はじめに
言語の変化を識別することは、政治学に限らず、社会科学全般において重要な課題である。
政治学において、Rodman(2020)は、Mikolov, Sutskever, Chen, Corrado, and Dean(2013)が開発した word2vec を用い、単語の意味変化を推定する複数の手法を比較している。Rodman(2020)が紹介する手法の多くは、モデルのパラメータ初期値を前期、あるいは全期間のデータを用いて推定したパラメータで置き換えるものであり、本質的には多数のモデルを逐次推定するアプローチである。これに対し、Rudolph and Blei(2018)は階層ベイズ構造を導入し、パラメータの時間的変動を許容しつつ、すべてのパラメータを単一のモデル枠組みの中で同時に推定する手法を提案した。また、単語の意味そのものではないが、多項分布モデルを用いて政党所属議員の発言傾向の差異を識別した Gentzkow, Shapiro, and Taddy(2019)の研究も存在する。
これらの研究が示すように、発言内容やその傾向の経時的変化を捉えることは、社会科学において極めて重要な課題である。
しかし、既存の分析手法の多くは情報工学や統計モデリングに依拠しており、社会科学が重視するミクロ経済学的な合理性や、選好の構造に基づく理論的な裏付けを十分に考慮していない。
さらに、変化を識別する際に時間単位ごとのパラメータを個別に設定する方法が一般的であるが、そのような設計は、推定の計算負荷を増大させるだけでなく、推定結果の格納を困難にするという問題を抱えている。
そこで本記事では、言語の意味変化を選択行動モデルの枠組みで捉え、利用するパラメータ数を減らしながら、一貫した理論的基盤をもつ推定手法を提案する。
単語選択行動のミクロ経済学的な基礎付け
本記事では、言語変化の識別を、与えられた文脈において話者がどの単語を選択するかという最適化行動が、時間の経過とともにどのように変化するかを分析することで操作化する。このとき、単語選択は単なる確率的出現頻度としてではなく、文脈依存的な選好関係に基づく合理的選択行動として定式化される。
選好
具体的には、話者が以下に示す選好関係に基づき、与えられた文脈の中で可算個の候補語の中から使用する単語を選択すると仮定する。
$$
\succeq_{c,t}
$$
ここで、$c$ は文脈(context)、$t$ は時間(time)を表す。
例えば、次の文を考える。
戦争は X の失敗である
このとき、1985年における話者の選好関係は、次のように表されると考えられる。
$$
外交 \succeq_{\text{「戦争, 失敗」},1985} チーズ
$$
すなわち、1985年の話者は「戦争は外交の失敗である」と表現する傾向が、「戦争はチーズの失敗である」と表現する傾向よりも高いとみなすことができる。
次に、話者の選好関係 $\succeq_{c,t}$ には、ミクロ経済学的合理性に基づく制約を課す。
まず完備性(completeness)として、加算個の語彙に属する任意の2単語 $x, y$ について、必ず $x \succeq_{c,t} y$ または $y \succeq_{c,t} x$ が成立すると仮定する。これは、話者が文脈に照らして任意の2単語のどちらがより適切かを常に判断可能であることを意味する。次に反射性(reflexivity)として、任意の単語 $x$ について $x \succeq_{c,t} x$ が成立するものとする。これにより、選好関係の出発点が矛盾なく定義され、自己との比較において少なくとも同等に望ましいとみなすことが保証される。さらに推移性(transitivity)として、任意の単語 $x, y, z$ について、$x \succeq_{c,t} y$ かつ $y \succeq_{c,t} z$ であれば必ず $x \succeq_{c,t} z$ が成立すると仮定する。これにより、文脈における単語選択の「適切さ」の評価が論理的に一貫し、循環的な矛盾(例:$x \succeq_{c,t} y \succeq_{c,t} z \succeq_{c,t} x$)が生じることを防ぐことができる。
効用関数
完備性、反射性、推移性の三条件が満たされ、かつ選択肢が可算であることから、この選好関係 $\succeq_{c,t}$ は効用関数 $U(c,t)$ によって表現可能であることが知られている(Kreps, 2013)。
本記事では、下記の効用関数を提案する。
$$
U(word,c, t) = \alpha_{word} + \sum_{d=1}^{\infty} \left( \beta_{word,d} \cdot \delta_{t,d} \cdot \sum_{i \in c} \gamma_{i,d} \right) + \epsilon
$$
後述するように、$\delta$ の性質により、この無限長の数列の総和は収束し、有限の値を持つことが保証される。
すなわち、文脈 $c$ において単語 $word$ を選択した際の効用は、単語固有の切片 $\alpha$ と、単語ベクトル $\beta$ と文脈ベクトル $\gamma$ の内積に、時間とともに変化する次元ごとの重み $\delta$ を掛け合わせることで表現できる。これらのパラメータ、特に経時変化する次元の重み $\delta$ の生成方法については、後ほど詳細に説明する。単語ベクトルを年ごとの次元の重みで重み付けすることで、単語の意味の変化を経時的に追うことが可能になる。また、観測者が直接把握できないノイズ項 $\epsilon$ は、個々人の信念や経験、あるいはその場の即興的判断により「適切な単語」の評価が微妙に変動する不確実性を表している。ここでは、$\epsilon$ が独立同分布の第1種極値分布に従うと仮定する。ここで、分析者が観測可能な効用関数の部分、すなわち
$$
\alpha_{word} + \sum_{d=1}^{\infty} \left( \beta_{word,d} \cdot \delta_{t,d} \cdot \sum_{i \in c} \gamma_{i,d} \right)
$$
を $\bar{U}(word,c, t)$ と表記する。
この効用関数の構造は、Gopalan, Ruiz, Ranganath and Blei(2014)を参考にしている。
単語選択確率
さて、ここでノイズ項が第1種極値分布に従うと仮定すると、加算個の語彙から単語 $w$ が選択される確率は、次のように表現できることが知られている。
$$
P(w | c, t) = \frac{exp(\bar{U}(w, c, t))}{\sum_{o \in 語彙} exp(\bar{U}(o, c, t))}
$$
しかし、このままではソフトマックス関数の分母の計算のため、日本語の全単語について $\bar{U}(w, c, t)$ を評価する必要があり、膨大な計算リソースを消費してしまう。ここで、ノイズ項が第1種極値分布に従う場合の効用最大化アクターの行動に特有の性質である「無関連な選択肢からの独立性(Independence of Irrelevant Alternatives: IIA)」を利用する。詳細の説明については、Train(2009)を参照されたい。
まず、IIAについて説明する。先に示した「外交」と「チーズ」の例を用いて、文脈 $c$ において「外交」が選択される確率と「チーズ」が選択される確率の比率を考える。
$$
P(外交|c, t) = \frac{exp(\bar{U}(外交, c, t))}{\sum_{o \in 語彙} exp(\bar{U}(o, c, t))}
$$
$$
P(チーズ|c, t) = \frac{exp(\bar{U}(チーズ, c, t))}{\sum_{o \in 語彙} exp(\bar{U}(o, c, t))}
$$
この比率を計算するために、$P(外交|c)$ を $P(チーズ|c)$ で割ると、
$$
\frac{P(外交|c, t)}{P(チーズ|c, t)} = \frac{\frac{exp(\bar{U}(外交, c, t))}{\sum_{o \in 語彙} exp(\bar{U}(o, c, t))}}{\frac{exp(\bar{U}(チーズ, c, t))}{\sum_{o \in 語彙} exp(\bar{U}(o, c, t))}}
$$
となる。ここで、分母の $\sum_{o \in 語彙} exp(\bar{U}(o, c, t))$ は相殺され、整理すると
$$
\frac{P(外交|c, t)}{P(チーズ|c, t)} = \frac{exp(\bar{U}(外交, c, t))}{exp(\bar{U}(チーズ, c, t))} = exp(\bar{U}(外交, c, t) - \bar{U}(チーズ, c, t))
$$
となる。すなわち、文脈内で「戦争は X の失敗である」の X として「外交」と「チーズ」のいずれがより適切かを判断する際、他の単語、たとえば「正義」「地政学」「国際法」「国際政治学現実主義」「コーラ」「ピザ」などは、この比率の計算に全く影響を与えない。これが、離散選択モデルにおけるIIAの特徴である。
尤度関数
詳細は Train(2009, pp. 64–66)を参照されたいが、上述したように、ノイズ項が第1種極値分布に従う場合、効用最大化アクターの行動は IIA の性質を満たすことが知られている。これにより、もともと「外交」対日本語全語彙の選択問題を、分析者がランダムに抽出した一部の単語との「外交」対その一部の単語の選択問題に置き換えることが可能となる。この一部の単語がランダムに選択されていれば、パラメータ推定の一致性は保持される。つまり、日本語でいうと、広辞苑に収録される全ての単語との選択問題を「外交」対「チーズ」の二者択一問題に置き換えても、効用に関する情報は失われないのである。
さらに、ノイズ項が第1種極値分布に従う場合、二者択一の離散選択問題では、選択肢 A の効用を $U_{A}$、選択肢 B の効用を $U_{B}$ としたとき、選択肢 A が選ばれる確率は以下の式で表される(Train 2009, p. 39):
$$
P(A) = \frac{1}{1 + exp(U_{B} - U_{A})}
$$
これを応用すると、コーパスで実際に使用された単語「外交」と、ランダムに抽出されたネガティブサンプルとの二者択一問題において、「外交」が選択される確率は次のように表現できる:
$$
P(外交|c, t) = \frac{1}{1 + exp(\bar{U}(ネガティブサンプル, c, t) - \bar{U}(外交, c, t))}
$$
$$
P(外交|c, t) = \frac{1}{1 + exp(\alpha_{ネガティブサンプル} + \sum_{d=1}^{\infty} \left( \beta_{ネガティブサンプル,d} \cdot \delta_{t,d} \cdot \sum_{i \in c} \gamma_{i,d} \right) - \alpha_{外交} - \sum_{d=1}^{\infty} \left( \beta_{外交,d} \cdot \delta_{t,d} \cdot \sum_{i \in c} \gamma_{i,d} \right) }
$$
$$
P(外交|c, t) = \frac{1}{1 + exp(\alpha_{ネガティブサンプル} - \alpha_{外交} + \sum_{d=1}^{\infty} \left( (\beta_{ネガティブサンプル,d} - \beta_{外交, d}) \cdot \delta_{t,d} \cdot \sum_{i \in c} \gamma_{i,d}\right))}
$$
このように、IIA と第1種極値分布の仮定に基づき二者択一問題に還元することで、膨大な語彙に対する確率計算を効率的かつ理論的に一貫して扱うことが可能となる。本記事ではこれを使用して単語選択の結果を記述する尤度関数を構築する。
事前分布
ここでは、効用関数内のパラメータの事前分布の構築方法について説明する。
単語埋め込みベクトル
ベイズモデルにおける単語ベクトルの事前分布には、従来、Rudolph and Blei(2018)を含む多くの研究で正規分布が用いられてきた。しかし、本研究では、正規分布のみでは十分な柔軟性を提供できるかという疑問に応えるため、正規分布を基底としたディリクレ過程を用いて事前分布を構築している。まず、全体のハイパーパラメータ $\alpha$ をガンマ分布からサンプリングする:
$$
\kappa \sim Gamma(0.001, 0.001)
$$
次に、棒折り過程に基づきディリクレ過程を構築し、無限に存在するクラスタの中でクラスタ $p$ に関するパラメータをサンプリングする:
$$
\pi_{p}\sim Beta(1, \kappa)
$$
$$
p_{p} = \pi_{p} \prod\limits_{l=1}^{p - 1} (1 - \pi_{l})
$$
さらに、クラスタ $p$ の中心ベクトルとばらつきは以下のようにサンプリングされる:
$$
P_{latent,p} \sim Normal(0,1)
$$
$$
P_{\sigma,p} \sim Gamma(0.001, 0.001)
$$
単語 $S$ のベクトルは、まず棒折り過程で構築された無限次元の確率ベクトルをパラメータとするカテゴリ分布からインデックスをサンプリングする:
$$
\eta_{S} \sim Categorical(p)
$$
その後、得られた $\eta_S$ に基づき、ベクトルをサンプリングする:
$$
embedding_{S} \sim Normal(P_{latent, \eta_{S}}, P_{\sigma, \eta_{S}})
$$
この一連のサンプリングプロセスの分布を $G$ と表す。
年ごとの次元の重み
次元重要度(重み)は、自己回帰的な階層棒折り過程によってモデル化される(Teh, Jordan, Beal, Blei, 2006)。まず、初年度の重要度ベクトルを棒折り過程によりサンプリングする。具体的には、まずハイパーパラメータ $\beta$ をサンプリングする:
$$
\chi \sim Gamma(0.001, 0.001)
$$
次に、棒折り過程により初年度の重要度ベクトルを求める:
$$
\omega_{1,d}\sim Beta(1, \chi)
$$
$$
\delta_{1,d} = \omega_{1,d} \prod\limits_{l=1}^{d - 1} (1 - \omega_{1,l})
$$
これを $d=1$ から $d=\infty$ まで繰り返す。
経時的変化の度合いを示すパラメータは以下のようにサンプリングされる:
$$
\theta \sim Gamma(0.001, 0.001)
$$
次に、年 $Y$ の重要度ベクトルは、前年 $Y-1$ の重要度ベクトルを事前分布として用いる階層棒折り過程によりサンプリングされる:
