概要
"A"とか"あ"に1つ1つIDを振り、それらを0と1で対応させているのが文字コード。
流れを追いながらの方が分かりやすいと思いますので書きます。
コンピュータ誕生
80年前(1942年くらい) コンピュータが誕生しました。
今でもそうですがコンピュータは0と1しか表現できません。
当時はデカい計算機程度の活躍でした。
ASCIIコード誕生
60年前(1960年くらい) 頭いい人がこんなことを考えました。
「これ、モールス信号みたいに文字1つ1つに0と1の羅列を割り当てたら、コンピュータで会話できるんじゃね?」
これが符号化文字集合と呼ばれるものです。
(符号とは信号、つまりビット列のことです。"ビット列化した文字の集合"ってことですね。)
これを基にして最初に作成された対応表がASCIIコードと呼ばれるものでした。

固定長とは、つまりビットを一定間隔で区切ったものを1文字とするということです。(ASCIIは7bit。正確には8bitらしいか…ちょっと難しいので割愛)
ここまでは良かったのですが、これを実際に作った人はとんでもないミスをします。
「数字0~9と、英語26文字と、$とか%とかの記号で100個くらいかな。7ビットなら128個も扱えるし十分だろ。よし、区切りは7ビットにしよう」としてしまったのです。
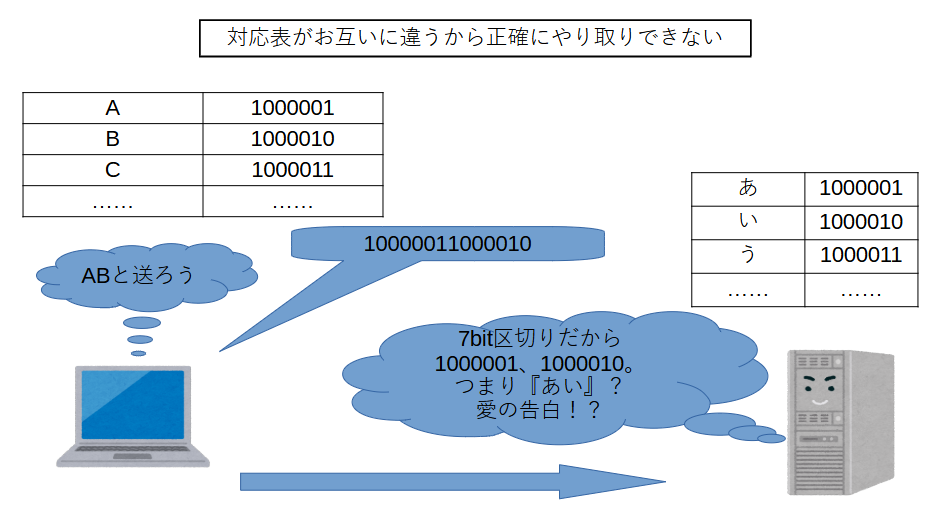
最初はこのシンプルな対応表でコンピュータ同士は会話できてたのですが後々大問題に。

各国が独自の符号化文字集合を作成。まさに地獄に。
50年前(1970年くらい)、符号化文字集合が乱立します。
ASCIIコードの登場で画期的に進歩した通信ですが、1つ重大な問題があります。
他の国「俺らの文字がないじゃん!」
こうなるとやることは一つ。
他の国「俺らも自分の国に対応した対応表を作るぜ!」
こうなると地獄です。
| 符号化文字集合 | 作って利用した国 | 内容 |
|---|---|---|
| ASCIIコード | アメリカ | 英字や数字のみ |
| JIS X 0201 | 日本 | カタカナだけ |
| KOI8-R | ロシア | キリル文字など |
| EBCDIC | ? | プログラムコード用? |
| ・・・ | ・・・ | ・・・ |
基本的にASCIIコードの部分はそのままに、8ビットに拡張した部分を自国の文字を当てたりしました。
英語と数字だけのやりとりならまだしも、一部の文字列は扱えません。
JIS X 0201で定義された「11111111」は「ア」なのに、KOI8-Rでは「Д」だったりするからです。
これが文字化けの原因です。
なんならEBCDICのようにASCIIとは全く互換性のない表まで出現する始末。
こうなるともう無茶苦茶です。
日本とロシア、中国と日本などでは表が異なるため文字が化けまくってやり取りできない状況になりました。

