時系列予測モデルについての理論的な説明はここでは行いません。
正しく理解できているとも思えないので、とりあえず聞きかじったものを使ってみる程度です。
ARIMAモデル作成
データからAR,I,MAという成分を考慮して作成するモデルです。
パラメータの探索がめんどくさく、グリッドサーチなどをfor文で組んだりしていましたが、
auto.arimaという関数がforcastパッケージに入っているそうです。
ありがてぇ。
今回は怪しいと思っていた一年周期をもとにモデルを考えています。
モデル作成前に自己相関関数acfなど確認します。
tsdisplay(cut_fill_data_2)
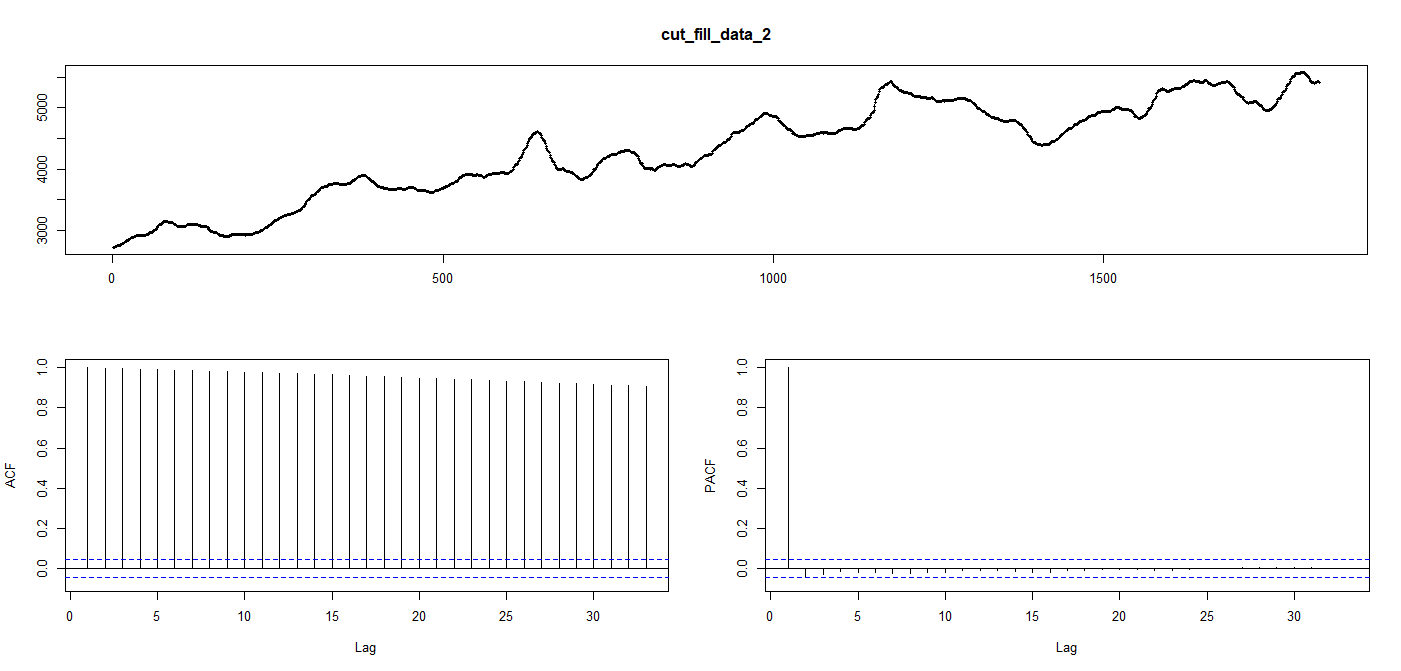
パット見てacfに周期的なピークはみられません。
library(forecast)
cut_fill_data_2.arima<-auto.arima(cut_fill_data_2,trace=T,stepwise=T,seasonal=T)
cut_fill_data_2.arima_200<-auto.arima(cut_fill_data_2,trace=T,stepwise=T,seasonal=200)
cut_fill_data_2.arima_300<-auto.arima(cut_fill_data_2,trace=T,stepwise=T,seasonal=300)
cut_fill_data_2.arima_600<-auto.arima(cut_fill_data_2,trace=T,stepwise=T,seasonal=600)
plot(forecast(cut_fill_data_2.arima,h=720))
どれも選択されるモデルは一緒でした。
> cut_fill_data_2.arima<-auto.arima(cut_fill_data_2,trace=T,stepwise=T,seasonal=T)
Fitting models using approximations to speed things up...
