はじめに
Arduino や mono-wireless などのデバイスとシリアル通信でやり取りする際に、送信しているバイナリー命令を確認することが必要になり、バイナリー理解のためのまとめです。以前に書いた記事文字列、Byte、Binaryをアップデートした内容です。
参考になったのは
[Python 入門]バイナリファイルの操作 (1/3)
の記事です。
なお、ここでの内容はPython3.6以上です。
Binary と Byte
おさらいもかねて、バイナリーとは、0,1 で表現されたもの(Bit)ですが、実際には、Byte で扱います。(8bit=1byte)
8bit = 2 の 8 乗=256 で、16 進数で 255 を表現すると FF になります。(0 も含んでいるので 255 が FF になります。)
実際にバイナリーエディター(ここでは、Stirling というソフトを用いています。)で Lena.png ファイルを開いてみると、1byte ごとに数値が並んでいるのがわかります。
(png のバイナリーの並びから画像を解読する方法は、以下の Web を参考にしてください。)
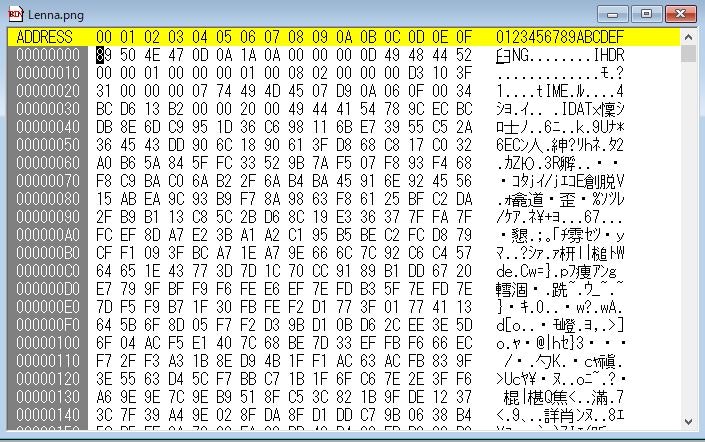
この Byte の並び(数字の並び)が何を意味するかわかっている場合は、Python や他のプログラムで正しく表示されるようになります。
例えば、 Lean.png は、PNG を読むによれば、
その画像ファイルが PNG であることは、ファイル先頭の 8 バイトを読めばわかります。
JPEG では FF D8 の 2 バイトから始まりますが、PNG ファイルではファイルの先頭に 8 バイトの 89 50 4E 47 0D 0A 1A 0A が存在するようです。文字列にすると \x89PNG\r\n\x1a\n こうなります。
先頭の\x89 は非 ASCII 文字で、この非 ASCII 文字からファイルが始まることでテキストファイルとの区別を付けられるようにしているそうです。また、7bit 目をクリアする不正なファイル転送を検知できたり、\r\n などが含まれているのも改行コードを勝手に変換されてしまうのを検知するためだそうです。
encode と decode(エンコード・デコード)
我々がわかる(意味ある)形から Binary(Byte)にすることをエンコードといい、数値の並びから、我々がわかる形にすることをデコードといいます。
エンコード・デコードするには、ルールが必要です。文字列<- ->Binary 変換の場合、 Python でデフォルトで使われているエンコーディングが"UTF-8"です。
Unicode と符号化
前回の記事でも書きましたが、Unicode の番号と(ある文字に対して一意に決めた番号)それを符号化(Binary)するものは違います。
参考:
Unicode と UTF-16 と UTF-8 の違い(秀丸で文字コードを確認)
第 4 回 UTF-8 の冗長なエンコード
例えば、
”あ”は、Unicode では、U+3042 になります。
ビットで表現すると 0011, 0000, 0100, 0010(0x3042)。
UTF-8 で エンコードすると
11100011 10000001 10000010
となります。16 進数で表すと 0xe3, 0x81, 0x82。(3 バイト)
UTF-8 符号化ルールでは、U+0800 から U+FFFF に属する文字は、
