はじめに
こんにちは、事業会社で働いているデータサイエンティストです。
最近、おかげさまで社内のとあるデータサイエンスプロダクトが佳境を迎え、実際に営業現場へ提供し、その効果を検証する段階に入りました。
一般的なウェブサービスにおける効果検証であれば、ユーザーをランダムに処置群と統制群に割り付け、いわゆる AB テストを実施するのが標準的でしょう。しかし、営業現場や社内で同様の検証を行おうとすると事情は大きく異なります。仮に社員を完全に処置群と統制群に分けた場合、「なぜ隣の席の A さんには権限が付与されて、自分には付与されないのか。不公平ではないか」といった疑問や不満が生じることは避けられません。
さらに、形式的に処置群と統制群を分けたとしても、統制群に属する B さんが「A さん、この案件を機械学習ツールで少し調べてくれませんか」と依頼したり、ツール導入によって部署全体の雰囲気や業務プロセスが改善されたりすることで、処置の効果が統制群へ波及してしまう可能性があります。これは、処置が他の単位に影響を与えないことを前提とする因果推論の基本仮定である SUTVA(Stable Unit Treatment Value Assumption。詳細は Imbens and Rubin 2015, p.9 以降)を満たさない状況に該当します。
もちろん、利用状況を厳密にモニタリングし、ツールの影響が統制群へ波及しないよう管理することも理論上は可能です。しかし、それには相当な運用コストや社内調整が伴い、現実的とは言い難い場合も少なくありません。
処置対象選定の問題
このように、多くのビジネス課題において、理想的な A/B テストを実施することは容易ではありません。実務でよく見られるのは、「良いツールですね。まずは四国営業部で試してみましょう」といった形で、特定の組織単位が選ばれ、その組織全体が処置群となるケースです。そのため、差分の差分法や関連する合成統制法を用いて、「ツールが導入されなかった場合の四国営業部の売上」という反実仮想を推定し、実際の売上との差分を効果として評価するアプローチが、現実的な選択肢となることが少なくありません。
ただし、ここで重要な論点となるのは、四国営業部がそもそも妥当な処置対象といえるのか、という点です。たとえば、この会社が飲食チェーンで、全国的には売上が右肩上がりで推移している一方、四国エリアだけは高松に日本一号店を置いた、フランス発の競合チェーンの進出によって業績が右肩下がりになっているとします。この場合、四国営業部は全国トレンドとは大きく異なる動きをしていることになり、全国の営業部を組み合わせても、その事前トレンドを十分に再現できない可能性があります。
それでも専務が「四国営業部で導入したい」と判断している場合、分析上は、四国営業部の反実仮想を他地域のデータからどこまで妥当に再現できるのか、そして効果を信頼に足る精度で推定できるのか、という問題に正面から向き合う必要があります。もちろん、ドメイン知識は重要ですが、可能な限りデータドリブンに検証することが望ましいでしょう。
分析の結果、四国営業部の事前トレンドが十分に再現でき、効果も安定的に推定できそうであれば、そのまま検証を進めればよいでしょう。一方で、再現性が低く、効果推定の不確実性が大きいと判断される場合には、その点を経営層に丁寧に報告し、「四国で実施すること自体は可能だが、効果測定の精度が下がる可能性がある」という前提を共有したうえで、進め方を再検討することが望ましいと言えます。
今回の記事で、選定された地域の反実仮想は果たして他の地域で再現できるか、また効果を正しく推定できるかを事前に検証する方法を、あえて上手くいかない状況で紹介します。
事前検証方法
さて、飲食チェーンの話をたくさんしてきましたが、今回の記事ではコロナ禍のデータを利用します。具体的には、このような状況を想像してください。あなたはコロナ禍時の厚生労働省の幹部で、感染防止にとても有効なマスクの存在を知り、これを全国で配ろうと考えていますが、政府の予算は無限ではないため、まずは効果を測定したいということになりました。ちょうど東京都の感染状況がメディアに取り上げられているため、上司から東京で検証しなさいと指示された。さて、東京の反実仮想を、他の都道府県で推定できますか?これは統計学でいうと、検定力分析に近い発想です。