$$
\omega_{Y,d} \sim Beta\left( \theta \omega_{Y-1,d}, \theta \left(1 - \sum_{l=1}^{d} \omega_{Y-1,l} \right) \right)
$$
$$
\delta_{Y,d} = \omega_{Y,d} \prod\limits_{l=1}^{d - 1} (1 - \omega_{Y,l})
$$
階層化の理由は、前年の次元重要度ベクトルを事前分布として組み込むことで、次元間の重なりを保持し、経時的変化を正確に捉えるためである。
年 $Y$ の次元重要度ベクトルの $d$ 番目の期待値は次のように表される:
$$
\mathbb{E}[\delta_{Y,d}] = \frac{1}{1 + \chi} \left( \frac{\chi}{1 + \chi} \right)^{d-1}.
$$
$\chi$ はガンマ分布から生成されるため、0より大きい実数であり、$\frac{\chi}{1+\chi}$ は 0 から 1 の間の実数となる。したがって、年 $Y$ の次元重要度ベクトルは、次元が増加するにつれて指数関数的に 0 へ収束する性質を持つことが分かる。
このように、ノンパラメトリックベイズの代表的構造である棒折り過程を用いることで、無限次元の重要度ベクトルであっても収束性と数学的整合性が保たれるのみならず、急速にゼロに収束する特性は次元選択機能としても寄与する。
詳細は筆者の別論文の Appendix(Wu, 2025)を参照されたい:
Stan コード
実装用のStanコードは下記の通りである。
functions {
vector stick_breaking(vector breaks){
int length = size(breaks) + 1;
vector[length] result;
result[1] = breaks[1];
real summed = result[1];
for (d in 2:(length - 1)) {
result[d] = (1 - summed) * breaks[d];
summed += result[d];
}
result[length] = 1 - summed;
return result;
}
real weighted_inner_product(
vector vec_a, vector vec_b, vector weight
){
vector[size(vec_a)] result_record;
for (i in 1:size(vec_a)){
result_record[i] = vec_a[i] * vec_b[i] * weight[i];
}
return sum(result_record);
}
real entropy(
vector distribution, real threshold
){
vector[size(distribution)] result;
for (i in 1:size(distribution)){
if (distribution[i] < threshold){
result[i] = 0.0;
} else {
result[i] = distribution[i] * log(distribution[i]);
}
}
return -sum(result);
}
real embedding_prior_lpmf(
array[] int word_seq,
int start, int end,
int group_type,
array[] vector word_embedding,
vector group,
array[] vector group_embedding, vector group_sigma
){
vector[end - start + 1] lambda;
int count = 1;
for (w in start:end){
vector[group_type] case_vector;
for (g in 1:group_type){
case_vector[g] = log(group[g]) + normal_lpdf(word_embedding[w] | group_embedding[g], group_sigma[g]);
}
lambda[count] = log_sum_exp(case_vector);
count += 1;
}
return sum(lambda);
}
real partial_sum_lpmf(
array[] int word,
int start, int end,
array[] int neg_word,
array[] int year,
array[] int word_lead_1,
array[] int word_lag_1,
array[] int word_lead_2,
array[] int word_lag_2,
array[] int word_lead_3,
array[] int word_lag_3,
array[] vector dimension_year,
vector word_intercept,
array[] vector word_embedding,
array[] vector word_context
){
vector[end - start + 1] log_likelihood;
int count = 1;
for (i in start:end){
log_likelihood[count] = - log1p(
exp(
word_intercept[neg_word[i]] - word_intercept[word[count]] +
(dimension_year[year[i]] .* (
word_context[word_lag_1[i]] + word_context[word_lead_1[i]] +
word_context[word_lag_2[i]] + word_context[word_lead_2[i]] +
word_context[word_lag_3[i]] + word_context[word_lead_3[i]]
)) '* (word_embedding[neg_word[i]] - word_embedding[word[count]])
)
);
count += 1;
}
return sum(log_likelihood);
}
}
data {
int<lower=1> word_type;
int<lower=1> year_type;
int<lower=1> group_type;
int<lower=1> dimension_type;
array[word_type] int<lower=1,upper=word_type> word_seq;
int<lower=1> N;
array[N] int<lower=1,upper=word_type> word;
array[N] int<lower=1,upper=word_type> neg_word;
array[N] int<lower=1,upper=year_type> year;
array[N] int<lower=1,upper=word_type> word_lead_1;
array[N] int<lower=1,upper=word_type> word_lag_1;
array[N] int<lower=1,upper=word_type> word_lead_2;
array[N] int<lower=1,upper=word_type> word_lag_2;
array[N] int<lower=1,upper=word_type> word_lead_3;
array[N] int<lower=1,upper=word_type> word_lag_3;
}
parameters{
real<lower=0> dimension_global_alpha;
real<lower=0> dimension_across_year_alpha;
array[year_type] vector<lower=0, upper=1>[dimension_type - 1] dimension_year_breaks;
real<lower=0> group_alpha; // ディリクレ過程の全体のパラメータ
vector<lower=0, upper=1>[group_type - 1] group_breaks; // ディリクレ過程のstick-breaking representationのためのパラメータ
vector<lower=0>[group_type] group_sigma;
array[group_type] vector[dimension_type] group_embedding;
vector[word_type] word_intercept_unnormalized;
array[word_type] vector[dimension_type] word_embedding;
array[word_type] vector[dimension_type] word_context;
}
transformed parameters {
array[year_type] simplex[dimension_type] dimension_year;
simplex[group_type] group;
vector[word_type] word_intercept;
for (t in 1:year_type){
dimension_year[t] = stick_breaking(dimension_year_breaks[t]);
}
group = stick_breaking(group_breaks);
word_intercept = word_intercept_unnormalized - mean(word_intercept_unnormalized);
}
model{
dimension_global_alpha ~ gamma(0.001, 0.001);
dimension_year_breaks[1] ~ beta(1, dimension_global_alpha);
dimension_across_year_alpha ~ gamma(0.001, 0.001);
for (t in 2:year_type){
for (d in 1:(dimension_type - 1)){
dimension_year_breaks[t, d] ~ beta(dimension_across_year_alpha * dimension_year[t - 1, d], dimension_across_year_alpha * (1 - sum(dimension_year[t - 1, 1:d])));
}
}
group_alpha ~ gamma(0.001, 0.001);
group_breaks ~ beta(1, group_alpha);
group_sigma ~ gamma(0.001, 0.001);
word_intercept ~ normal(0, 10);
for (g in 1:group_type){
group_embedding[g] ~ normal(0, 1);
}
int grainsize = 1;
target += reduce_sum(
embedding_prior_lupmf, word_seq, grainsize,
group_type,
word_embedding,
group,
group_embedding, group_sigma
);
target += reduce_sum(
partial_sum_lupmf, word, grainsize,
neg_word,
year,
word_lead_1,
word_lag_1,
word_lead_2,
word_lag_2,
word_lead_3,
word_lag_3,
dimension_year,
word_intercept,
word_embedding,
word_context
);
}
また、事後分布から quantities of interest を抽出するためのコードは以下の通りである。コード内では、実際に選択された単語の効用 $\bar{U}(\text{実際に選択された単語}, c, t)$ とネガティブサンプルの効用 $\bar{U}(\text{ネガティブサンプル}, c, t)$ を比較し、前者が後者より高い場合の割合(正答率)を計算する処理も含まれている。
functions {
vector stick_breaking(vector breaks){
int length = size(breaks) + 1;
vector[length] result;
result[1] = breaks[1];
real summed = result[1];
for (d in 2:(length - 1)) {
result[d] = (1 - summed) * breaks[d];
summed += result[d];
}
result[length] = 1 - summed;
return result;
}
real weighted_inner_product(
vector vec_a, vector vec_b, vector weight
){
vector[size(vec_a)] result_record;
for (i in 1:size(vec_a)){
result_record[i] = vec_a[i] * vec_b[i] * weight[i];
}
return sum(result_record);
}
real entropy(
vector distribution, real threshold
){
vector[size(distribution)] result;
for (i in 1:size(distribution)){
if (distribution[i] < threshold){
result[i] = 0.0;
} else {
result[i] = distribution[i] * log(distribution[i]);
}
}
return -sum(result);
}
real embedding_prior_lpmf(
array[] int word_seq,
int start, int end,
int group_type,
array[] vector word_embedding,
vector group,
array[] vector group_embedding, vector group_sigma
){
vector[end - start + 1] lambda;
int count = 1;
