はじめに
こんにちは、事業会社で働いているデータサイエンティストです。
この記事は、学会発表に向けて準備している研究の第一報です。
背景として、私は投票行動のパネルデータからアクターのイデオロギーを推定する「理想点推定(ideal point estimation)」に関心を持っており、これまでにもこちらの研究のように、国際関係論の関心と結びつけて国連総会の投票行動を分析してきました。
特徴としては、既存研究のように、議員のイデオロギーが時間と共に変動していくのではなく、活性化される次元(アジェンダ)が時間と共に変動するすることが投票行動の変化を生み出すと仮定する点です。
その過程で、手法に興味を持っていただいた方々から「このモデルをアメリカ議会の投票データに適用するとどうなるのか」という質問を繰り返し受けてきました。また、理想点推定の古典的研究は Poole and Rosenthal(2000)に代表されるようにアメリカ議会分析に根ざしており、この分野にも貢献したいと考え、今回はアメリカ上院の投票データを対象に同様の分析を行いました。
従来の手法では、理想点空間は 1 次元や 2 次元といった、あらかじめ分析者が固定した少数の次元で表現されることが一般的です。これに対して本研究では、ノンパラメトリック・ベイズ手法を用いることで、次元の数そのものと、それぞれの時点における重要度を同時に推定する枠組みを提案します。
モデル全体像
ここでは、本モデルの基本的な考え方と、その背後にある直観を説明します。特に、議員の選好の捉え方、理想点空間の次元構造、そして時間とともに変化する政治的争点の扱いに焦点を当てます。
詳細に入る前に、まず全体像から説明します。
このモデルは、上院議員と投票(法案や動議)をベクトルとして表現し、その内積によって賛成・反対といった投票行動を予測するものです。機械学習に馴染みのある方であれば、「議員に対して法案をレコメンドする協調フィルタリング」と捉えると理解しやすいと思います。
ベクトル化自体は比較的単純ですが、重要なのは「何次元で表現するべきか」、そして「その次元の重要度は時間とともにどう変化するのか」という点です。本研究ではこの問題に対して、各年ごとに「次元の重要度」を表すベクトルを導入することで対応しています。
この「年固有の次元の重要度ベクトル」とは、その時代においてどのタイプの争点がどれだけ重要だったか、を表すものです。
直観的には、議員のイデオロギー自体は比較的安定している一方で、「どの争点が前面に出るか」は時代によって大きく異なります。つまり、観測される投票行動の変化は、議員の選好が変わったというよりも、どの次元が活性化されているかが変化した結果だと考えます。
具体例で考えてみましょう。ある議員が、特定の外交政策や憲法的争点に対して強い立場を持っていたとします。しかし、そのような争点に関する投票がしばらく議題に上らなければ、その次元における選好はデータ上ほとんど観測されません。これは、その議員の立場が中立になったことを意味するわけではなく、単にその次元が「活性化されていない」だけです。
この構造はレコメンドシステムにも類似しています。例えばECサイトで、特定の人気商品が一時的に在庫切れになった場合、ユーザーがそれを選ばなくなります。しかし、それは嗜好が変化したのではなく、単に選択肢が提示されていないだけです。同様に、本モデルでは「選好が変わる」のではなく、「選好にかかる重みが時間とともに変化する」と考えます。
この点で、本研究は Bailey(2007)や Bailey, Strezhnev and Voeten(2017)、Martin and Quinn(2002)といった、理想点そのものが時間とともに変化すると仮定する従来の政治学研究とは異なります。本モデルでは、議員の理想点は時間を通じて安定していると仮定し、その代わりに「どの次元が重要か」が時間とともに変動する枠組みを採用しています。
議員の投票行動
本記事では、上院議員の投票行動を、下記のロジスティック回帰モデルで表す:
$$
賛成_{i,j} \sim Bernoulli(logit(\alpha_i + \beta_j + \sum_{d=1}^{\infty} \left( \theta_{i,d} \cdot \phi_{j,d} \cdot \delta_{t_{j},d} \right)))
$$
ここで、
- $\alpha_i$:議員固有の傾向(賛成しやすさ)
- $\beta_j$:法案固有の通過しやすさ
- $\theta_{i,d}$:議員の理想点(次元 $d$ における位置)
- $\phi_{j,d}$:法案の特性(次元 $d$ における位置)
- $\delta_{t_{j},d}$:時点 $t$ における次元 $d$ の重要度
を表します。この定式化はGopalan, Ruiz, Ranganath and Blei(2014)を参考にしています。
要するに、議員の理想点 $\theta_i$ と法案の特性 $\phi_j$ の内積に、時間ごとに変化する次元の重み $\delta_t$ を掛け合わせることで、投票行動が決定されます。
重要なのは、議員の理想点自体は時間を通じて安定していると仮定する一方で、「どの次元がどれだけ重要か」は時間とともに変化する点である。つまり、観測される投票行動の変化は、議員の選好そのものの変化ではなく、政治的争点の構造(どの次元が前面に出るか)の変化として捉えられます。
このように、本モデルは議員と法案を潜在ベクトルとして表現しつつ、時間ごとに変化する次元の重要度を導入することで、政治的対立構造のダイナミクスを柔軟に捉えることを目的としています。
次は、事前分布の設計に入ります。
事前分布の設計
本研究では、分析者の裁量を最小限にし、なるべくデータドリブンに結果を自動発見できるようにするため、ノンパラメトリック・ベイズを多く利用します。
議員の理想点の事前分布
議員の理想点 $\theta_i$ には、潜在的なクラスタ構造(政治的陣営やタイプ)が存在すると考え、ディリクレ過程に基づく混合モデルを導入します。
ディリクレ過程の詳細については Ghosal and van der Vaar(2017)などの先行文献を参照してください。
まず、全体の集中度パラメータを:
$$
\gamma \sim Gamma(0.001, 0.001)
$$
とし、棒折り過程(stick-breaking)により混合比を生成します:
$$
v_g \sim Beta(1, \gamma)
$$
$$
\pi_g = v_g \prod_{l=1}^{g-1} (1 - v_l)
$$
各クラスタ $g$ の平均ベクトルと分散は:
$$
\mu_g \sim Normal(0, 1)
$$
$$
\sigma_g \sim Gamma(0.001, 0.001)
$$
とします。
各議員 $i$ の理想点は、この混合分布から生成されます:
$$
z_i \sim Categorical(\pi)
$$
$$
\theta_i \sim Normal(\mu_{z_i}, \sigma_{z_i}^2)
$$
この構造により、議員の理想点はいくつかの潜在的なグループ(政治的陣営やタイプ)周辺に分布しますが、完全に同一になることはありません。
次元重要度の定式化
次に、各年における次元の重要度 $\delta_{t}$ を定式化します。
