はじめに
PNGフォーマットの生みの親のグレン・ランダース=パーソン氏が先月亡くなったというニュースを見て、WebエンジニアとしてPNG形式に相当お世話になっている割には、その構造がどうなっているのかというのをあまり知らないということに思い至りました。
そこで、今更ですがPNGファイルの構造を調べつつ、PNGファイルを読み込むプログラムを簡単に書いてみました。
PNGであること
その画像ファイルがPNGであることは、ファイル先頭の8バイトを読めばわかります。
JPEGではFF D8の2バイトから始まりますが、PNGファイルではファイルの先頭に8バイトの 89 50 4E 47 0D 0A 1A 0A が存在するようです。文字列にすると \x89PNG\r\n\x1a\n こうなります。
先頭の\x89は非ASCII文字で、この非ASCII文字からファイルが始まることでテキストファイルとの区別を付けられるようにしているそうです。また、7bit目をクリアする不正なファイル転送を検知できたり、\r\nなどが含まれているのも改行コードを勝手に変換されてしまうのを検知するためだそうです。
チャンク
最初の8バイトのPNGシグネチャをのぞいて、チャンクというデータのまとまりが続きます。
| 種類 | サイズ | 説明 |
|---|---|---|
| length | 4 bytes | チャンクのdata部分のバイト数を表す |
| type | 4 bytes | 4文字でチャンクの種類を表す |
| data | 可変長 bytes | lengthで指定されたbyte長のチャンクのデータ |
| CRC | 4 bytes | typeとdataのCRCで、データの破損をチェックできる |
チャンクの種類
チャンクの種類はいろいろありますが、絶対に必要なチャンクが3種類あり、IHDRとIDATとIENDです。
IHDRは画像のサイズやカラータイプなどの情報が保持されてる場所で、IDATは実際の画像データが圧縮された形式で格納されています。IENDは画像データの終わりを表します。
ちなみにIHDRチャンクはすべてのチャンクの先頭、つまりPNGのシグネチャの次に位置します。
チャンク読み込みの流れ
- まず、先頭の8byteを読み込みPNG画像であることを確認
- IHDRチャンクを読み込む
- IENDまで(IDATチャンクなどの)チャンクを読み込む
- 読み込んだIDATチャンクは圧縮されているので展開する
PNG画像の読み込み
利用する画像
Wikipediaにあったレナ画像を利用します。
https://en.wikipedia.org/wiki/File:Lenna_(test_image).png

プログラム
go言語で書いて行きます。goの標準パッケージにある image/png/reader.go が完成されているので、これを参考にしながらコードを書いて行きます。
まずは画像ファイルをオープンし、先頭8 bytesを読み込みPNG画像であることを確認するまでのコードを書いてみます。
package main
import (
"fmt"
"io"
"os"
"path/filepath"
)
func parse(r io.Reader) error {
buffer := make([]byte, 8)
_, err := io.ReadFull(r, buffer)
if err != nil {
return err
}
if string(buffer) != "\x89PNG\r\n\x1a\n" {
return fmt.Errorf("not a PNG")
}
return nil
}
func main() {
imageFile := filepath.Join("images", "lenna.png")
file, err := os.Open(imageFile)
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
err = parse(file)
if err != nil {
fmt.Println(err)
return
}
fmt.Println("Complete")
}
io.ReadFull()は指定したバッファのサイズ分読み込み、読み込めない場合にはエラーを返します。読み込むバイト長が決まっているPNGの読み込みに便利な関数で、標準パッケージでもこちらが利用されています。今回はそこまで大きなファイルを読み込まないことやbufferサイズをいちいち定義するのがめんどくさいので、Bufferにすべてを読み込み、先頭から逐次的に読み込み処理していくという方針にします。
package main
import (
"bytes"
"fmt"
"io"
"os"
"path/filepath"
)
func parse(r io.Reader) (err error) {
buffer := new(bytes.Buffer)
_, err = buffer.ReadFrom(r)
if err != nil {
return err
}
if string(buffer.Next(8)) != "\x89PNG\r\n\x1a\n" {
return fmt.Errorf("not a PNG")
}