考えはシンプルです。「もし本当に効果があったとしたら、今のデータと手法でその効果を正しく検出できるか?」を、あえてデータを加工して実験してみるのです。
具体的には、以下のステップでシミュレーションを行います。
- 「正解」をあらかじめ作る: 実際の東京都の陽性者数データに対し、ある特定の日以降、意図的に「1日あたり $i$ 人減少した」という偽の処置効果を上書きする
- モデルを回す: その「加工されたデータ」を因果推論用の統計的手法に投入し、東京都の反実仮想を推定させます。答え合わせ: 推定された効果($\hat{\tau}$)が、自分が注入した「正解($-i$)」を正しく捉えているか、そして統計的に有意な差として検出できているかを確認する
- 感度を測る: この $i$ の値を 0 から 1000 まで変化させて繰り返し計算し、「どのくらいの効果量があれば、東京都という特殊なエリアで有意な結果を出せるのか」という境界線を探る
もし、1日1000人の減少という劇的な効果を注入しても「有意差なし」と判定されるのであれば、他道府県のデータでは東京都のトレンドを十分に説明できていない、つまり東京を検証対象に選ぶのは筋が悪いという判断を下すことができます。それでは、実際に R を使って、この「あえて上手くいかないかもしれない検証」を実装してみましょう。
実装
今回の記事では、因果効果を推定する手法として一般化合成統制法(Xu 2017)を用います。
一般化合成統制法の考え方を言葉で説明すると、まず統制群のデータのみを用いて、データの背後にある潜在的なトレンド構造を推定します。ここでは、観測された売上や指標の背後に存在する共通要因や時間的変動パターンを抽出します。
次に、その統制群から推定されたトレンド構造を用いて、処置群の事前期間の動きをできるだけ精度高く再現するような重み(因子負荷)を推定します。この重みを固定したうえで、処置が行われなかった場合に処置群がたどったであろう軌跡、すなわち反実仮想を構築します。
そして、実際の観測値とこの反実仮想との差分を因果効果として評価します。
一般化合成統制法の詳細については下記の記事を参照していただければと思います:
Xu(2017)の論文のp. 63のp. 64に推定用アルゴリズムの説明があります。
まずは、こちらからデータをダウンロードします:
covid_df <- readr::read_csv("newly_confirmed_cases_daily.csv") |>
dplyr::select(!ALL) |>
tidyr::pivot_longer(!Date, names_to = "tdfk", values_to = "count") |>
dplyr::mutate(
Date = as.Date(Date)
)
時間のスパンは:
> covid_df$Date |> min()
[1] "2020-01-16"
> covid_df$Date |> max()
[1] "2023-05-08"
3年くらいあって、ここで東京都の感染者数だけ、2023年4月1日から毎日 1000 人人工的に減らして:
covid_sim_df <- covid_df |>
dplyr::mutate(
treatment = dplyr::case_when(
tdfk == "Tokyo" & Date >= as.Date("2023-04-01") ~ 1,
TRUE ~ 0
),
count = dplyr::case_when(
treatment == 1 ~ count - 1000,
TRUE ~ count
) |>
pmax(0)
)
モデルに入れましょう:
m_covid_gsynth <- gsynth::gsynth(count ~ treatment, data = covid_sim_df,
index = c("tdfk","Date"), force = "two-way",
CV = TRUE, r = c(0, 5), se = TRUE,
inference = "parametric", nboots = 1000,
parallel = FALSE)
まずは可視化で、反実仮想と実数の差分を確認します:
> plot(m_covid_gsynth)
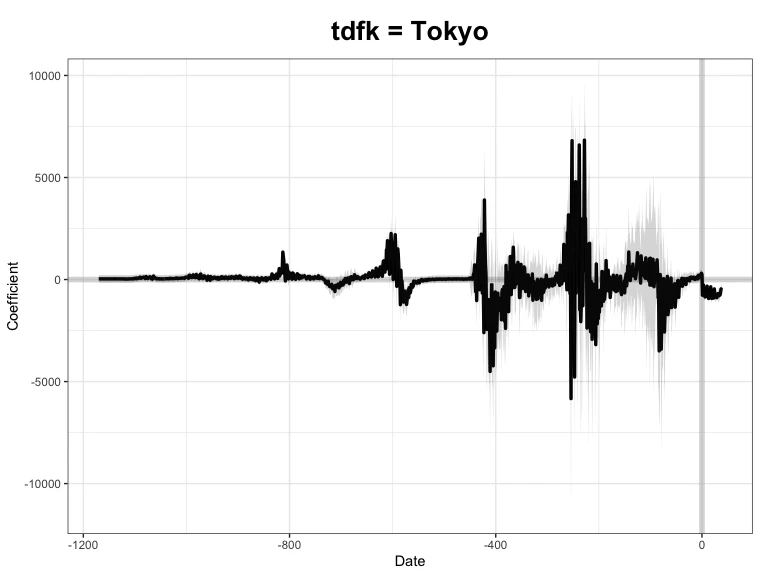