バラバラの表を統一しようとUnicodeが誕生
※以下Unicodeの仕組みは理解不足で一部正確ではないです。
大枠は合っているかと思いますが鵜呑みにしないでください。
30年前(1991年) ようやく「全世界、すべての文字を詰め込んだ夢の表を作ろう!みんなでこれを使えば、一切の文字化けなくPCでやりとりできるぞ!」と誰かが提案しました。
これがUnicodeと呼ばれるものです。
最初期、世界で使われている表をまとめると7000文字くらいだと予想していました。
それでも油断せず区切りは16ビットに。なんと6万文字も格納できます。

悪夢再び。Unicodeの上限6万でも足りず
Unicode完成からたった数年後(1993年) 6万文字では足りなくなりました。

まさに歴史は繰り返す。ASCIIコードの120文字で足りなかった教訓が丸で活かせず。
原因は漢字の数を舐めていたためです。現在Unicodeの60%は漢字だとか……()
ここでとった行動は、Unicodeという対応表を2つに分離することでした。
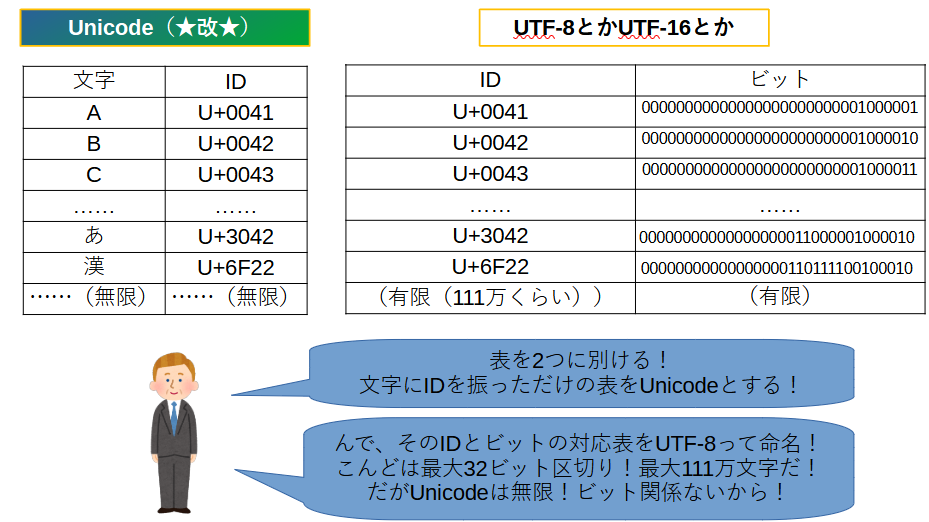
実際は一部の文字は32ビット以下で扱えます。イラストはイメージ優先にしています。この辺りの仕組みは私も勉強中……
1つめの表は、現在のUnicodeと呼ばれる表です。イラストの左の表です。
『U+0041』というのは、『Unicodeの番号だよ。16進数で41番目だよ』って意味です。
『U+0041』などの番号をコードポイントと呼んだりします。
このUnicode★改★という表に上限なんてありません。ただただ、世界中の文字や記号に番号を割り振っているだけですから。
2つ目の表は、この割り振ったIDと実際のビット列の対応表です。これがUTF-8やUTF-16と呼ばれるものです。
もちろん、0と1の羅列(ビット列)で通信する以上、どこで区切るかという取り決めは必須になります。
そして区切りの数(桁数)で取り扱える文字の数が決まるのも必然。
UTF-8では最大を32桁にしました。最大111万文字です(現在16万文字埋まっています)
UTF-16やUTF-8の仕組みは理解が追い付いていないため割愛しますが、32ビットを1文字にしていたらPC同士のやり取りが激重になります。
例えなので適当ですが、ASCIIだったら8bitなので"A"を送るのに『00000001』でよいが、UTF8は最長32Bitなので"A"を表現するのに『00000000000000000000000000000001』と送る必要があるからです。

