この記事について
「等身大3D LED CUBE」(以下LED)上に、スキャンした塗り絵を投影するためのプログラムを開発しました。
これは2017横浜ガジェット祭りで行う子供向けワークショップのコンテンツの一つです。
Windows 10にインストールしたPython2.7 + OpenCV2.4を使った画像処理の結果をまとめています。(Python2.7を利用しているのは実行環境にあわせるためです。後日Python3.xの説明も載せたいと思います。)
ここで扱っている主な画像処理は以下となります。
- 2つの画像の位置合わせ(アフィン変換)
- 格子領域の矩形取得
- 格子内の画素の読み取り
私はPythonとOpenCVともに触るのは今回がはじめてです(Qiitaも!)。冗長なコードが多々あると思いますがご指摘頂けると幸いです。なお、本プログラミングを行うにあたり参考にさせていただいたサイトの皆さまには、この場を借りて感謝申し上げます。
開発環境のセットアップやOpenCVの使い方はこちら を参考にさせていただきました。
ここで使用した全てのコードや画像は、GitHubに掲載予定です。
やりたいこと
ドット絵の塗り絵をスキャナーでスキャンすると、3D LED CUBE上にドット絵を表示したい。
「塗り絵を表示する」というアトラクションは、ららぽーと湘南のGraffiti Natureや、鴨川シーワールドでも見たことがある人気のイベントです。
このようなExperenceを、解像度が縦32x横16x奥行8ドットのLEDで行うにはだいぶ無理がありますが。それでも「制約の中でこそイノベーションは生まれる」という言葉を信じてトライしてみました。
ちなみに、ドット絵といえばファミコンのキャラクターとの親和性が非常に高いですね。
たとえばこんなかんじ。
ファミコン世代なので、このようなキャラクターがLEDの中を飛び跳ねたら単純に楽しそうです。
実現に向けたステップ
- 32x16ドットの塗り絵フォームを作成
- フォーム画像とスキャン画像の位置合わせ
3. トンボの検出
4. アフィン変換 - 格子の識別
- ドット領域の画素の読み込み
- 複数枚の塗り絵からアニメーション画像の生成
- 3D LED CUBEへ描画
32x16ドットの塗り絵フォームを作成
まずはドット塗り絵用A4サイズのフォームをExcelで作成します。
プログラムで読みとるドット領域は決め打ちの位置とするため、スキャン時の変動(位置ずれ、傾き、回転)は自動で補正する必要があります。このため、画像の位置合わせ用にトンボを3点打ったフォームを作成しました。
フォーム画像とスキャン画像それぞれの上にある3点を検出してアフィン変換をかけると位置補正ができます。
トンボの形は単純な「+」です。特徴点によるパターンマッチングを使えばロゴのような画像でもよいかも知れません。
そして作成したのが以下のフォームです(フォーム1)。

3点にトンボを打ち、枠の色は黒いと塗り絵の邪魔になると思いグレーにしてみました。
ひとまずこのフォームをもとに進めていきます。
フォーム画像とスキャン画像の位置合わせ
フォーム画像とスキャン画像のトンボを取得し、そのトンボを利用して位置合わせを行います。
トンボの検出
Excel -> PDF -> JPGに変換したフォーム画像から、3点のトンボと、各ドットの枠座標を抽出します。PDF -> JPG変換はこちらのサイトを利用。
まずはHarrisコーナー検出を試してみます。
import numpy as np
import cv2
# Load an color image in grayscale
img = cv2.imread('3dledcube_01-001.jpg',cv2.IMREAD_COLOR)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
dst = cv2.cornerHarris(gray,2,3,0.04)
# result is dilated for marking the corners, not important
dst = cv2.dilate(dst,None)
# Threshold for an optimal value, it may vary depending on the image.
img[dst>0.01*dst.max()]=[0,0,255]
cv2.imshow('dst',img)
k = cv2.waitKey(0)
if k == 27: # wait for ESC key to exit
cv2.destroyAllWindows()
elif k == ord('s'): # wait for 's' key to save and exit
cv2.imwrite('test01_result.png',img)
cv2.destroyAllWindows()
さて結果はご覧のとおり。