うーん、怪しい傾向が既にありますね、、、
X 軸は、処置開始時点を 0 として標準化した時間を示し、Y 軸は実数から反実仮想の推定値を差し引いた差分を表しています。
負の値の時間は処置開始前の期間を意味します。本来、もし 46 道府県に共通するトレンドのみで東京都の感染者数を十分に再現できているのであれば、処置前のY軸の値はゼロ付近で安定的に推移するはずです。つまり、事前期間において実測値と反実仮想の間に体系的な乖離があってはならない、ということです。
しかし、図から視覚的にも明らかなように、処置前の差分は大きく振れており、安定してゼロ付近に収束していません。これは、東京都が他の道府県とは異なる独自のトレンドを有しており、他地域のデータから十分に再現できていない可能性を示唆します。
したがって、このケースでは、合成統制法や差分の差分法が前提とする、データの裏に共通トレンドが存在する仮定が成立していない可能性が高いと考えられます。
ただ、こちらも視覚的に分かりますが、処置開始後、Y 軸の値が少し減少していて、人工的に感染者数を1000人減らした状況とは整合的です。推定された効果を数字で確認しましょう:
> m_covid_gsynth$est.avg
Estimate S.E. CI.lower CI.upper p.value
ATT.avg -724.925 58.24548 -839.0841 -610.766 0
若干絶対値で見ると低いですね、
最後に、感染者1000人減少ではなく、いろんな現象人数に対してモデルがどう反応するかもシミュレーションで確認しましょう。0 人から 1000 人までの 200 パターンについて見てみます:
future::plan(future::multisession)
sim_results_df <- seq(0, 1000, length.out = 200) |>
furrr::future_map(
\(i){
covid_sim_df <- covid_df |>
dplyr::mutate(
treatment = dplyr::case_when(
tdfk == "Tokyo" & Date >= as.Date("2023-04-01") ~ 1,
TRUE ~ 0
),
count = dplyr::case_when(
treatment == 1 ~ count - i,
TRUE ~ count
) |>
pmax(0)
)
m_covid_gsynth <- gsynth::gsynth(count ~ treatment, data = covid_sim_df,
index = c("tdfk","Date"), force = "two-way",
CV = TRUE, r = c(0, 5), se = TRUE,
inference = "parametric", nboots = 1000,
parallel = FALSE)
m_covid_gsynth$est.avg |>
tibble::as_tibble() |>
dplyr::bind_cols(true_effect = -i)
},
.options = furrr::furrr_options(seed = 1),
.progress = TRUE
) |>
dplyr::bind_rows()
さて、可視化しましょう:
sim_results_df |>
dplyr::mutate(
significant = dplyr::case_when(
CI.lower * CI.upper > 0 ~ "significant",
TRUE ~ "not significant"
)
) |>
ggplot2::ggplot() +
ggplot2::geom_point(ggplot2::aes(x = true_effect, y = Estimate, color = significant)) +
ggplot2::geom_errorbar(ggplot2::aes(x = true_effect, ymin = CI.lower, ymax = CI.upper, color = significant), alpha = 0.3) +
ggplot2::geom_abline(intercept = 0, slope = 1)