return nil
}
func main() {
imageFile := filepath.Join("images", "lenna.png")
file, err := os.Open(imageFile)
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
err = parse(file)
if err != nil {
fmt.Println(err)
return
}
fmt.Println("Complete")
}
buffer.Next(8)で8 bytes分読み込むというコードが書けるので直感的ですね。
CRCのチェックなどは行わずに最低限のコードを書くという方針で、以降コードを書いていこうと思います。
IHDRチャンクを読み込む
IHDRチャンクは25byteと長さが決まっています。lengthの4 bytesとCRCの4 bytesを除いた13 bytesの内訳は順に次のようになります。
| 種類 | サイズ |
|---|---|
| 画像幅 | 4 bytes |
| 画像高さ | 4 bytes |
| ビット深度 | 1 byte |
| カラータイプ | 1 byte |
| 圧縮方式 | 1 byte |
| フィルタ方式 | 1 byte |
| インターレース方式 | 1 byte |
圧縮方式やフィルタ方式は国際規格では0のみが定義されています。インターレース方式は無しの0かAdam7の1の2パターンが定義されています。
カラータイプは5種類あり、これは0(グレースケール)、1(パレット使用)、2(Trueカラー)、4(透過)の組み合わせの合計値になります。それぞれのカラーについて許可されるビット深度が異なってきます。
| カラータイプ | PNG画像タイプ | 許可されるビット深度 |
|---|---|---|
| 0 | グレースケール画像 | 1,2,4,8,16 |
| 2 | Trueカラー画像 | 8,16 |
| 3 | インデックスカラー画像 | 1,2,4,8 |
| 4 | グレースケール画像(透過) | 8,16 |
| 6 | Trueカラー画像(透過) | 8,16 |
以上をもとにparse()をちょこっと書き換えます。
func parse(r io.Reader) (err error) {
buffer := new(bytes.Buffer)
_, err = buffer.ReadFrom(r)
if err != nil {
return err
}
// PNGシグネチャの読み込み
if string(buffer.Next(8)) != "\x89PNG\r\n\x1a\n" {
return fmt.Errorf("not a PNG")
}
// IHDRチャンクの読み込み
_ = buffer.Next(4)
if string(buffer.Next(4)) != "IHDR" {
return fmt.Errorf("invalid")
}
width := int(binary.BigEndian.Uint32(buffer.Next(4)))
height := int(binary.BigEndian.Uint32(buffer.Next(4)))
depth := int(buffer.Next(1)[0])
colorType := int(buffer.Next(1)[0])
if int(buffer.Next(1)[0]) != 0 {
return fmt.Errorf("unknown compression method")
}
if int(buffer.Next(1)[0]) != 0 {
return fmt.Errorf("unknown filter method")
}
interlace := int(buffer.Next(1)[0]) == 1
_ = buffer.Next(4) // CRC
fmt.Println("width:", width, "height:", height, "depth:", depth, "colorType:", colorType, "interlace:", interlace)
return nil
}
width: 512 height: 512 depth: 8 colorType: 2 interlace: false
Complete
IDATチャンクの読み込み
チャンクタイプでIENDが登場するまで、IDATのデータ部分をひたすらスライスに追加していきます。
func parse(r io.Reader) (err error) {
// ...略...
// IDATチャンクの読み込み
data := make([]byte, 0, 32)
loop := true
for loop {
length := int(binary.BigEndian.Uint32(buffer.Next(4)))
chunkType := string(buffer.Next(4))
switch chunkType {
case "IDAT":
fmt.Println("chunk: IDAT")
data = append(data, buffer.Next(length)...)