まず初年度 $t=1$ において:
$$
\epsilon \sim Gamma(0.001, 0.001)
$$
$$
u_{1,d} \sim Beta(1, \epsilon)
$$
$$
\delta_{1,d} = u_{1,d} \prod_{l=1}^{d-1} (1 - u_{1,l})
$$
とし、$\delta_{1}$ は棒折り過程で生成された、シンプレックス上のベクトルになります。
次元重要度の経時変化
次に、階層ディリクレ過程を構築する際に登場する階層棒折り過程(Teh, Jordan, Beal, and Blei, 2006)を用いて、年ごとの重要度ベクトルに時間的依存構造を導入します。
まず、変動の強さを制御するパラメータ:
$$
\kappa \sim Gamma(0.001, 0.001)
$$
を導入し、各年 $t > 1$ について:
$$
u_{t,d} \sim Beta\left(
\kappa \cdot \delta_{t-1,d},
\kappa \cdot \left(1 - \sum_{l=1}^{d} \delta_{t-1,l} \right)
\right)
$$
$$
\delta_{t,d} = u_{t,d} \prod_{l=1}^{d-1} (1 - u_{t,l})
$$
とします。これにより、次元の重要度が時間とともに変化することを柔軟に許容しつつ、階層的な棒折り過程によって導入された自己回帰的構造が、前後の年との過度な乖離を抑制します。その結果、推定された次元の連続性が保たれ、解釈可能性の高い分析が可能となります。
直観的な解釈
少し複雑な説明になったのでここで少しまとめます。
この構造により:
- $\theta_i$(議員の理想点)は時間を通じて安定
- $\delta_t$(争点の重要度)は時間とともに変化
という分離が実現されます。
すなわち、
「議員が変わる」のではなく、「何が争点になるかが変わる」
という政治過程をモデル化しています。
モデル実装
実装用のStanコードはこちらです。拡張性を考えて、変数名からあえて政治学色を外し、より汎用的、かつビジネスでも使いやすい user(ここでは上院議員)と item(ここでは法案)にしています。また、重要なQOIの事後分布もサンプリングされます。
functions {
vector stick_breaking(vector breaks){
int length = size(breaks) + 1;
vector[length] result;
result[1] = breaks[1];
real summed = result[1];
for (d in 2:(length - 1)) {
result[d] = (1 - summed) * breaks[d];
summed += result[d];
}
result[length] = 1 - summed;
return result;
}
real entropy(
vector distribution, real threshold
){
vector[size(distribution)] result;
for (i in 1:size(distribution)){
if (distribution[i] < threshold){
result[i] = 0.0;
} else {
result[i] = distribution[i] * log(distribution[i]);
}
}
return -sum(result);
}
real partial_sum_lpmf(
array[] int result,
int start, int end,
array[] int user, array[] int item, array[] int time,
array[] vector dimension_time,
vector user_propensity, vector item_propensity,
array[] vector user_latent, array[] vector item_latent
){
vector[end - start + 1] lambda;
int count = 1;
for (i in start:end){
lambda[count] = bernoulli_logit_lpmf(
result[count] |
user_propensity[user[i]] +
item_propensity[item[i]] +
item_latent[item[i]] '* (user_latent[user[i]] .* dimension_time[time[i]])
);
count += 1;
}
return sum(lambda);
}
}
data {
int dimension_type;
int group_type;
int user_type;
int item_type;
int time_type;
int N;
array[N] int user;
array[N] int item;
array[N] int time;
array[N] int result;
int val_N;
array[val_N] int val_user;
array[val_N] int val_item;
array[val_N] int val_time;
array[val_N] int val_result;
}
parameters {
real<lower=0> dimension_global_alpha;
real<lower=0> dimension_across_time_alpha;
array[time_type] vector<lower=0, upper=1>[dimension_type - 1] dimension_time_breaks;
real<lower=0> group_alpha; // ディリクレ過程の全体のパラメータ
vector<lower=0, upper=1>[group_type - 1] group_breaks; // ディリクレ過程のstick-breaking representationのためのパラメータ
vector<lower=0>[group_type] group_sigma;
array[group_type] vector[dimension_type] group_latent;
vector[user_type] user_propensity_unnormalized;
vector[item_type] item_propensity_unnormalized;
array[user_type] vector[dimension_type] user_latent;
array[item_type] vector[dimension_type] item_latent;
}
transformed parameters {
vector[user_type] user_propensity;
vector[item_type] item_propensity;
array[time_type] simplex[dimension_type] dimension_time;