ARIMA(2,1,2) with drift : 10560.5
ARIMA(0,1,0) with drift : 13457.69
ARIMA(1,1,0) with drift : 11033.2
ARIMA(0,1,1) with drift : 11690.67
ARIMA(0,1,0) : 13497.62
ARIMA(1,1,2) with drift : 10569.68
ARIMA(2,1,1) with drift : 10587.7
ARIMA(3,1,2) with drift : 10524.57
ARIMA(3,1,1) with drift : 10362.12
ARIMA(3,1,0) with drift : 10481.01
ARIMA(4,1,1) with drift : 10485.12
ARIMA(2,1,0) with drift : 10728.01
ARIMA(4,1,0) with drift : 10446.39
ARIMA(4,1,2) with drift : 10362.58
ARIMA(3,1,1) : 10361.23
ARIMA(2,1,1) : 10591.59
ARIMA(3,1,0) : 10482.24
ARIMA(4,1,1) : Inf
ARIMA(3,1,2) : 10527.22
ARIMA(2,1,0) : 10732.98
ARIMA(2,1,2) : 10564.94
ARIMA(4,1,0) : 10446.8
ARIMA(4,1,2) : 10361.69
Now re-fitting the best model(s) without approximations...
ARIMA(3,1,1) : 10365.47
Best model: ARIMA(3,1,1)
予測をplotしてみます。
試しに720日分。
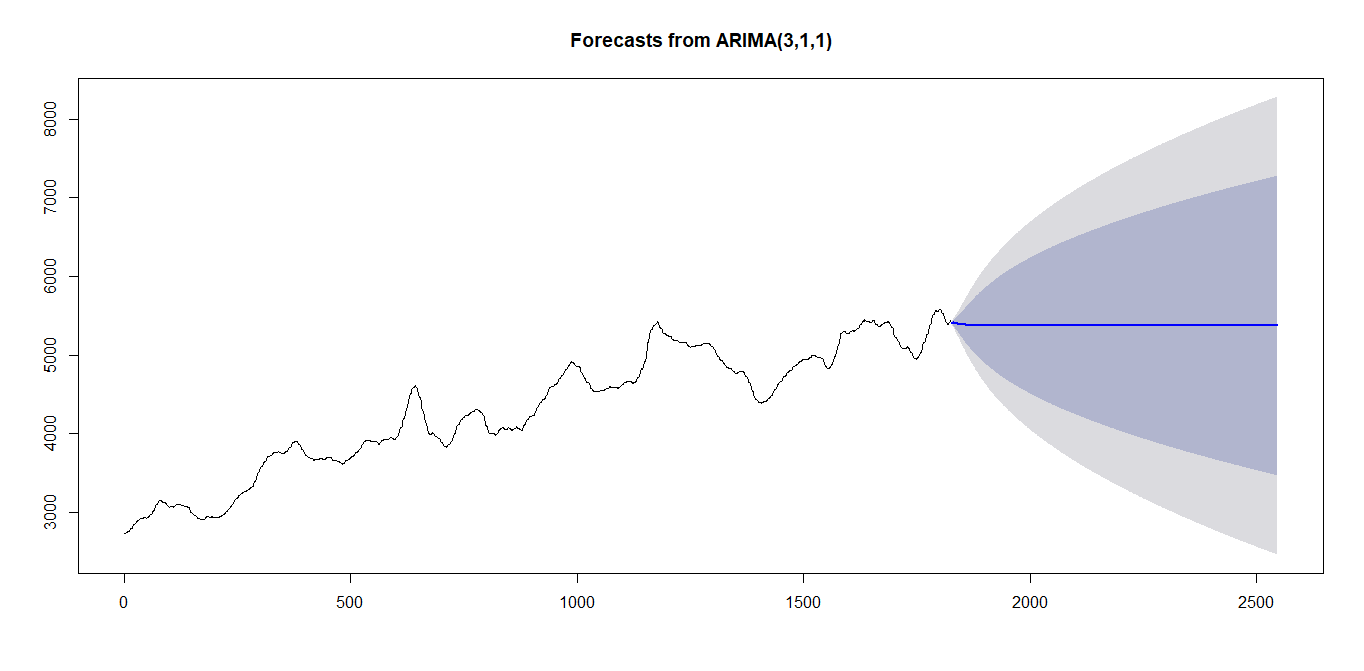
こりゃダメだ。
いっそseasonを無視してみたら?
