Introduction

The Reinforcement Learning Designer App, released with MATLAB R2021a, provides an intuitive way to perform complex parts of Reinforcement Learning such as:
- Configuration
- Training
- Simulation
from GUI. It may be fresh in your mind that MATLAB users were in a frenzy about its capabilities. This article attempts to use this feature to train the OpenAI Gym environment with ease.
Since reinforcement learning with MATLAB/Simulink is no longer Challenging with this App, I dare to tackle the thorny path of Python (OpenAI Gym) integration.
Reinforcement Learning Designer App:

Set up Python virtual environment for reinforcement learning
The default Python configuration for MATLAB looks like as follows:
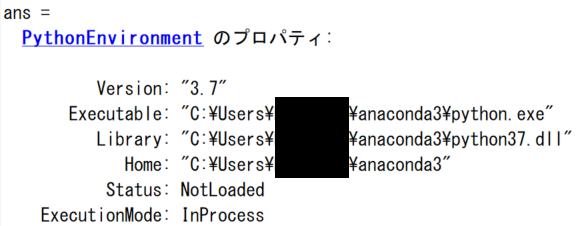
Warning
Having a Python, which is compatible with your MATLAB, is a big prerequisite to call Python from MATLAB*
*Learn more about using Python from MATLAB
We could have installed an OpenAI Gym library in this Python virtual environment, but since it takes time to resolve dependencies between Python libraries (e.g., versioning), we will simply prepare another Python virtual environment just for reinforcement learning from the terminal as follows. In case you are wondering, Anaconda is being used for this time:
conda create --name matlab-rl python=3.7
Next, installing OpenAI Gym.
We've got two ways to install it:
- conda
- pip
though, I had a trouble with conda, so let's "close the eyes to the details" and install OpenAI Gym with pip as follows:
pip install gym==[version]
pip install gym[atari]
Now, we will use the pyenv command for Python integration from MATLAB, but in order to use the Python virtual environment we created above with MATLAB, we will use the following command:
rlPython = {'Version','C:\Users\HYCE\anaconda3\envs\matlab-rl\python.exe'};
pyenv(rlPython{:})

This allows to access the new Python environment from MATLAB.
OpenAI Gym Environement

Let us pull one of the environments for reinforcement learning available from OpenAI Gym:
myenv = py.gym.make('MountainCar-v0')
See GitHub OpenAI Gym for the Python implementaion of this environment.
As you can see from the picture of the environment, it is a simple environment where the goal is to accelerate the car left and right to complete the climb up the mountain. The observations are considered to be the (x,y) coordinates, the speed, and the reward signal, as well as the end condition achievement flag (isdone signal)
Details of this environment
All we need to know is the I/O of the environment at the end of the day, so we gather information from GitHub OpenAI Gym:

Make "Observations" of the environment
According to the information above, there are two pieces of information available as follows:
- Car position
- Car velocity
Let us check them out.
Use the details function to display the properties of a Python object:
details(myenv.reset())

The data property of the object after taking an action is probably the observation data:
res = myenv.reset();
res.data

Surely ... these figures are the two pieces of observational data.
Render and display responses to random actions
In myenv object, you'll see some "typical" methods:
- step
- render
These methods are considered to be useful to confirm the detals of each step such as
- Position (Observation 1: car position)
- Velocity (Observation 2: car velocity)
- Reward (Reward of step)
- isdone (End condition achievement flag)
for i = 1:1000
action = int16(randi([0,2],1));
myenv.step(action);
myenv.render();
end
It works!
Preparation to receive the data back from the environment.
Now that you've seen how it works, check the output with one last action (action):
result = myenv.step(action)

These surely correspond to the observations, [Position, Velocity, Reward, isdone], that MATLAB recieves.
Here we use MATLAB <--> Python technique: "take anything complex as a cell variable for the time being":
% Accept Python results in a cell for now
result = cell(result)
% Check if only Observations can be passed to MATLAB
Observation = double(result{1})'
% Reward
Reward = double(result{2})
% isdone?
IsDone = boolean(double(result{3}))
Now, we can convert them to variable types that can be handled in MATLAB. The rest of the work will be done in MATLAB World, so it will be much easier.
% close the environment
myenv.close();
This concludes the experiment, and we are ready to run reinforcement learning in MATLAB.
Create a custom environment wrapper class
Keeping in mind what we have done so far, we need to convert the "environment" created in Python to the "environment" for MATLAB, so we will create a custom MATLAB environment. The following link will show you how to create custom environment class - Create Custom MATLAB Environment from Template.
when you run
rlCreateEnvTemplate("MountainCar_v0");
a template for MountainCar_v0 environment class is generated. This is the starting point.
Apply the aforementioned technique "take anything complex as a cell variable for the time being" to the template and define MountainCar_v0.m as follows:
click for MountainCar_v0 class
classdef MountainCar_v0 < rl.env.MATLABEnvironment
%MOUNTAINCAR_V0: Template for defining custom environment in MATLAB.
%% Properties (set properties' attributes accordingly)
properties
open_env = py.gym.make('MountainCar-v0');
end
properties
% Initialize system state [x,dx/dt]'
end
properties(Access = protected)
% Initialize internal flag to indicate episode termination
IsDone = false;
end
%% Necessary Methods
methods
% Contructor method creates an instance of the environment
% Change class name and constructor name accordingly
function this = MountainCar_v0()
% Initialize Observation settings
ObservationInfo = rlNumericSpec([2 1]);
ObservationInfo.Name = 'Mountain Car States';
ObservationInfo.Description = 'Position x, Velocity dx/dt';
% Initialize Action settings
ActionInfo = rlFiniteSetSpec([0 1 2]);
ActionInfo.Name = 'Mountain Car Action';
% The following line implements built-in functions of RL env
this = this@rl.env.MATLABEnvironment(ObservationInfo,ActionInfo);
end
% Apply system dynamics and simulates the environment with the
% given action for one step.
function [Observation,Reward,IsDone,LoggedSignals] = step(this,Action)
LoggedSignals = [];
% Observation
result = cell(this.open_env.step(int16(Action)));
Observation = double(result{1})'; % ndarray >> MATLAB double
% Reward
Reward = double(result{2});
% is Done?