simplex[group_type] group;
user_propensity = user_propensity_unnormalized - mean(user_propensity_unnormalized);
item_propensity = item_propensity_unnormalized - mean(item_propensity_unnormalized);
for (t in 1:time_type){
dimension_time[t] = stick_breaking(dimension_time_breaks[t]);
}
group = stick_breaking(group_breaks);
}
model {
dimension_global_alpha ~ gamma(0.001, 0.001);
dimension_time_breaks[1] ~ beta(1, dimension_global_alpha);
dimension_across_time_alpha ~ gamma(0.001, 0.001);
for (t in 2:time_type){
for (d in 1:(dimension_type - 1)){
dimension_time_breaks[t, d] ~ beta(dimension_across_time_alpha * dimension_time[t - 1, d], dimension_across_time_alpha * (1 - sum(dimension_time[t - 1, 1:d])));
}
}
group_alpha ~ gamma(0.001, 0.001);
group_breaks ~ beta(1, group_alpha);
user_propensity ~ normal(0, 10);
item_propensity ~ normal(0, 10);
group_sigma ~ gamma(0.001, 0.001);
for (g in 1:group_type){
group_latent[g] ~ normal(0, 1);
}
for (c in 1:user_type){
vector[group_type] case_vector;
for (g in 1:group_type){
case_vector[g] = log(group[g]) + normal_lpdf(user_latent[c] | group_latent[g], group_sigma[g]);
}
target += log_sum_exp(case_vector);
}
for (r in 1:item_type){
item_latent[r] ~ normal(0, 1);
}
int grainsize = 1;
target += reduce_sum(
partial_sum_lupmf, result,
grainsize,
user, item, time,
dimension_time,
user_propensity, item_propensity,
user_latent, item_latent
);
}
generated quantities {
array[dimension_type] real drawn_G;
array[user_type] vector[group_type] estimated_eta;
vector[time_type] entropy_per_time;
array[val_N] int predicted;
real F1_score;
{
int sampled_group = categorical_rng(group);
drawn_G = normal_rng(group_latent[sampled_group], group_sigma[sampled_group]);
}
for (c in 1:user_type){
vector[group_type] case_vector;
for (g in 1:group_type){
case_vector[g] = log(group[g]) + normal_lpdf(user_latent[c] | group_latent[g], group_sigma[g]);
}
estimated_eta[c] = softmax(case_vector);
}
for (i in 1:time_type){
entropy_per_time[i] = entropy(dimension_time[i], 0.00001);
}
for (i in 1:val_N){
predicted[i] = bernoulli_logit_rng(
user_propensity[val_user[i]] +
item_propensity[val_item[i]] +
item_latent[val_item[i]] '* (user_latent[val_user[i]] .* dimension_time[val_time[i]])
);
}
{
int TP = 0;
int FP = 0;
int FN = 0;
for (i in 1:val_N){
if (val_result[i] == 1 && predicted[i] == 1){
TP += 1;
}
else if (val_result[i] == 0 && predicted[i] == 1){
FP += 1;
}
else if (val_result[i] == 1 && predicted[i] == 0){
FN += 1;
}
}
F1_score = (2 * TP) * 1.0/(2 * TP + FP + FN);
}
}
前処理
今回の分析で利用するデータは、こちらからダウンロードできます:
まず、マスターデータを作成する際に利用する関数を用意します:
master_table <- function(df, col) {
col_name <- rlang::as_label(rlang::enquo(col))
id_name <- stringr::str_c(col_name, "_id")
df |>
dplyr::select({{ col }}) |>
dplyr::distinct() |>
dplyr::arrange({{ col }}) |>
dplyr::mutate(
!!id_name := dplyr::row_number()
)
}
次に、データを読み込んで:
vote_raw_df <- readr::read_csv("local_data/Sall_votes.csv")
vote_info_df <- readr::read_csv("local_data/Sall_rollcalls.csv")
senator_info <- readr::read_csv("local_data/Sall_members.csv")
分析に必要な情報を LEFT JOIN で取得するデータフレイムを作成します:
vote_df <- vote_raw_df |>
dplyr::left_join(
vote_info_df |>
dplyr::mutate(
year = lubridate::year(date)