cut_fill_data_2.arima_no_season<-auto.arima(cut_fill_data_2,trace=T,stepwise=T,seasonal=F)
plot(forecast(cut_fill_data_2.arima_no_season,h=720))
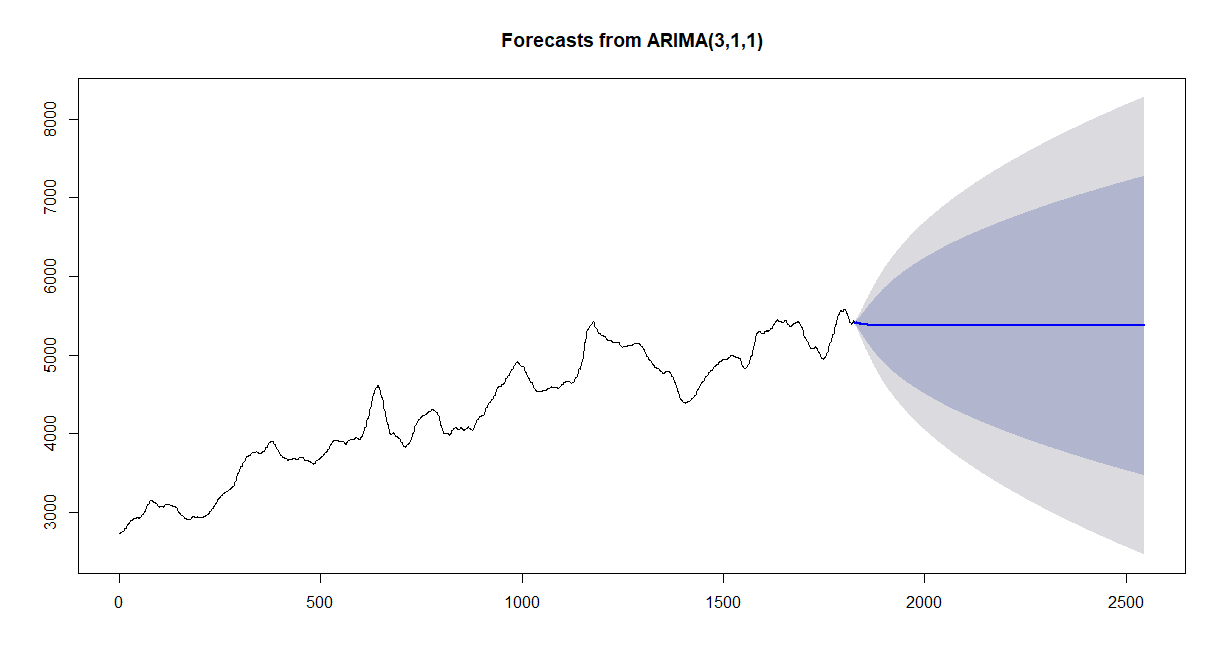
変わらない。
autoとはいえ、もう少しパラメータをいじってみる
model_arima <- auto.arima(
cut_fill_data_2,
ic="aic",
stepwise=F,
approximation=F,
max.p=10,
max.q=10,
max.order=20,
parallel=T,
num.cores=4,
seasonal=T
)
#step wise F
#parallel T
plot(forecast(model_arima,h=720))
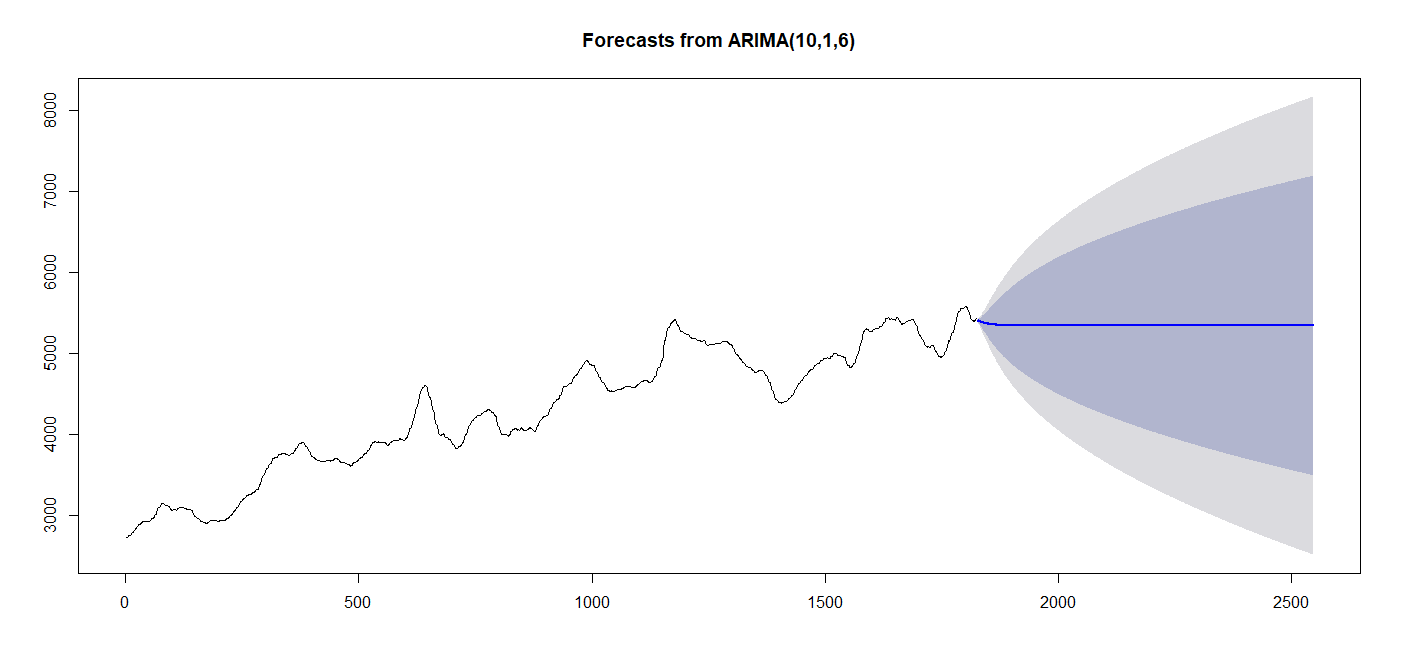
パラメータが変化しました。
model_arima_SWT <- auto.arima(
cut_fill_data_2,
ic="aic",
stepwise=T,
approximation=F,
max.p=10,
max.q=10,
max.order=20,
parallel=F,
num.cores=4,
seasonal=T
