はじめに
こんにちは、事業会社で働いているデータサイエンティストです。
本記事は、以下の記事の続編として、推定したベイズ機械学習モデル、とりわけ、いわゆる因子分析系のモデル、を「実際にどう運用するのか」に焦点を当てて解説します。
まず大前提として、本記事は信用区間を不要とする分析タスクを想定しています。そのため、法律や社内・組織内規定により厳密な信用区間を報告しないといけない場合は、本記事で紹介される手法を利用しないでください。
さて、私が民間企業でデータサイエンティストとして約5年間働きつつ、学会発表などを通じてアカデミアとの関係も保ってきた中で強く感じたのが、政治学方法論・計量経済学をはじめとする統計学系分野と、ビジネスとの間に存在する大きなギャップです。それは何かというと、統計学は基本的に「モデルを運用する」ことを前提としていない、という点です。
ここで言う「運用」とは、一度推定したモデルを継続的に利用し、学習時には存在しなかった新しいデータに対しても判断を下し続けることと定義します。
もちろん政治学の分野でも、DW-NOMINATE や V-Dem のように、継続的にデータや推定結果を更新していく優れたプロジェクトは存在します。しかし、全体として見れば、論文が刊行された時点で分析は完結し、その後の運用まではあまり重視されないケースが多いのも事実です。
アカデミアでは「論文が出ました、はい終わり」で済むことが多い一方、ビジネスの現場では、毎週の経営会議で指標を更新して報告するや新しいユーザーの映画をレコメンドするといった形で、モデルを継続的に使い続けることが求められます。このギャップこそが、アカデミアからビジネスへ移る人が、まず最初に直面する大きな壁の一つだと感じています。
本記事では、因子分析モデルを軸に「運用とはそもそも何か」を整理したうえで、運用を考える際に陥りがちな落とし穴を解説し、最後に実務で使える具体的な運用方法を紹介していきます。
タイトルにも書いている通り、本記事で紹介する運用手法は、ベイズの原理原則を厳密に守り、信用区間をはじめとするパラメータ不確実性の価値を何よりも重視する立場から見れば、場合によっては統計学への裏切りと受け取られるかもしれません。
それでもなお、これは私自身が試行錯誤の末にたどり着いた、ベイズ因子分析モデルを現実の業務で安定的に運用するための方法です。理論的な美しさよりも、継続的に動き続けること、壊れずに使われ続けることを優先した結果でもあります。
もし、どうしてもベイズの原理原則を最優先に据えたいのであれば、本記事で指摘する「運用上の課題」を正面から解決する、より洗練された新しい手法をぜひ開発してみてください。
では、早速本題に入りましょう!
運用とは
アカデミアでもビジネスでも、データサイエンスのプロジェクトでは、基本的に「あるモデルを推定し、そのモデルから得られる示唆を報告したり、性能を評価したりする」ことが多いでしょう。用いられる方法論にも共通点は多く、この点ではアカデミアとビジネスは意外と近いと感じる人も少なくありません。
しかし、その先に待っているものは大きく異なります。アカデミアでは、得られた示唆や性能を論文としてまとめ、どこかに投稿して採択されたら一区切り、というケースが多いでしょう。一方でビジネスでは、特に平均処置効果の推定を目的とした因果推論・効果検証以外のプロジェクトにおいて、次のような反応がほぼ確実に返ってきます。
- 「おお、商談成約率の予測モデル、精度が高いですね。では、営業部に毎日配信するためのシステムを作りましょう」
- 「なるほど、ユーザーの好みが抽出できているんですね。では早めにバックエンドチームと話して、商品表示ロジックに組み込みましょう」
これが、ここで言う運用です。こうしたネクストアクションが自然に出てくることを事前に想定でき、なおかつ驚かなくなることが、ビジネスに馴染めた最初の定性的な指標だと、私は考えています。
運用フェーズに入ると、エンジニアとのコミュニケーションが一気に増えます。以前、エンジニアとどのようにコミュニケーションを取るべきかについて記事を書いているので、興味のある方はぜひご覧ください。
ただし、実は問題はコミュニケーションだけではありません。ここで一度、商談成約率の予測モデルを例に考えてみましょう。話を単純化するため、次のようなモデルが推定されたとします。
$$
\hat{成約率_{i}} = \hat{f}(商談回数_{i}, 業種_{i})
$$
この場合、これまで関わったことのない業種の顧客が来たときにどう予測するか、という問題はありますが、これについては対応方法が数多く存在するため、ここでは詳細を省きます。要するに、あらかじめ定義された特徴量から予測を行うタスクは、運用時にそれほど本質的な困難に直面しないことが多いのです。
では、因子分析をはじめとするモデルではどうでしょうか。新しいユーザーが来るたびに、そのユーザーの嗜好を表すベクトルを同じモデルの枠組みで推定する必要があります。アカデミア出身の方であれば、新しいユーザーを含めた全ユーザーのデータを使って、再度モデルを推定することを真っ先に考えるでしょう。これは統計学的には非常に正しい判断です。
しかし、このやり方には大きく二つの問題があります。
第一に、計算時間の問題です。ゼロから再推定すると、とてつもない時間がかかります。後ほど具体的な数字を示しますが、たった一人の新しいユーザーのためにモデルを再推定する方法は、本記事で提案する方法と比べて約57倍の時間を要します。しかも、本記事で提案する方法でも、全体モデルとの整合性は十分に保たれます。では、ユーザーへのレコメンドなどのおそらく信用区間を利用しない実務タスクで使うために、信用区間がどうのこうのという統計学的厳密さのためだけに、本当に57倍の時間をかけますか。その判断基準を経営会議で取締役・役員の前で説明する勇気はありますか。経営の立場に立って、ぜひ一度考えてみてください。
第二の問題は、因子の安定性です。トピックモデル、ファクターモデル、協調フィルタリングといった因子分析系モデルでは、学習データが変わると、推定される因子も微妙に変化します。そのため、元々の推定結果における第一次元と、新しいデータを含めて再推定した際の第一次元が、同じ傾向を表している保証はありません。これは学習アルゴリズムの確率的な性質による場合もあれば、新しいデータがモデルに新たな情報を与え、構造そのものが見直された結果である場合もあります。
後者はまさに因子モデルの強みですが、例えば「第一次元は自社の広告収入と強く相関しているから、第一次元がマイナスのユーザー数を毎週の経営会議で共有しよう」といった運用が始まった瞬間、モデルが勝手に行う構造の見直しは、現場にとっては余計なお世話になりかねません。