) |>
dplyr::select(congress, rollnumber, year),
by = c("congress", "rollnumber")
) |>
dplyr::mutate(
vote = stringr::str_c(congress, "_", rollnumber)
) |>
dplyr::filter(cast_code %in% c(1, 6))
最後に、マスターデータ作成と ID 付与を実施し:
senator_master <- vote_df |>
master_table(icpsr)
vote_master <- vote_df |>
master_table(vote)
year_master <- vote_df |>
master_table(year)
vote_df_with_id <- vote_df |>
dplyr::left_join(senator_master, by = "icpsr") |>
dplyr::left_join(vote_master, by = "vote") |>
dplyr::left_join(year_master, by = "year") |>
dplyr::mutate(
result = dplyr::case_when(
cast_code == 1 ~ 1,
cast_code == 6 ~ 0,
TRUE ~ NA
)
)
検証データの ID も用意します:
set.seed(1)
val_id <- c(
sample(which(vote_df_with_id$result == 1), 2500),
sample(which(vote_df_with_id$result == 0), 2500)
)
では実際にデータをモデルに投入しましょう。まずはモデルをコンパイルし、変分推論を実施した後に結果をデータフレイムにまとめます:
m_init <- cmdstanr::cmdstan_model("dynamic_dimension.stan",
cpp_options = list(
stan_threads = TRUE
)
)
m_estimate <- m_init$variational(
seed = 2026,
threads = 8,
tol_rel_obj = 0.01,
output_samples = 100,
data = list(
dimension_type = 10,
group_type = 10,
user_type = nrow(senator_master),
item_type = nrow(vote_master),
time_type = nrow(year_master),
N = nrow(vote_df_with_id[-val_id,]),
user = vote_df_with_id$icpsr_id[-val_id],
item = vote_df_with_id$vote_id[-val_id],
time = vote_df_with_id$year_id[-val_id],
result = vote_df_with_id$result[-val_id],
val_N = nrow(vote_df_with_id[val_id,]),
val_user = vote_df_with_id$icpsr_id[val_id],
val_item = vote_df_with_id$vote_id[val_id],
val_time = vote_df_with_id$year_id[val_id],
val_result = vote_df_with_id$result[val_id]
)
)
m_summary <- m_estimate$summary()
変分推論における事後分布のサンプル数が 100 と少ない点に違和感を持つ読者もいるかもしれません。しかし、本モデルは約 7 万のパラメータを含んでおり、Stan のデフォルト設定に従ってサンプル数を 1000 に設定すると、R 側で約 7000 万規模の事後サンプルを扱うことになり、実行時にクラッシュが発生します。なお、本文では触れていませんが、Python と NumPyro を用いた場合でも同様の問題が生じました。
このような計算上の制約を踏まえ、本研究では変分推論の特性、すなわち、MCMC のように大量のサンプルを逐次保持するのではなく、まず分布自体を近似し、その後にサンプリングを行う(Kucukelbir et al., 2017)、を活かし、事後分布からのサンプル数を意図的に最小限に抑えています。
さて、検証データに対する分類精度を F1 スコアで確認しましょう;
> m_summary |>
+ dplyr::filter(stringr::str_detect(variable, "F1"))
# A tibble: 1 × 7
variable mean median sd mad q5 q95
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 F1_score 0.798 0.799 0.00437 0.00489 0.792 0.805
0.8 と統計的に有意な差がないため、賛成・反対の分類性能がかなり優れていると言えます。ではこの高い精度を踏まえて、実際モデルがどのような「アメリカ政治史」を推定したのかを確認しましょう。
イデオロギー次元の可視化
まず、推定された各次元は本当に解釈可能なのでしょうか。例えば、ある次元が他の次元と 1 あるいは -1 に近い強い相関を持っている場合、モデルは実質的に同じ情報を複数の次元に重複して割り当てていることになり、冗長(redundant)な構造を推定している可能性があります。
このような問題が生じていないかを確認するために、まずは上院議員の理想点における各次元間の相関を可視化して検証します:
m_summary |>
dplyr::filter(stringr::str_detect(variable, "user_latent\\[")) |>
dplyr::pull(mean) |>
matrix(ncol = 10) |>
cor() |>
as.data.frame() |>
tibble::tibble() |>
dplyr::mutate(
dimension_1 = dplyr::row_number()
) |>
tidyr::pivot_longer(!dimension_1, names_to = "dimension_2", values_to = "correlation") |>
dplyr::mutate(
dimension_2 = as.integer(stringr::str_remove_all(dimension_2, "V"))
) |>
ggplot2::ggplot() +
ggplot2::geom_tile(ggplot2::aes(x = dimension_1, y = dimension_2, fill = correlation)) +
ggplot2::geom_text(
ggplot2::aes(x = dimension_1, y = dimension_2, label = round(correlation, 2)),
size = 3,