1110-xxxx ,10xx-xxxx, 10xx-xxxx, 右からビットを入れていきます。
より詳細は、第 4 回 UTF-8 の冗長なエンコードを参考にしてください。
一番右側:10xx-xxxx --> xxxx=0010, xx=00
真ん中:10xx-xxxx --> xxxx=0001, xx=00
一番左:1110-xxxx --> xxxx=0011
となり、0xe3, 0x81, 0x82 となります。
UTF-16 では、数値の部分は Unicode と同じ 0x3042 になります。(2 バイト)
Python で Binary を扱う
Python で Binary は Bytes 型で取り扱い、b'xxx'がついて表示されます。
また、表記として”\xnn ”が出てきますが、16 進表記文字(n は 0 ~ f)を表しています。
Python で Unicode コードポイントと文字を相互変換(chr, ord, \x, \u, \U)
例えば、文字を使わずに文字列と同様なエスケープシーケンスを使って、「b'a'」と同じ値を持つリテラルを記述する場合は、 b'\x61'と書きます。
ASCII 文字列から Binary へ
ASCII 文字列から Bytes 型への変換は簡単にできます。文字列の前にbをつけるか、エンコードメソッドでエンコードします。
# デフォルトのエンコードはUTF-8
b_data = 'abcd'.encode()
print(b_data,type(b_data))
# >>> b'abcd' <class 'bytes'>
b_data2 = b'abcd'
print(b_data2,type(b_data2))
# >>> b'abcd' <class 'bytes'>
# bytesまたはbytearryを使う場合は、引数はBytes型にしないといけない。
b_data3 = bytes('abcd'.encode())
print(b_data3,type(b_data3))
# >>> b'abcd' <class 'bytes'>
# abcdの16進数を入れても同じ
b_data4 = bytes([0x61,0x62,0x63,0x64])
print(b_data4,type(b_data4))
# >>> b'abcd' <class 'bytes'>
# abcdの16進数をエスケープシーケンスで入れても同じ
b_data5 = b'\x61\x62\x63\x64'
print(b_data5,type(b_data5))
# >>> b'abcd' <class 'bytes'>
実際に Binary editor で確かめるためにファイルに書き出してみます。
Binary にすると文字列のように結合することができます。
with open('./b_file1.bin','wb') as f:
f.write(b_data+b_data2+b_data3+b_data4+b_data5)
Binary editor で読み込んでみると、

16 進数 61,62,63,64 (abcd)が 5 セット並んでいるのがわかります。
Unicode 文字列から Binary へ
ASCII 文字列は 1Byte で表現できますが、日本語は 1Byte では表現できません。そのため日本語を Binary に変換するためには encode する必要があります。
b_data6 = 'あ'.encode('utf-8')
print(b_data6)