さらに厄介なのは、因子モデルには符号の不定性があり、推定のたびに因子の正負が逆転してしまう可能性がある点です。
もちろん、アカデミアから来たばかりの人であれば、そもそもこのように因子をモニタリングする依頼自体を断るでしょう。私自身も、最初は断りかけました。しかし、ビジネス課題と真正面から向き合うために、解決策を考えることにしました。方法論が解決できる課題を制限するのではなく、解決しなければならない課題があるなら、それに応じた方法を考える。本記事は、その試行錯誤の結果をまとめたものです。
運用の知恵:パラメータをデータとして扱う
ここからの内容は、こちらの記事の説明を前提としていますので、先に読んでいただければと思います!
ここで紹介する運用の知恵とは、新しいユーザーが流入した際に、すでに推定済みの「次元関連」「映画関連」「ユーザークラスター関連」の各パラメータについては事後平均をそのまま定数として固定し、学習対象から外すという考え方です。そのうえで、新しいユーザーに紐づくパラメータだけを新たに推定します。
このアプローチによって、まず新規ユーザー追加時に学習しなければならないパラメータ数が大幅に削減されます。さらに、次元・映画・ユーザークラスターに関するパラメータはすべて既存モデルから引き継いだ定数であるため、モデルの表現力をあえて強く制限することになり、その結果として、新しいユーザーのパラメータは必ず元のモデルと整合的な位置に推定されます。
一方で、この方法は元のモデルにおけるパラメータ不確実性を完全に無視している点に注意が必要です。ベイズの原理原則を厳密に守り、信用区間をはじめとするパラメータ不確実性の価値を最重要視する立場から見れば、これはまさに統計学への裏切りと映るでしょう。実際、新しいユーザーに紐づくパラメータの分散が過小推定されることは避けられません。
それでもなお、後ほど示す性能検証から分かるように、パラメータの平均値に着目する限り、この運用手法は元のモデルをかなり高い精度で再現できています。したがって、平均値にもとづいて意思決定を行うようなタスクにおいては、本手法は非常に実用的で有効なアプローチだと言えるでしょう。
再現実験
まずは、本記事で利用するStanコードです:
functions {
vector stick_breaking(vector breaks){
int length = size(breaks) + 1;
vector[length] result;
result[1] = breaks[1];
real summed = result[1];
for (d in 2:(length - 1)) {
result[d] = (1 - summed) * breaks[d];
summed += result[d];
}
result[length] = 1 - summed;
return result;
}
real partial_sum_lpmf(
array[] int result,
int start, int end,
array[] int user, array[] int movie,
real search_intercept,
vector search_user, vector search_movie,
array[] vector cutpoints,
vector dimension,
vector movie_propensity,
array[] vector user_latent, matrix movie_latent
){
vector[end - start + 1] lambda;
int count = 1;
for (i in start:end){
if (result[count] == 1) {
vector[2] case_when;
case_when[1] = bernoulli_logit_lpmf(0 | search_intercept + search_user[user[i]] + search_movie[movie[i]]);
case_when[2] = bernoulli_logit_lpmf(1 | search_intercept + search_user[user[i]] + search_movie[movie[i]]) +
ordered_logistic_lpmf(
result[count] |
movie_propensity[movie[i]] +
user_latent[user[i]] '* (movie_latent[movie[i],:]' .* dimension),
cutpoints[user[i]]
);
lambda[count] = log_sum_exp(case_when);
} else {
lambda[count] = bernoulli_logit_lpmf(1 | search_intercept + search_user[user[i]] + search_movie[movie[i]]) +
ordered_logistic_lpmf(
result[count] |
movie_propensity[movie[i]] +
user_latent[user[i]] '* (movie_latent[movie[i],:]' .* dimension),
cutpoints[user[i]]
);
}
count += 1;
}
return sum(lambda);
}
}
data {
int user_type;
int movie_type;
int result_type;
int dimension_type;
int group_type;
vector[dimension_type] dimension;
vector[group_type] group_user;
vector[group_type] group_user_sigma;
matrix[group_type, dimension_type] group_user_latent;
real search_intercept;
vector[movie_type] search_movie;
vector[movie_type] movie_propensity;
matrix[movie_type, dimension_type] movie_latent;
int N;
array[N] int user;
array[N] int movie;
array[N] int result;