_ = buffer.Next(4) // CRC
case "IEND":
fmt.Println("chunk: IEND")
loop = false
default:
fmt.Println("chunk:", chunkType)
_ = buffer.Next(length) // chunk data
_ = buffer.Next(4) // CRC
}
}
fmt.Println("data length:", len(data))
return nil
}
width: 512 height: 512 depth: 8 colorType: 2 interlace: false
chunk: sRGB
chunk: IDAT
chunk: IEND
data length: 473761
Complete
チャンクタイプも表示するようにしました。
IDATが複数登場する場合もあるらしいのですが、今回は1つしかIDATは存在しませんでした。
dataスライスの長さがそのままバイト数になるので、今回の画像は473761 bytes(約463KB)のデータがあることになります。
ファイル情報ともだいたい一致していますね。
このデータは圧縮されているので、展開してRGB変換していきます。
データの展開
PNGでは画像データはzlib圧縮されているので、 標準パッケージのcompress/zlibを利用して展開を行います。
圧縮されたデータのスライスを受け取り、展開後のスライスを返す関数は次のようになります。
func uncompress(data []byte) ([]byte, error) {
dataBuffer := bytes.NewReader(data)
r, err := zlib.NewReader(dataBuffer)
if err != nil {
return nil, err
}
defer r.Close()
var buffer bytes.Buffer
_, err = buffer.ReadFrom(r)
if err != nil {
return nil, err
}
return buffer.Bytes(), nil
}
この関数をデータ読み込み後に呼び出してみましょう。
func parse(r io.Reader) (err error) {
// ...略...
// 画像データの展開
data, err = uncompress(data)
if err != nil {
return
}
fmt.Println("uncompressed data length:", len(data))
return nil
}
width: 512 height: 512 depth: 8 colorType: 2 interlace: false
chunk: sRGB
chunk: IDAT
chunk: IEND
data length: 473761
uncompressed data length: 786944
Complete
512×512ピクセルで各ピクセル毎にRGBの3色それぞれについて8bitずつ利用するので、786432 bytesが画像のデータです。
展開後のバイト数は786944 bytesとなっており、その差は512 bytesあります。これはスキャンライン毎に付与されるフィルタタイプのデータサイズです。非インタレースPNGでは、上から1行ずつ画像が表示されるので、高さが512の画像は512回スキャンされるため、512 bytes分実際の画像データよりもスライスのサイズが多いということになります。
フィルタタイプの読み込み
フィルタタイプは各スキャンラインの先頭に付与されるので、スキャンラインがどれくらいの長さなのかということを把握しないといけません。非インタレースの場合は、1行の表現に何bytes必要とするかが分かれば良いです。つまり、1ピクセルあたり何bits使用するのかを知る必要があります。これは、カラータイプとビット深度の組み合わせによって異なってきます。
| カラータイプ | PNG画像タイプ | 許可されるビット深度 | bits / pixel |
|---|---|---|---|
| 0 | グレースケール画像 | 1,2,4,8,16 | 1,2,4,8,16 |
| 2 | Trueカラー画像 | 8,16 | 24,48 |
| 3 | インデックスカラー画像 | 1,2,4,8 | 1,2,4,8 |
| 4 | グレースケール画像(透過) | 8,16 | 16,32 |
| 6 | Trueカラー画像(透過) | 8,16 | 32,64 |
1pixelの表示に必要なbit数を返す関数は以下のようになります。
func bitsPerPixel(colorType int, depth int) (int, error) {
switch colorType {
case 0:
return depth, nil
case 2:
return depth * 3, nil
case 3:
return depth, nil
case 4:
return depth * 2, nil
case 6:
return depth * 4, nil
default:
return 0, fmt.Errorf("unknown color type")
}
}
この関数を利用して、全行のフィルタータイプを表示すると次のようになります。
func parse(r io.Reader) (err error) {
// ...略...
// フィルタタイプの読み込み
bitsPerPixel, err := bitsPerPixel(colorType, depth)
if err != nil {
return
}
rowSize := 1 + (bitsPerPixel*width+7)/8
rowData := make([]byte, rowSize)
for h := 0; h < height; h++ {
offset := h*rowSize
rowData = data[offset:offset+rowSize]
filterType := int(rowData[0])
fmt.Println(filterType)
}
return nil
}
width: 512 height: 512 depth: 8 colorType: 2 interlace: false
chunk: sRGB
chunk: IDAT
chunk: IEND
data length: 473761
uncompressed data length: 786944
1
2
2
2
2
3
3
3
.
