この記事を読む方へ
英語ができる方は下記の資料の方がオススメです。
TensorFlow w/XLA:TensorFlow, Compiled!
Tensorflowをもっと高速化やメモリの効率化、サイズの最適化をしてみたい方向けです。
XLAの利点は大きく5個あります。
- 実行スピードの高速化
- メモリの効率化
- カスタムされた操作の依存性の除去
- モバイルのフットプリントを除去
- ポータビリティの向上
ただしXLA自体が実験的な状態な点と状況によってはスピードが下がると言われているのでこの点を考慮して実際に性能を測りながら使用する方が良いと思います。
XLAがどのように動作するか
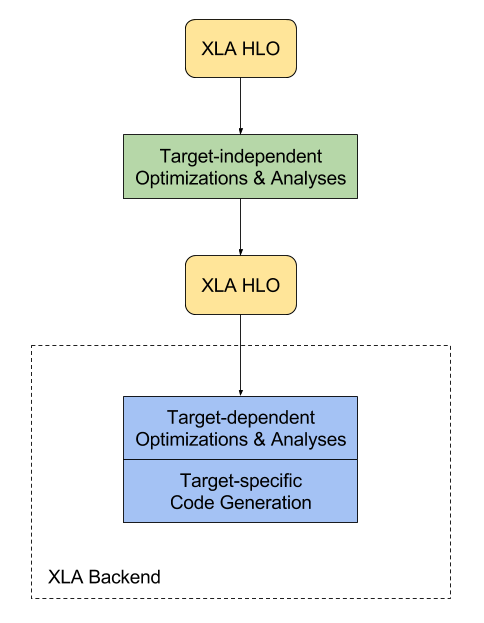
- HLO(High Level Optimizet)によってターゲット環境とは独立して最適化
- 操作の融合
- バッファーの解析
- メモリーの実行時間の配分(計算時間に依存)
- HLOによってターゲットに適した最適化を行う。
- 特にGPUの場合は操作の融合は計算の際のパーティションの区切り方を決める際に有用で操作もしく組み合わせによってライブラリの呼び方が変わる。
- ターゲットに依存したコードの生成を行う。
- LLVMをLow Level IRのために使用して最適化されたコードの生成を行う
なぜ早くなるか
従来は左側の構成のため、マシーンごとに最適化できていませんがXLAを使用することによってマシーンごとに最適化をしています。その最適化にJITを使用しています。
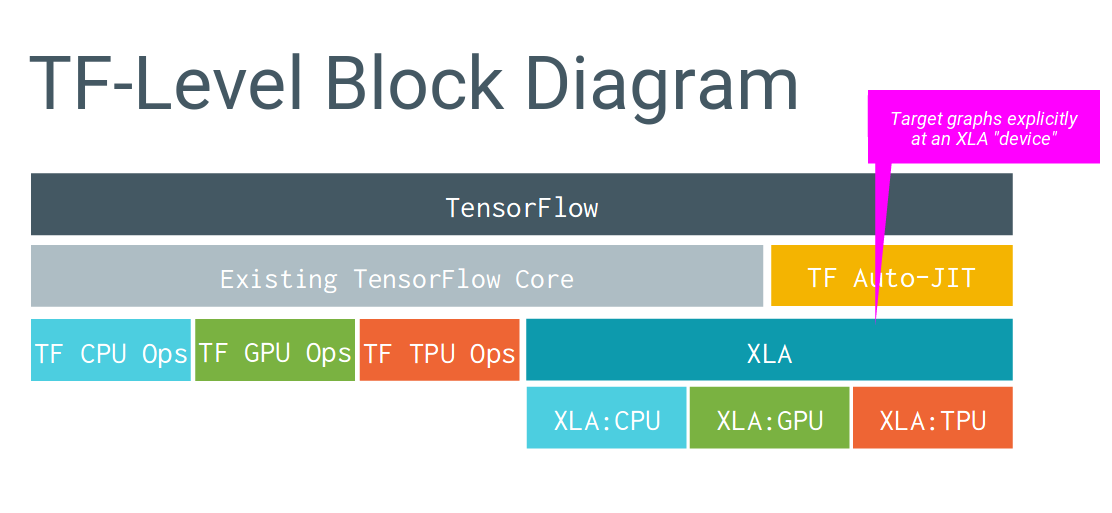
JITとは
Just in Time compilationの略で下記のような特徴があります。
- 実行時にビルド
- コンパイル時のオーバーヘッドが少ない
詳細は下記
実際にどれくらい早くなるか
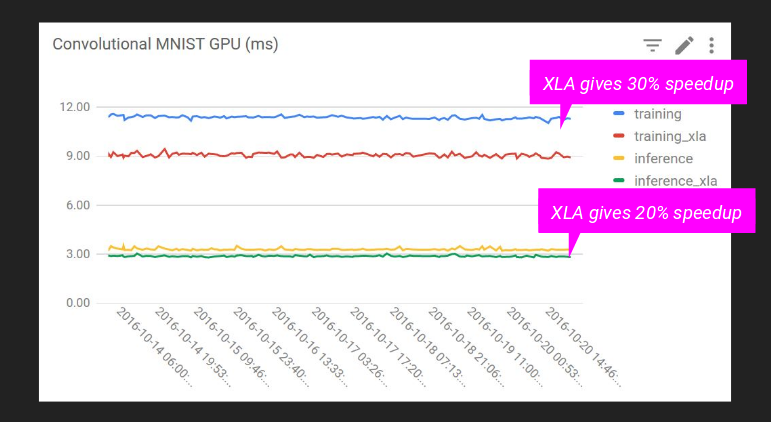