IsDone = boolean(double(result{3}));
if (Observation(1) >= 0.4)
Reward = 0;
IsDone = true;
end
this.IsDone = IsDone;
% (optional) use notifyEnvUpdated to signal that the
% environment has been updated (e.g. to update visualization)
notifyEnvUpdated(this);
end
% Reset environment to initial state and output initial observation
function InitialObservation = reset(this)
result = this.open_env.reset();
InitialObservation = double(result)';
% (optional) use notifyEnvUpdated to signal that the
% environment has been updated (e.g. to update visualization)
notifyEnvUpdated(this);
end
end
%% Optional Methods (set methods' attributes accordingly)
methods
% Helper methods to create the environment
end
methods (Access = protected)
% (optional) update visualization everytime the environment is updated
% (notifyEnvUpdated is called)
%function envUpdatedCallback(this)
%end
end
end
Create an environment instance from a custom environment class
Now we will create an instance from our custom environment class. This will be the definition of the environment that will trained in MATLAB.
matEnv = MountainCar_v0();
We wil make sure if this environment is valid. In the case when a custom environment is newly defined, validateEnvironment is used to checkup the custom environment.
validateEnvironment(matEnv)
This function
- makes initial observations and actions
- simulates the environment ofr 1-2 steps
to check in advance if the reinforcement learning is ready to go. If there are no problems, then you can proceed.
Training