.
.
国際規格におけるフィルタメソッド0がサポートするフィルタタイプは5つあります。詳細は省きますが、タイプによっては直前のスキャンラインのデータ(非インターレースの場合で言うと1つ上のピクセル)を利用するので、直前のスキャンラインのデータを保持しておく必要があります。なお、直前のスキャンラインがない場合やスキャンラインの先頭で左にピクセルが無い場合はそのバイトは0として扱われます。
フィルタタイプを適応してく処理はちょこっと複雑なので標準パッケージからまるまる拝借します。
少し長くなるので、applyFilterという名前で関数に切り出しました。
func applyFilter(data []byte, width, height, bitsPerPixel, bytesPerPixel int) ([]byte, error) {
rowSize := 1 + (bitsPerPixel*width+7)/8
imageData := make([]byte, width*height*bytesPerPixel)
rowData := make([]byte, rowSize)
prevRowData := make([]byte, rowSize)
for h := 0; h < height; h++ {
offset := h * rowSize
rowData = data[offset : offset+rowSize]
filterType := int(rowData[0])
currentScanData := rowData[1:]
prevScanData := prevRowData[1:]
switch filterType {
case 0:
// No-op.
case 1:
for i := bytesPerPixel; i < len(currentScanData); i++ {
currentScanData[i] += currentScanData[i-bytesPerPixel]
}
case 2:
for i, p := range prevScanData {
currentScanData[i] += p
}
case 3:
for i := 0; i < bytesPerPixel; i++ {
currentScanData[i] += prevScanData[i] / 2
}
for i := bytesPerPixel; i < len(currentScanData); i++ {
currentScanData[i] += uint8((int(currentScanData[i-bytesPerPixel]) + int(prevScanData[i])) / 2)
}
case 4:
var a, b, c, pa, pb, pc int
for i := 0; i < bytesPerPixel; i++ {
a, c = 0, 0
for j := i; j < len(currentScanData); j += bytesPerPixel {
b = int(prevScanData[j])
pa = b - c
pb = a - c
pc = int(math.Abs(float64(pa + pb)))
pa = int(math.Abs(float64(pa)))
pb = int(math.Abs(float64(pb)))
if pa <= pb && pa <= pc {
// No-op.
} else if pb <= pc {
a = b
} else {
a = c
}
a += int(currentScanData[j])
a &= 0xff
currentScanData[j] = uint8(a)
c = b
}
}
default:
return nil, fmt.Errorf("bad filter type")
}
copy(imageData[h*len(currentScanData):], currentScanData)
prevRowData, rowData = rowData, prevRowData
}
return imageData, nil
}
func parse(r io.Reader) (err error) {
// ...略...
// フィルタタイプの適用
bitsPerPixel, err := bitsPerPixel(colorType, depth)
if err != nil {
return
}
bytesPerPixel := (bitsPerPixel + 7) / 8
data, err = applyFilter(data, width, height, bitsPerPixel, bytesPerPixel)
if err != nil {
return
}
fmt.Println("applied filter type data length:", len(data))
return nil
}
width: 512 height: 512 depth: 8 colorType: 2 interlace: false
chunk: sRGB
chunk: IDAT
chunk: IEND
data length: 473761
uncompressed data length: 786944
applied filter type data length: 786432
Complete
フィルタタイプを適用した結果のスライスのサイズが、5125123=786432になっています。ちゃんとフィルタタイプに応じて画像データを構築できていそうです。
ちなみにフィルタタイプを無視して画像を出力するとこの様な画像が得られます。

フィルタタイプを無視するということは、フィルタが適用されている状態、つまりzlibでの圧縮効率を高めるための処理がされている状態と言えると思います。赤緑青白黒といった色で画像が構成されているように見えます。これは、0や255のといった値を多く使うことで圧縮効率が高まるということなのでしょう。(そのように利用するフィルタタイプが選択されている。)
色情報の抽出
出力はRGBAなpngにするとして、これまでに取得した画像データをRGBAにマッピングする必要があります。
マッピングの仕方はカラータイプとビット深度によって変わってくるのですが、サンプル画像はカラータイプが2でビット深度が8であることが分かっているので、その画像タイプだけのマッピングをコードにすると以下のようになります。
func parse(r io.Reader) (img image.Image, err error) {
// ...略...
