その2 からの続きです。
前々回ではフォーム画像とスキャン画像の位置合わせ、前回は、フォーム画像のドット領域の矩形情報を取得しました。
さて今回は、それらを利用して、ドット領域の画素を読み込み、塗り絵から 16x32 pixelのドット絵を作成します。
ドット領域の画素の読み込み
位置合わせをした画像に対して、矩形単位でピクセルの色を読み、その平均をその矩形の色として決定します。
ソースコードの抜粋
def getColoringImage(scan, form, rects_file):
''' get 'very small' coloring from scan img'''
# アフィン変換後のスキャン画像を取得
scan = normalize_scan_image(form, scan)
# 格子矩形情報をRead
obj_text = codecs.open(rects_file, 'r', encoding='utf-8').read()
tmp = json.loads(obj_text)
rects = np.array(tmp)
# 最終的に取得する16x32の画像の箱を用意
size = GRID_ROWS, GRID_COLUMNS, 3
bgr_img = np.zeros(size, dtype=np.uint8)
# 黒と白を除いた色の平均を求めるため、HSVで色の有無を確認する
# http://yu-write.blogspot.jp/2013/12/opencv-pythonopencv_12.html
hsv_img = cv2.cvtColor(scan, cv2.COLOR_BGR2HSV)
# 格子矩形のオフセット
offset = 0
# 彩度の閾値 彩度が低いものは無視する
saturation_threshold = 0
# 格子内で最低限必要なピクセルの割合。この数字以下ははみ出た線として無視する
color_pixel_ratio = 0.0
print 'parms : offset ={0}, saturation_threshold = {1}, color_pixel_ratio = {2}'.format(offset, saturation_threshold, color_pixel_ratio)
print "[ X, Y] H S V [R G B ] number of pixels"
idx = 0
for rect in enumerate(rects):
r = rect[1] # r = x, y, w, h
if r[2] == 0 & r[3] == 0: # 右端の線はWとHが0なので無視
continue
# 格子矩形でクリップ
cropped = hsv_img[r[1]+offset:r[1]+r[3]-offset, r[0] + offset: r[0]+r[2]-offset]
# cropped_bgr = scan[r[1]+offset:r[1]+r[3]-offset, r[0]+offset:r[0]+r[2]-offset]
# plt.imshow(cv2.cvtColor(cropped_bgr, cv2.COLOR_BGR2RGB))
# plt.show()
# HSVそれぞれの平均を求める(彩度Sがしきい値よりも大きいピクセルのみを採用)
valid_h_list = [[hsv[0] for hsv in img_line if hsv[1] > saturation_threshold] for img_line in cropped]
valid_s_list = [[hsv[1] for hsv in img_line if hsv[1] > saturation_threshold] for img_line in cropped]
valid_v_list = [[hsv[2] for hsv in img_line if hsv[1] > saturation_threshold] for img_line in cropped]
pixel_count = sum([len(line) for line in valid_h_list])
average_h, average_s, average_v = 0, 0, 0
# 色ついたのピクセル数がcolor_pixel_ratioの割合以上であれば採用
if pixel_count > len(cropped) * len(cropped) * color_pixel_ratio:
average_h = (sum([sum(line) for line in valid_h_list]) / pixel_count)
average_s = (sum([sum(line) for line in valid_s_list]) / pixel_count)
average_v = (sum([sum(line) for line in valid_v_list]) / pixel_count)
# HSV to RGB
bgr_pixel = cv2.cvtColor(np.array([[[average_h, average_s, average_v]]],
dtype=np.uint8),
cv2.COLOR_HSV2BGR)[0][0]
# GRID_COLUMNS x GRID_ROWSの画像にピクセル値を設定する
bgr_img[idx/GRID_COLUMNS, idx-(idx/GRID_COLUMNS)*GRID_COLUMNS] = bgr_pixel
print '[{0:2d}, {1:2d}] {2:3d} {3:3d} {4:3d}, {5:3}, {6:3d}'.format(idx / GRID_COLUMNS + 1, idx - (idx / GRID_COLUMNS) * GRID_COLUMNS + 1, int(average_h+0.5), int(average_s+0.5), int(average_v+0.5), bgr_pixel, pixel_count)
idx = idx + 1
return bgr_img
解説
位置合わせを行ったスキャン画像に対して、色空間をHSVに変換して色の有無を識別します。
一つの格子は約60x60=3600ピクセルあり、色がのっているピクセルの平均を求めることで、その格子の代表値とします。そして最終的には16x32ピクセルの画像を生成しています。
それでは、小学生の娘に描いてもらったドット塗り絵を、実際にスキャンしてこのプログラムにかけてみます。
これは位置合わせ済みの画像です。
")
そして以下が結果です。