color = "black"
) +
ggplot2::scale_fill_gradient2(
low = "red",
mid = "white",
high = "blue",
midpoint = 0,
limits = c(-1, 1),
name = "Correlation"
) +
ggplot2::scale_x_continuous(breaks = 1:10) +
ggplot2::scale_y_continuous(breaks = 1:10) +
ggplot2::coord_fixed() +
ggplot2::theme_minimal() +
ggplot2::labs(
title = "Latent Dimension Correlations",
x = "Dimension Index",
y = "Dimension Index"
)
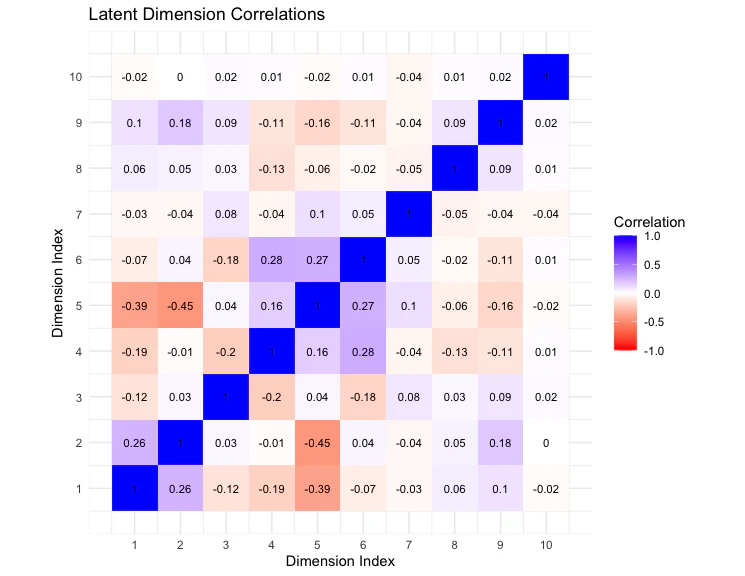
この図からもわかるように、次元同士に相関がある、絶対値で最も高いものでも -0.5 以下のため、モデルは同じ情報を複数の次元に重複して割り当てているわけではないといえます。
では、各次元の重要度($\delta_{t}$)を可視化しましょう。ただし、実際にモデルに利用され、高い重要度を持ったことのある最初の 6 つの次元に限ります。
m_summary |>
dplyr::filter(stringr::str_detect(variable, "dimension_time\\[")) |>
dplyr::mutate(
id = variable |>
purrr::map(
\(x){
as.integer(stringr::str_split(x, "\\[|\\]|,")[[1]][2:3])
}
)
) |>
tidyr::unnest_wider(id, names_sep = "_") |>
dplyr::left_join(
year_master, by = c("id_1" = "year_id")
) |>
dplyr::filter(id_2 %in% 1:6) |>
split(~ id_2) |>
purrr::map(
\(this_df){
this_df |>
ggplot2::ggplot() +
ggplot2::geom_line(ggplot2::aes(x = year, y = mean)) +
ggplot2::geom_ribbon(ggplot2::aes(x = year, ymin = q5, ymax = q95), fill = ggplot2::alpha("blue", 0.3)) +
ggplot2::labs(
title = stringr::str_c("Dimension ", this_df$id_2[1])
) +
ggplot2::ylim(c(0, 1))
}
) |>
do.call(what = gridExtra::grid.arrange, args = _)
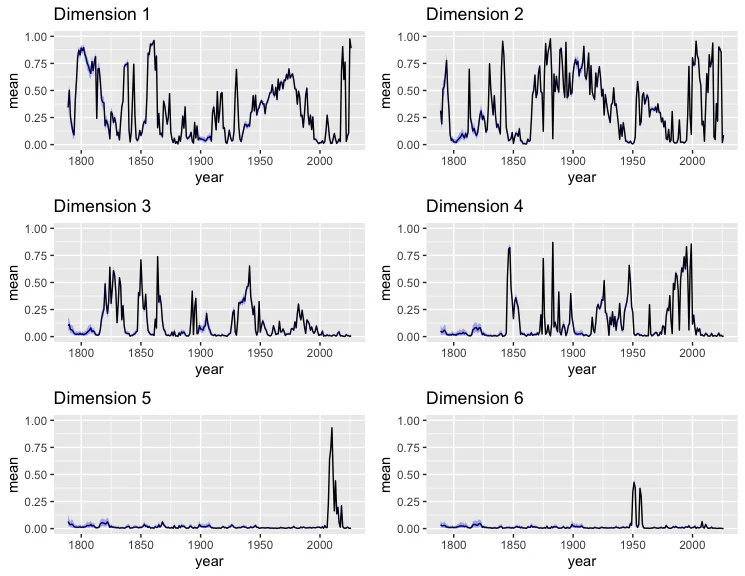
まず、視覚的にこれ単体で見てもなかなか判断がつかないため、まずは各次元の値が最も高い議員と最も低い議員を 10 人ずつ抽出しましょう:
user_latent <- m_summary |>
dplyr::filter(stringr::str_detect(variable, "user_latent\\[")) |>
dplyr::pull(mean) |>
matrix(ncol = 10)
> user_latent |>
+ as.data.frame() |>
+ tibble::tibble() |>
+ dplyr::bind_cols(icpsr = senator_master$icpsr) |>
+ dplyr::left_join(
+ senator_info |>
+ dplyr::select(bioname, icpsr) |>
+ dplyr::distinct(),
+ by = "icpsr"
+ ) |>
+ tidyr::pivot_longer(!c(icpsr, bioname), names_to = "dimension", values_to = "estimate") |>
+ dplyr::filter(dimension %in% stringr::str_c("V", 1:6)) |>
+ split(~ dimension) |>
+ purrr::map(
+ \(this_df){
+ top <- this_df |>
+ dplyr::arrange(-estimate) |>
+ dplyr::slice_head(n = 10)
+
+ bottom <- this_df |>
+ dplyr::arrange(estimate) |>
+ dplyr::slice_head(n = 10)
+
+ top |>
+ dplyr::bind_rows(bottom) |>
+ dplyr::select(bioname) |>
+ `colnames<-`(this_df$dimension[1])
+ }
+ ) |>
+ dplyr::bind_cols()
# A tibble: 20 × 6
V1 V2 V3 V4 V5 V6
<chr> <chr> <chr> <chr> <chr> <chr>
1 WARREN, Elizabeth WARREN, Elizabeth NYE, Gerald Prentice LA FOLLETTE, Robert Marion DeMINT, James W. CONNALLY, Thomas Terry (T…
2 MARKEY, Edward John GILLIBRAND, Kirsten FRAZIER, Lynn Joseph WALLOP, Malcolm COBURN, Thomas Allen HILL, Joseph Lister
3 SANDERS, Bernard CRANE, Winthrop Murray WILLIAMS, John James NORRIS, George William TILLIS, Thomas Roland (Thom) SPARKMAN, John Jackson
4 LEHMAN, Herbert Henry HASTINGS, Daniel Oren SHIPSTEAD, Henrik SYMMS, Steven Douglas CORNYN, John THURMOND, James Strom
5 WYDEN, Ronald Lee TOWNSEND, John Gillis, Jr. KEM, James Preston HILL, Joseph Lister ALLARD, A. Wayne McFARLAND, Ernest William
6 MERKLEY, Jeff BOOKER, Cory Anthony TALMADGE, Herman Eugene FRAZIER, Lynn Joseph INHOFE, James Mountain RUSSELL, Richard Brevard,…