for (w in start:end){
vector[group_type] case_vector;
for (g in 1:group_type){
case_vector[g] = log(group[g]) + normal_lpdf(word_embedding[w] | group_embedding[g], group_sigma[g]);
}
lambda[count] = log_sum_exp(case_vector);
count += 1;
}
return sum(lambda);
}
real partial_sum_lpmf(
array[] int word,
int start, int end,
array[] int neg_word,
array[] int year,
array[] int word_lead_1,
array[] int word_lag_1,
array[] int word_lead_2,
array[] int word_lag_2,
array[] int word_lead_3,
array[] int word_lag_3,
array[] vector dimension_year,
vector word_intercept,
array[] vector word_embedding,
array[] vector word_context
){
vector[end - start + 1] log_likelihood;
int count = 1;
for (i in start:end){
log_likelihood[count] = - log1p(
exp(
word_intercept[neg_word[i]] - word_intercept[word[count]] +
(dimension_year[year[i]] .* (
word_context[word_lag_1[i]] + word_context[word_lead_1[i]] +
word_context[word_lag_2[i]] + word_context[word_lead_2[i]] +
word_context[word_lag_3[i]] + word_context[word_lead_3[i]]
)) '* (word_embedding[neg_word[i]] - word_embedding[word[count]])
)
);
count += 1;
}
return sum(log_likelihood);
}
}
data {
int<lower=1> word_type;
int<lower=1> year_type;
int<lower=1> group_type;
int<lower=1> dimension_type;
array[word_type] int<lower=1,upper=word_type> word_seq;
int<lower=0> val_N;
array[val_N] int<lower=1,upper=word_type> val_word;
array[val_N] int<lower=1,upper=word_type> val_neg_word;
array[val_N] int<lower=1,upper=year_type> val_year;
array[val_N] int<lower=1,upper=word_type> val_word_lead_1;
array[val_N] int<lower=1,upper=word_type> val_word_lag_1;
array[val_N] int<lower=1,upper=word_type> val_word_lead_2;
array[val_N] int<lower=1,upper=word_type> val_word_lag_2;
array[val_N] int<lower=1,upper=word_type> val_word_lead_3;
array[val_N] int<lower=1,upper=word_type> val_word_lag_3;
}
parameters{
real<lower=0> dimension_global_alpha;
real<lower=0> dimension_across_year_alpha;
array[year_type] vector<lower=0, upper=1>[dimension_type - 1] dimension_year_breaks;
real<lower=0> group_alpha; // ディリクレ過程の全体のパラメータ
vector<lower=0, upper=1>[group_type - 1] group_breaks; // ディリクレ過程のstick-breaking representationのためのパラメータ
vector<lower=0>[group_type] group_sigma;
array[group_type] vector[dimension_type] group_embedding;
vector[word_type] word_intercept_unnormalized;
array[word_type] vector[dimension_type] word_embedding;
array[word_type] vector[dimension_type] word_context;
}
transformed parameters {
array[year_type] simplex[dimension_type] dimension_year;
simplex[group_type] group;
vector[word_type] word_intercept;
for (t in 1:year_type){
dimension_year[t] = stick_breaking(dimension_year_breaks[t]);
}
group = stick_breaking(group_breaks);
word_intercept = word_intercept_unnormalized - mean(word_intercept_unnormalized);
}
generated quantities {
array[dimension_type] real drawn_G;
array[word_type] vector[group_type] estimated_eta;
vector[year_type] entropy_per_year;
real accuracy;
{
int sampled_group = categorical_rng(group);
drawn_G = normal_rng(group_embedding[sampled_group], group_sigma[sampled_group]);
for (w in 1:word_type){
vector[group_type] case_vector;
for (g in 1:group_type){
case_vector[g] = log(group[g]) + normal_lpdf(word_embedding[w] | group_embedding[g], group_sigma[g]);
}
estimated_eta[w] = softmax(case_vector);
}
for (i in 1:year_type){
entropy_per_year[i] = entropy(dimension_year[i], 0.00001);
}
array[val_N] int predict;
for (i in 1:val_N){
real utility_positive = word_intercept[val_word[i]] +
(dimension_year[val_year[i]] .* (
word_context[val_word_lag_1[i]] + word_context[val_word_lead_1[i]] +
word_context[val_word_lag_2[i]] + word_context[val_word_lead_2[i]] +
word_context[val_word_lag_3[i]] + word_context[val_word_lead_3[i]]
)
) '* (word_embedding[val_word[i]]);
real utility_negative = word_intercept[val_neg_word[i]] +
(dimension_year[val_year[i]] .* (
word_context[val_word_lag_1[i]] + word_context[val_word_lead_1[i]] +
word_context[val_word_lag_2[i]] + word_context[val_word_lead_2[i]] +
word_context[val_word_lag_3[i]] + word_context[val_word_lead_3[i]]
)
) '* (word_embedding[val_neg_word[i]]);
if (utility_positive > utility_negative){
predict[i] = 1;
} else {
predict[i] = 0;
}
}
accuracy = mean(predict);
}
}
前処理とモデル推定
提案手法の妥当性と実用性を示すため、本記事は、衆議院外務委員会の議事録データをもとに、単語の意味の変化を捉えることを試みる。
`%>%` <- magrittr::`%>%`
mecabbing <- function(text){
text |>
stringr::str_replace_all("[^一-龠ぁ-んーァ-ヶーa-zA-Z]", " ") |>
RMeCab::RMeCabC(1) |>
unlist() %>%
.[which(names(.) == "名詞")] |>
stringr::str_c(collapse = " ")
}
# データのダウンロード
full_corp <- quanteda.corpora::download("data_corpus_foreignaffairscommittee") |>
quanteda::corpus_subset(speaker != "")
# 肩書きを含む人名の抽出
capacity_full <- full_corp |>
stringr::str_sub(1, 20) |>
stringr::str_replace_all("\\s+.+|\n", "") |> # 冒頭の名前部分の取り出し
stringr::str_replace( "^.+[参事|政府特別補佐人|内閣官房|会計検査院|最高裁判所長官代理者|主査|議員|副?大臣|副?議長|委員|参考人|分科員|公述人|]君((.+))?$", "\\1")
# 肩書きの抽出
capacity <- full_corp |>
stringr::str_sub(1, 20) |>
stringr::str_replace_all("\\s+.+|\n", "") |> # 冒頭の名前部分の取り出し
stringr::str_replace( "^.+?(参事|政府特別補佐人|内閣官房|会計検査院|最高裁判所長官代理者|主査|議員|副?大臣|副?議長|委員|参考人|分科員|公述人|君((.+))?$)", "\\1") |> # 冒頭の○から,名前部分までを消去
stringr::str_replace("(.+)", "") |>
stringr::str_replace("^○.+", "Other")
# 年の抽出
record_year <- quanteda::docvars(full_corp, "date") |>
lubridate::year() |>
as.numeric()
# 並列処理の準備
future::plan(future::multisession, workers = 16)
sub_corp_df <- tibble::tibble(
capacity_full = capacity_full,
capacity = capacity,
record_year = record_year,
# テキストデータ形式をquantedaからbase Rのcharacter型に変換する
text = full_corp |>
as.list() |>
unlist()
) |>
dplyr::filter(dplyr::between(record_year, 1950, 2017)) |>
dplyr::filter(capacity %in% c("委員", "大臣", "副大臣")) |>
# 発言の冒頭の名前と肩書きを削除
dplyr::mutate(
text = stringr::str_remove_all(text, stringr::fixed(capacity_full))
) |>
dplyr::mutate(text_mecabbed = furrr::future_map_chr(text, ~ mecabbing(.x), .progress = TRUE)) |>
dplyr::mutate(
text_id = dplyr::row_number()
)
sub_corp_use_tokens <- sub_corp_df |>
dplyr::pull(text_mecabbed) |>
quanteda::phrase() |>
quanteda::tokens() |>
quanteda::tokens_remove("の") |>
quanteda::dfm() |>
quanteda::dfm_trim(min_termfreq = 100, max_termfreq = 200000) |>
colnames()
word_master <- tibble::tibble(
word = sub_corp_use_tokens
) |>
dplyr::arrange(word) |>
dplyr::mutate(
word_id = dplyr::row_number()
)
year_master <- sub_corp_df |>
dplyr::select(record_year) |>
dplyr::distinct() |>
dplyr::arrange(record_year) |>
dplyr::mutate(
year_id = dplyr::row_number()
)
set.seed(12345)
sub_corp_long_df_lag_correct_and_neg <- sub_corp_df |>
dplyr::select(text_id, record_year, text_mecabbed) |>