The following steps are carried out using the Reinforcement Learning Designer application. Here is the flow:
- Setting up training
- Training
- Simulation & Visualization
- Export Critic & Agent
- Simulation using expored Critic & Agent
1-4 can be carried out within the App.
Setting up training
The environment is the matEnv created earlier, and the agent is specified as follows:
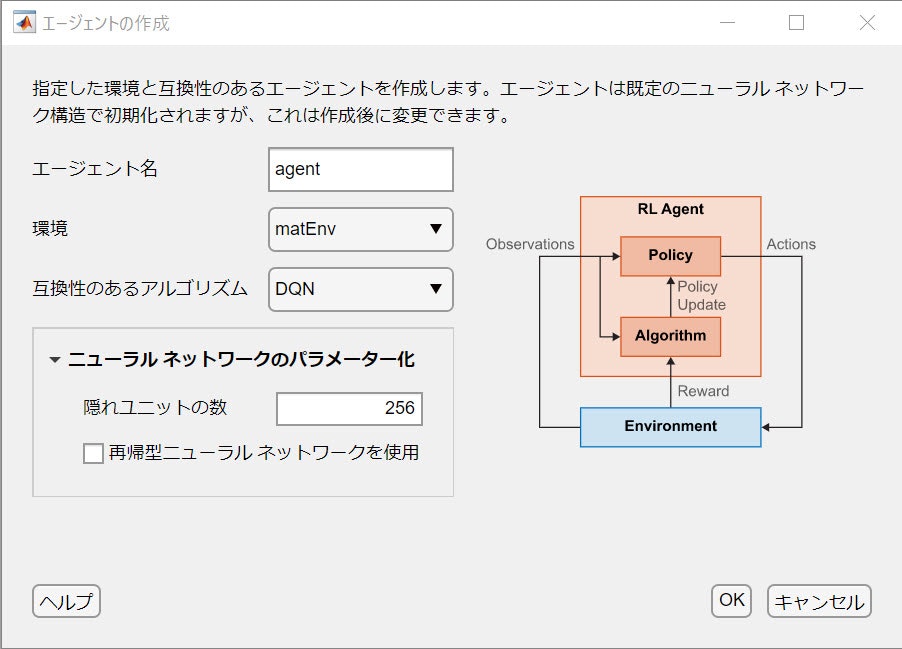
Populate the items with:
- DQN
- The width of the Critic network = 256
The training settings should look like this:
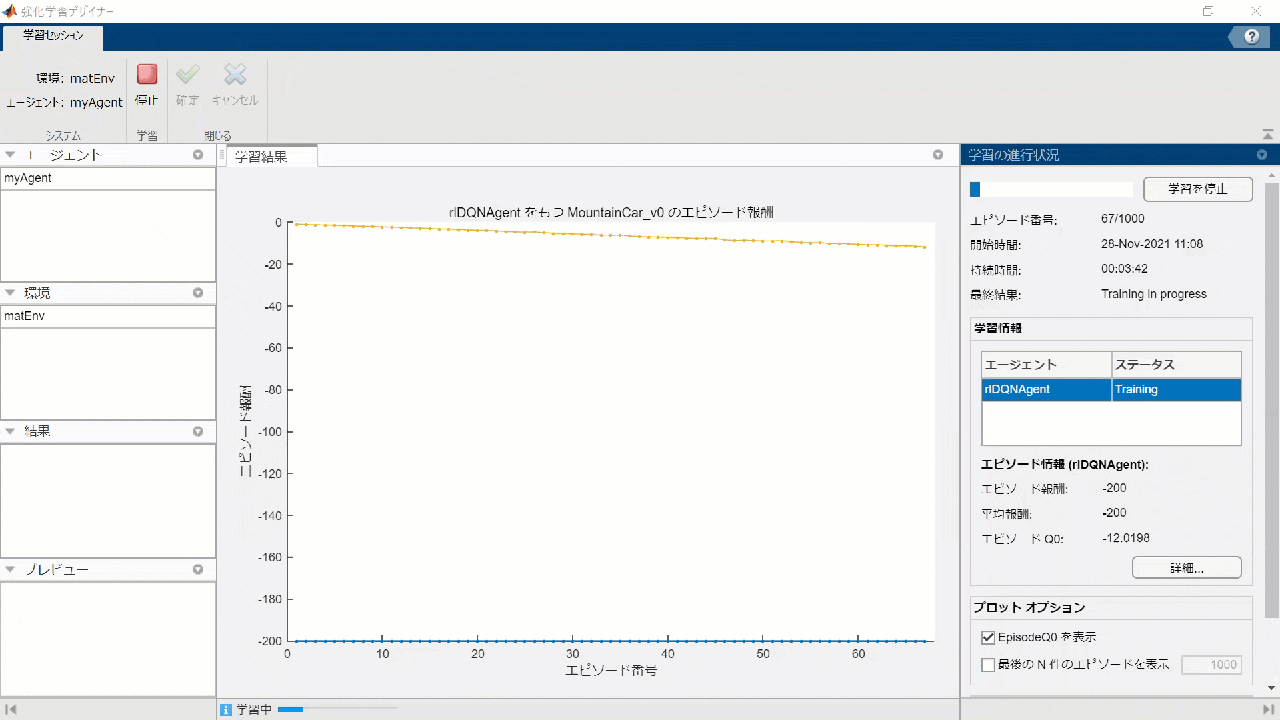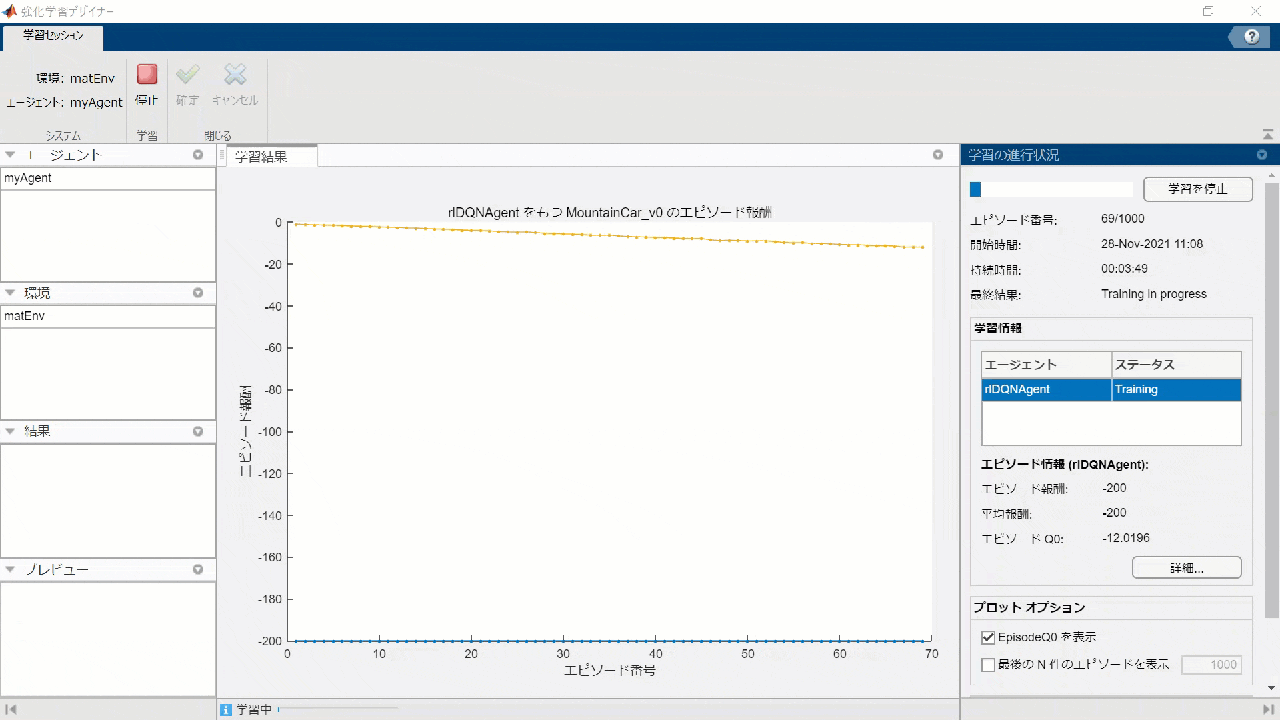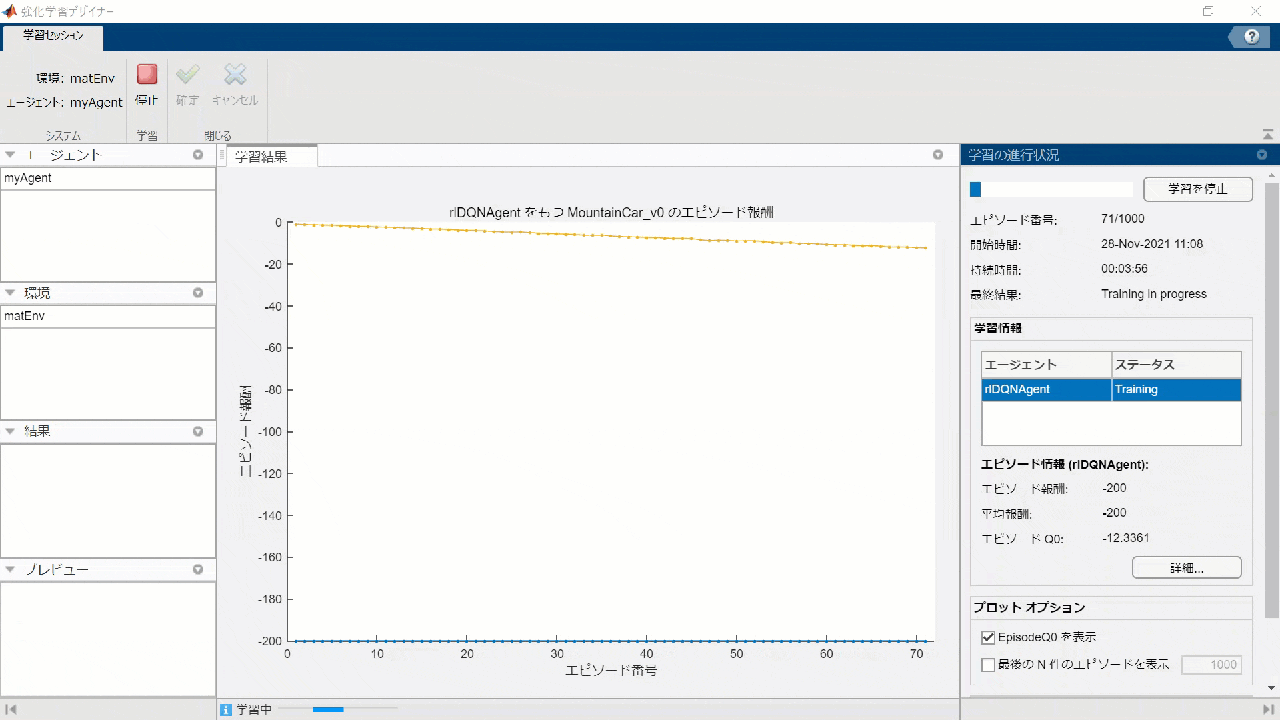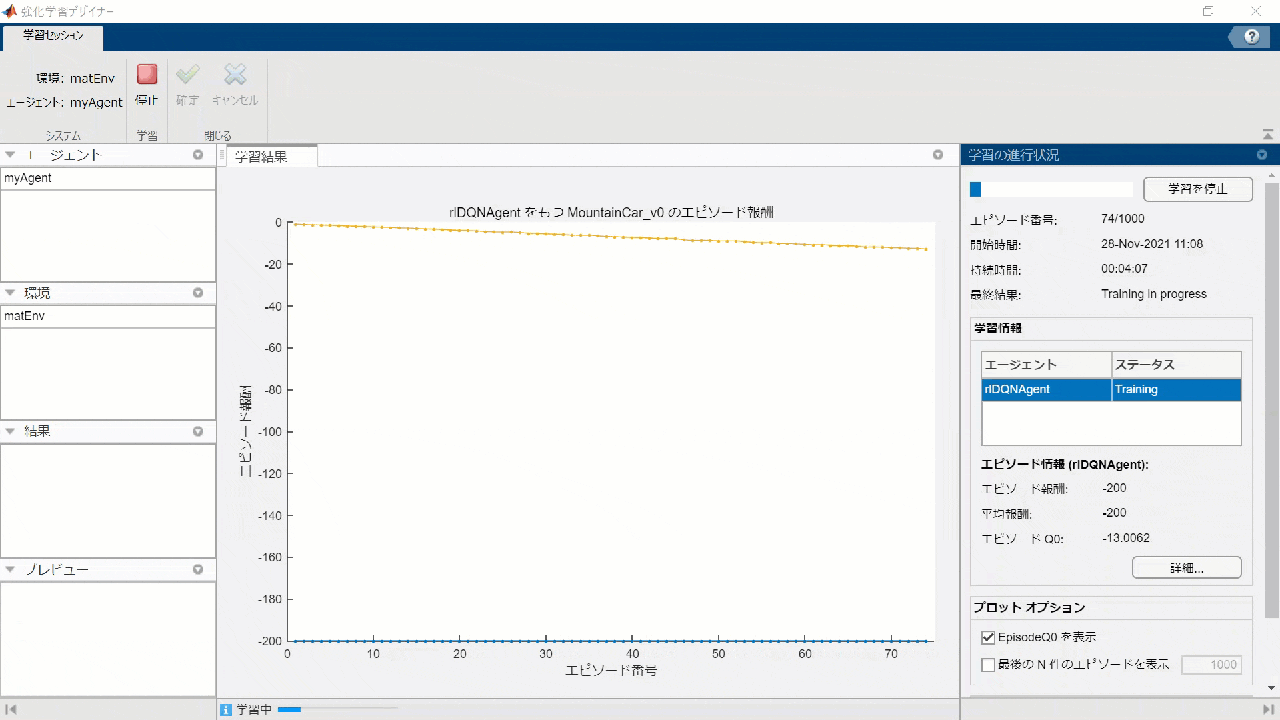
Training
Click the Run button and wait for the rest of the study to finish ....