}
parameters {
array[user_type] vector[dimension_type] user_latent;
array[user_type] ordered[result_type - 1] cutpoints;
vector[user_type] search_user;
}
model {
for (i in 1:user_type){
vector[group_type] case_vector;
for (j in 1:group_type){
case_vector[j] = log(group_user[j]) + normal_lpdf(user_latent[i] | group_user_latent[j,:], group_user_sigma[j]);
}
target += log_sum_exp(case_vector);
}
search_user ~ normal(0, 10);
int grainsize = 1;
target += reduce_sum(
partial_sum_lupmf, result,
grainsize,
user, movie,
search_intercept,
search_user, search_movie,
cutpoints,
dimension,
movie_propensity,
user_latent, movie_latent
);
}
前提の記事の中のStanコードと比べたらわかるように、
「次元関連」「映画関連」「ユーザークラスター関連」の各パラメータは、すべて data としてモデルに渡しています。そのため、新しいユーザーのパラメータを推定する際に、これらの値が更新されることは絶対にありません。これは厳密にはベイズの原理原則に反する挙動ですが、その代わりに、新しい次元が突然現れたり、既存の次元の解釈が変わったりすることがなく、運用の観点では非常に扱いやすいという大きな利点があります。
とはいえ、この一見すると少し奇妙にも見える Stan の書き方で、本当に新しいユーザーを元のモデルと整合的な位置に推定できるのか、という疑問は当然生じるでしょう。そこで、本記事では確率的な単体テストを行い、この点を検証します。
具体的には、すでに全学習データを用いて推定済みの「次元関連」「ユーザー関連」「映画関連」「ユーザークラスター関連」のパラメータが手元にある状況を考えます。そのうえで、あえてユーザー関連のパラメータだけを隠し、本記事で紹介する手法がそれらをどの程度の精度で再現できるのかを、まず確認していきます。
まずはモデルをコンパイルして:
m_nu_init <- cmdstanr::cmdstan_model("recommand_new_user.stan",
cpp_options = list(
stan_threads = TRUE
)
)
推定を実施します:
> m_nu_estimate <- m_nu_init$variational(
seed = 12345,
threads = 8,
data = list(
user_type = max(movie_df_with_id$user_id),
movie_type = nrow(movie_master),
result_type = max(movie_df_with_id$point) + 1,
dimension_type = 20,
group_type = 10,
dimension = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^dimension\\[")) |>
dplyr::pull(mean),
group_user = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^group_user\\[")) |>
dplyr::pull(mean),
group_user_sigma = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^group_user_sigma\\[")) |>
dplyr::pull(mean),
group_user_latent = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^group_user_latent\\[")) |>
dplyr::pull(mean) |>
matrix(ncol = 20),
search_intercept = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^search_intercept")) |>
dplyr::pull(mean),
search_movie = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^search_movie\\[")) |>
dplyr::pull(mean),
movie_propensity = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^movie_propensity\\[")) |>
dplyr::pull(mean),
movie_latent = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^movie_latent\\[")) |>
dplyr::pull(mean) |>
matrix(ncol = 20),
N = nrow(movie_df_with_id_downsampled[-test_id,]),
user = movie_df_with_id_downsampled$user_id[-test_id],
movie = movie_df_with_id_downsampled$movie_id[-test_id],
result = movie_df_with_id_downsampled$point[-test_id] + 1
)
)
------------------------------------------------------------
EXPERIMENTAL ALGORITHM:
This procedure has not been thoroughly tested and may be unstable
or buggy. The interface is subject to change.