dplyr::mutate(
word = text_mecabbed |>
quanteda::phrase() |>
quanteda::tokens() |>
quanteda::tokens_remove("の") |>
as.list()
) |>
tidyr::unnest_longer(word) |>
dplyr::filter(word %in% word_master$word) |>
dplyr::select(text_id, word, record_year) |>
dplyr::left_join(word_master, by = "word") |>
dplyr::left_join(year_master, by = "record_year") |>
dplyr::group_by(text_id) |>
purrr::reduce(
1:3,
\(this_df, i){
this_df |>
dplyr::mutate(
!!stringr::str_c("lag_", i) := dplyr::lag(word_id, i),
!!stringr::str_c("lead_", i) := dplyr::lead(word_id, i),
)
},
.init = _
) |>
dplyr::ungroup() |>
tidyr::drop_na() |>
dplyr::mutate(
neg_word_id = sample(word_master$word_id, dplyr::n(), replace = TRUE)
) |>
purrr::reduce(
1:1000, # 流石に1000回繰り返してもたまたま被るやつがあるとは思えない
\(this_df, i){
if (sum(this_df$word_id == this_df$neg_word_id) == 0){
return(purrr::done(this_df))
} else {
done_df <- this_df |>
dplyr::filter(word_id != neg_word_id)
not_done_df <- this_df |>
dplyr::filter(word_id == neg_word_id) |>
dplyr::mutate(
neg_word_id = sample(word_master$word_id, dplyr::n(), replace = TRUE)
)
return(dplyr::bind_rows(done_df, not_done_df))
}
},
.init = _
)
set.seed(12345)
val_id <- sample(seq_len(nrow(sub_corp_long_df_lag_correct_and_neg)), 10000)
data_list <- list(
word_type = nrow(word_master),
year_type = nrow(year_master),
group_type = 10,
dimension_type = 20,
word_seq = 1:nrow(word_master),
N = nrow(sub_corp_long_df_lag_correct_and_neg[-val_id,]),
word = sub_corp_long_df_lag_correct_and_neg$word_id[-val_id],
neg_word = sub_corp_long_df_lag_correct_and_neg$neg_word_id[-val_id],
year = sub_corp_long_df_lag_correct_and_neg$year_id[-val_id],
word_lead_1 = sub_corp_long_df_lag_correct_and_neg$lead_1[-val_id],
word_lag_1 = sub_corp_long_df_lag_correct_and_neg$lag_1[-val_id],
word_lead_2 = sub_corp_long_df_lag_correct_and_neg$lead_2[-val_id],
word_lag_2 = sub_corp_long_df_lag_correct_and_neg$lag_2[-val_id],
word_lead_3 = sub_corp_long_df_lag_correct_and_neg$lead_3[-val_id],
word_lag_3 = sub_corp_long_df_lag_correct_and_neg$lag_3[-val_id]
)
学習データの量を確認しよう。
> nrow(sub_corp_long_df_lag_correct_and_neg[-val_id,])
[1] 10767739
要するに、モデルは 1000 万の単語選択結果から、$\succeq_{c,t}$ を実数で表現する $\bar{U}(word,c, t)$ のパラメータを推定する。
次に、モデルをコンパイルする。
m_dw2v_init <- cmdstanr::cmdstan_model("estimation/dynamic_word2vec.stan",
cpp_options = list(
stan_threads = TRUE
)
)
本記事では、変分推論によりモデルの推定を行う(Kucukelbir, Tran, Ranganath, Gelman, and Blei, 2017)。変分推論は、MCMC 法と比較すると事後分布の分散を過小評価する傾向があることが知られている(Blei, Kucukelbir, McAuliffe, 2017)が、その計算効率の高さから、政治学を含む大規模データに基づくベイズモデルの推定に広く用いられている(Grimmer, 2011)。
> m_dw2v_estimate <- m_dw2v_init$variational(
seed = 12345,
threads = 6,
data = data_list
)
------------------------------------------------------------
EXPERIMENTAL ALGORITHM:
This procedure has not been thoroughly tested and may be unstable
or buggy. The interface is subject to change.
------------------------------------------------------------
Gradient evaluation took 11.6341 seconds
1000 transitions using 10 leapfrog steps per transition would take 116341 seconds.
Adjust your expectations accordingly!
Begin eta adaptation.
Iteration: 1 / 250 [ 0%] (Adaptation)
Iteration: 50 / 250 [ 20%] (Adaptation)
Iteration: 100 / 250 [ 40%] (Adaptation)
Iteration: 150 / 250 [ 60%] (Adaptation)
Iteration: 200 / 250 [ 80%] (Adaptation)
Iteration: 250 / 250 [100%] (Adaptation)
Success! Found best value [eta = 0.1].
Begin stochastic gradient ascent.
iter ELBO delta_ELBO_mean delta_ELBO_med notes
100 -3374462.276 1.000 1.000
200 -2578600.876 0.654 1.000
300 -2182234.497 0.497 0.309
400 -1911131.752 0.408 0.309
500 -1738934.964 0.346 0.182
600 -1622348.440 0.301 0.182
700 -1538120.081 0.265 0.142
800 -1473527.050 0.238 0.142
900 -1422665.778 0.215 0.099
1000 -1381131.493 0.197 0.099
1100 -1346455.704 0.099 0.072
1200 -1317069.306 0.071 0.055
1300 -1291420.038 0.055 0.044
1400 -1269110.330 0.042 0.036
1500 -1248838.512 0.034 0.030
1600 -1230835.813 0.028 0.026
1700 -1214195.078 0.024 0.022
1800 -1199007.181 0.021 0.020
1900 -1184984.101 0.018 0.018
2000 -1171860.314 0.017 0.016
2100 -1159619.722 0.015 0.015
2200 -1148002.357 0.014 0.014
2300 -1137084.001 0.013 0.013
2400 -1126703.656 0.012 0.012
2500 -1116897.459 0.011 0.011
2600 -1107440.546 0.011 0.011
2700 -1098377.655 0.010 0.010
2800 -1089718.428 0.010 0.010 MEAN ELBO CONVERGED MEDIAN ELBO CONVERGED
Drawing a sample of size 1000 from the approximate posterior...
COMPLETED.
Finished in 36559.4 seconds.
最後に、quantities of interest の事後分布も併せて抽出する。
qoi_dw2v_init <- cmdstanr::cmdstan_model("estimation/dynamic_word2vec_qoi.stan")
qoi_dw2v_estimate <- qoi_dw2v_init$generate_quantities(
seed = 12345,
fitted_params = m_dw2v_estimate,
data = list(
word_type = nrow(word_master),
year_type = nrow(year_master),
group_type = 10,
dimension_type = 20,
word_seq = 1:nrow(word_master),
val_N = nrow(sub_corp_long_df_lag_correct_and_neg[val_id,]),
val_word = sub_corp_long_df_lag_correct_and_neg$word_id[val_id],
val_neg_word = sub_corp_long_df_lag_correct_and_neg$neg_word_id[val_id],
val_year = sub_corp_long_df_lag_correct_and_neg$year_id[val_id],
val_word_lead_1 = sub_corp_long_df_lag_correct_and_neg$lead_1[val_id],
val_word_lag_1 = sub_corp_long_df_lag_correct_and_neg$lag_1[val_id],
val_word_lead_2 = sub_corp_long_df_lag_correct_and_neg$lead_2[val_id],
val_word_lag_2 = sub_corp_long_df_lag_correct_and_neg$lag_2[val_id],
val_word_lead_3 = sub_corp_long_df_lag_correct_and_neg$lead_3[val_id],
val_word_lag_3 = sub_corp_long_df_lag_correct_and_neg$lag_3[val_id]
)
)
qoi_dw2v_summary <- qoi_dw2v_estimate$summary()
推定結果の可視化
予測精度
まず、10000 件の検証データで、実際に選択された単語の効用 $\bar{U}(\text{実際に選択された単語}, c, t)$ とネガティブサンプルの効用 $\bar{U}(\text{ネガティブサンプル}, c, t)$ を比較し、前者が後者より高い場合の割合(正答率)の事後分布を確認しよう。
qoi_dw2v_estimate$draws("accuracy") |>
posterior::as_draws_df() |>
as.data.frame() |>
tibble::tibble() |>
ggplot2::ggplot() +
ggplot2::geom_density(ggplot2::aes(x = accuracy), fill = ggplot2::alpha("blue", 0.3)) +
ggplot2::labs(
title = "Posterior Distribution of Accuracy on 10000 Test Sample Comparisons"
)

正答率は94%を統計的に有意に上回っており、完璧ではないものの、本モデルが選好を表す効用関数のノイズ項以外の構造を十分に推定できていることを示唆している。
単語ベクトル
次に、推定された単語ベクトル $\beta$ が本当に意味を捉えていることをより強く示すため、t-SNE図(Maaten and Hinton, 2008)で $\beta$ を二次元に圧縮してから可視化する。
set.seed(12345)
tsne_df <- m_dw2v_summary |>
dplyr::filter(stringr::str_detect(variable, "^word_embedding\\[")) |>
dplyr::pull(median) |>
matrix(ncol = 20) |>
rbind(qoi_dw2v_estimate$draws("drawn_G") |>
posterior::as_draws_df() |>
tibble::as_tibble() |>
dplyr::mutate(
dplyr::across(
dplyr::everything(),
~ as.numeric(.)