)
#step wise T
#parallel F
plot(forecast(model_arima_SWT,h=50))
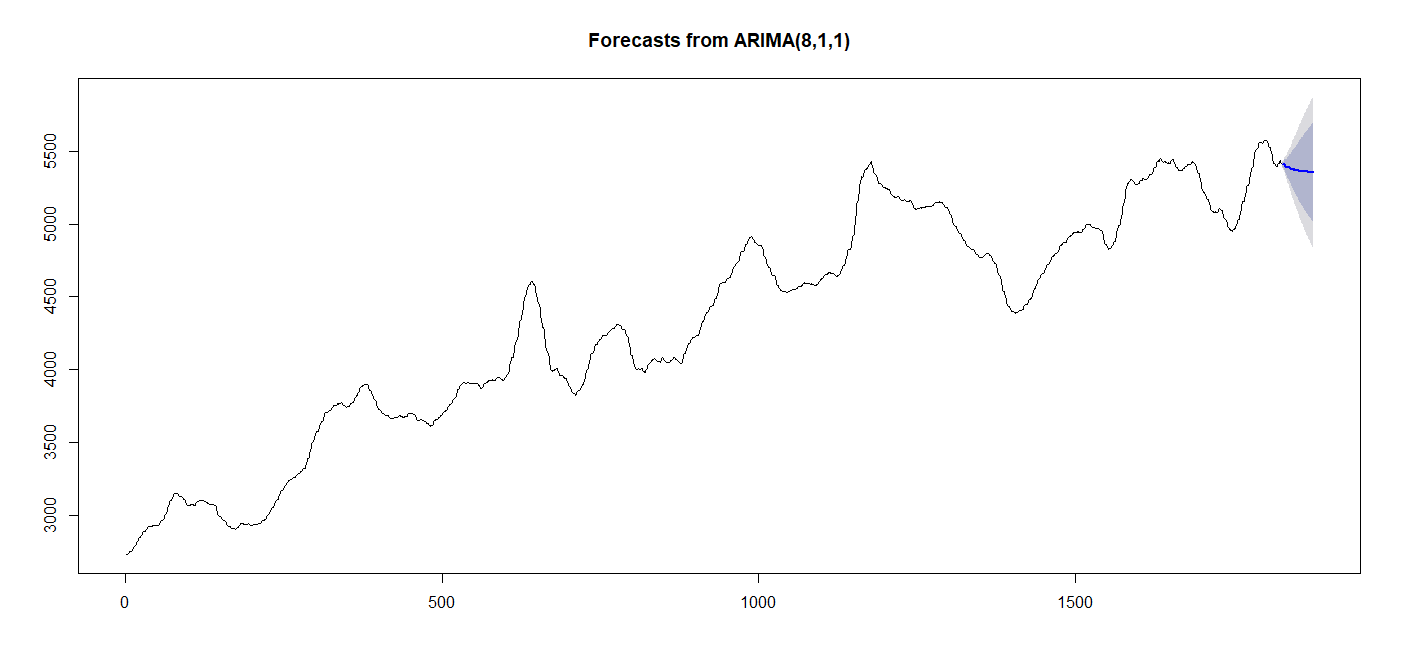
model_arima_SF <- auto.arima(
cut_fill_data_2,
ic="aic",
stepwise=T,
approximation=F,
max.p=10,
max.q=10,
max.order=20,
parallel=F,
num.cores=4,
seasonal=F
)
#step wise T
#parallel F
#seasonal F
plot(forecast(model_arima_SF,h=50))
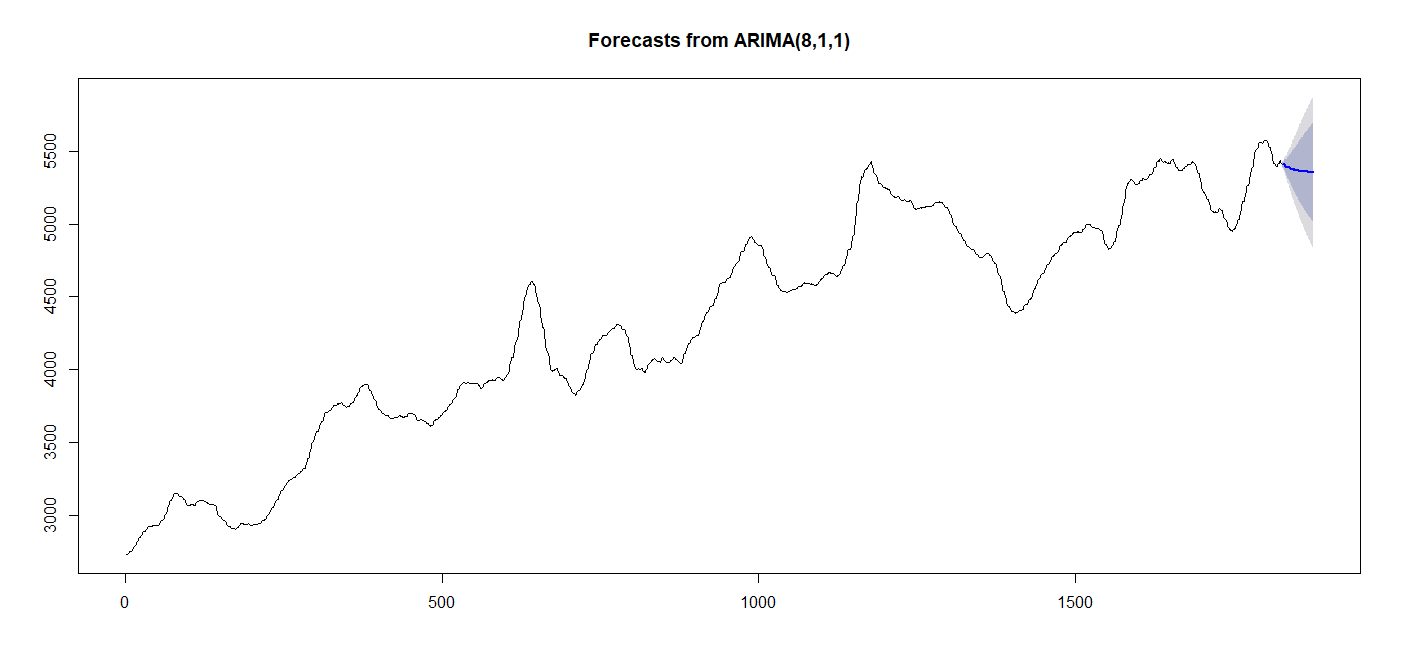
model_arima_more <- auto.arima(
cut_fill_data_2,
ic="aic",
stepwise=T,
approximation=F,
max.p=20,
max.q=20,
max.order=20,
parallel=F,
num.cores=4,
seasonal=F
)
plot(forecast(model_arima_more,h=50))
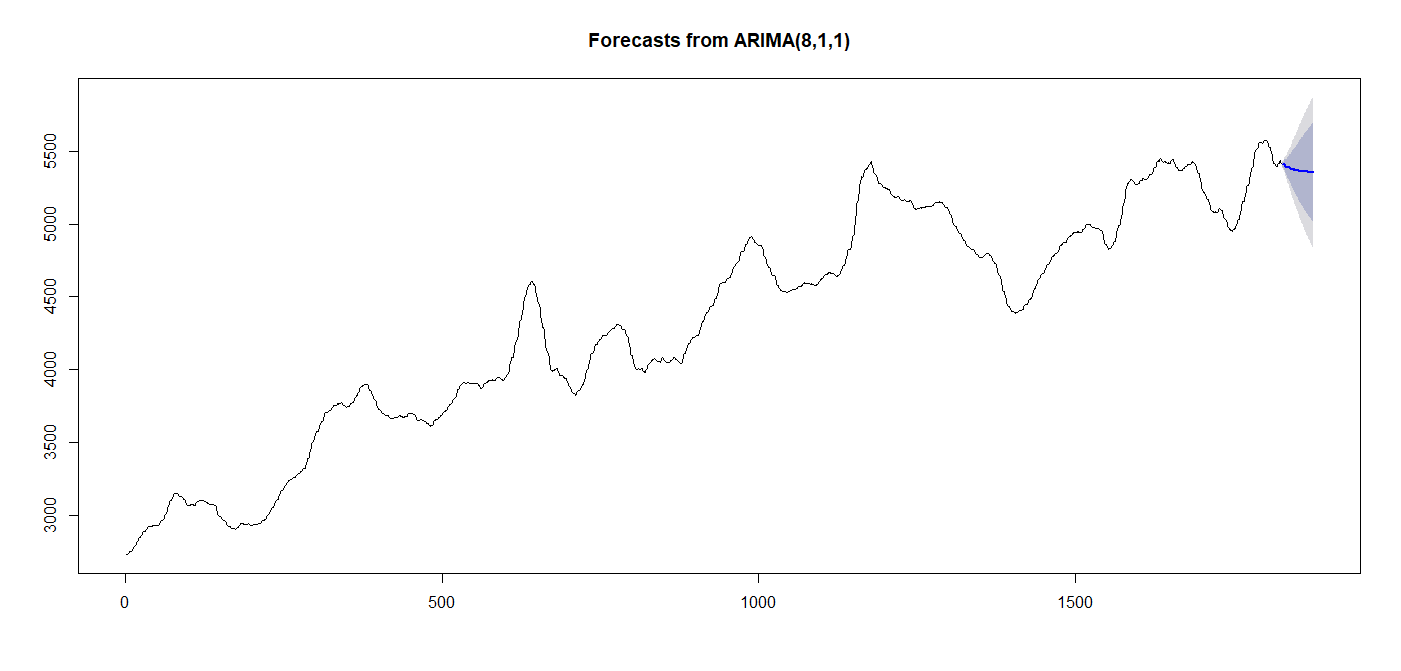
いくつかチューニングを変えてみましたが嬉しい結果は得られませんでした。