一列目をダンプした結果です。
parms : offset =0, saturation_threshold = 0, color_pixel_ratio = 0.0
[ X, Y] H S V [R G B ] number of pixels
[ 1, 1] 35 5 237, [232 237 236], 3721
[ 1, 2] 36 5 236, [231 236 235], 3599
[ 1, 3] 35 4 237, [233 237 236], 3599
[ 1, 4] 35 7 233, [227 233 232], 3658
[ 1, 5] 39 5 236, [231 236 235], 3599
[ 1, 6] 36 4 235, [231 235 234], 3599
[ 1, 7] 36 7 233, [227 233 232], 3658
[ 1, 8] 35 6 237, [231 237 236], 3599
[ 1, 9] 37 4 236, [232 236 235], 3599
[ 1, 10] 34 5 233, [228 233 232], 3658
[ 1, 11] 39 5 237, [232 237 236], 3599
[ 1, 12] 37 4 238, [234 238 237], 3599
[ 1, 13] 36 6 233, [228 233 232], 3658
[ 1, 14] 34 4 238, [234 238 238], 3599
[ 1, 15] 33 4 238, [234 238 238], 3599
[ 1, 16] 36 5 236, [231 236 235], 3599
色が塗られていない格子は、背景色として真っ黒(RGB=0,0,0)になることが期待値です。
ここで捕捉です。
なぜ塗っていない白色を黒色にしているのかというと、LEDの特性として黒は再現できません(点灯しないだけ)。塗り絵の下地は白色ですが、白色をすべて真っ白にしてしまうと。LEDが白色で点灯してしまうことになります。白色のLEDは塗り絵のキャラクターがわかりずらくなるため、背景色は真っ黒(=点灯しない)にしています。(そのため実は塗り絵で白色、黒色は使えません。。)
さてダンプの一列目の値を見ると元のRGB値はすべて真っ白ではありません。そのためHSVの彩度(S)も0にはなっていません。カラーでスキャンしているため下地の色は真っ白にはならないようです。
HSVでどのように色の識別を行うかはこちら を参考にさせていただきました。
それによると、
色相を使う場合には注意点が一つあり、真っ白な点や真っ黒な点のように、どの色相にもあてはまる点の色相は0になります。このような点を含めて平均値を求めてしまうと、平均値は必ず0に近い値になってしまいます。このような点を排除するため、S(彩度)の値を使います。
とのことなので、彩度を使って平均値を求めるピクセルとするかどうかしきい値saturation_threshold を設けました。
ダンプを見ると白色部の彩度は4~7となっているのでsaturation_threshold = 10に変更して実行します。

parms : offset =0, saturation_threshold = 10, color_pixel_ratio = 0.0
[ X, Y] H S V [R G B ] number of pixels
[ 1, 1] 64 55 59, [48 59 46], 230
[ 1, 2] 65 37 89, [78 89 76], 331
[ 1, 3] 60 44 45, [37 45 37], 207
[ 1, 4] 61 62 49, [37 49 37], 314
[ 1, 5] 59 48 47, [38 47 38], 227
[ 1, 6] 54 35 38, [33 38 34], 240
[ 1, 7] 66 73 29, [22 29 21], 277
[ 1, 8] 62 57 62, [49 62 48], 253
[ 1, 9] 64 39 56, [49 56 47], 262
[ 1, 10] 60 45 40, [33 40 33], 271
[ 1, 11] 59 39 55, [47 55 47], 264
[ 1, 12] 60 33 66, [57 66 57], 219
[ 1, 13] 61 39 62, [53 62 53], 377
[ 1, 14] 64 36 54, [47 54 46], 200
[ 1, 15] 59 48 37, [30 37 30], 187
[ 1, 16] 62 39 71, [61 71 60], 298
まだ背景色が真っ黒にならずにぼやけています。
再びダンプを見ると、彩度が10以上のピクセルが200~300あるようです。
[1, 1]の格子の図を拡大して確認してみると、枠線が含まれていることがわかります。