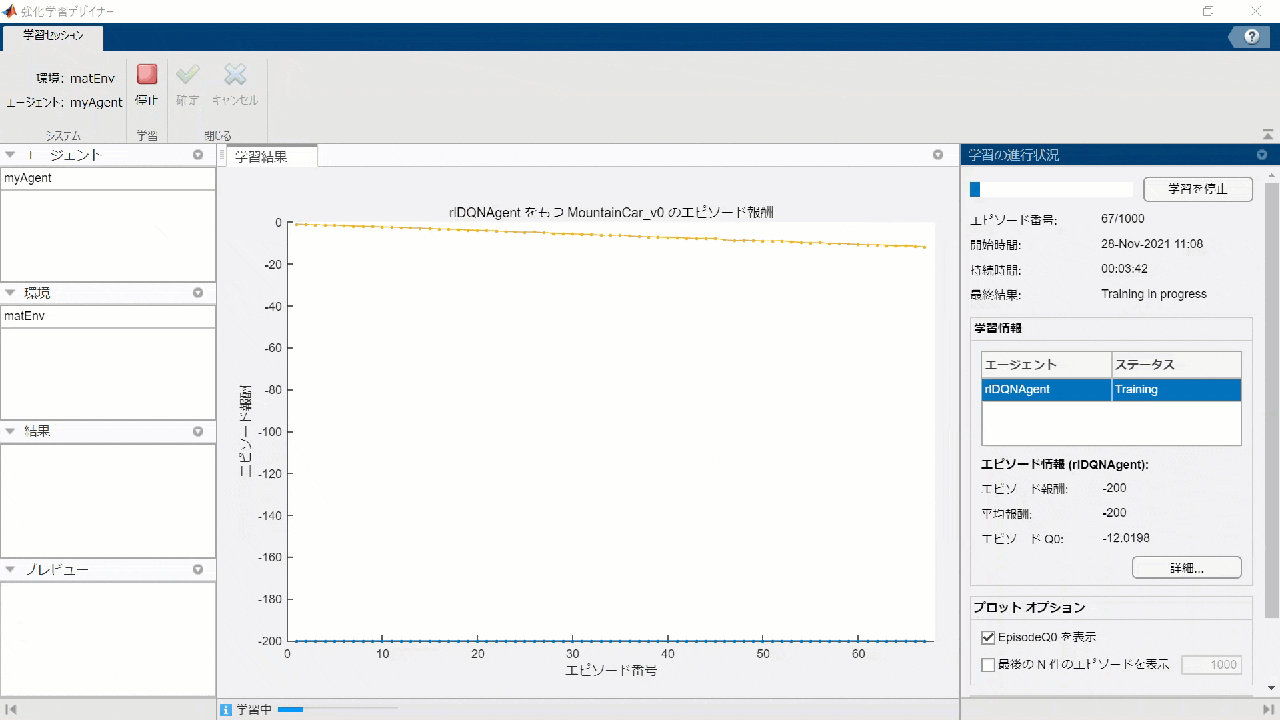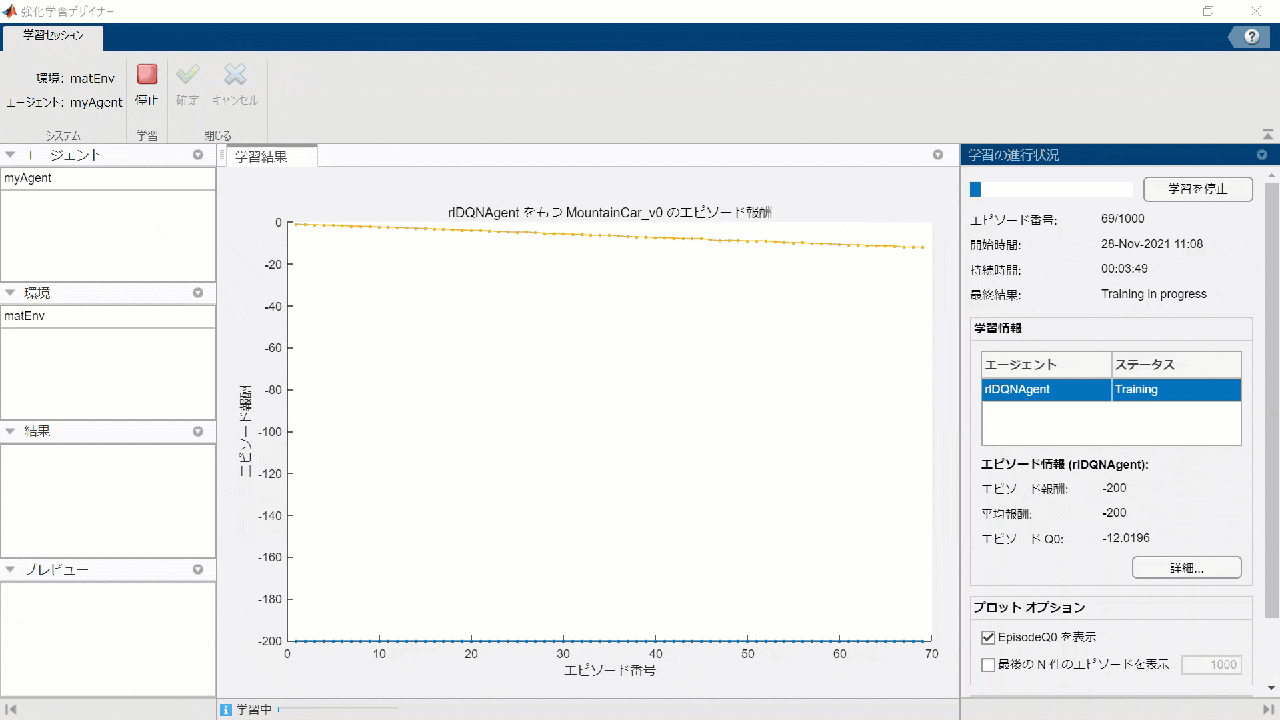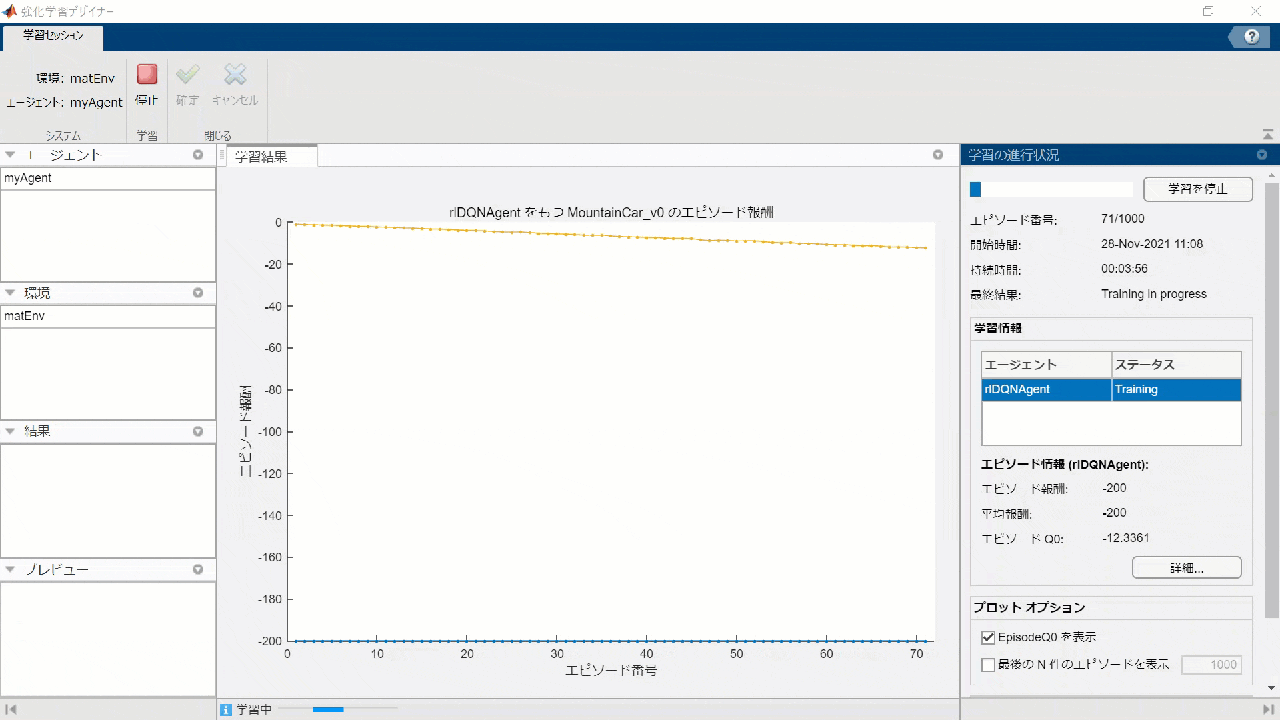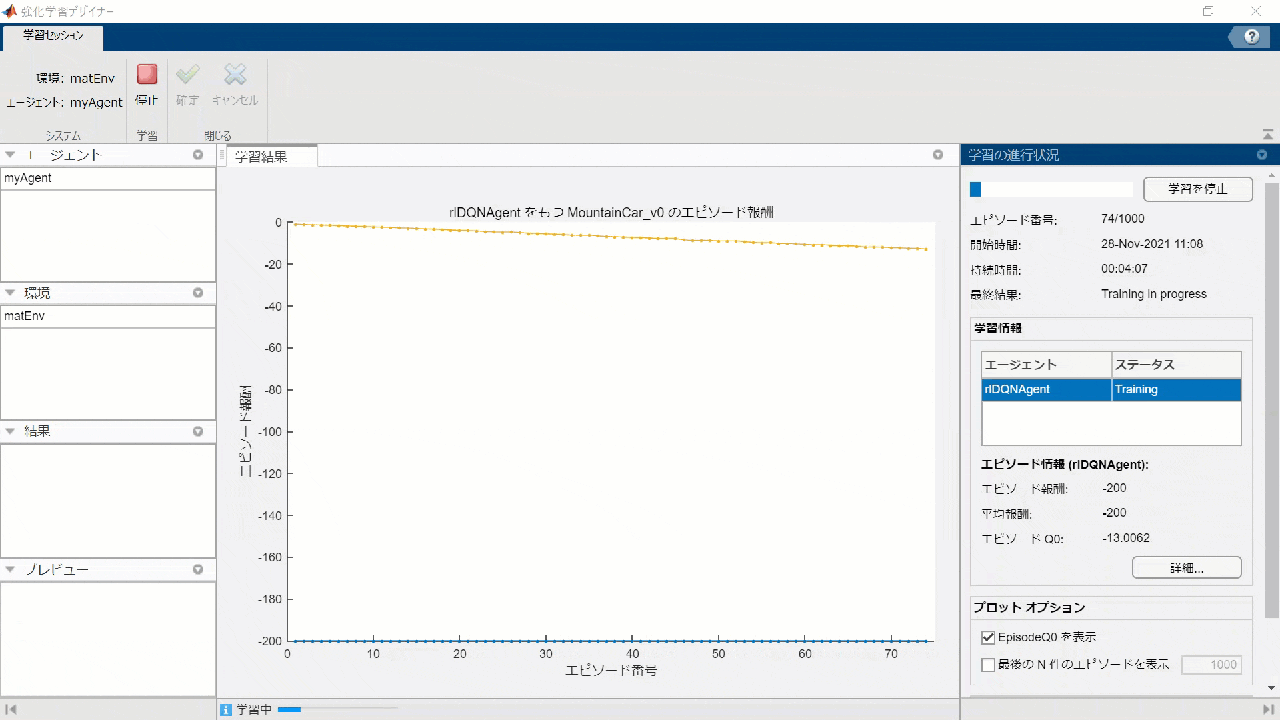
Simulation & Visualization
When training is finished, you can run the simulation from the app, but in this case it will not be rendered and you will not be able to see the car in motion, so exporting the model to run the manual simulation would be a good fit.
Export Critic & Agent
You can export the agent or the elements of the agent - export only networks for deep reinforcement learning as follows:
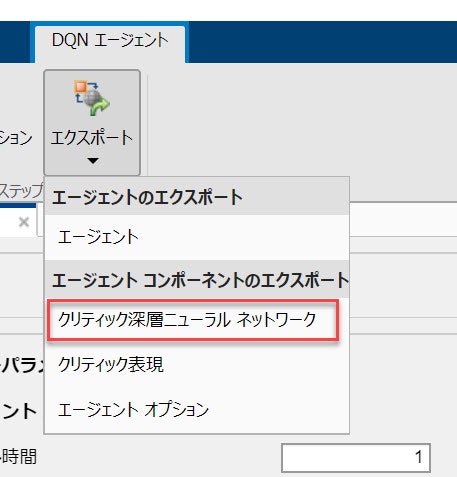
The Critic network will be transfered to the MATLAB workspace. In this configuration, it should be found with its name of agent_criticNetwork.
With R2021a, exported network should be a DAGnetwork object, but with R2021b or later, it should a dlnetwork object. Therefore, the type of the variable passed to the network in R2021b has to be dlarray. The following program for visualization of simulation takes this into account and works with the versions of our interest.
Run a simulation manually to see if the car climbs up the mountain
Let us prepare the function for visualization to render OpenAi Gym. This is the part where you need to do a little bit of work to make MATLAB work with Python, but it's not a big deal for Qiita readers, I bet, since it makes reinforcement learning far easier in return.