)
) |>
dplyr::select(dplyr::starts_with("drawn_G")) |>
as.matrix()
) |>
Rtsne::Rtsne() |>
purrr::pluck("Y") |>
tibble::as_tibble() |>
dplyr::bind_cols(
type = c(rep("word", nrow(word_master)), rep("sample", 1000)),
name = c(word_master$word, rep("sample", 1000)),
)
g_tsne <- tsne_df |>
dplyr::filter(type == "word") |>
ggplot2::ggplot() +
ggplot2::geom_text(ggplot2::aes(x = V1, y = V2, label = name), color = ggplot2::alpha("blue", 0.5)) +
ggplot2::geom_density_2d(data = tsne_df |>
dplyr::filter(type == "sample"),
ggplot2::aes(x = V1, y = V2),
color = ggplot2::alpha("black", 0.2),
show.legend = FALSE
)
plotly::ggplotly(g_tsne)
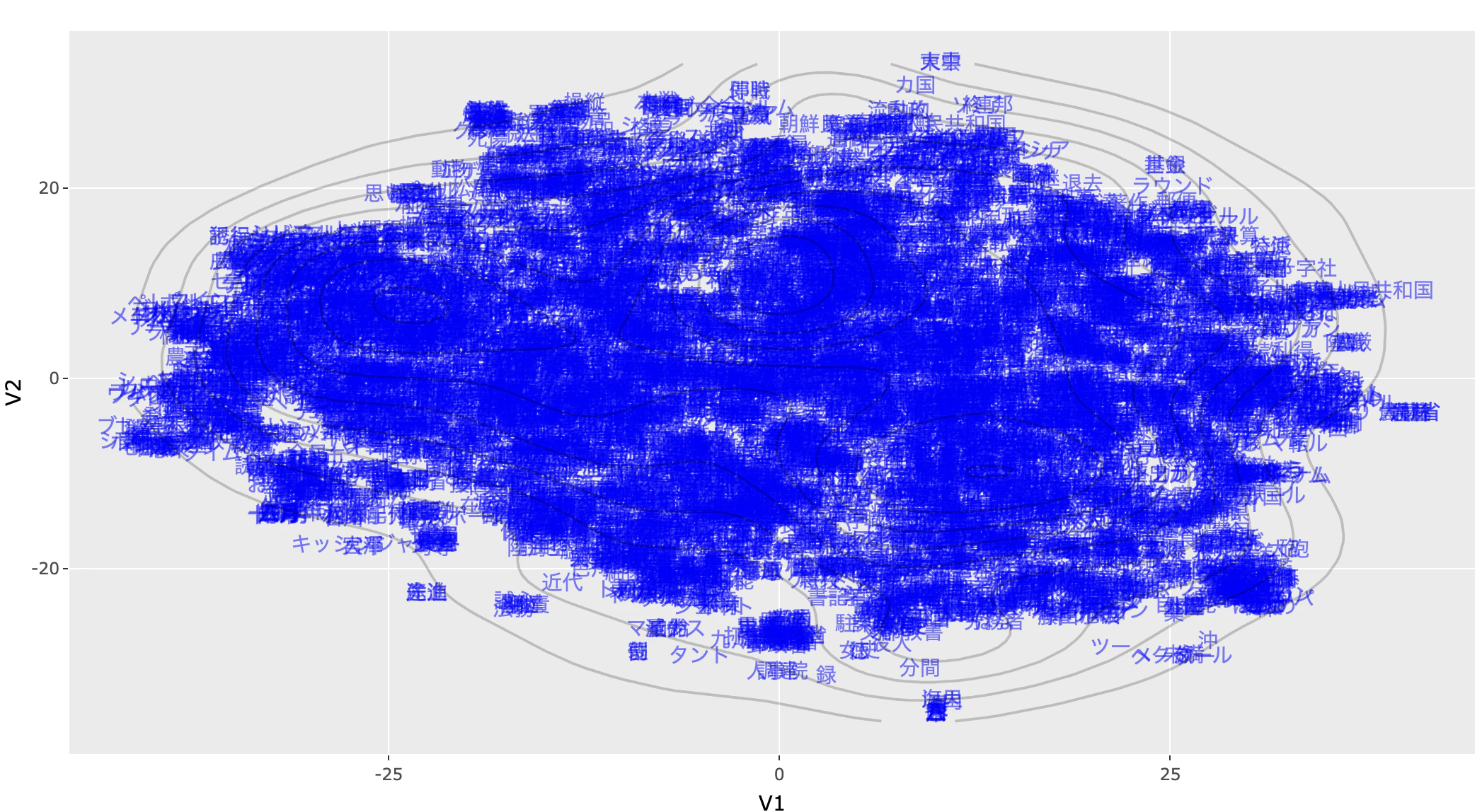
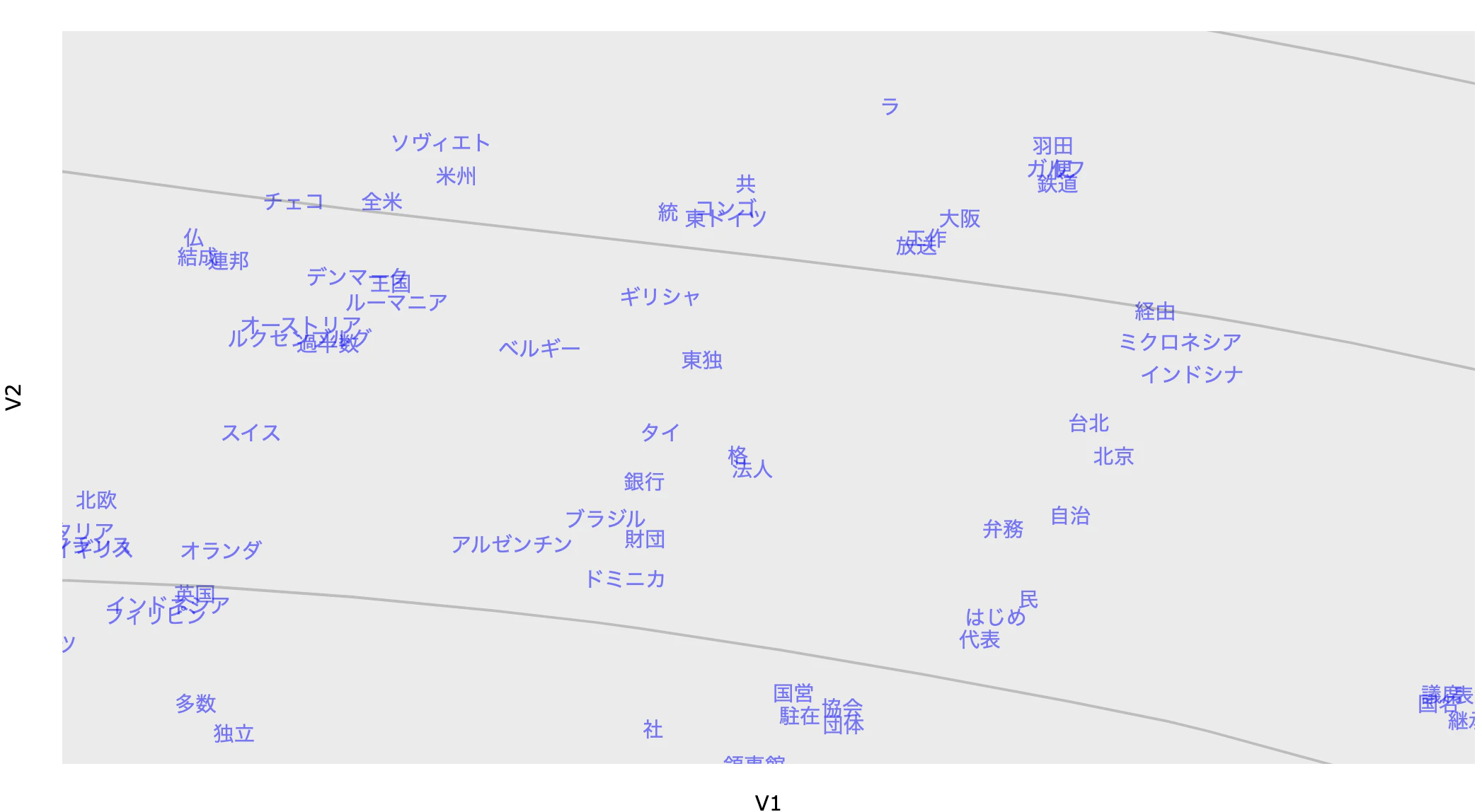
まず、同じ文脈で利用されることが多いと思われる海里系の単語と漢数字が近いところに分布している。
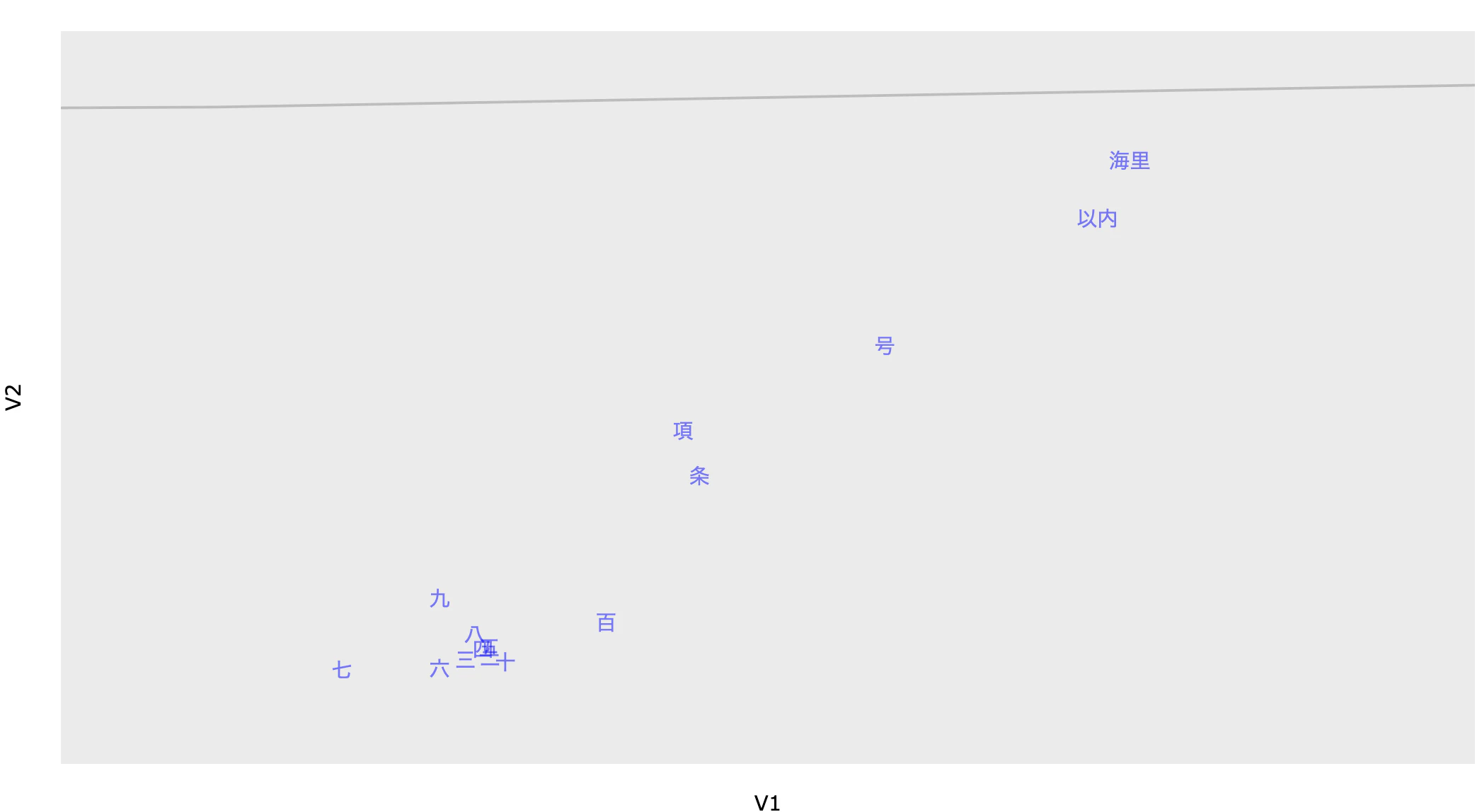
また、「戰」などの旧字体とヤルタ、マツカーサー(ママ)、進駐、講和などの終戦直後の文脈で出現する単語も近い場所に分布している。
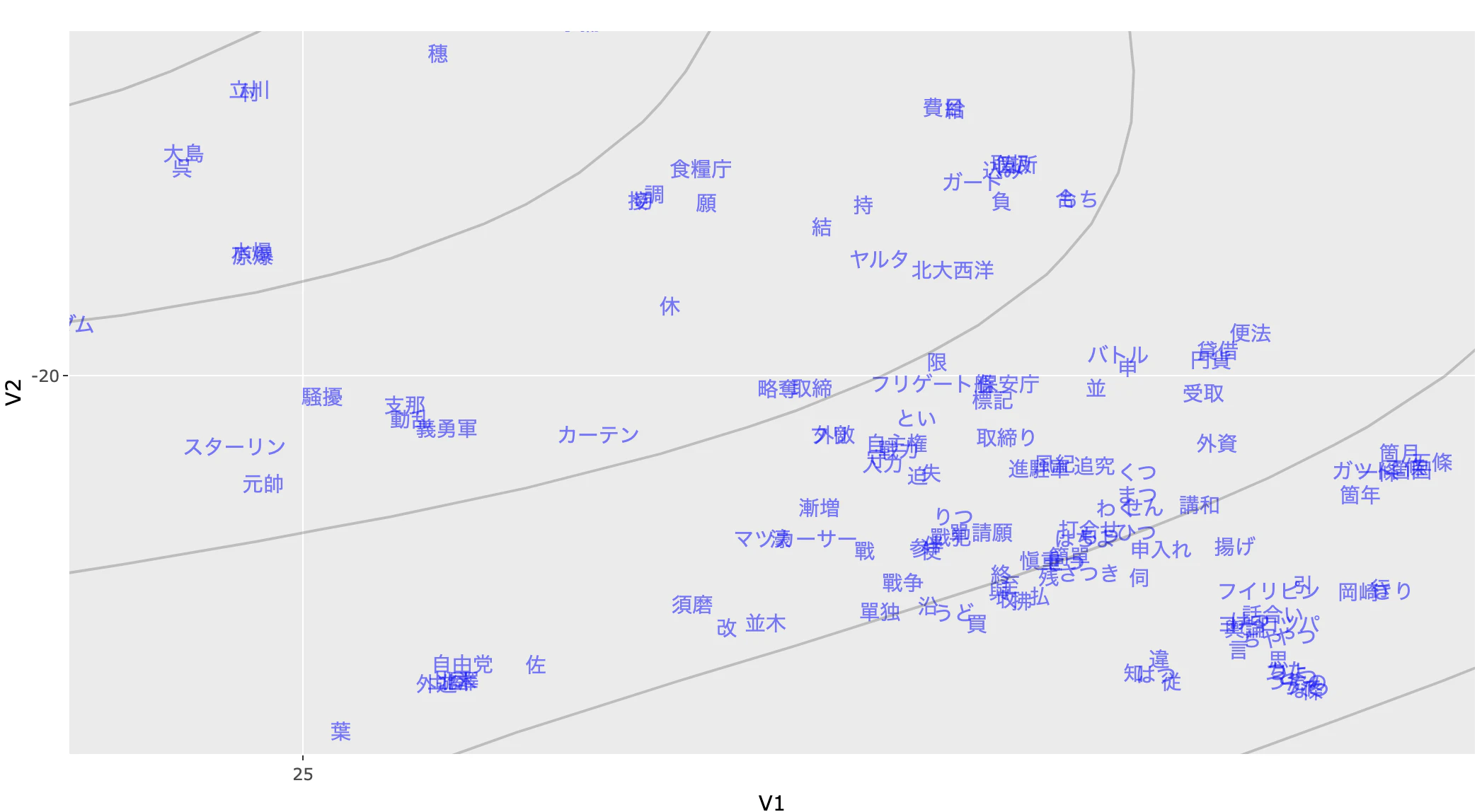
予算系の単語も近い場所に分布している。
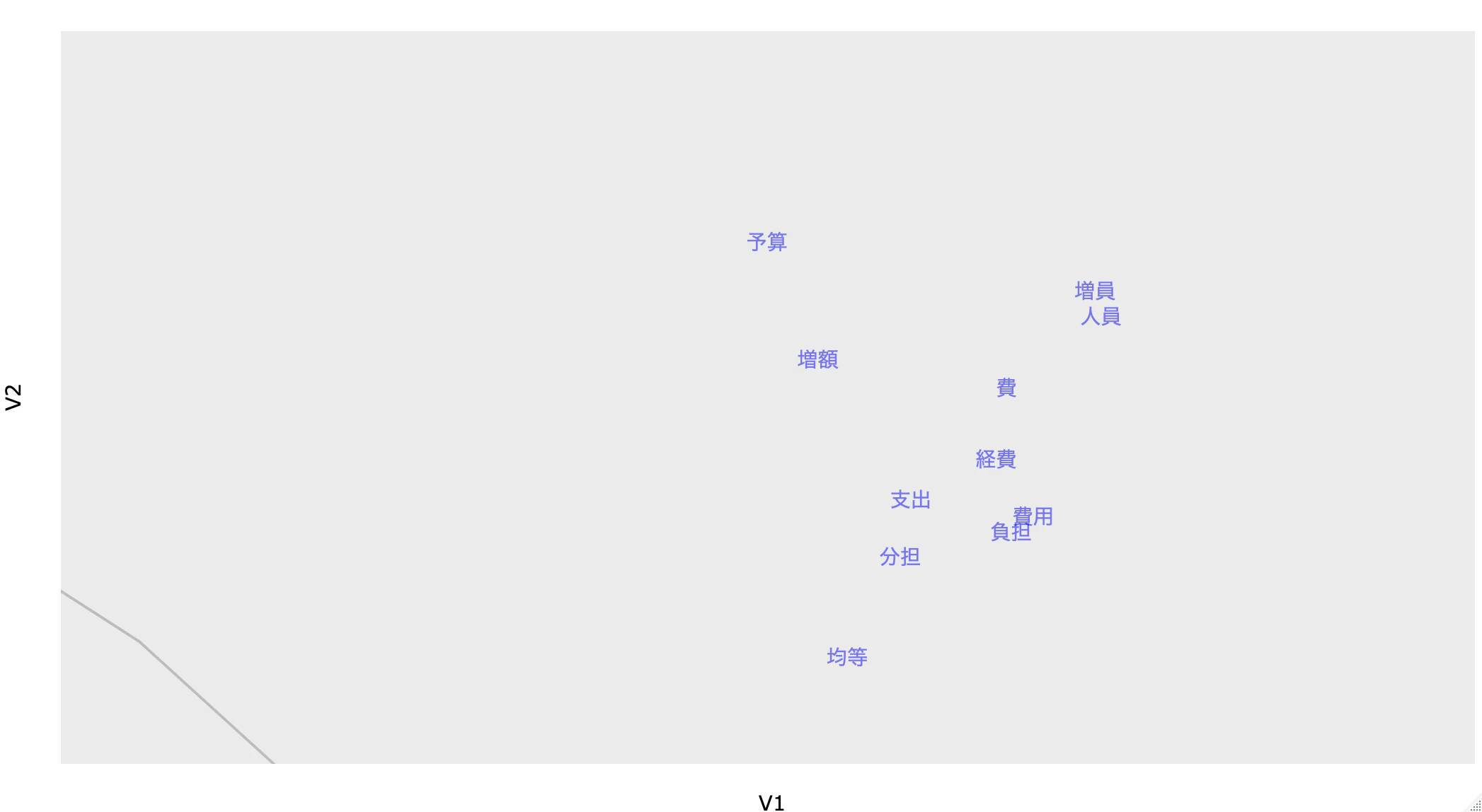
地理名称系の単語も近い場所に分布している。
犯罪系の単語も近い場所に分布している。
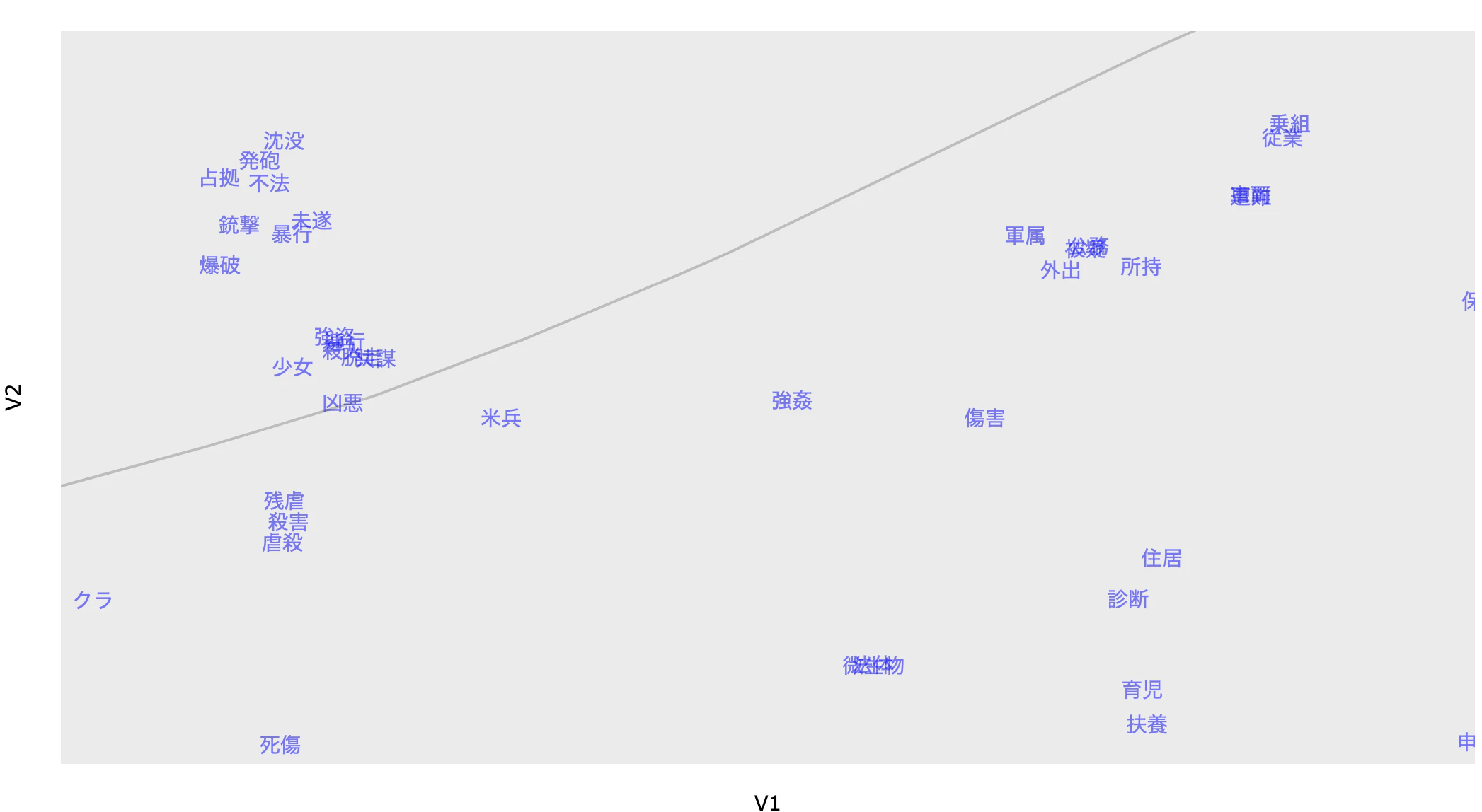
この結果から、$\beta$ がランダムなベクトルを推定しているのではなく、衆議院外務委員会の発言傾向を的確に捉えていることが確認できる。
次元の重み
ここでは、時間によって変化する選好関係を表現する効用関数の機構である $\delta$ を時系列で可視化する。
m_dw2v_summary |>
dplyr::filter(stringr::str_detect(variable, "dimension_year\\[")) |>
dplyr::mutate(
id = variable |>
purrr::map(
\(x){
stringr::str_split(x, "\\[|\\]|,")[[1]][2:3]
}
)
) |>
tidyr::unnest_wider(id, names_sep = "_") |>
dplyr::mutate(
dplyr::across(
dplyr::starts_with("id"),
~ as.integer(.)
)
) |>
dplyr::left_join(
year_master, by = c("id_1" = "year_id")
) |>
ggplot2::ggplot() +
ggplot2::geom_line(ggplot2::aes(x = record_year, y = mean, color = as.factor(id_2))) +
ggplot2::geom_ribbon(ggplot2::aes(x = record_year, ymin = q5, ymax = q95, fill = as.factor(id_2)), alpha = 0.3) +
ggplot2::scale_x_continuous(breaks = seq(min(year_master$record_year), max(year_master$record_year), by = 2)) +
ggplot2::theme(axis.text.x = ggplot2::element_text(angle = 45, hjust = 1)) +
ggplot2::labs(
title = "Change of Dimensions' Importance Across Time",
x = "Year",
y = "Importance",
color = "dimension id",
fill = "dimension id"
) +
ggplot2::geom_vline(xintercept = 1989, linetype = "dashed", color = "blue", alpha = 0.6, linewidth = 1.5) +
ggplot2::annotate("text", x = 1989, y = Inf, label = "End of Cold War", vjust = 2, color = "blue")
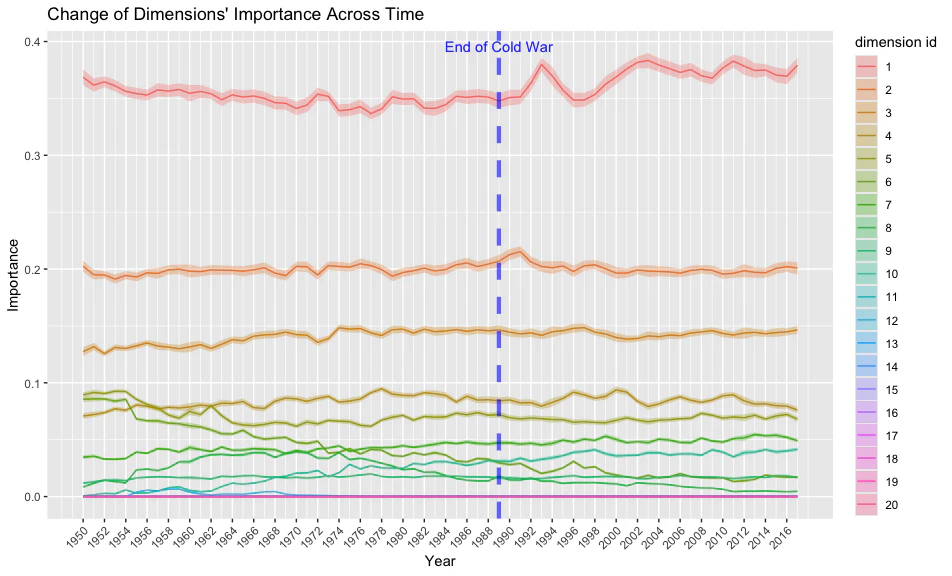
まず注目すべきは、$\delta$ の安定性である。分析前には、特に冷戦終結前後にかけて $\delta$ に大きな変動が生じるのではないかと予想していたが、実際にはどの次元の重みにおいても顕著な経時的変化は見られなかった。
また、実際にゼロ以上の重みが付与された次元は、およそ10次元程度に過ぎず、非常に限られている。Rodriguez and Spirling(2022)でも指摘されているように、言語データをベクトルで表現する従来のモデルは、しばしばより多くの次元を必要とする。しかし、本モデルの分析結果からは、それほど多くの次元は必ずしも必要ではないことが示唆される。詳細は本記事の範囲外であるが、棒折り過程を用いて次元ごとに異なる重みを付与することで、言語データをより効率的に表現できる可能性がある。
単語の意味の変遷
ここでは、各単語ベクトルの要素に、その年における対応する次元の重みを乗じたベクトルを作成し、これを「顕示単語ベクトル」と呼ぶ
$$
\hat{\beta_{word,d,t}} := \beta_{word,d} \cdot \delta_{d,t}
$$
以降では、同一年の顕示単語ベクトル同士のコサイン類似度を計算し、最も類似する単語の変化を追跡することで、単語の意味の変化を可視化する。
まずは、単語ベクトル $\beta$ と年における対応する次元の重み $\delta$ をそれぞれ抽出して、
word_embedding_matrix <- m_dw2v_summary |>
dplyr::filter(stringr::str_detect(variable, "^word_embedding\\[")) |>
dplyr::pull(mean) |>
matrix(ncol = 20)
dimension_year_matrix <- m_dw2v_summary |>
dplyr::filter(stringr::str_detect(variable, "^dimension_year\\[")) |>
dplyr::pull(mean) |>
matrix(ncol = 20)
顕示単語ベクトルを計算する。
word_embedding_matrix_weighted <- year_master |>
nrow() |>
seq_len() |>
purrr::map(
\(i){
word_master |>
nrow() |>
seq_len() |>
purrr::map(
\(j){
word_embedding_matrix[j,] * dimension_year_matrix[i,]
}
) |>
do.call(what = rbind, args = _)
}
)
最後に、コサイン類似度を計算するための関数を用意して、
cos_sim <- function(a, b){
as.numeric(a %*% b)/sqrt(sum(a ^ 2) * sum(b ^ 2))
}
まず中華人民共和国の意味の変化を可視化しよう。
year_master |>
nrow() |>
seq_len() |>
purrr::map(
\(i){
this_matrix <- word_embedding_matrix_weighted[[i]]
this_matrix |>
nrow() |>
seq_len() |>
purrr::map_dbl(
\(i){
cos_sim(this_matrix[1211, ], this_matrix[i, ])
}
) |>
tibble::tibble(
cos_sim = _,
word = word_master$word
) |>
dplyr::arrange(-cos_sim) |>
dplyr::slice_head(n = 20) |>
dplyr::mutate(
record_year = year_master$record_year[i],
rid = dplyr::row_number() |>
rev()
)
}
) |>
dplyr::bind_rows() |>
dplyr::filter(
record_year %in% c(1950, 1955, 1960, 1965, 1970, 1975, 1980, 1985, 1990, 1995, 2000, 2005, 2015)
) |>
ggplot2::ggplot() +
ggplot2::geom_text(ggplot2::aes(x = as.factor(record_year), y = rid, label = word, alpha = cos_sim), color = "blue", family = "HiraKakuPro-W3") +
ggplot2::theme_minimal(base_family = "HiraKakuPro-W3") +
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank(),
axis.title.y = ggplot2::element_blank(),
axis.text.y = ggplot2::element_blank(),
axis.ticks.y = ggplot2::element_blank()
