はじめに
PDFから画像ファイルへの変換について調べたので、その備忘録として記載します。
参考
PythonでPDFを画像ファイル(JPEG、PNG)に変換する方法
Install の方法
【Python】PDFと画像の相互変換
pdf2image github
環境と環境構築
試した環境
Win10 Pro 64bit
Anaconda
Python3.7
IDEとしてVScodeを利用しています。
モジュールインストール
pdf2imageとpopplerをインストールする必要があります。
condaを使っているならば、できるだけcondaでインストールすることをお勧めします。
Anaconda仮想環境の作り方(conda-forge、Jupyter notebook)
Condaでインストールするならば
conda install -c conda-forge pdf2image
conda install -c conda-forge poppler
conda-forgeからインストールできます。
(conda-forgeからのインストールが設定されている場合は、-c conda-forge は不要です。)
pipでインストールするならば
pip install pdf2image
pip install poppler
使い方
PythonでPDFを画像ファイル(JPEG、PNG)に変換する方法を参考に使い方を説明します。
題材は、上記のHPの例題にある厚生労働省の毎月勤労統計調査(平成30年9月分結果速報等)の概要 のPDFを利用します。
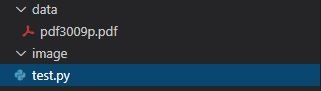
ホルダー構成
dataホルダー(この中にPDFファイルを入れます)
imageホルダー(画像に変換されたものがこのホルダーに入ります。)
test.py(コードが書かれたファイル)
pdf2imageの関数を直接使う方法
test.pyの内容
from pathlib import Path
from pdf2image import convert_from_path
# PDFファイルのパス
pdf_path = Path("./data/pdf3009p.pdf")
# outputのファイルパス
img_path=Path("./image")
# この1文で変換されたjpegファイルが、imageホルダー内に作られます。
convert_from_path(pdf_path, output_folder=img_path,fmt='jpeg',output_file=pdf_path.stem)
convert_from_pathの引数
pdf2image’s documentation
convert_from_path(pdf_path, dpi=200, output_folder=None, first_page=None, last_page=None, fmt='ppm', jpegopt=None, thread_count=1, userpw=None, use_cropbox=False, strict=False, transparent=False, single_file=False, output_file=str(uuid.uuid4()), poppler_path=None, grayscale=False, size=None, paths_only=False)
pdf_pathは、 文字列、 pathlib.Pathのどちらでもよいようです。
今回の例題ではpathlib.Pathにしています。
output_fileではファイル名を指定してます。デフォルトでは乱数(uuid.uuid4())でファイル名が生成されます。
[Python] UUIDを生成するuuid.uuid4()はどうやってUUIDを生成しているのか?
実行結果
imageホルダーの中にpdf3009p0001-01.jpgファイルなどができます。
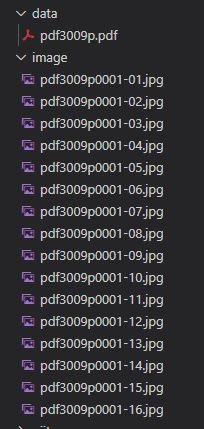
pdf_path.stemで"./data/pdf3009p.pdf"の中のpdf3009pを取ってきます。
これに、0001-01.jpgが追記されています。
Outputファイルの名前を自由に設定する
Outputファイルの名前を自由に設定するには、下記のプログラム中のコメント「画像ファイルを1ぺージずつ保存」のように書くと、任意の名前を付けることができます。
test2.pyの内容
from pathlib import Path
from pdf2image import convert_from_path
def pdf_image(pdf_file,img_path, fmt='jpeg', dpi=200):
#pdf_file、img_pathをPathにする
pdf_path = Path(pdf_file)
image_dir = Path(img_path)
# PDFをImage に変換(pdf2imageの関数)
pages = convert_from_path(pdf_path, dpi)
# 画像ファイルを1ページずつ保存
for i, page in enumerate(pages):
file_name = "{}_{:02d}.{}".format(pdf_path.stem,i+1,fmt)
image_path = image_dir / file_name
page.save(image_path, fmt)
if __name__ == "__main__":
# PDFファイルのパス
pdf_path = Path("./data/pdf3009p.pdf")
img_path=Path("./image")
pdf_image(pdf_file=pdf_path,img_path=img_path, fmt='jpeg', dpi=200)
実行結果
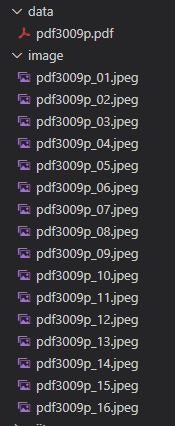
自分で設定した通りの名前で保存することができています。