MNIST: GPU
学習速度:30%アップ
予測速度:20%アップ
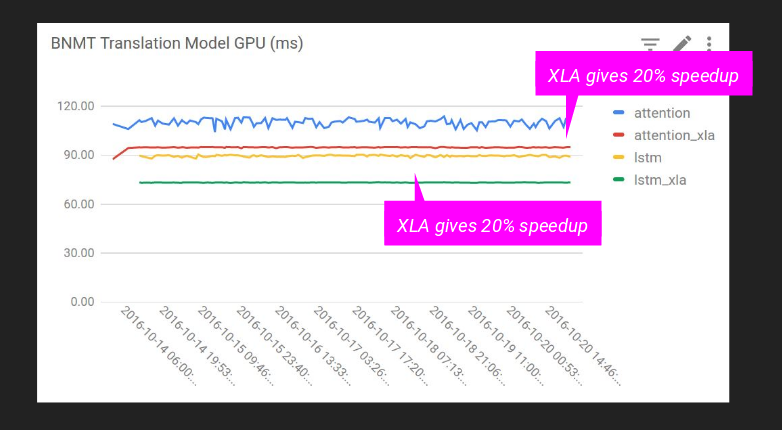
複雑なモデルのケース
Attention: 20%向上
LSTM: 20%向上
実際に使うには
ソースからのビルド
実験段階なのでXLAを有効にするにはソースからビルドする必要があります。
詳しくは下記をご覧下さい。
configureの際に下記の質問にyにして答える必要があります。
Do you wish to build TensorFlow with the XLA just-in-time compiler (experimental)? [y/N]
使用方法
セッション全体での使用
# Config to turn on JIT compilation
config = tf.ConfigProto()
config.graph_options.optimizer_options.global_jit_level = tf.OptimizerOptions.ON_1
sess = tf.Session(config=config)
一部で適用
jit_scope = tf.contrib.compiler.jit.experimental_jit_scope
x = tf.placeholder(np.float32)
with jit_scope():
y = tf.add(x, x) # The "add" will be compiled with XLA.
デバイスを指定して適用
with tf.device("/job:localhost/replica:0/task:0/device:XLA_GPU:0"):
output = tf.add(input1, input2)
Example のコード
参考
XLA Overview
TensorFlow w/XLA:TensorFlow, Compiled!
Using JIT Compilation