# >>>b'\xe3\x81\x82'
# ちなみにb'あ'ではエラーになります。
# print(b'あ')
# >>>SyntaxError: bytes can only contain ASCII literal characters.
# 試しにエンコーディングをかえてみます。
b_data7 = 'あ'.encode('utf-16')
print(b_data7)
# >>>b'\xff\xfeB0'
実際に Binary editor で確かめるためにファイルに書き出してみます。
with open('./b_file2.bin','wb') as f:
f.write(b_data6+b_data7)

UTF-8 でエンコードした値が 3 バイト入っています。次に 4 バイトあります。
先ず最初の 3 バイトは、「Unicode と符号化」で示した通り、E3 81 82 となっています。
次の 4 バイトについてですが、UTF-16 では 2 バイトの 0x30、0x42 になるはずですが、4 バイトになっています。
UTF-16 でエンコードした場合、BOM( Byte Order Mark : バイトオーダーマーク)がついてくるため 4 バイトになっています。UTF-16 ではビッグエンディアンの場合は「FE FF」、リトルエンディアンの場合は「FF FE」と記述されます。Python では、リトルエンディアン(小さい方の数字を先に記述する。)で変換されているため上記のような 4 バイトのリトルエンディアンの出力になっています。
ちなみに Python で UTF-8 で BOM 付きでエンコードする場合は、encoding='utf-8-sig'とします。”あ”の BOM 付きでは、b'\xef\xbb\xbf\xe3\x81\x82'となります。「EF BB BF」が BOM。
参考:Python3 での windows 上のテキスト設定ファイルの読み方
ASCII 文字列(数字)から Binary へ
文字列の数字は、ASCII コードの数字が割り当てられます。
b_data8 = b'1234'
print(b_data8,type(b_data8))
# >>>b'1234' <class 'bytes'>
# 実際にBinary editorで確かめるためにファイルに書き出してみます。
with open('./b_file3.bin','wb') as f:
f.write(b_data8)

ASCII コードの 0x31, 0x32, 0x33, 0x34 10 進数では 49, 50, 51, 52 となります。(ASCII コード表を確認してみてください。)
Int(0-255)から Binary
0-255 までの整数では 1Byte なので、bytes または、bytearray で対応可能です。
# int to bytes
# 0-255までの数字、それ以外はエラーになる
b_int1 = bytes([1,2,3,4,255])
print(b_int1,type(b_int1))
# >>>b'\x01\x02\x03\x04\xff' <class 'bytes'>
b_int2 = bytes([0x01,0x02,0x03,0x04,0xff])
print(b_int2,type(b_int2))
# >>>b'\x01\x02\x03\x04\xff' <class 'bytes'>
b_int3 = bytes([256])
print(b_int3,type(b_int3))
# >>>ValueError: bytes must be in range(0, 256)
Int から Binary
x=256
print(x.to_bytes(2,'little'))
# >>>b'\x00\x01'
print(x.to_bytes(2,'big'))
# >>>b'\x01\x00'
.to_bytes メソッドで bytes 型に変換できます。byte の読み込み順(エンディアン)と何バイトで表すかを引数で指定する必要があります。
y=b'\x01\x00'
print(int.from_bytes(y, byteorder = "big"))
# >>>256
bytes 型から整数型に戻すには int.from_bytes 関数を用いることで元に戻すことができます。
Struct モジュール
様々な値(浮動小数など)を扱う場合、struct モジュールを利用します。 変換したい数値を何バイトで表現するか(されているか)の情報が必要です。
エンコード(pack)
import struct
print(struct.pack('hhhhi',1,2,3,32767,256))
# >>>b'\x01\x00\x02\x00\x03\x00\xff\x7f\x00\x01\x00\x00'
1,2,3,32767 の数値を
h:2byte, short(C 言語型) リトルエンディアンでエンコードします。
256 の数値を
i:4byte, int(C 言語型) リトルエンディアンでエンコードします。
# 先頭に>をつけるとビッグエンディアンになります。
print(struct.pack('>hhhhi',1,2,3,32767,256))
# >>>b'\x00\x01\x00\x02\x00\x03\x7f\xff\x00\x00\x01\x00'
デコード(unpack)
エンコードして作った Bytes 型を元に戻します。デコードには unpack を用います。
data = b'\x00\x01\x00\x02\x00\x03\x7f\xff\x00\x00\x01\x00'
print(struct.unpack('>hhhhi',data))
# >>>(1, 2, 3, 32767, 256)
まとめ
文字列では、encode()メソッドで Bytes 型に変換でき、その逆は、decode()メソッドで文字列に戻すことができます。
整数型では、to_bytes()メソッドで Bytes 型に変換でき、その逆は int.from_bytes()関数で整数型に戻すことができます。
より複雑なことをする場合には、struct モジュールを使って、byte の順番(エンディアン)、何バイトで表現するのかを指定します。Bytes 型に変換する場合には、pack()関数、元に戻すには、unpack()関数を用います。
Bytes 型では文字列同じように「+」で bytes 列同士を結合できます。
変換した Bytes 型が正しいかどうかは、めんどくさいですが、バイナリファイルで保存して、バイナリーエディターで確認してみると良いかもしれません。