------------------------------------------------------------
Gradient evaluation took 0.056738 seconds
1000 transitions using 10 leapfrog steps per transition would take 567.38 seconds.
Adjust your expectations accordingly!
Begin eta adaptation.
Iteration: 1 / 250 [ 0%] (Adaptation)
Iteration: 50 / 250 [ 20%] (Adaptation)
Iteration: 100 / 250 [ 40%] (Adaptation)
Iteration: 150 / 250 [ 60%] (Adaptation)
Iteration: 200 / 250 [ 80%] (Adaptation)
Iteration: 250 / 250 [100%] (Adaptation)
Success! Found best value [eta = 0.1].
Begin stochastic gradient ascent.
iter ELBO delta_ELBO_mean delta_ELBO_med notes
100 -263481.073 1.000 1.000
200 -222866.338 0.591 1.000
300 -208881.496 0.416 0.182
400 -202218.961 0.321 0.182
500 -198708.694 0.260 0.067
600 -196491.687 0.219 0.067
700 -195073.007 0.188 0.033
800 -194103.878 0.165 0.033
900 -193405.893 0.147 0.018
1000 -192908.508 0.133 0.018
1100 -192498.022 0.033 0.011
1200 -192195.649 0.015 0.007 MEDIAN ELBO CONVERGED
Drawing a sample of size 1000 from the approximate posterior...
COMPLETED.
Finished in 129.5 seconds.
data のリストの作成ロジックでよりはっきり確認できますが、元のモデルのパラメータに該当する部分、すべて元のモデルの推定結果の事後分布の平均から取って直接今回の運用用モデルに渡しています。
では比較のため、ユーザーごとの探索傾向($\lambda$, search_user)とユーザーの潜在ベクトル ($\gamma$, user_latent)を抽出して比較します。ただし、ユーザーの潜在ベクトルは実際にモデルに利用された第一次元しか比較しません。
comparison_df <- m_nu_summary |>
dplyr::filter(stringr::str_detect(variable, "^user_latent\\[")) |>
dplyr::mutate(
id = variable |>
purrr::map(
\(x){
as.integer(stringr::str_split(x, "\\[|\\]|,")[[1]][2:3])
}
)
) |>
tidyr::unnest_wider(id, names_sep = "_") |>
dplyr::filter(id_2 == 1) |>
dplyr::select(replicated = mean) |>
dplyr::bind_cols(
m_summary |>
dplyr::filter(stringr::str_detect(variable, "^user_latent\\[")) |>
dplyr::mutate(
id = variable |>
purrr::map(
\(x){
as.integer(stringr::str_split(x, "\\[|\\]|,")[[1]][2:3])
}
)
) |>
tidyr::unnest_wider(id, names_sep = "_") |>
dplyr::filter(id_2 == 1) |>
dplyr::select(original = mean)
) |>
dplyr::mutate(
param = "user_latent"
) |>
dplyr::bind_rows(
m_nu_summary |>
dplyr::filter(stringr::str_detect(variable, "^search_user\\[")) |>
dplyr::select(replicated = mean) |>
dplyr::bind_cols(
m_summary |>
dplyr::filter(stringr::str_detect(variable, "^search_user\\[")) |>
dplyr::select(original = mean)
) |>
dplyr::mutate(
param = "search_user"
)
)
まずは可視化で比較しましょう:
comparison_df |>
ggplot2::ggplot() +
ggplot2::geom_point(ggplot2::aes(x = replicated, y = original, color = param)) +
ggplot2::geom_abline(slope = 1, intercept = 0, color = "red", linetype = "dashed", linewidth = 2)
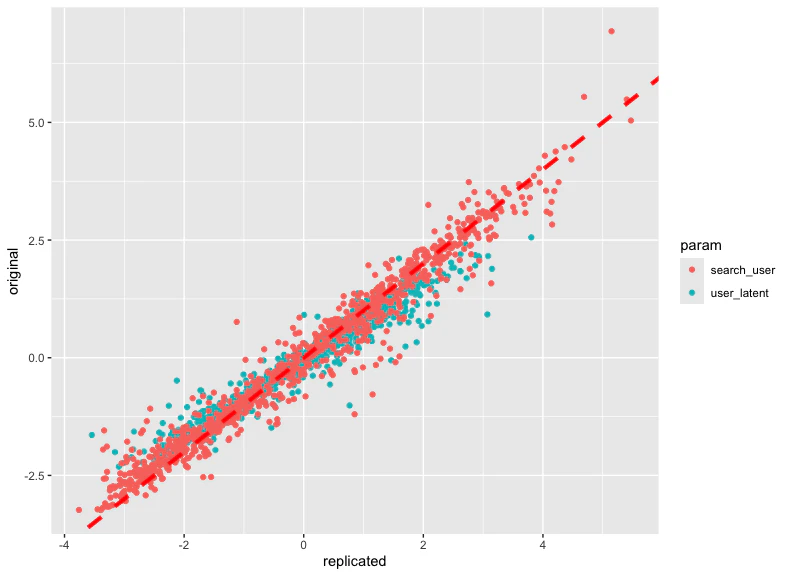
パラメータの種類ごとに色分けして可視化していますが、いずれについても、本記事の手法で再現したパラメータの値(replicated)と、元のモデルで推定されたパラメータの値(original)を表す点は、45度線(赤線)付近に密集して分布しています。このことから、本手法によって非常に高い精度で元のパラメータが再現されていると言えるでしょう。
両者のわずかなズレについては、ベイズ推定に固有のサンプリングによる不確実性として、十分に説明可能な範囲に収まっています。
次に、本記事の手法で再現したパラメータの値がどこまで元のモデルで推定されたパラメータの値を説明できるかをより定量的に判断するため、本記事の手法で再現したパラメータの値がどこまで元のモデルで推定されたパラメータの値を従属変数、元のモデルで推定されたパラメータの値を説明変数とする単回帰を実施します:
> comparison_df |> lm(original ~ replicated, data = _) |> summary()
Call:
lm(formula = original ~ replicated, data = comparison_df)
Residuals:
Min 1Q Median 3Q Max
-1.93903 -0.13484 0.00262 0.13385 2.40100