キッチリした周期性のあるデータならばまた違ったのでしょう。
あと、ARIMAモデルというのはデータ数が多い場合には精度が良くないらしく、
それも影響しているのかもしれません。
学習させるデータの幅が大きかったのかも。
もし改善させるとしたら、過去の値は無視して、周期性を360に固定して、
過去360日のデータから数日先を予測するなどの方法が良いかもしれません。
360日分切り出してautoで学習させ、何日分かを予測。
新しいデータを追加して、古いデータは捨てて予測を変える。
のように。
考えは実行
イメージ的にこんな感じ
pred_data_from_361<-NULL
im<-cut_fill_data_2
saveGIF(
for(i in seq(1,600,50)){
end<-i+360
roll_data<-im[i:end]
model_arima_roll <- auto.arima(
roll_data,
ic="aic",
stepwise=F,
approximation=F,
max.p=10,
max.q=10,
max.order=20,
parallel=T,
num.cores=4,
seasonal=T
)
mod_forecast<-forecast(model_arima_roll,h=50)
forecast_start<-end+1
forecast_end<-end+50
plot(c(1:1000),c(0,rep(6000,999)),type="n",xlab="",ylab="")
points(c(i:end),roll_data,type="l")
points(c(forecast_start:forecast_end),mod_forecast$mean,type="l",col="red")
pred_data_from_361<-c(pred_data_from_361, mod_forecast$mean)
}
, movie.name="pred.gif", interval=0.8)
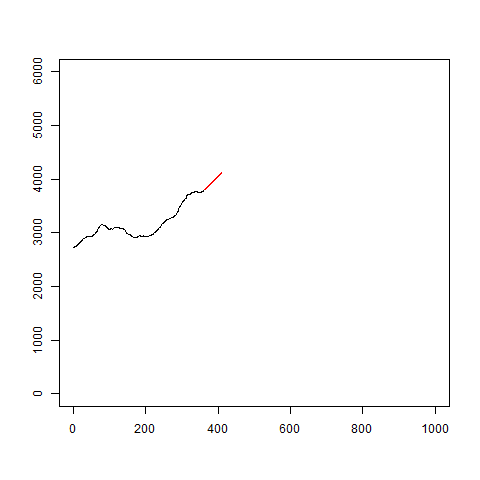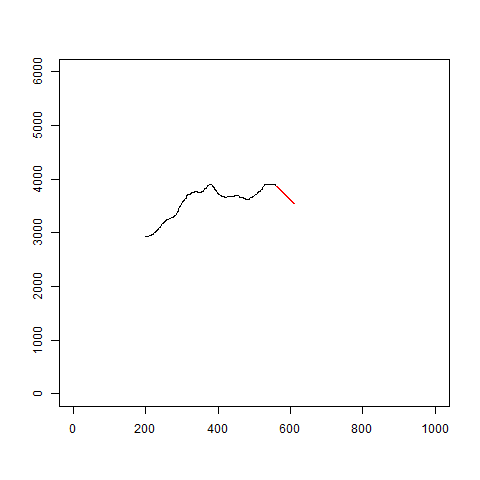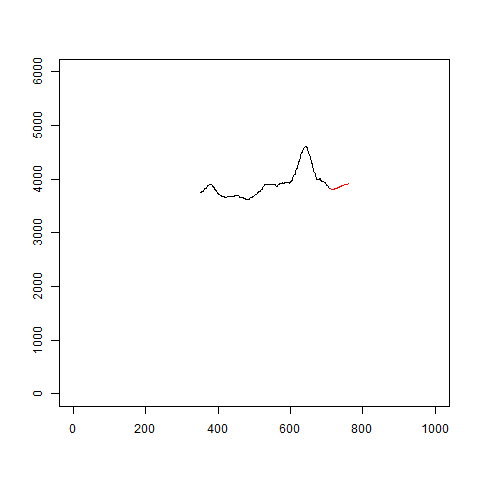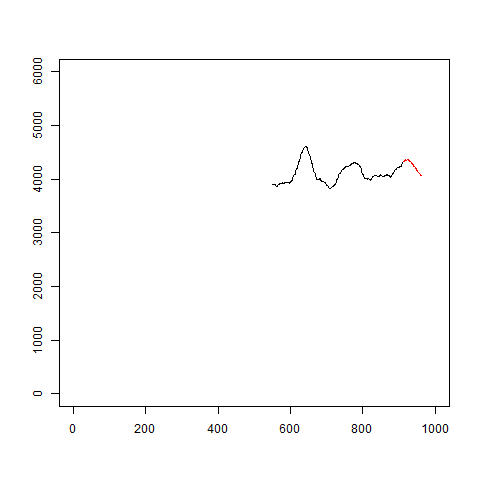
イメージはこんな感じです。
gifを見るとわかるように、当たり外れがあります。
あまり信用はできなさそうです。
一枚の図で全体を見てみます。
plot(c(1:1000),c(0,rep(6000,999)),type="n",xlab="",ylab="")
points(c(1:911),im[1:911],type="l")
points(c(362:961),pred_data_from_361,type="p",col="red")