この線が影響しないよう、読み取る領域を、枠線を含まないようにオフセットを設けています。
offset = 5とすると、矩形の上下左右から5ピクセル内側の領域が読み取り対象となります。
枠線だけであればoffset = 5で良さそうです。

parms : offset =5, saturation_threshold = 10, color_pixel_ratio = 0.0
[ X, Y] H S V [R G B ] number of pixels
[ 1, 1] 0 0 0, [0 0 0], 0
[ 1, 2] 0 0 0, [0 0 0], 0
[ 1, 3] 0 0 0, [0 0 0], 0
[ 1, 4] 0 0 0, [0 0 0], 0
[ 1, 5] 0 0 0, [0 0 0], 0
[ 1, 6] 0 0 0, [0 0 0], 0
[ 1, 7] 0 0 0, [0 0 0], 0
[ 1, 8] 0 0 0, [0 0 0], 0
[ 1, 9] 0 0 0, [0 0 0], 0
[ 1, 10] 0 0 0, [0 0 0], 0
[ 1, 11] 0 0 0, [0 0 0], 0
[ 1, 12] 0 0 0, [0 0 0], 0
[ 1, 13] 0 0 0, [0 0 0], 0
[ 1, 14] 0 0 0, [0 0 0], 0
[ 1, 15] 0 0 0, [0 0 0], 0
[ 1, 16] 0 0 0, [0 0 0], 0
枠線を除去した結果、彩度<10のため、白色の部分は真っ黒になりました。
でもまだキャラクターの輪郭がぼやけています。
図中の「ミク」の「ミ」の上のピクセル(列4,行21)に注目してみると、はみ出した線が影響しているようです。

[21, 3] 0 0 0, [0 0 0], 0
[21, 4] 32 36 247, [212 247 245], 111 ★111ピクセルを拾っている
[21, 5] 0 0 0, [0 0 0], 0
[21, 6] 0 0 0, [0 0 0], 0
[21, 7] 0 0 0, [0 0 0], 0
[21, 8] 0 0 0, [0 0 0], 0
[21, 9] 0 0 0, [0 0 0], 0
[21, 10] 100 36 241, [241 230 207], 130
[21, 11] 82 11 251, [248 251 240], 4
[21, 12] 0 0 0, [0 0 0], 0
[21, 13] 0 0 0, [0 0 0], 0
[21, 14] 0 0 0, [0 0 0], 0
[21, 15] 0 0 0, [0 0 0], 0
[21, 16] 0 0 0, [0 0 0], 0
はみ出た線が影響しないようにオフセットを5→10ピクセルに変更します。

オフセットを多くすると平均値を求める画素が減ってしまうため、矩形内における色の面積にもしきい値を設けたいと思います。
例えば色のついたピクセル(彩度10以上)の面積を50%以上とした場合、50%を超えないと真っ黒にします。
色の面積のしきい値はcolor_pixel_ratio = 0.5と指定します。
ではその実行結果です。

やっと意図したものになってきました。ふー。
でもクリボーの中の画素が抜けてしまっています。
ここからは、ここまで出てきたパラメータ(offset, saturation_threshold, color_pixel_ratio)調整の世界となります。
最終的にはこの画像に関しては以下のパラメータが良さそうです。
parms : offset =10, saturation_threshold = 10, color_pixel_ratio = 0.25
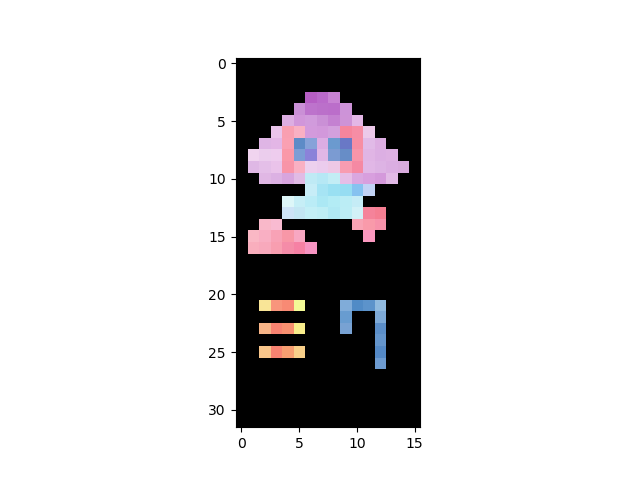
元画像も再掲載。
いい感じではないでしょうか。
そして、最終的な16x32の原寸大画像はこちらです。ダウンロードしてお楽しみください。

512ギャラリー
16x32=512画素のギャラリーです。
さて、プログラム完成直後にすぐに試してみたくて手元の蛍光ペンで描いた猫型ロボットです。太い方で描いたのでそこそこ線を拾えています。