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.014302 0.007539 -1.897 0.058 .
replicated 0.883934 0.004717 187.392 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3274 on 1884 degrees of freedom
Multiple R-squared: 0.9491, Adjusted R-squared: 0.9491
F-statistic: 3.512e+04 on 1 and 1884 DF, p-value: < 2.2e-16
replicated の係数は理論上の理想値である 1 をわずかに下回っていますが、切片が 5% 水準で 0 と有意差がないこと、および決定係数が 0.9 を超えている事実を鑑みれば、本手法は元の推定結果を十分に精度高く再現できていると定量的に評価できます。
新しいユーザーのパラメータ推定
ここで本当の本題に入り、新しいユーザーのパラメータを推定してみましょう!
元の記事の結論ですが:
ユーザーの好みは「アート志向の映画」(プラス方向)と「商業志向の映画」(マイナス方向)という軸で集約できます。ここで、極端な視聴傾向を持つ二人のユーザー、すなわち「商業志向の映画の上位10作品のみに満点をつけ、他は一切見ない層」と「アート志向の映画の上位10作品のみに満点をつけ、他は一切見ない層」を想定し、それぞれのパラメータを具体的に推定・検証してみましょう。まずはデータを作成します:
usa_movie_lover_df <- movie_master |>
dplyr::mutate(
user_id = 1,
point = dplyr::case_when(
movie_id %in% (m_summary |>
dplyr::filter(stringr::str_detect(variable, "^movie_latent\\[")) |>
dplyr::mutate(id = variable |> purrr::map(\(x){as.integer(stringr::str_split(x, "\\[|\\]|,")[[1]][2:3])})) |>
tidyr::unnest_wider(id, names_sep = "_") |>
dplyr::filter(id_2 == 1) |>
dplyr::bind_cols(m = movie_master$movie) |>
dplyr::arrange(mean) |> dplyr::slice_head(n = 10) |> dplyr::pull(id_1)) ~ 5,
TRUE ~ 0
)
)
art_movie_lover_df <- movie_master |>
dplyr::mutate(
user_id = 1,
point = dplyr::case_when(
movie_id %in% (m_summary |>
dplyr::filter(stringr::str_detect(variable, "^movie_latent\\[")) |>
dplyr::mutate(id = variable |> purrr::map(\(x){as.integer(stringr::str_split(x, "\\[|\\]|,")[[1]][2:3])})) |>
tidyr::unnest_wider(id, names_sep = "_") |>
dplyr::filter(id_2 == 1) |>
dplyr::bind_cols(m = movie_master$movie) |>
dplyr::arrange(-mean) |> dplyr::slice_head(n = 10) |> dplyr::pull(id_1)) ~ 5,
TRUE ~ 0
)
)
では、推定を実施します:
> m_uml_estimate <- m_nu_init$variational(
seed = 12345,
threads = 8,
data = list(
user_type = 1,
movie_type = nrow(movie_master),
result_type = max(movie_df_with_id$point) + 1,
dimension_type = 20,
group_type = 10,
dimension = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^dimension\\[")) |>
dplyr::pull(mean),
group_user = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^group_user\\[")) |>
dplyr::pull(mean),
group_user_sigma = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^group_user_sigma\\[")) |>
dplyr::pull(mean),
group_user_latent = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^group_user_latent\\[")) |>
dplyr::pull(mean) |>
matrix(ncol = 20),
search_intercept = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^search_intercept")) |>
dplyr::pull(mean),
search_movie = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^search_movie\\[")) |>
dplyr::pull(mean),
movie_propensity = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^movie_propensity\\[")) |>
dplyr::pull(mean),
movie_latent = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^movie_latent\\[")) |>
dplyr::pull(mean) |>
matrix(ncol = 20),
N = nrow(usa_movie_lover_df),
user = usa_movie_lover_df$user_id,
movie = usa_movie_lover_df$movie_id,
result = usa_movie_lover_df$point + 1
)
)
------------------------------------------------------------
EXPERIMENTAL ALGORITHM:
This procedure has not been thoroughly tested and may be unstable
or buggy. The interface is subject to change.