- Environment
- Trained network (Critic)
- Number of simulations to run
are passed to the visualization function as follows:
visSim(matEnv,trainedCritic,5);
click for visSim.m
function visSim(env,net,numSim)
% Run Simulation using "step" method
%
%
if isa(net,"dlnetwork") % in case of dlnetwork
dlnetFlag = true;
end
for i=1:numSim
state = single(env.open_env.reset()); % initial [x, dx/dt]
if dlnetFlag % dlnetwork
state = dlarray(state,"BC");
end
isDone = false; % Break criterion
steps = 0; % step counts
while(~isDone && steps < 200)
% Take the best action according to state
% Note that the network accepts S --> Q(S,A)
[~,action] = max(predict(net,state));
if dlnetFlag
action = extractdata(action);
end
% Recieve result from the environment: action \in {0,1,2}
result = cell(env.open_env.step(int16(action-1)));
% Display OpenAI Gym environment
env.open_env.render();
% new [x, dx/dt]
new_state = single(result{1});
% isDone signal
isDone = boolean(single(result{3}));
% stop criterion
if (new_state(1) >=0.49)
isDone = true;
end
state = new_state; % update [x, dx/dt]
if dlnetFlag % dlnetwork
state = dlarray(state,"BC");
end
steps = steps + 1;
end
env.open_env.close(); % Close OpenAI Gym environment
end
end
Now, you will see it is actually working.
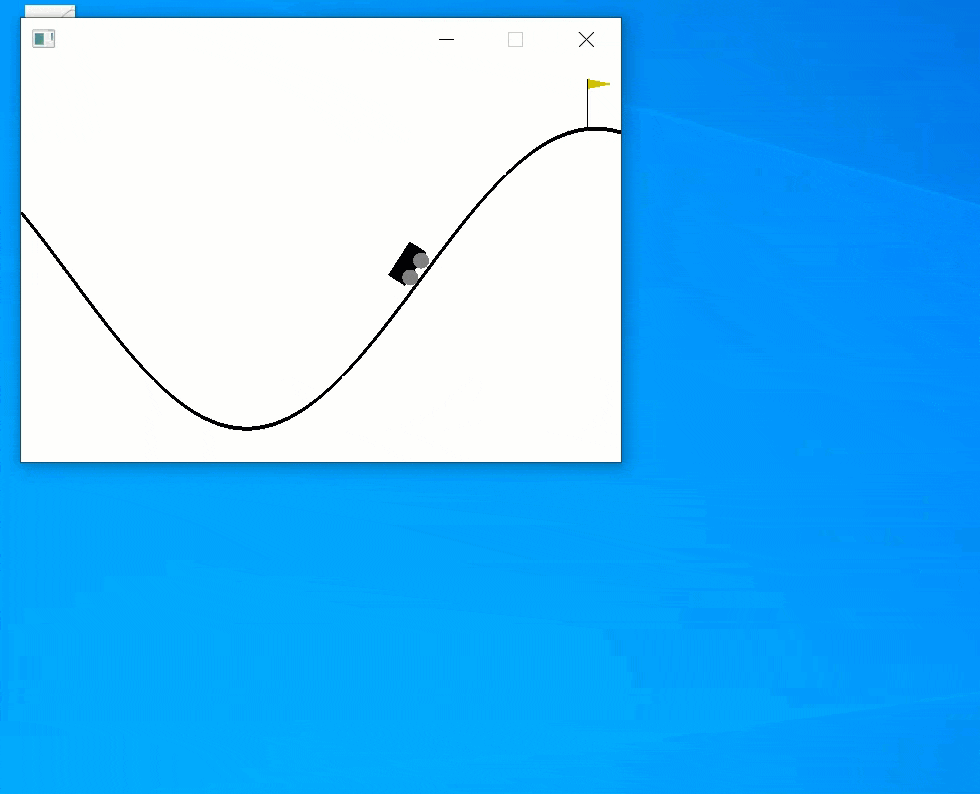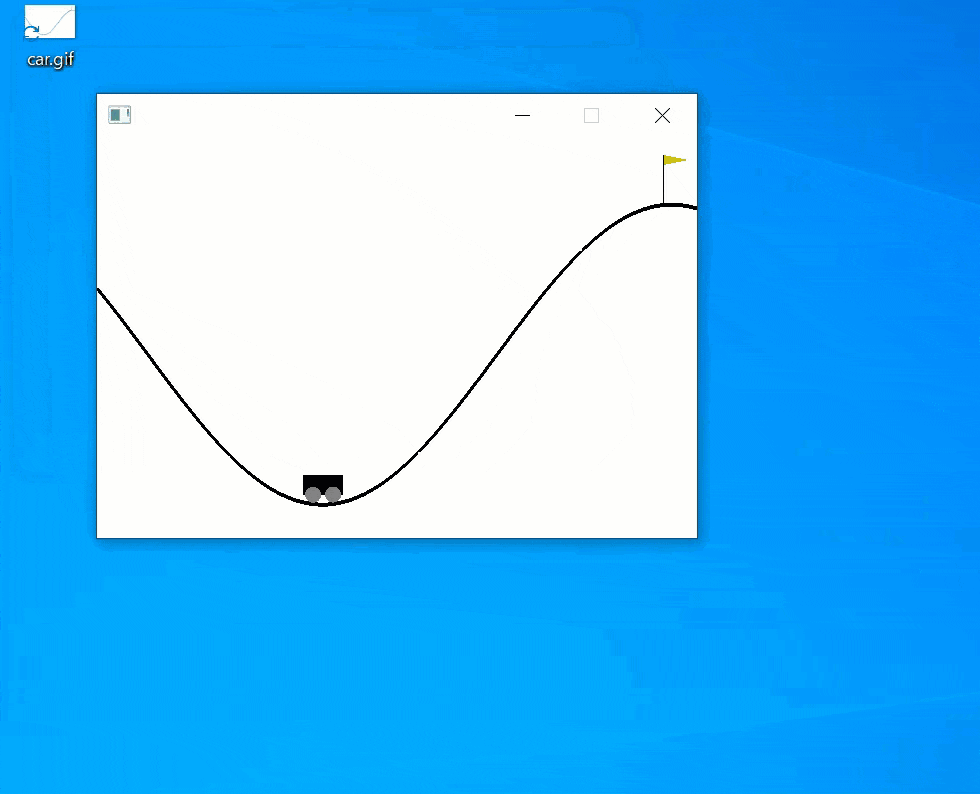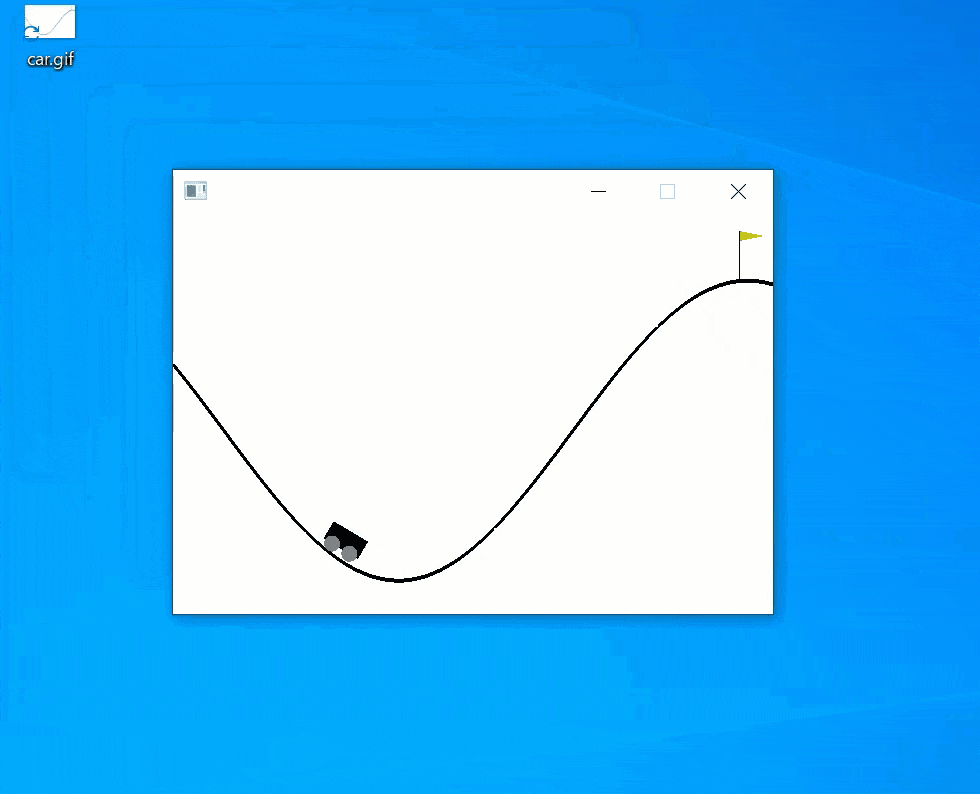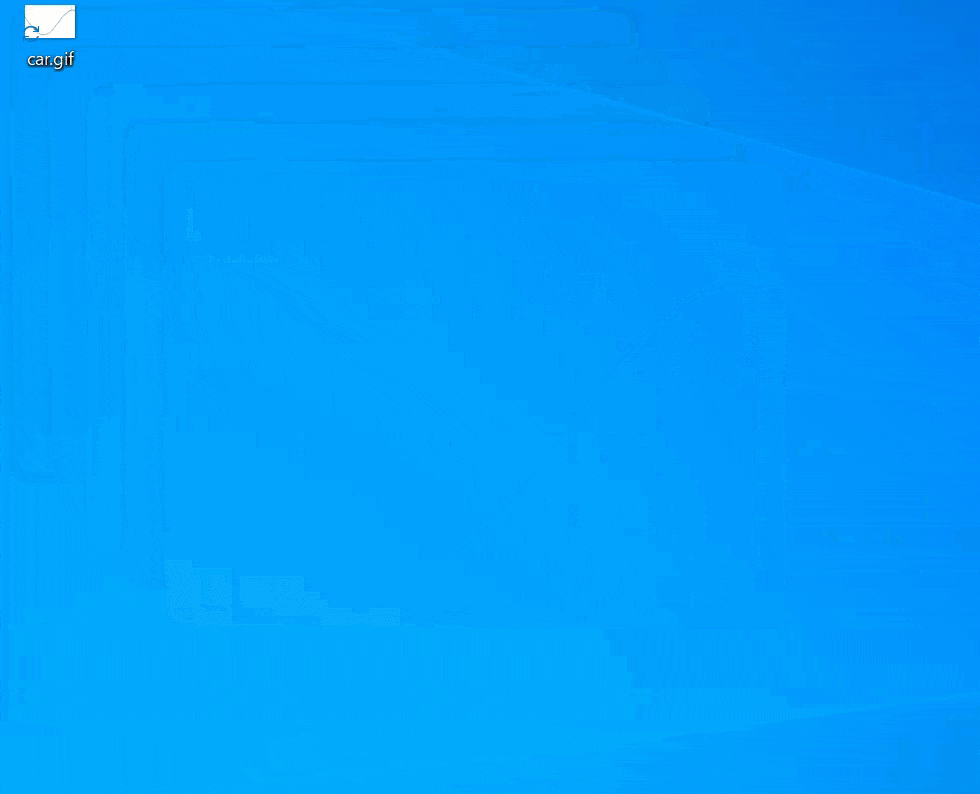
Summary
- We used MATLAB's reinforcement designer App to train an agent in the OpenAI Gym environment.
- To take advantage of Python's rendering, manual simulation is required.
- The reinforcement learning designer App makes the life much easier. That has energized me to try using the environments defined in Python platform.