格子を無視した純粋な塗り絵です(モデルは娘の担任(男))。背景に色がついていると、実際のLEDでの表示がどうなるかは確認が必要です。


さてここまで苦労してきましたが、Windows標準のペイントアプリでスキャン画像を16x32に縮小するとどうなるのか試してみました。



結果はいかがですか?1つ目と2つ目は、格子の色を拾っているのか背景がグレーがかっています。キャラクターの輪郭もぼやけているのでこちらに分がありそうです。3つ目はペイントのほうがきれいですね。
ソースコード全文
# -*- coding: utf-8 -*-
import codecs
import json
import numpy as np
from matplotlib import pyplot as plt
import cv2
GRID_COLUMNS = 16
GRID_ROWS = 32
def search_mark(img, pos):
u""" search registar mark """
frmX, toX = 0, 280 # x mark range
frmY, toY = 0, 280 # y mark range
if pos == 0: # left upper
mark = img[frmY:toY, frmX:toX]
rect = {"x": frmX, "y": frmY}
elif pos == 1: # right upper右
mark = img[frmY:toY, img.shape[1]-toX:img.shape[1]-frmX]
rect = {"x": img.shape[1]-toX, "y": frmY}
elif pos == 2: # left bottom
mark = img[img.shape[0]-toY:img.shape[0], frmX:toX]
rect = {"x": frmX, "y": img.shape[0]-toY}
else: # right bottom
mark = img[img.shape[0]-toY:img.shape[0]-frmY, img.shape[1]-toX:img.shape[1]-frmX]
rect = {"x": img.shape[1]-toX, "y": img.shape[0]-toY}
gray = cv2.cvtColor(mark, cv2.COLOR_BGR2GRAY) # モノクロ化
ret, bin = cv2.threshold(gray, 127, 255, 0) # 2値化
# cv2.imshow('out',bin) # トンボの範囲を表示
# cv2.waitKey(1000) #1秒停止
# 輪郭の抽出
contours, hierarchy = cv2.findContours(bin,
cv2.RETR_TREE,
cv2.CHAIN_APPROX_SIMPLE)
print "contours={}, ".format(len(contours)), "hierarchy={}".format(len(hierarchy))
if len(contours) > 1: # 1つめの輪郭は矩形そのものになるため1以上のものを確認
cnt = contours[len(contours)-1] # 末尾の輪郭
M = cv2.moments(cnt) # モーメント
cx = int(M['m10']/M['m00']) # 重心X
cy = int(M['m01']/M['m00']) # 重心Y
else:
return 0, 0 # 輪郭がない場合
cv2.circle(img, (rect["x"] + cx, rect["y"]+cy), 10, (0, 0, 255), -1)
print (cx, cy), '=', (rect["x"] + cx, rect["y"] + cy)
return rect["x"] + cx, rect["y"] + cy # 関数の戻り値
def search_registration_marks(img):
u""" search registration marks"""
cx0, cy0 = search_mark(img, 0) # 左上のトンボの重心(基準)
dx0, dy0 = search_mark(img, 1) # 右上のトンボの重心(基準)
ex0, ey0 = search_mark(img, 2) # 左下のトンボの重心(基準)
fx0, fy0 = search_mark(img, 3) # 右下のトンボの重心(基準)
if (ex0 == 0 & ey0 == 0):
pts2 = np.float32([[cx0, cy0], [dx0, dy0], [fx0, fy0]])
elif (dx0 == 0 & dy0 == 0):
pts2 = np.float32([[fx0, fy0], [ex0, ey0], [cx0, cy0]]) # 180度回転
elif (fx0 == 0 & fy0 == 0):
pts2 = np.float32([[ex0, ey0], [cx0, cy0], [dx0, dy0]]) # 左90度回転
else:
pts2 = np.float32([[dx0, dy0], [fx0, fy0], [ex0, ey0]]) # 右90度回転
return pts2
def normalize_scan_image(form_path, scan_path):
''' normalize scan image'''
# 比較元画像の読み込み
src = cv2.imread(form_path)
pts2 = search_registration_marks(src)
print 'src = ', pts2
# スキャン画像の読み込み
scan = cv2.imread(scan_path)
pts1 = search_registration_marks(scan)
print 'scan = ', pts1
# 画面に収まるようにリサイズして表示
resized_scan = cv2.resize(scan, (scan.shape[1]/4, scan.shape[0]/4))
cv2.imshow("scan", resized_scan)
# アフィン変換
height, width, ch = src.shape
M = cv2.getAffineTransform(pts1, pts2)