------------------------------------------------------------
Gradient evaluation took 0.000548 seconds
1000 transitions using 10 leapfrog steps per transition would take 5.48 seconds.
Adjust your expectations accordingly!
Begin eta adaptation.
Iteration: 1 / 250 [ 0%] (Adaptation)
Iteration: 50 / 250 [ 20%] (Adaptation)
Iteration: 100 / 250 [ 40%] (Adaptation)
Iteration: 150 / 250 [ 60%] (Adaptation)
Iteration: 200 / 250 [ 80%] (Adaptation)
Success! Found best value [eta = 1] earlier than expected.
Begin stochastic gradient ascent.
iter ELBO delta_ELBO_mean delta_ELBO_med notes
100 -44.768 1.000 1.000
200 -35.293 0.634 1.000
300 -33.504 0.441 0.268
400 -33.112 0.333 0.268
500 -32.433 0.271 0.053
600 -32.188 0.227 0.053
700 -33.145 0.199 0.029
800 -32.084 0.178 0.033
900 -32.591 0.160 0.029
1000 -32.766 0.145 0.029
1100 -33.498 0.047 0.022
1200 -32.166 0.024 0.022
1300 -31.999 0.019 0.021
1400 -31.912 0.018 0.021
1500 -31.401 0.018 0.016
1600 -31.285 0.017 0.016
1700 -31.852 0.016 0.016
1800 -31.853 0.013 0.016
1900 -32.056 0.012 0.006 MEDIAN ELBO CONVERGED
Drawing a sample of size 1000 from the approximate posterior...
COMPLETED.
Finished in 1.7 seconds.
> m_uml_summary <- m_uml_estimate$summary()
> m_aml_estimate <- m_nu_init$variational(
seed = 12345,
threads = 8,
data = list(
user_type = 1,
movie_type = nrow(movie_master),
result_type = max(movie_df_with_id$point) + 1,
dimension_type = 20,
group_type = 10,
dimension = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^dimension\\[")) |>
dplyr::pull(mean),
group_user = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^group_user\\[")) |>
dplyr::pull(mean),
group_user_sigma = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^group_user_sigma\\[")) |>
dplyr::pull(mean),
group_user_latent = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^group_user_latent\\[")) |>
dplyr::pull(mean) |>
matrix(ncol = 20),
search_intercept = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^search_intercept")) |>
dplyr::pull(mean),
search_movie = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^search_movie\\[")) |>
dplyr::pull(mean),
movie_propensity = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^movie_propensity\\[")) |>
dplyr::pull(mean),
movie_latent = m_summary |>
dplyr::filter(stringr::str_detect(variable, "^movie_latent\\[")) |>
dplyr::pull(mean) |>
matrix(ncol = 20),
N = nrow(art_movie_lover_df),
user = art_movie_lover_df$user_id,
movie = art_movie_lover_df$movie_id,
result = art_movie_lover_df$point + 1
)
)
------------------------------------------------------------
EXPERIMENTAL ALGORITHM:
This procedure has not been thoroughly tested and may be unstable
or buggy. The interface is subject to change.
------------------------------------------------------------
Gradient evaluation took 0.000491 seconds
1000 transitions using 10 leapfrog steps per transition would take 4.91 seconds.
Adjust your expectations accordingly!
Begin eta adaptation.
Iteration: 1 / 250 [ 0%] (Adaptation)
Iteration: 50 / 250 [ 20%] (Adaptation)
Iteration: 100 / 250 [ 40%] (Adaptation)
Iteration: 150 / 250 [ 60%] (Adaptation)
Iteration: 200 / 250 [ 80%] (Adaptation)
Success! Found best value [eta = 1] earlier than expected.