これでは困るということでUTF-8では何とよく使う文字だけ長さを短く扱えます。これにより容量を最小限にしてやり取りできるようになりました。
Q&A
Q:結局『文字コード』ってどれを指すの?
A:文字とID(符号化文字集合)、IDとビット列(文字符号化)、2つの表をごっちゃにした単語っぽいです。
多分…
Q:Unicodeってわざわざ表を2つに分けた意味はあるの?結局UTF-8でも111万文字までという上限はあるんでしょ?
A.確かに。
ごもっともな疑問です。私もこれについてはちょっと合理的な説明ができません。
ただ、新たな文字や記号が増えても、Unicodeの方は追加するだけで永久的に使えるから……不変の表という意味ではいいのかも……
Q:よく聞くShift-JISって何?
A.Unicodeとは全く関係のない、日本で独自の成長を遂げた文字コードです
「ASCIIは英語で読めないなあ……とりあえずカタカナ46文字に入れ替えるか!」
としてJIS X 0201という表を作りました。つまりASCIIコードと形は類似しています。
しかし10年後(1978年)、
「あかん、カタカナだけやと見づらいわ!やっぱりひらがなと漢字もいるわ!」となりました。
しかしJIS X 0201はASCIIと同じ7~8bitで作成済。
漢字なんて合わせるととても256個などでは足りません。
ということでもう一つ表を作りました。これがJIS X 0208です。
そして、この2つの表を統合したのがShif-JISと呼ばれる文字コードです。
つまりShif-JISはUnicodeなどは全く関係なく、完全に日本独自の文字コードになっています。
当然UTF-8などとの互換性などあるはずもなく。Unicodeで想定されたビット列をShif-JISという表に当てはめて解釈するとめちゃくちゃな文字になります。これが文字化けです。
メリットはありません。Shift-JISに関わった偉人には悪いが、Unicodeに移行するべき。
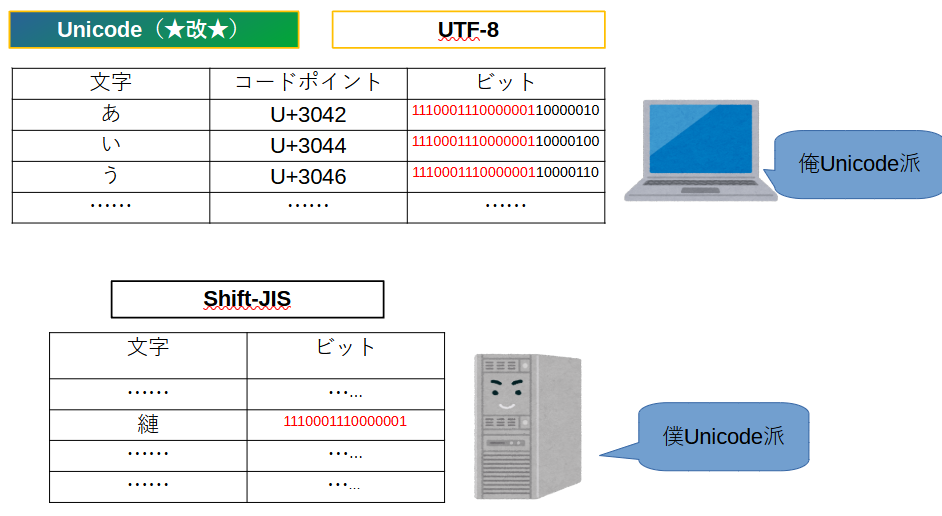
このように使う文字コードが異なると……

こうなります。
参考URL
https://systemengineers.hateblo.jp/entry/2021/08/07/142124
https://wa3.i-3-i.info/word111.html