) +
ggplot2::labs(
title = "中華人民共和国",
x = "年"
)

「中華人民共和国」の意味の変化の分析結果を見ると、まず冷戦の初期において、「スターリン」、「(李)承晩」、「蒋介石」など冷戦時代を代表する人物との類似度が高かったが、時間が経つにつれて、「スターリン」以外の単語が「中華人民共和国」と最も類似する単語のリストから姿を消した。また、初期において、「国交」「拒絶」が類似単語の上位にあったが、1972年9月に日中共同声明を発表して、日本と中華人民共和国が国交を結んだ前後から、「拒絶」の類似度が下がり、「正統」の類似度が上がった。これはまさに日本外交のスタンスの変化を本記事が提案したモデルがうまく捉えた証拠であるといえよう。
一方で、あまり変化が見られなかった単語が大半を占めている。例えば、「自衛」の類似単語の変化を可視化しよう。
year_master |>
nrow() |>
seq_len() |>
purrr::map(
\(i){
this_matrix <- word_embedding_matrix_weighted[[i]]
this_matrix |>
nrow() |>
seq_len() |>
purrr::map_dbl(
\(i){
cos_sim(this_matrix[5068, ], this_matrix[i, ])
}
) |>
tibble::tibble(
cos_sim = _,
word = word_master$word
) |>
dplyr::arrange(-cos_sim) |>
dplyr::slice_head(n = 20) |>
dplyr::mutate(
record_year = year_master$record_year[i],
rid = dplyr::row_number() |>
rev()
)
}
) |>
dplyr::bind_rows() |>
dplyr::filter(
record_year %in% c(1950, 1955, 1960, 1965, 1970, 1975, 1980, 1985, 1990, 1995, 2000, 2005, 2015)
) |>
ggplot2::ggplot() +
ggplot2::geom_text(ggplot2::aes(x = as.factor(record_year), y = rid, label = word, alpha = cos_sim), color = "blue", family = "HiraKakuPro-W3") +
ggplot2::theme_minimal(base_family = "HiraKakuPro-W3") +
ggplot2::theme(
panel.grid.major = ggplot2::element_blank(),
panel.grid.minor = ggplot2::element_blank(),
axis.title.y = ggplot2::element_blank(),
axis.text.y = ggplot2::element_blank(),
axis.ticks.y = ggplot2::element_blank()
) +
ggplot2::labs(
title = "自衛",
x = "年"
)

年ごとにわずかな変化は観察されるものの、「中華人民共和国」に見られたような顕著な語義変化は確認されない。このことから、本モデルは、意味的な変化がほとんどない単語に対しては不要な変動を付与せず、実際に変化が生じた単語に対してのみ適切に変化を反映するという、シグナルとノイズを効果的に識別する機能を有しているといえる。
結論
本稿は、政治学における言語の意味変化の識別という重要な課題に対し、ミクロ経済学的な合理的選択モデルと階層的ノンパラメトリックベイズモデルを融合させた新たな推定手法を提案した。
従来の単語埋め込みモデルが単なる確率的共起に依存していたのに対し、本提案モデルは、話者の文脈依存的な単語選択を効用最大化行動として定式化することで、単語の意味空間の変動に一貫した理論的基盤を与えた。具体的には、完備性、反射性、推移性といった選好の合理的制約を満たす効用関数の経時変化を、時間変動する次元の重み $\delta_{t,d}$ と単語ベクトル $\beta_{word,d}$ の相互作用として定式化した。これにより、パラメータ数を抑制しつつ、意味変化を効率的に捉える枠組みを構築した。
また、ノイズ項に第1種極値分布を仮定し、IIA を利用することで、大規模語彙に対する確率計算をネガティブ・サンプリングを用いた二者択一問題に理論的に還元し、計算効率と推定の一貫性を両立させた。
さらに、時間変動する次元の重み $\delta_{t,d}$ の事前分布に自己回帰的な階層棒折り過程を導入することで、時間的連続性を保持しつつ、無限次元の柔軟性と次元重要度の自動的な収束を保証した。これは、先行研究が抱えていた次元数の事前設定や、時間ごとのモデル個別推定に伴う計算負荷およびパラメータ貯蔵の問題に対する本質的な解決策となる。
衆議院外務委員会の議事録データを用いた検証では、本提案モデルが高い予測精度(正答率94%超)を示し、推定された単語ベクトルが関連性の高い単語を意味空間上で近接させるなど、政治的言説の特徴を的確に捉えていることが確認された。