Begin stochastic gradient ascent.
iter ELBO delta_ELBO_mean delta_ELBO_med notes
100 -60.718 1.000 1.000
200 -36.114 0.841 1.000
300 -32.603 0.596 0.681
400 -30.189 0.467 0.681
500 -29.134 0.381 0.108
600 -28.907 0.319 0.108
700 -26.958 0.284 0.080
800 -27.620 0.251 0.080
900 -28.066 0.225 0.072
1000 -28.230 0.203 0.072
1100 -27.687 0.105 0.036
1200 -27.446 0.038 0.024
1300 -27.966 0.029 0.020
1400 -27.204 0.024 0.020
1500 -27.459 0.021 0.019
1600 -27.361 0.021 0.019
1700 -26.187 0.018 0.019
1800 -27.027 0.019 0.019
1900 -25.324 0.024 0.020
2000 -26.232 0.027 0.028
2100 -26.100 0.025 0.028
2200 -26.607 0.026 0.028
2300 -26.666 0.025 0.028
2400 -26.842 0.022 0.019
2500 -25.761 0.026 0.031
2600 -25.629 0.026 0.031
2700 -27.033 0.026 0.031
2800 -27.416 0.025 0.019
2900 -27.872 0.020 0.016
3000 -26.113 0.023 0.016
3100 -26.246 0.023 0.016
3200 -26.752 0.023 0.016
3300 -26.234 0.025 0.019
3400 -26.546 0.025 0.019
3500 -26.522 0.021 0.016
3600 -25.885 0.023 0.019
3700 -27.684 0.024 0.019
3800 -26.288 0.028 0.020
3900 -25.203 0.031 0.025
4000 -25.421 0.025 0.020
4100 -26.129 0.027 0.025
4200 -25.635 0.027 0.025
4300 -26.163 0.027 0.025
4400 -26.453 0.027 0.025
4500 -26.725 0.028 0.025
4600 -26.498 0.027 0.020
4700 -26.659 0.021 0.019
4800 -25.595 0.020 0.019
4900 -26.776 0.020 0.019
5000 -26.370 0.020 0.019
5100 -26.795 0.019 0.016
5200 -25.001 0.024 0.016
5300 -26.528 0.028 0.016
5400 -28.313 0.033 0.042
5500 -26.706 0.038 0.044
5600 -27.736 0.041 0.044
5700 -25.839 0.048 0.058
5800 -26.533 0.046 0.058
5900 -25.485 0.046 0.058
6000 -26.323 0.048 0.058
6100 -26.434 0.047 0.058
6200 -26.926 0.041 0.041
6300 -27.040 0.036 0.037
6400 -25.847 0.034 0.037
6500 -26.225 0.030 0.032
6600 -25.701 0.028 0.026
6700 -26.948 0.025 0.026
6800 -26.205 0.026 0.028
6900 -26.225 0.021 0.020
7000 -25.708 0.020 0.020
7100 -25.752 0.020 0.020
7200 -26.175 0.020 0.020
7300 -26.007 0.020 0.020
7400 -26.040 0.016 0.016
7500 -26.389 0.015 0.016
7600 -25.826 0.016 0.016
7700 -25.614 0.012 0.013
7800 -25.953 0.010 0.013
7900 -26.273 0.011 0.013
8000 -26.260 0.009 0.012 MEAN ELBO CONVERGED
Drawing a sample of size 1000 from the approximate posterior...
COMPLETED.
Finished in 5.3 seconds.
> m_aml_summary <- m_aml_estimate$summary()
推定に要した時間は、それぞれわずか 1.7 秒と 5.3 秒でした。前回の記事でモデルをゼロから推定した際、285.8 秒を要したことと比較すれば、その差は一目瞭然です。
たとえ本手法に厳しめの条件(遅い方の 5.3 秒)で比較したとしても、既存の各パラメータ(次元・映画・クラスタ)を定数として固定し、新規ユーザーのパラメータのみを限定的に推定する本アプローチは、全データの再推定を行う手法に対して 53.92 倍という圧倒的な計算時間の削減を実現しています。
では推定されたパラメータは元のモデルと整合的でしょうか?まずアート映画のユーザーから確認しましょう:
> m_aml_summary
# A tibble: 28 × 7
variable mean median sd mad q5 q95
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 lp__ -76.3 -75.1 6.29 3.95 -85.0 -69.7
2 lp_approx__ -12.8 -12.4 3.52 3.36 -19.2 -7.75
3 user_latent[1,1] 6.86 6.87 0.194 0.208 6.54 7.17
4 user_latent[1,2] -0.214 -0.298 2.22 2.23 -3.82 3.55
5 user_latent[1,3] 0.131 0.133 1.95 1.88 -3.01 3.36
6 user_latent[1,4] -0.624 -0.624 2.10 2.15 -4.05 2.81
7 user_latent[1,5] 0.142 0.148 2.06 2.04 -3.16 3.64
8 user_latent[1,6] -0.116 -0.144 2.04 2.14 -3.20 3.11
9 user_latent[1,7] 0.243 0.213 2.01 2.03 -2.93 3.53
10 user_latent[1,8] 0.0824 0.126 1.96 1.89 -3.20 3.26
# ℹ 18 more rows
# ℹ Use `print(n = ...)` to see more rows
ユーザーの好みは「アート志向の映画」(プラス方向)と「商業志向の映画」(マイナス方向)という軸で集約できるというのが元のモデルの結論ですが、アート志向の映画上位10作品にのみ満点をつけるユーザーの第一次元のスコアは意図通りプラスの方向に振れ、元のモデルと整合する結果となりました。
では商業映画の人はどうでしょうか?