// 色情報の抽出
nrgba := image.NewNRGBA(image.Rect(0, 0, width, height))
for y := 0; y < height; y++ {
for x := 0; x < width; x++ {
offset := bytesPerPixel*width*y + bytesPerPixel*x
pixel := data[offset : offset+bytesPerPixel]
i := y*nrgba.Stride + x*4
nrgba.Pix[i] = pixel[0] // R
nrgba.Pix[i+1] = pixel[1] // G
nrgba.Pix[i+2] = pixel[2] // B
nrgba.Pix[i+3] = 255 // A
}
}
img = nrgba
return
}
main()でこれを新しいpngで出力するようにします。
func main() {
inputFilePath := filepath.Join("images", "lenna.png")
inputFile, err := os.Open(inputFilePath)
if err != nil {
fmt.Println(err)
return
}
defer inputFile.Close()
img, err := parse(inputFile)
if err != nil {
fmt.Println(err)
return
}
outputFile, err := os.Create("output.png")
if err != nil {
fmt.Println(err)
return
}
defer outputFile.Close()
png.Encode(outputFile, img)
fmt.Println("Complete")
}
これで実行すると、output.pngが生成されます。

心なしか自分で読み込んだレナの方が元のレナよりも美人に見えますね(笑)
インターレースPNGの読み込み
レナの画像の情報をImageMagickのidentifyコマンドで見てみても、インターレースされていないことがわかります。
$ identify -verbose images/lenna.png | grep -i interlace
Interlace: None
png:IHDR.interlace_method: 0 (Not interlaced)
ImageMagickでインターレース化されたPNGを作ります。変換時に余計なチャンクが付加されてしまうので、-define png:exclude-chunkを指定してIHDRとIDATとIENDの3つのチャンクのみが含まれるようにしています。
$ convert images/lenna.png -interlace PNG -define png:exclude-chunk="tEXt,zTXt,gAMA,cHRM,bKGD" images/lenna-interlace.pngpng
$ identify -verbose images/lenna-interlace.png | grep -i interlace
Image: images/lenna-interlace.png
Interlace: PNG
png:IHDR.interlace_method: 1 (Adam7 method)
この画像を先程のプログラムにかけてみます。
width: 512 height: 512 depth: 8 colorType: 2 interlace: true
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IEND
data length: 520902
uncompressed data length: 787392
bad filter type
インターレース画像ではスキャンラインが純粋な行毎ではないので、画像データをフィルタタイプとして読み込んでしまっていてエラーになるようですね。インターレースの場合でも正しく画像を読み込めるようにプログラムを修正します。
Adam7
PNGのインターレースはAdam7というアルゴリズムによって実装されています。画像を8x8ピクセルの画像に分割し、そのそれぞれの画像について、下の画像の番号毎のグループにして、番号順にデータ化します。表示する際は、データの先頭から順に画像を読んでいき、計7回のパスで完璧な画像が表示されるというものです。まだ読み込まれていないパスのピクセルは左上のピクセルで補完します。