7 HIRONO, Mazie HELMY, George S. TALLMADGE, Nathaniel Pitcher LA FOLLETTE, Robert Marion, Jr. BURR, Richard M. KERR, Robert Samuel
8 MURRAY, Patty BARBOUR, William Warren BROOKHART, Smith Wildman MURKOWSKI, Lisa BARRASSO, John A. HUMPHREYS, Robert
9 KENNEDY, Edward Moore (Ted) HANNA, Marcus Alonzo (Mark) BUTLER, Hugh Alfred BORAH, William Edgar SASSE, Benjamin Eric LONG, Russell Billiu
10 BRISTOW, Joseph Little WHITE, Wallace Humphrey, Jr. RANDOLPH, John WHEELER, Burton Kendall BUNNING, James Paul David LAIRD, William Ramsey, III
11 BANKS, James E. TUBERVILLE, Thomas Hawley (Tommy) CHASE, Dudley PETTIGREW, Richard Franklin BROWN, Sherrod FERGUSON, Homer Samuel
12 EAST, John Porter SIMMONS, James Fowler BRADY, Nicholas Frederick WHERRY, Kenneth Spicer SANDERS, Bernard DIRKSEN, Everett McKinley
13 MOODY, Ashley Brooke SCOTT, Richard Lynn (Rick) CHAFEE, John Hubbard GREENE, Albert Collins CARDIN, Benjamin Louis BRICKER, John William
14 HELMS, Jesse MILLER, Homer Virgil Milton BALDWIN, Roger Sherman VANCE, Zebulon Baird GOODWIN, Carte P. BENNETT, Wallace Foster
15 MORENO, Bernardo (Bernie) McLAURIN, Anselm Joseph McGEE, Gale William HALE, Frederick DURBIN, Richard Joseph MARTIN, Edward
16 TUBERVILLE, Thomas Hawley (Tommy) BATE, William Brimage EVANS, Daniel Jackson ALLEN, William Vincent BURRIS, Roland WILLIAMS, John James
17 BLACKBURN, Marsha HAMILTON, William Thomas WINTHROP, Robert Charles TOWNSEND, John Gillis, Jr. MARKEY, Edward John BREWSTER, Ralph Owen
18 SYMMS, Steven Douglas SCHMITT, Eric Stephen ROBINSON, Joseph Taylor COKE, Richard LEAHY, Patrick Joseph TAFT, Robert Alphonso
19 MCCORMICK, David Harold NAUDAIN, Arnold SEYMOUR, Horatio BRICKER, John William LAUTENBERG, Frank Raleigh COTTON, Norris H.
20 LANKFORD, James BLACK, Hugo Lafayette RODNEY, Daniel UPHAM, William WHITEHOUSE, Sheldon FLANDERS, Ralph Edward
また、各次元に特徴的な法案の単語も併せて分散多項回帰モデル(Taddy 2015)を利用して抽出します。ただし、法案が持つ次元の要素をそのまま使うのではなく、投票が行われた年の次元重要度ベクトルで重み付けた次元の要素を使います:
dimension_time <- m_summary |>
dplyr::filter(stringr::str_detect(variable, "dimension_time\\[")) |>
dplyr::pull(mean) |>
matrix(ncol = 10)
item_latent <- m_summary |>
dplyr::filter(stringr::str_detect(variable, "item_latent\\[")) |>
dplyr::pull(mean) |>
matrix(ncol = 10)
weighted_item_latent <- vote_df_with_id |>
dplyr::select(vote_id, year_id) |>
dplyr::distinct() |>
dplyr::arrange(vote_id) |>
split(~ vote_id) |>
purrr::map(
\(this_df){
item_latent[this_df$vote_id[1],] * dimension_time[this_df$year_id[1],]
},
.progress = TRUE
) |>
do.call(what = rbind, args = _)
dtl_desc_dfm <- vote_master |>
dplyr::left_join(
vote_info_df |>
dplyr::mutate(vote = stringr::str_c(congress, "_", rollnumber)) |>
dplyr::select(vote, dtl_desc),
by = "vote"
) |>
dplyr::pull(dtl_desc) |>
stringr::str_remove_all("[^a-zA-Z ]") |>
quanteda::tokens() |>
quanteda::tokens_remove(quanteda::stopwords()) |>
quanteda::tokens_ngrams(1:2) |>
quanteda::tokens_tolower() |>
quanteda::dfm() |>
quanteda::dfm_trim(min_termfreq = 100)
cl <- parallel::makeCluster(16)
m_dmr_dtl <- distrom::dmr(
covars = weighted_item_latent,
counts = dtl_desc_dfm,
cl = cl,
standardize = FALSE,
verb = TRUE
)
parallel::stopCluster(cl)
> m_dmr_dtl |>
+ coef() |>
+ as.matrix() |>
+ as.data.frame() |>
