前回までに、scikit-learn のロジスティック回帰を使って競馬予測のモデルの赤ちゃんが出来上がりました。
今回は赤ちゃんから幼児くらいには成長させてみようと思います。
モデルの検証
前回までに作成したモデル
説明変数
予想するレースでは、斤量のみ
n 走前のレースでは 斤量・単勝オッズ・人気・補正(補正タイム:クラス内相対値)・補9(補正タイム:絶対値)、確定順位
※前回までに作成したモデルは、1走前までのデータを使用
予測の結果の混合行列
アンダーサンプリング,標準化
正解率 0.7564325552811307
混同行列
[[ 14077 23335]
[ 18676 116394]]
適合率 0.4297926907458859
再現率 0.3762696461028547
F値 0.40125418656025086
# 学習・予測をし直してるので、第3回の記事と若干数値が異なります
実際に馬券を買ったら
この予測モデルでに基づいて、単勝馬券を全て買ったらどうなるか計算してみました
Bet金額 3275300
収支 -718980
回収率 78.04842304521723
回収率 78.0% って出鱈目に買ったときと大差ないのだ
グラフにしてみると
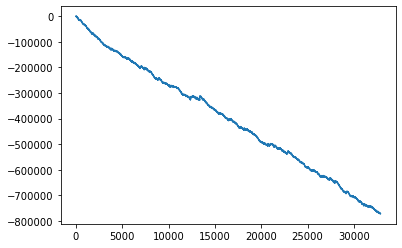
説明変数を2走前までのデータに変更
予測の結果の混合行列
アンダーサンプリング,標準化
正解率 0.753345762034756
混同行列
[[ 12286 21206]
[ 15839 100859]]
適合率 0.43683555555555553
再現率 0.3668338707751105
F値 0.398786049304575
1走前までの説明変数を使ったときと大差ないのだ
実際に馬券を買ったら
この予測モデルでに基づいて、単勝馬券を全て買ったらどうなるか計算してみました
Bet金額 2812500
収支 -611480
回収率 78.25848888888889
回収率 78.3%
僅かに回収率が上昇したが、変化なし
グラフにしてみると
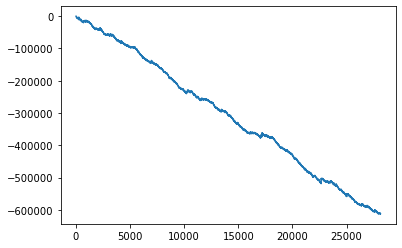
説明変数を3走前までのデータに変更
3走前までのデータを説明変数にする場合も試してみたが、変化なし。
次の方針
回収率を改善するには正解率も大事だが、いかに人気薄の馬を予測し的中できるかが重要
そうすると、多くの人が注目しない説明変数を基に予測したほうがいいのかも
ということで、多くの人が注目しない説明変数で予測してみることにするのだ
多くの人が注目する変数を使わないで予測
馬券の回収率を上げるために、多くの人が注目するような
予測レースの、単勝オッズ・人気
過去のレースの、補正(補正タイム:クラス内相対値)・補9(補正タイム:絶対値)、確定順位
などを説明変数に使わないで予測してみる。
説明変数
予想するレースでは、斤量のみ
n 走前のレースでは 斤量、斤量体重比、枠番、馬番、脚質、キャリア、間隔
馬固有データとして、性別、年齢、父タイプ名、母父タイプ名
※2走前までのレースデータを連結して使用
予測の結果の混合行列
アンダーサンプリング,標準化
正解率 0.7609278248727026
混同行列
[[ 2902 29308]
[ 4591 104993]]
適合率 0.3872948084879221
再現率 0.09009624340266997
F値 0.14618542679394503
Wall time: 7.4 s
再現率が、激減
説明変数が弱いから仕方ないのだ
実際に馬券を買ったら
この予測モデルでに基づいて、単勝馬券を全て買ったらどうなるか計算してした
Bet金額 749300.0
収支 -130960.0
回収率 82.52235419725076
回収率が 82.5% なのには驚き
的中した馬券の 人気 とそのカウントを出力してみると ↓
当たった馬券の 25% は、4番人気以下の馬なので正解率は同じ程度でも回収率が上昇したのだ
1 539
2 246
3 134
4 83
5 61
6 30
7 26
8 15
9 7
10 5
12 2
11 1
グラフにしてみると

次回からの方針
正解率を上げようとすると、回収率が下がる(人気馬ばかり買う予測メソッドになってしまう)
人気に関わる要素(前走までの人気・オッズ・タイム)を入れないと回収率はアップするが、再現率が激減
次回からは、 説明変数を変化させながら回収率を改善する方法を探るのだ 良いアイデアが思い浮かばない💦
今回はここまで![]()