例えば512x512ピクセルの画像の場合、上の図の1に該当するピクセルが4096(64x64)個存在します。1ピクセル3 bytesだとすると、12288 bytesとスキャンライン毎のフィルタタイプを表すデータサイズの64 bytesを足した12352 bytesが最初のパスのデータサイズになります。
このパス毎のデータサイズとフィルタタイプを出力するようにプログラムを修正してみます。
PNGのドキュメント( https://www.w3.org/TR/PNG/#13Progressive-display )にインタレース画像表示のプログラムが書かれていますが、go言語の標準パッケージのコードをここでも拝借することにします。
まずは、8x8の画像のどの位置から読み始めるのかなどのパス毎のオフセット値を構造体に持たせます。
type interlaceScan struct {
xFactor, yFactor, xOffset, yOffset int
}
var interlacing = []interlaceScan{
{8, 8, 0, 0},
{8, 8, 4, 0},
{4, 8, 0, 4},
{4, 4, 2, 0},
{2, 4, 0, 2},
{2, 2, 1, 0},
{1, 2, 0, 1},
}
フィルタータイプを適用している部分をインタレースと非インタレースで場合分けしましょう。
// フィルタタイプの適用
bitsPerPixel, err := bitsPerPixel(colorType, depth)
if err != nil {
return
}
bytesPerPixel := (bitsPerPixel + 7) / 8
if interlace {
completeData := make([]byte, width*height*bytesPerPixel)
for pass := 0; pass < 7; pass++ {
p := interlacing[pass]
passWidth := (width - p.xOffset + p.xFactor - 1) / p.xFactor
passHeight := (height - p.yOffset + p.yFactor - 1) / p.yFactor
dataLength := passWidth*passHeight*bytesPerPixel
fmt.Println("passWidth:", passWidth, "passHeight:", passHeight, "size:", dataLength+passHeight, "(", dataLength, "+", passHeight, ")")
}
data = completeData
} else {
data, err = applyFilter(data, width, height, bitsPerPixel, bytesPerPixel)
if err != nil {
return
}
}
fmt.Println("applied filter type data length:", len(data))
width: 512 height: 512 depth: 8 colorType: 2 interlace: true
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IDAT
chunk: IEND
data length: 520902
uncompressed data length: 787392
pw: 64 ph: 64 bytes: 12352 ( 12288 + 64 )
pw: 64 ph: 64 bytes: 12352 ( 12288 + 64 )
pw: 128 ph: 64 bytes: 24640 ( 24576 + 64 )
pw: 128 ph: 128 bytes: 49280 ( 49152 + 128 )
pw: 256 ph: 128 bytes: 98432 ( 98304 + 128 )
pw: 256 ph: 256 bytes: 196864 ( 196608 + 256 )
pw: 512 ph: 256 bytes: 393472 ( 393216 + 256 )
applied filter type data length: 786432
Complete
ちゃんとパス毎に読み込むべきサイズが計算できていそうです。