dst = cv2.warpAffine(scan, M, (width, height))
resized_dst = cv2.resize(dst, (dst.shape[1]/4, dst.shape[0]/4))
cv2.imshow("affine", resized_dst)
return dst
def getColoringImage(scan, form, rects_file):
''' get 'very small' coloring from scan img'''
# アフィン変換後のスキャン画像を取得
scan = normalize_scan_image(form, scan)
# 格子矩形情報をRead
obj_text = codecs.open(rects_file, 'r', encoding='utf-8').read()
tmp = json.loads(obj_text)
rects = np.array(tmp)
# 最終的に取得する16x32の画像の箱を用意
size = GRID_ROWS, GRID_COLUMNS, 3
bgr_img = np.zeros(size, dtype=np.uint8)
# 黒と白を除いた色の平均を求めるため、HSVで色の有無を確認する
# http://yu-write.blogspot.jp/2013/12/opencv-pythonopencv_12.html
hsv_img = cv2.cvtColor(scan, cv2.COLOR_BGR2HSV)
# 格子矩形のオフセット
offset = 10
# 彩度の閾値 彩度が低いものは無視する
saturation_threshold = 10
# 格子内で最低限必要なピクセルの割合。この数字以下ははみ出た線として無視する
color_pixel_ratio = 0.25
print 'parms : offset ={0}, saturation_threshold = {1}, color_pixel_ratio = {2}'.format(offset, saturation_threshold, color_pixel_ratio)
print "[ X, Y] H S V [R G B ] number of pixels"
idx = 0
for rect in enumerate(rects):
r = rect[1] # r = x, y, w, h
if r[2] == 0 & r[3] == 0: # 右端の線はWとHが0なので無視
continue
# 格子矩形でクリップ
cropped = hsv_img[r[1]+offset:r[1]+r[3]-offset, r[0] + offset: r[0]+r[2]-offset]
# cropped_bgr = scan[r[1]+offset:r[1]+r[3]-offset, r[0]+offset:r[0]+r[2]-offset]
# plt.imshow(cv2.cvtColor(cropped_bgr, cv2.COLOR_BGR2RGB))
# plt.show()
# HSVそれぞれの平均を求める(彩度Sがしきい値よりも大きいピクセルのみを採用)
valid_h_list = [[hsv[0] for hsv in img_line if hsv[1] > saturation_threshold] for img_line in cropped]
valid_s_list = [[hsv[1] for hsv in img_line if hsv[1] > saturation_threshold] for img_line in cropped]
valid_v_list = [[hsv[2] for hsv in img_line if hsv[1] > saturation_threshold] for img_line in cropped]
pixel_count = sum([len(line) for line in valid_h_list])
average_h, average_s, average_v = 0, 0, 0
# 色ついたのピクセル数がcolor_pixel_ratioの割合以上であれば採用
if pixel_count > len(cropped) * len(cropped) * color_pixel_ratio:
average_h = (sum([sum(line) for line in valid_h_list]) / pixel_count)
average_s = (sum([sum(line) for line in valid_s_list]) / pixel_count)
average_v = (sum([sum(line) for line in valid_v_list]) / pixel_count)
# HSV to RGB
bgr_pixel = cv2.cvtColor(np.array([[[average_h, average_s, average_v]]],
dtype=np.uint8),
cv2.COLOR_HSV2BGR)[0][0]
# GRID_COLUMNS x GRID_ROWSの画像にピクセル値を設定する
bgr_img[idx/GRID_COLUMNS, idx-(idx/GRID_COLUMNS)*GRID_COLUMNS] = bgr_pixel
print '[{0:2d}, {1:2d}] {2:3d} {3:3d} {4:3d}, {5:3}, {6:3d}'.format(idx / GRID_COLUMNS + 1, idx - (idx / GRID_COLUMNS) * GRID_COLUMNS + 1, int(average_h+0.5), int(average_s+0.5), int(average_v+0.5), bgr_pixel, pixel_count)
idx = idx + 1
return bgr_img
if __name__ == "__main__":
bgr_img = getColoringImage('scan.jpg', 'form.jpg', 'rects.json')
cv2.imwrite('result.png', bgr_img)
# matplotlibの色空間はRGB
plt.imshow(cv2.cvtColor(bgr_img, cv2.COLOR_BGR2RGB))
plt.show()
その4へ続きます。