+ tibble::rownames_to_column(var = "dimension") |>
+ tibble::tibble() |>
+ tidyr::pivot_longer(!dimension, names_to = "vocab") |>
+ dplyr::filter(dimension != "intercept" & dimension %in% c(1:6)) |>
+ split(~ dimension) |>
+ purrr::map(
+ \(df){
+ df |>
+ dplyr::mutate(
+ value = abs(value)
+ ) |>
+ dplyr::arrange(-value) |>
+ dplyr::select(vocab) |>
+ dplyr::slice_head(n = 20)
+ }
+ ) |>
+ dplyr::bind_cols() |>
+ `colnames<-`(stringr::str_c("dimension_", 1:6)) |>
+ print(n = 20)
New names:
• `vocab` -> `vocab...1`
• `vocab` -> `vocab...2`
• `vocab` -> `vocab...3`
• `vocab` -> `vocab...4`
• `vocab` -> `vocab...5`
• `vocab` -> `vocab...6`
# A tibble: 20 × 6
dimension_1 dimension_2 dimension_3 dimension_4 dimension_5 dimension_6
<chr> <chr> <chr> <chr> <chr> <chr>
1 table_helms r_reducing amend_hjres invoke_cloture question hr_appropriations
2 allen_amendment substitute_h ordering_engrossment substitute_h trial nay_supports
3 allen reducing_duty ordering invoke first_monday nay
4 invoke_cloture amend_substitute increasing_duty table_helms constitution williams
5 rc_s increasing_duty amendment_proposes registration mr barring
6 invoke cent_ad amend_hj iron_steel counsel motion_recommit
7 cloture iron_steel color thurmond oclock yea_supports
8 metzenbaum census hr_adding reducing_duty sjres appeal_decision
9 rejected_nay session_p admission amend_substitute consider_s yea
10 nay_supports adjourn_p consenting sergeantatarms_request states_p rejected_nay
11 adjourn_p steel import senate_tabled defense dept
12 panama_canal consent_appointment reading_hr cloture bonds hr_committee
13 kennedy_amendment r_increasing admitted tabled adopt s_amend
14 harbor discussion engrossment increasing_duty s mc
15 nay per_cent table_hr bumpers res farm
16 table_sen valorem_p hereafter amendment_express resolution hr_passage
17 helms r_eliminating pass_h accounts establish appeal
18 kansas amend_amendment proposes amendment_prohibit select resources
19 insist amend_committee material law_enforcement committee decision_chair
20 p_p iron table_helms prevention senate maintenance
ここからは、各次元がどのような意味を持っているのかを、議員と法案テキストの両方から解釈していきます。やっていることはシンプルで、「その次元で極端な位置にいる議員は誰か」と「その次元で特徴的な法案は何か」を対応づけて読む、という作業です。アメリカ政治に詳しくないこともあり、この解釈はまだ暫定的なものです。私自身の専攻文献の調査だけでなく、他の研究者と学会などの場での意見交換も活用しながら、よりブラッシュアップする予定です。
第 1 次元:現代的イデオロギーと政党対立
第 1 次元で極端な値を持つ議員には、Elizabeth Warren、Edward Markey、Bernard Sanders といったリベラル派の重鎮と、Jesse Helms や Marsha Blackburn といった保守派の代表格が並んでいます。語彙に目を向けると、cloture(討論終結)や table_helms(ヘルムズ議員の修正案を棚上げする動議)といった現代的な手続きに関する語が目立ちます。これは、20世紀後半から現代に至る、あらゆるイデオロギーが政党軸に集約された「分極化」の構造を捉えた主次元であると解釈できます。
第 2 次元:産業保護と関税政策
第 2 次元の特徴は、語彙に顕著に現れています。reducing_duty、increasing_duty、iron_steel、valorem_p(従価税)といった、関税と特定の産業(鉄鋼)に関連する単語が上位を占めています。19 世紀から 20 世紀初頭にかけて、アメリカ上院における最大の経済的争点は、北部の工業保護のための高関税か、南部の農業輸出のための自由貿易かという点にありました。この次元は、政党軸とは別の「経済的利害」に基づいた対立軸を抽出しています。また、この次元が 21 世紀から再び重要度の高まりを見せたのも、アメリカの保護主義への回転を示しているといえよう。
第3次元:地理的「辺境」と中央の対立
第3次元の語彙には、建国期の admission(州の昇格)やcolor(奴隷制に関連する人種概念)が含まれる一方で、Gerald Nye や Lynn Frazier といった20世紀中盤の議員が抽出されています。19世紀、この次元は「どの地域が合衆国の地図に加わるか」という実存的な問いを扱っていました。admissionという語彙はこの時期の遺産です。しかし、州の加入が一段落した後も、この次元は「農村・辺境(Periphery)」と「都市・中央(Center)」の対立として生き残ったと思われます。北ダコタ州選出の Nye や Frazier がこの次元で極端な値を持つのは、彼らが東部の金融資本や国際介入に反対する農本主義的な孤立主義を代表していたためです。よって、政党の枠を超えた「地域的な独立性」を測定する指標として機能したと解釈できる。しかし、2000 年前後を境に、地域的な利害(農村か都市か)が完全に政党(共和党か民主党か)と一致する「Big Sort」が起きたことで、独自の対立軸としての重みを失い、イデオロギーの対立を表す第 1 次元へと吸収されていったと理解できる。