この状態で出力されるoutput.pngはcompleteDataスライスが0で初期化されているので真っ黒な画像になります。次にデータにフィルタタイプを適用しながらデータを取得してみましょう。
取得したデータは、Adam7の対応するピクセルに再配置します。
データの再配置
// フィルタタイプの適用
bitsPerPixel, err := bitsPerPixel(colorType, depth)
if err != nil {
return
}
bytesPerPixel := (bitsPerPixel + 7) / 8
if interlace {
completeData := make([]byte, width*height*bytesPerPixel)
dataOffset := 0
for pass := 0; pass < 7; pass++ {
p := interlacing[pass]
passWidth := (width - p.xOffset + p.xFactor - 1) / p.xFactor
passHeight := (height - p.yOffset + p.yFactor - 1) / p.yFactor
dataLength := passWidth * passHeight * bytesPerPixel
filterLength := passHeight
fmt.Println("passWidth:", passWidth, "passHeight:", passHeight, "size:", dataLength+filterLength, "(", dataLength, "+", filterLength, ")")
// パスのフィルタ適用後のデータを取得
passData := data[dataOffset : dataOffset+dataLength+filterLength]
passData, err = applyFilter(passData, passWidth, passHeight, bitsPerPixel, bytesPerPixel)
if err != nil {
return
}
dataOffset += dataLength + filterLength
// 対応したピクセルに再配置する
passOffset := 0
for y := 0; y < passHeight; y++ {
for x := 0; x < passWidth; x++ {
position := (y*p.yFactor+p.yOffset)*width + (p.xOffset + x*p.xFactor)
copy(completeData[position*bytesPerPixel:], passData[passOffset:passOffset+bytesPerPixel])
passOffset += bytesPerPixel
}
}
}
data = completeData
} else {
data, err = applyFilter(data, width, height, bitsPerPixel, bytesPerPixel)
if err != nil {
return
}
}
fmt.Println("applied filter type data length:", len(data))
パス毎に取得したデータに対してフィルタタイプを適用し、対応したピクセルに再配置します。
これを行うことにより、正しい画像が生成されていきます。
パス毎に生成される画像は次のようになります。
| pass | 画像 | 補完画像 |
|---|---|---|
| 1 | 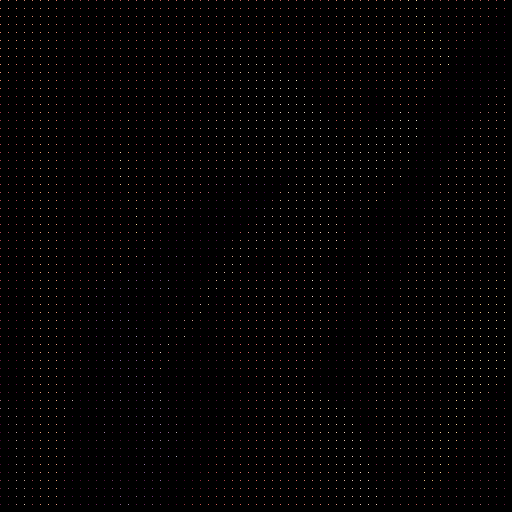 |
 |
| 2 | 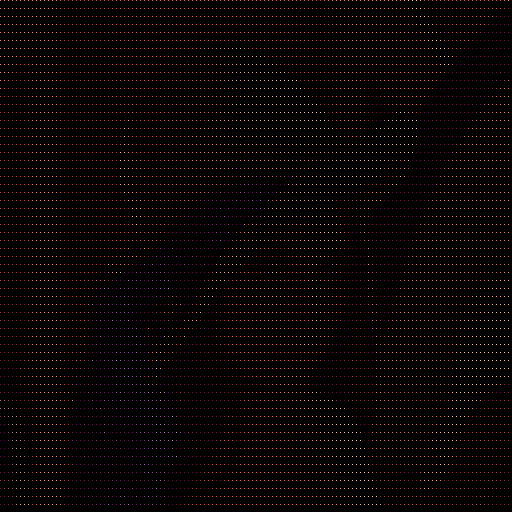 |
 |
| 3 | 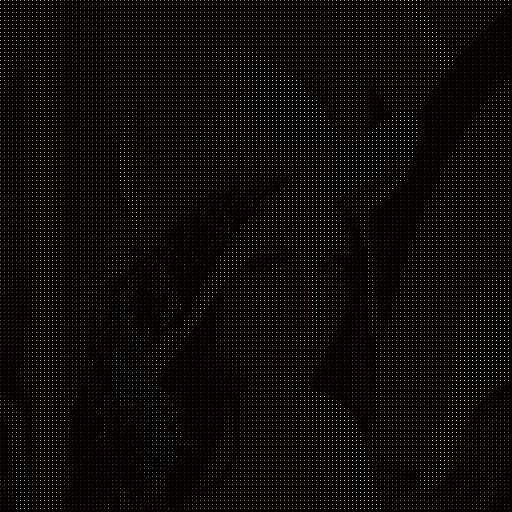 |
 |
| 4 |  |
 |
| 5 |  |
 |
| 6 |  |
 |
| 7 |  |
 |
まだ読み込まれていないピクセルを左上のピクセルで補完するだけで、1つめのパスで大体どんな画像か分かりますね。インターレースすごい。
プログラム全体
GitHubにコードを載せています。
https://github.com/kouheiszk/png-reader/blob/master/main.go