以上のシミュレーション結果から明らかなように、少なくとも記事で扱ったコロナのシナリオにおいては、一般化合成統制法による推定値は、真の効果に対して体系的に過小推定となる傾向が確認されました。すなわち、実際の効果よりも小さく見積もられるバイアスが存在する可能性があります。
さらに重要なのは、効果が比較的小さい領域において、効果の符号すら逆転してしまうリスクが観察された点です。これは、真の効果がマイナスであるにもかかわらず、推定上はプラスに見えてしまう可能性を意味します。
したがって、本記事で扱ったコロナ禍のように、各都道府県がそれぞれ固有のトレンドを持ち得る状況では、一般化合成統制法の推定結果をそのまま因果効果として解釈することには慎重であるべきです。実際、コロナ禍においてメディアが「東京都の感染状況」「大阪府の感染拡大」といったように都道府県単位で報道していたのは、地域ごとに異なる動学が存在していたことの表れとも言えるでしょう。
このように単位ごとの独自トレンドが強い場合、他地域のデータを組み合わせても、対象地域の事前トレンドを十分に再現できない可能性があります。その結果、因果効果の推定には構造的なバイアスが入り込むリスクがあります。
だからこそ、本稿で行ったような事前の事前検証(事前期間における再現性の検証やシミュレーション)は重要です。実際に施策を実行してから「推定がうまくいかなかった」と気づくのではなく、実験を走らせる前の段階で問題を検出し、その限界やリスクを意思決定者に共有できることに大きな意義があります。これは単なる技術的検証ではなく、より良い経営判断を支えるためのプロセスでもあるのです。
結論
本記事では、理想的な A/B テストが実施できない状況において、一般化合成統制法を用いて因果効果を推定する際の事前検証の重要性を、あえて上手くいかない可能性のあるコロナ禍のデータを用いて確認しました。
シミュレーションの結果、東京都のように他地域とは異なる固有トレンドを持つ可能性が高いケースでは、
- 事前期間における反実仮想が現実を十分に再現できない
- 効果を体系的に過小推定する傾向がある
- 効果が小さい場合には符号すら誤るリスクがある
といった問題が生じ得ることが分かりました。
これは手法そのものの善し悪しというよりも、その単位が他の単位からどれだけ再現可能かというデータ構造の問題です。コロナ禍において都道府県ごとに報道が分かれていたのは、まさに各地域が独自の動学を持っていたことの表れとも言えます。そのような状況では、他地域を組み合わせて対象地域の反実仮想を精度高く構築すること自体が難しくなります。
重要なのは、施策を実行してから推定結果に一喜一憂するのではなく、実行前にその検証設計がどの程度機能しそうかを確認することです。本記事で示したようなシミュレーションは、「このデータ構造で本当に効果を識別できるのか?」という問いに事前に答えるための実務的なアプローチです。
もし事前検証の段階で再現性が低いことが判明すれば、
- 検証対象の再選定を行う
- 補助的な共変量を追加する
- 効果測定の精度が落ちることを意思決定者に共有する
といった選択肢を検討できます。
因果推論は「結果を出すための魔法」ではありません。むしろ、どの条件なら信頼できる結果が出せるのかを見極めるための枠組みです。その意味で、事前検証は統計的なテクニックであると同時に、組織における健全な意思決定プロセスを支える重要なステップでもあります。
実務において本当に価値があるのは、「効果があった」と言い切ることではなく、
「この設計なら、これくらいの精度で効果を測れます」と事前に説明できることなのだと、私は考えています。
最後に、私たちと一緒に働きたい方はぜひ下記のリンクもご確認ください:
参考文献
Imbens, Guido W., and Donald B. Rubin. Causal inference in statistics, social, and biomedical sciences. Cambridge university press, 2015.
Xu, Yiqing. "Generalized synthetic control method: Causal inference with interactive fixed effects models." Political Analysis 25.1 (2017): 57-76.