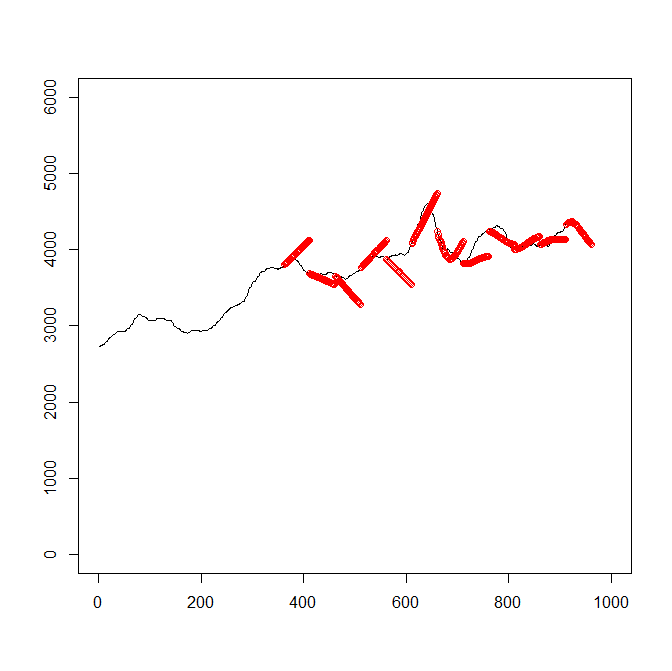
当てはまりはよくありません。
50日という期間が長すぎて当たらないように見えるのかもしれません。
20日くらいに制限してみます。
pred_data_from_361_20<-NULL
im<-cut_fill_data_2
saveGIF(
for(i in seq(1,300,20)){
end<-i+360
roll_data<-im[i:end]
model_arima_roll <- auto.arima(
roll_data,
ic="aic",
stepwise=F,
approximation=F,
max.p=10,
max.q=10,
max.order=20,
parallel=T,
num.cores=4,
seasonal=T
)
mod_forecast<-forecast(model_arima_roll,h=20)
forecast_start<-end+1
forecast_end<-end+20
plot(c(1:1000),c(0,rep(6000,999)),type="n",xlab="",ylab="")
points(c(i:end),roll_data,type="l")
points(c(forecast_start:forecast_end),mod_forecast$mean,type="l",col="red")