> m_uml_summary
# A tibble: 28 × 7
variable mean median sd mad q5 q95
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 lp__ -84.0 -82.2 9.20 4.89 -97.6 -75.9
2 lp_approx__ -13.0 -12.8 3.45 3.33 -18.8 -7.62
3 user_latent[1,1] -7.63 -7.63 0.276 0.279 -8.09 -7.19
4 user_latent[1,2] 0.104 0.0799 1.96 1.90 -3.06 3.41
5 user_latent[1,3] 0.121 0.145 2.04 2.09 -3.19 3.45
6 user_latent[1,4] -0.425 -0.414 2.19 2.23 -3.85 3.25
7 user_latent[1,5] 0.0223 0.0984 1.89 1.88 -3.22 3.00
8 user_latent[1,6] -0.211 -0.227 2.16 2.18 -3.77 3.41
9 user_latent[1,7] 0.0615 0.121 1.93 1.92 -3.20 3.15
10 user_latent[1,8] -0.0532 -0.00398 2.31 2.35 -3.85 3.77
# ℹ 18 more rows
# ℹ Use `print(n = ...)` to see more rows
商業志向の映画はマイナス方向ですが、商業志向の映画上位10作品にのみ満点をつけるユーザーの第一次元のスコアは意図通りマイナスの方向に振れ、こちらも元のモデルと整合する結果となりました。
以上より、少なくとも本モデルにおいては本手法の有効性が示されました。ただし、これが全ての因子分析モデルにそのまま適用できるとは限りません。
他モデルで本手法を採用する際は、再現されたパラメータが元のモデルの推定値と十分に一致しているか、事前に妥当性を検証してください。また、今回実施した「商業映画派 vs アート映画派」のような、推定値の挙動を事前に予測できる「極端なダミーデータ」を用いたシミュレーションを事前に行うことを強く推奨します。
結論
本記事では、ベイズ因子分析モデルを「システムとして運用する」ための現実的な解として、既存パラメータを定数として固定し、新規ユーザーのみを部分推定する手法を紹介しました。
この手法は、ベイズ統計学が本来大切にすべき「不確実性の伝播」や「パラメータの同時推定」という大原則を、ある意味で裏切るものです。統計学的厳密さを重んじる方々から見れば、不完全な手法に見えるかもしれません。
しかし、実務の現場が求めているのは、「50倍以上の計算資源を投じて得られる100点の厳密さ」ではなく、「数秒で結果を返し、昨日と今日で基準がブレない80点の安定性」であることもまた事実です。
また、「ベイズの真価は不確実性を定量化できることにある」という言説を耳にしますが、あえて強い言葉で言えば、その認識は時代遅れです。現代のベイズ統計学の本質は、目の前の課題に対して柔軟にモデルを組み上げ、データに潜む構造を鮮やかに可視化するモデリングの自由度にこそあります。その一端を理解するために、ぜひこちらの動画の48分以降を視聴してみてください:
もちろん、この「運用の知恵」がすべての銀の弾丸になるわけではありません。データの分布が劇的に変わる「コンセプトドリフト」が起きれば、定数化したパラメータそのものを見直す(再学習する)必要も出てくるでしょう。
大切なのは、「方法論が解決できる課題を制限するのではなく、解決しなければならない課題があるなら、それに応じた方法を考える」という姿勢です。
この記事が、アカデミアからビジネスの荒波に飛び込み、理想と現実のギャップに悩むデータサイエンティストの皆さんの武器になれば幸いです。
理論を愛しつつも、現場で戦い続けましょう。
最後に、私たちと一緒に働きたい方はぜひ下記のリンクもご確認ください: