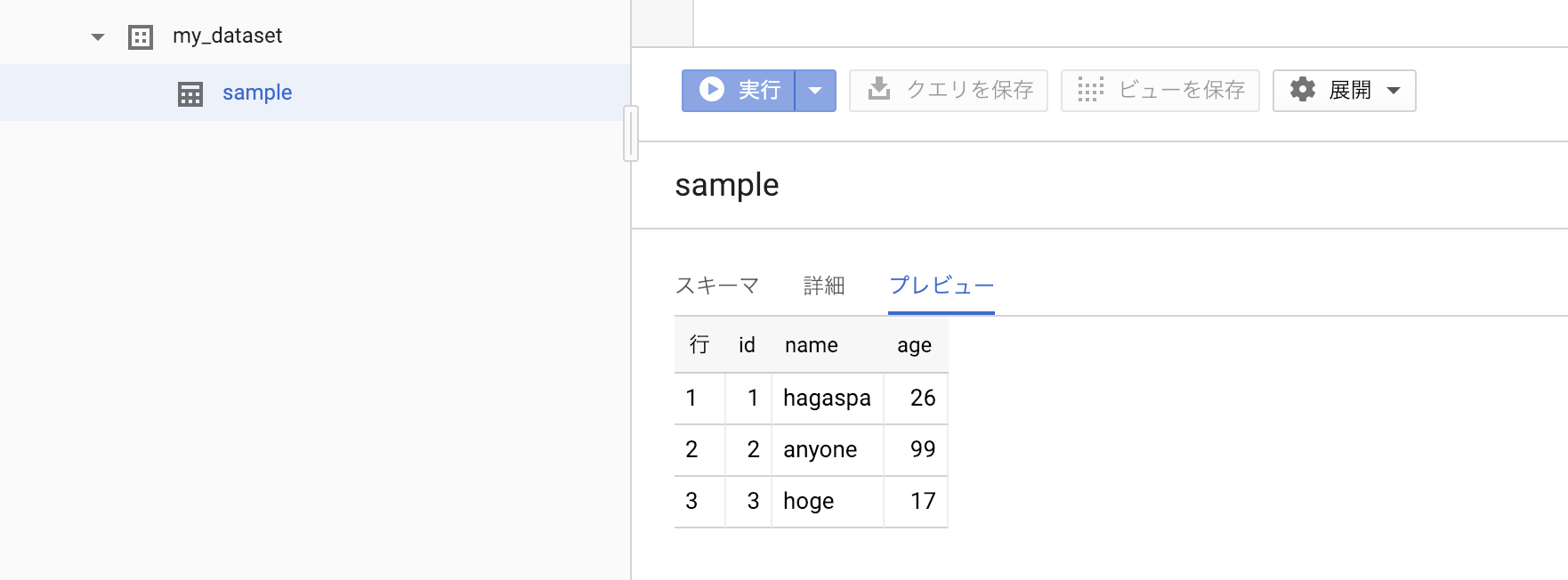
csvデータがインポート出来ました!
まとめ
データ基盤を作る上では、しばしばテーブルの更新状態に依存することがあります。
今回は単純にデータをロードしただけですが実業務だと、
- 前日データを使ってテーブルAにデータをロードする。
-
テーブルAが更新されているなら、
Tableauデータソースへ適用や集計処理などを実施。 - テーブルAへの取り込みがエラーなら、後続処理を止めSlack通知を行う。
などのワークフローを組むことが多いです。
そのためAirflowもとい、Composerを使用してデータ基盤構築フローを組むことはとても便利だと感じました。
困ったら
基本はドキュメントに記載されています。またossなので最悪ソースコードを読めます。
Dataflow以外にも色んなサービスをAirflowで使用できるので、operatorsを参照してやりたいことがAirflowで実現できるか考慮しましょう!