pred_data_from_361_20<-c(pred_data_from_361_20, mod_forecast$mean)
}
, movie.name="pred_20.gif", interval=0.8)
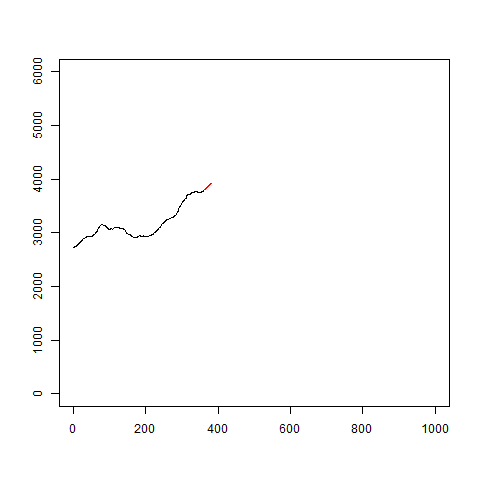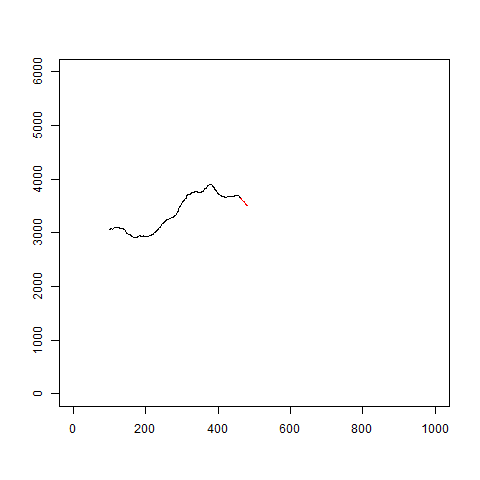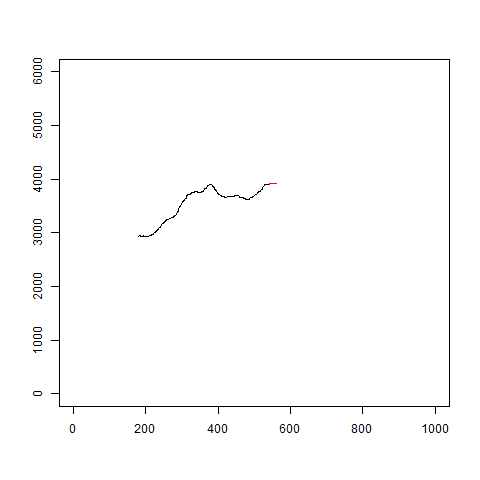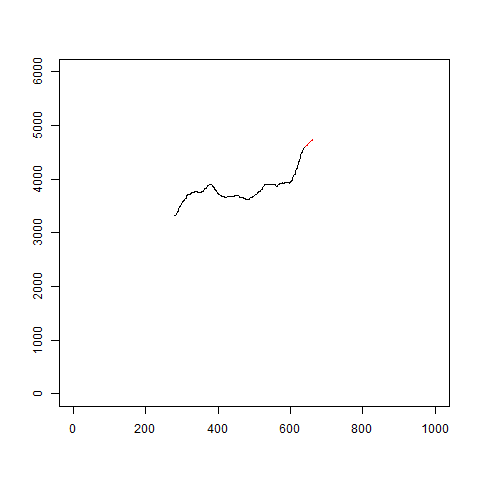
plot(c(1:1000),c(0,rep(6000,999)),type="n",xlab="",ylab="")
points(c(1:661),im[1:661],type="l")
points(c(362:661),pred_data_from_361_20,type="p",col="red")
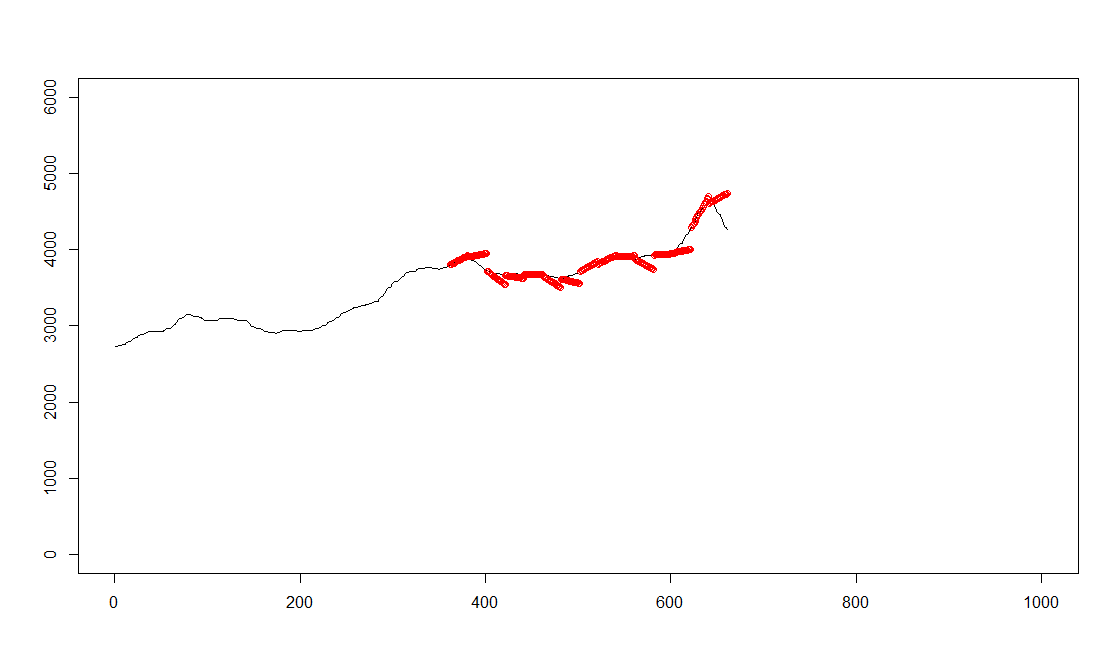
多少良くなった気もしますが、急な変化には対応できていないようです。
図を見ていると、トレンド成分のみで予測しているようにも思えます。
時系列解析手ごわい・・・
きっともっとうまいやり方もあるのでしょうが、
定常性を見つけられないとしんどいものがあります。
次回はそれっぽい予測をしてくれることで有名なprophetさんに登場願います。