目次
- はじめに
- ライブラリの紹介
- livedoor-corpusでのテストコード
はじめに
本記事ではBERTによるテキストのマルチクラス分類(文書分類、text Classification)を手軽に行えるライブラリの紹介をします。
タイトルの3行というのはそのライブラリのメソッド的な意味です。
BERTとは
BERTとは、Bidirectional Encoder Representations from Transformers の略で
「Transformerによる双方向のエンコード表現」と訳され、2018年10月にGoogleのJacob Devlinらの論文で発表された自然言語処理モデルです。
翻訳、文書分類、質問応答など自然言語処理の仕事の分野のことを「(自然言語処理)タスク」と言いますが、BERTは、多様なタスクにおいて当時の最高スコアを叩き出しました。
引用:Ledge.ai「BERTとは|Googleが誇る自然言語処理モデルの特徴、仕組みを解説」
参考:Qiita「自然言語処理の王様「BERT」の論文を徹底解説」
BERTによるテキスト分類
ありがたいことにBERTによるテキスト分類のサンプル記事は既に多く存在しています。
が、結構長かったりして取っ掛かりにくいんですよね。
参考:
自然言語処理モデル(BERT)を利用した日本語の文章分類
BERTを用いて、日本語文章の多値分類を行う
【PyTorch】BERTを用いた日本語文書分類入門
なので少し調べてみたら手軽なライブラリにパッキングしてくれた方がいらっしゃいました↓↓
「Simple Transformers」
元記事:Simple Transformers — Multi-Class Text Classification with BERT, RoBERTa, XLNet, XLM, and DistilBERT
このライブラリは「そのまま動作する」Transformerライブラリです。
技術的な詳細を気にすることなく、3行のコードでTransformerを使用する場合は、これが最適です。
(元記事訳)
BERTにはいくつか種類がありますが、
BERT,GPT,GPT-2,Transformer-XL,XLNet,XLM,RoBERTa,DistliBERTの8つを似た書き方で実行できるのがTransformersというライブラリです。
この「Simple Transformers」はそれをさらに使いやすくしたライブラリです。
導入
公式ではcondaを推奨していますが僕はvenv仮想環境で行いました。
前提系:$ pip install pandas tqdm scipy scikit-learn transformers tensorboardx simpletransformers
これらに加えてpytorchが必要になります。
GPUを使う場合は別途CUDAの導入が必要になるので調べてみてください。
CPUの場合はpytorchのみのインストールで大丈夫です。
インストールコマンドは公式から自分の環境に合わせたものを取得できます。→Pytorch公式
ちなみに僕の環境ではGPUのメモリ不足エラーを回避できなかったのでCPUで実行しました。長いです。
使ってみる
まずは公式に乗っているDemoを日本語でまとめると
データ取得
- ここからデータをダウンロード
-
data/ディレクトリにtrain.csvとtest.csvを展開
前処理
import pandas as pd
train_df = pd.read_csv('data/train.csv', header=None)
train_df['text'] = train_df.iloc[:, 1] + " " + train_df.iloc[:, 2]
train_df = train_df.drop(train_df.columns[[1, 2]], axis=1)
train_df.columns = ['label', 'text']
train_df = train_df[['text', 'label']]
train_df['text'] = train_df['text'].apply(lambda x: x.replace('\\', ' '))
train_df['label'] = train_df['label'].apply(lambda x:x-1)
eval_df = pd.read_csv('data/test.csv', header=None)
eval_df['text'] = eval_df.iloc[:, 1] + " " + eval_df.iloc[:, 2]
eval_df = eval_df.drop(eval_df.columns[[1, 2]], axis=1)
eval_df.columns = ['label', 'text']
eval_df = eval_df[['text', 'label']]
eval_df['text'] = eval_df['text'].apply(lambda x: x.replace('\\', ' '))
eval_df['label'] = eval_df['label'].apply(lambda x:x-1)
インスタンス生成
from simpletransformers.classification import ClassificationModel
model = ClassificationModel('roberta', 'roberta-base', num_labels=4)
訓練
model.train_model(train_df)
評価
result, model_outputs, wrong_predictions = model.eval_model(eval_df)
以上が元記事に掲載されているサンプルです。簡単ですね。
日本語ではどうなん?