特筆すべき成果として、「中華人民共和国」に関する分析結果は、日中間の外交スタンスが「国交拒絶」から「正統」性の承認へと変化した歴史的転換点(1972年の日中共同声明前後)における語義の顕著な変化を正確に捉えることに成功した。他方で、「自衛」のように意味的変化が少ない単語に対しては、不必要な変動を付与しないシグナル・ノイズ識別機能を有することも示された。この事実は、本モデルが単なるノイズではなく、政治的選好構造の変化に起因する真の言語変化のシグナルを抽出する能力を持つことを明確に示唆する。
参考文献
Blei, David M., Alp Kucukelbir, and Jon D. McAuliffe. "Variational inference: A review for statisticians." Journal of the American statistical Association 112.518 (2017): 859-877.
Gentzkow, Matthew, Jesse M. Shapiro, and Matt Taddy. "Measuring group differences in high‐dimensional choices: method and application to congressional speech." Econometrica 87.4 (2019): 1307-1340.
Gopalan, Prem, Francisco J. R. Ruiz, Rajesh Ranganath and David M. Blei. "Bayesian nonparametric poisson factorization for recommendation systems." Artificial Intelligence and Statistics. PMLR, 2014.
Grimmer, Justin. "An introduction to Bayesian inference via variational approximations." Political Analysis 19.1 (2011): 32-47.
Kreps, David M. Microeconomic foundations. Vol. 1. Princeton university press, 2013.
Kucukelbir, Alp, Dustin Tran, Rajesh Ranganath, Andrew Gelman, David M. Blei. "Automatic differentiation variational inference." Journal of machine learning research 18.14 (2017): 1-45.
Maaten, Laurens van der, and Geoffrey Hinton. "Visualizing data using t-SNE." Journal of machine learning research 9.Nov (2008): 2579-2605.
Mikolov, Tomas, Ilya Sutskever, Kai Chen, Greg S Corrado, Jeff Dean. "Distributed representations of words and phrases and their compositionality." Advances in neural information processing systems 26 (2013).
Rodman, Emma. "A timely intervention: Tracking the changing meanings of political concepts with word vectors." Political Analysis 28.1 (2020): 87-111.
Rodriguez, Pedro L., and Arthur Spirling. "Word embeddings: What works, what doesn’t, and how to tell the difference for applied research." The Journal of Politics 84.1 (2022): 101-115.
Rudolph, Maja, and David Blei. "Dynamic embeddings for language evolution." Proceedings of the 2018 world wide web conference. 2018.
Teh, Yee Whye, Michael I. Jordan, Matthew J. Beal, and David M. Blei. "Hierarchical Dirichlet processes." Journal of the American Statistical Association 101.476 (2006): 1566-1581.
Train, Kenneth E. Discrete choice methods with simulation. Cambridge university press, 2009.