第 4 次元:制度的「拒否権」と少数派の権利
初期のこの次元は、人種問題とそれに対する南部の抵抗を明確に捉えています。thurmond(人種隔離政策の支持者James Strom Thurmond)という固有名詞や registration(登録)がその象徴です。より重要なのは、語彙に含まれるinvoke_cloture(討論終結の動議)です。公民権運動の時代、南部議員はフィリバスター(議事妨害)を武器に戦いました。
第 5 次元:憲法主義と反主流派の台頭
第5次元で最も高い値を示すのは、James DeMint や Tom Coburn といった「ティーパーティー運動」を主導した議員たちです。語彙には question、trial、constitution、counsel といった、司法手続きや憲法解釈に関連する言葉が並びます。これは 2010 年前後に顕著となった、財政保守主義に加えて「憲法への回帰」を掲げて主流派に挑戦した、手続き的・司法的な反乱の次元であると解釈できます。
私の以前の研究でも、同様の次元を発見できたため、これはある程度データ量とモデル定式化にロバスト性のある結果であるとといえよう。
第6次元:委員会政治と南部長老派
第 6 次元の上位には、Richard Russell や John Sparkman といった、委員長ポストを長年独占した南部の実力者(Southern Barons)が並びます。語彙も hr_appropriations(歳出法案)、motion_recommit(委員会差し戻し動議)、dept(各省庁)など、具体的な予算配分と委員会の権限に関連するものが支配的です。
結論
本研究では、アメリカ上院の投票データを対象に、理想点そのものではなく「争点の重要度」が時間とともに変化するという視点から、政治的対立構造のダイナミクスを捉える新たな枠組みを提案しました。ノンパラメトリック・ベイズ手法を用いることで、次元数を事前に固定することなく、データから自動的にイデオロギー空間の構造を抽出し、その重要度の変遷を柔軟に推定できる点が本モデルの特徴です。
実証分析の結果、従来の研究でも指摘されてきた政党間対立に加え、地域的対立や制度的権力、さらには特定の歴史的文脈に依存した争点が、時代ごとに異なる強度で現れる様子が確認されました。特に重要なのは、これらの変化を「議員の選好の変化」としてではなく、「どの争点が前面化するか」という構造的変化として一貫して説明できる点にあります。
また、約 0.8 という高い F1 スコアが示すように、本モデルは単なる解釈的枠組みにとどまらず、実際の投票行動の予測においても高い性能を持つことが確認されました。これは、政治学的な理論と機械学習的な予測性能の両立が可能であることを示唆しています。
今後の課題としては、各次元の解釈をさらに精緻化することに加え、下院データや他国の議会データへの適用、さらには国連総会データとの比較分析などを通じて、本モデルの外的妥当性を検証していく必要があります。
本稿はあくまで第一報であり、分析・解釈ともに発展途上にありますが、「次元が変わるのではなく、次元の重要度が変わる」という視点は、政治過程の理解に新たな示唆を与える可能性があります。今後、学会での議論や他研究者との対話を通じて、この枠組みをさらに洗練させていきたいと考えています。
最後に、私たちと一緒に働きたい方はぜひ下記のリンクもご確認ください:
参考文献
Bailey, Michael A. "Comparable preference estimates across time and institutions for the court, congress, and presidency." American Journal of Political Science 51.3 (2007): 433-448.
Bailey, Michael A., Anton Strezhnev, and Erik Voeten. "Estimating dynamic state preferences from United Nations voting data." Journal of Conflict Resolution 61.2 (2017): 430-456.
Ghosal, Subhashis, and Aad W. van der Vaart. Fundamentals of nonparametric Bayesian inference. Vol. 44. Cambridge University Press, 2017.
Gopalan, Prem, Francisco J. R. Ruiz, Rajesh Ranganath and David M. Blei. "Bayesian nonparametric poisson factorization for recommendation systems." Artificial Intelligence and Statistics. PMLR, 2014.
Kucukelbir, Alp, Dustin Tran, Rajesh Ranganath, Andrew Gelman, David M. Blei. "Automatic differentiation variational inference." Journal of machine learning research 18.14 (2017): 1-45.
Martin, Andrew D., and Kevin M. Quinn. "Dynamic ideal point estimation via Markov chain Monte Carlo for the US Supreme Court, 1953–1999." Political analysis 10.2 (2002): 134-153.
Matt Taddy "Distributed multinomial regression," The Annals of Applied Statistics 9.3 (2015): 1394-1414.
Poole, Keith T., and Howard Rosenthal. Congress: A political-economic history of roll call voting. Oxford University Press, USA, 2000.
Teh, Yee Whye, Michael I. Jordan, Matthew J. Beal, and David M. Blei. "Hierarchical Dirichlet processes." Journal of the American Statistical Association 101.476 (2006): 1566-1581.