次に日本語の文章ではどれくらい使えるんだろうということで(BERTの理解が足りていませんが)
おなじみlivedoorコーパスで試してみました。
前処理
ダウンロードしたままの状態だとドメインごとに.txtで散らばっているのでCSVにまとめました。
その際にドメインをラベルに置き換え、ラベルと本文のみの状態にします。
ちょっとCPUだとしんどいのでテストは0~2の3ドメインで行いました。
(dokujo-tsushin、it-life-hack、kaden-channel)

これをtrainとtestに分割します
from sklearn.model_selection import train_test_split
X_train_df, X_test_df, y_train_s, y_test_s = train_test_split(
data["text"], data["label"], test_size=0.2, random_state=0, stratify=data["label"]
)
train_df = pd.DataFrame([X_train_df,y_train_s]).T
test_df = pd.DataFrame([X_test_df,y_test_s]).T
train_df["label"] = train_df["label"].astype("int")
test_df["label"] = test_df["label"].astype("int")
訓練&評価
※pretrain_modelの指定を間違えています。日本語のものにしてください。
from simpletransformers.classification import ClassificationModel
model = ClassificationModel('roberta', 'roberta-base', num_labels=3,use_cuda=False)
model.train_model(train_df)
result, model_outputs, wrong_predictions = model.eval_model(test_df)
結果
精度:0.8798329801724872
損失:0.24364208317164218
でした。
元データをまともに読んでいないのでそれぞれのドメインの特徴は把握していませんが、良い精度ですね。
おまけに他のドメイン記事にpredictをかけるとこんな感じになりました。
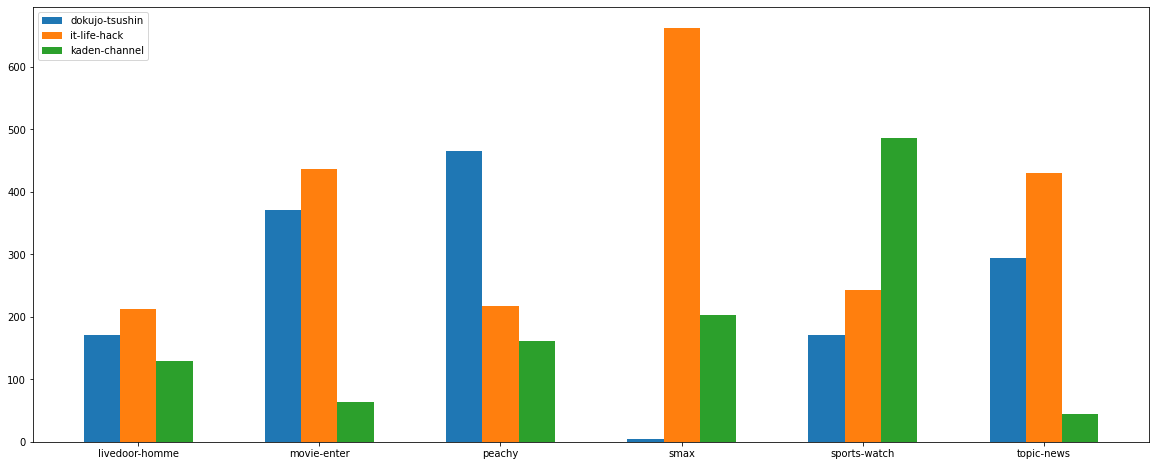
ITライフハックとガジェットサイトのS-MAXが似ていると言えそうですね。
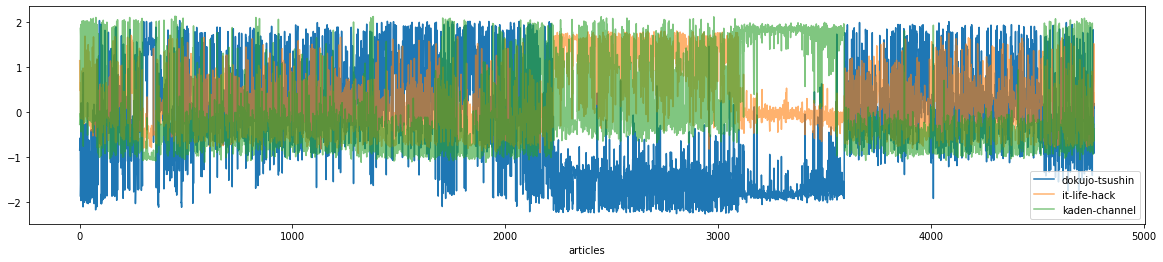
全体の確率
ドメイン分けずに雑にプロットしましたが結構分かれてますね。
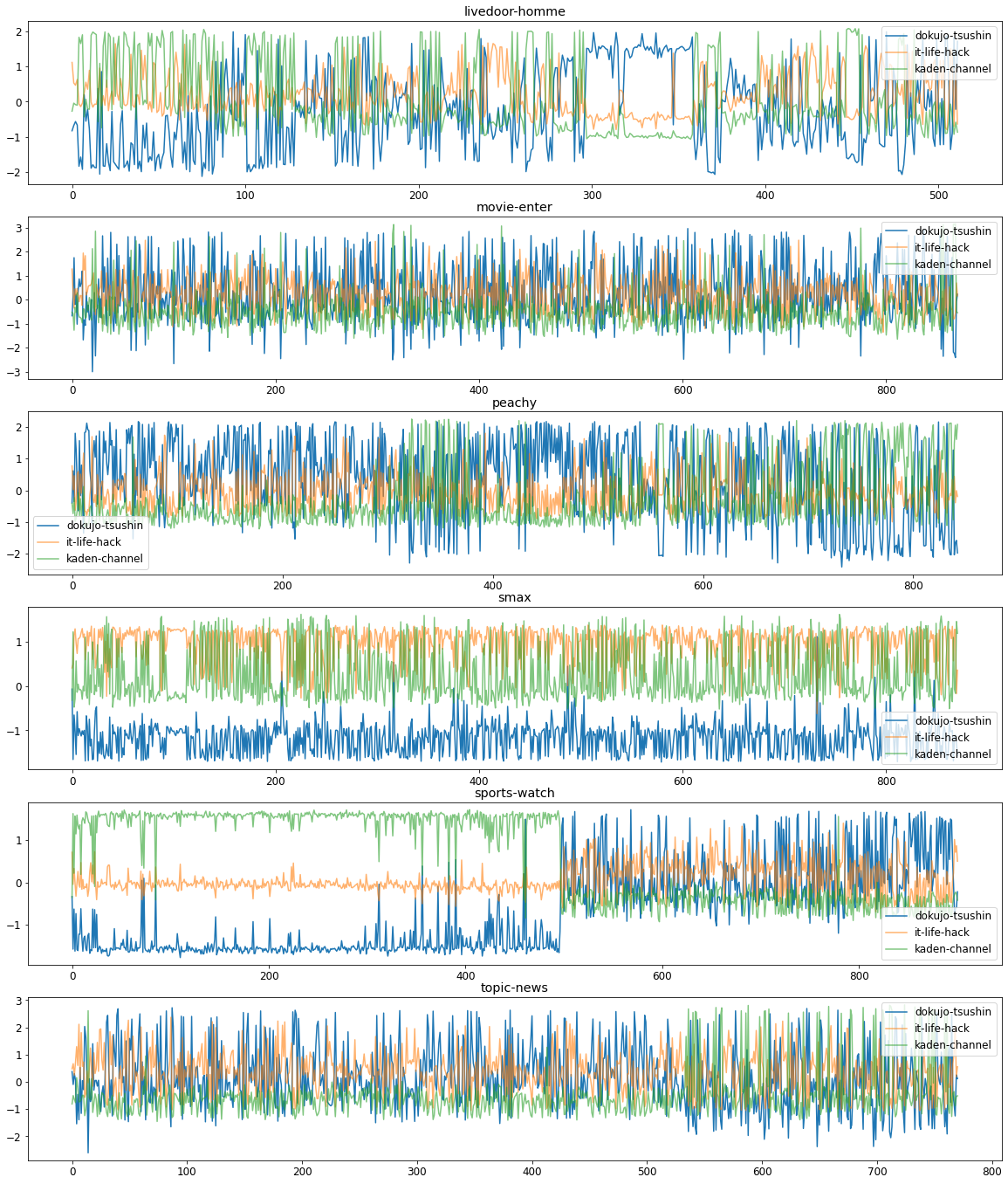
ドメインごとの確率
おわり
こんな感じでデータを用意するだけで簡単にBERTによるテキスト分類が実行できます。
github見た感じ詳細な設定や他タスクにも活用できるようですね。
BERTについて学ぶ前に触ってしまったので少し勉強してからまた色々なデータで試してみようと思います。
ぜひ使ってみてください。