トンボは検出できているのですが、フォームをちょっと手直しします。
- 次工程で利用する格子が検出できていない
- 画像右下のトンボの上端部が、格子下端の線と近いので距離を置く
フォームを修正して再度実験。左側が元画像、右側が結果の画像です。
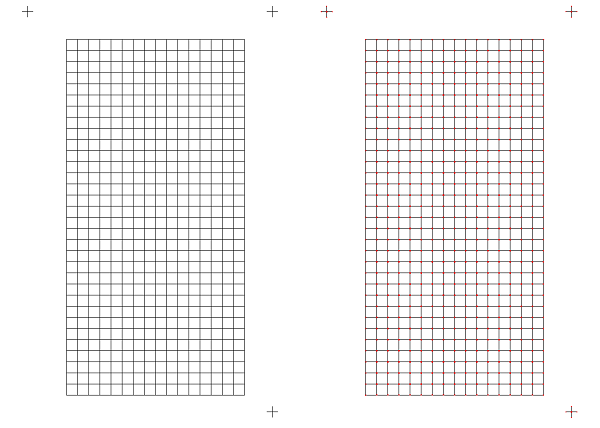
この図ではちょっとわかりにくいのですが、今度はトンボと格子の交点が検出できています。
続いてフォーム画像とスキャン画像のトンボ位置を使った位置合わせを行います。
位置合わせ
スキャンを行うと、用紙の向きが異なったり微妙な位置ずれ(傾き、ズレ、拡大縮小)は普通に発生します。位置ずれは格子領域の読み込みに影響するため、フォーム画像の大きさにあわせて位置ずれを行います。
こちらを参考に、3点の座標値をつかってアフィン変換を行い位置合わせを行いました。
# -*- coding: utf-8 -*-
import numpy as np
import cv2
frmX,toX = 0,280 # トンボの範囲
frmY,toY = 0,280 # トンボの範囲
def searchMark(img, pos):
u""" トンボを探す関数"""
if pos==0: #左側のトンボを探す
mark = img[frmY:toY, frmX:toX]
rect = {"x":frmX, "y":frmY}
elif pos==1: #右側のトンボを探す
mark = img[frmY:toY, img.shape[1]-toX:img.shape[1]-frmX]
rect = {"x":img.shape[1]-toX, "y":frmY}
elif pos==2: #左下のトンボを探す
mark = img[img.shape[0]-toY:img.shape[0], frmX:toX]
rect = {"x":frmX, "y":img.shape[0]-toY}
else:#右下のトンボを探す
mark = img[img.shape[0]-toY:img.shape[0]-frmY, img.shape[1]-toX:img.shape[1]-frmX]
rect = {"x":img.shape[1]-toX, "y":img.shape[0]-toY}
gray = cv2.cvtColor(mark, cv2.COLOR_BGR2GRAY) #モノクロ化
ret, bin = cv2.threshold(gray, 127, 255, 0) #2値化
cv2.imshow('out',bin) #トンボの範囲を表示
cv2.waitKey(1000) #1秒停止
contours, hierarchy = cv2.findContours(bin, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) #輪郭の抽出
print "contours={}, ".format(len(contours)), "hierarchy={}".format(len(hierarchy))
if len(contours) > 1:
cnt = contours[len(contours)-1] #1つめの輪郭
M = cv2.moments(cnt) #モーメント
cx = int(M['m10']/M['m00']) #重心X
cy = int(M['m01']/M['m00']) #重心Y
else:
return 0, 0
cv2.circle(img,(rect["x"]+cx,rect["y"]+cy), 10, (0,0,255), -1)
print (cx, cy), '=', (rect["x"] + cx, rect["y"] + cy)
return rect["x"] + cx, rect["y"] + cy #関数の戻り値
def searchRegistrationMarks(img):
u""" 3つのトンボを探す関数"""
cx0,cy0 = searchMark(img,0) # 左上のトンボの重心(基準)
dx0,dy0 = searchMark(img,1) # 右上のトンボの重心(基準)
ex0,ey0 = searchMark(img,2) # 左下のトンボの重心(基準)
fx0,fy0 = searchMark(img,3) # 右下のトンボの重心(基準)
if (ex0 == 0 & ey0 == 0):
pts2 = np.float32([[cx0,cy0],[dx0,dy0],[fx0,fy0]])
elif (dx0 == 0 & dy0 == 0):
pts2 = np.float32([[fx0,fy0],[ex0,ey0],[cx0,cy0]]) #180度回転
elif (fx0 == 0 & fy0 == 0):
pts2 = np.float32([[ex0,ey0],[cx0,cy0],[dx0,dy0]]) #左90度回転
else:
pts2 = np.float32([[dx0,dy0],[fx0,fy0],[ex0,ey0]]) #右90度回転
return pts2
#
# アフィン変換テスト
#
# 比較元画像の読み込み
src = cv2.imread('3dledcube_03-1.jpg')
pts2 = searchRegistrationMarks(src)
print 'src = ', pts2
resized_src = cv2.resize(src,(src.shape[1]/4, src.shape[0]/4))
cv2.imshow("src", resized_src)
# スキャン画像の読み込み
scan = cv2.imread('3dledcube_03-1_r01.jpg')
pts1 = searchRegistrationMarks(scan)
print 'scan = ', pts1
resized_scan = cv2.resize(scan,(scan.shape[1]/4, scan.shape[0]/4))
cv2.imshow("scan", resized_scan)
height,width,ch = src.shape
M = cv2.getAffineTransform(pts1,pts2)
dst = cv2.warpAffine(scan,M,(width,height))
resized_dst = cv2.resize(dst,(dst.shape[1]/4, dst.shape[0]/4))
cv2.imshow("dst", resized_dst)
cv2.waitKey()
フォーム画像とスキャン画像ともに、用紙の四隅の領域を確認して三箇所トンボの重心となる座標を取得し、それをもとにアフィン変換を行っています。
3点を検出しているため、用紙の向きが90度や180度回転していてもフォーム画像の3点にあわせて位置合わせができます。
テスト結果はこちらです。フォーム画像にあわせて、傾いた画像を補正できています。

その2へ続きます。