初心者の私がインターン先企業の顧客対応のチャットボットを作ってみたものとなります。新しい技術について書かれているものではありませんが、工夫した点等をメインにして成果をまとめてみたいと思います。初投稿で初心者丸出しですが、何卒よろしくお願いいたします。このチャットボットの作成には以下の2つの記事とGitHubのリポジトリを大いに参考にさせていただきました。RAGを最初から丁寧に理解して実装したいという方はこれらの記事をしっかり読んでいただけたら良いのかなと存じます。
[Azure] OpenAI Service で AI チャットボットを作ってみよう
Azure OpenAI ServiceによるRAG実装ガイドを公開しました
サイオステクノロジー武井さんが提供されているGitHubのリポジトリ
この記事の目次
- リポジトリの全体構成
- 利用したAzureのサービス
2.1. Azure OpenAIの利用
2.2. RAGのインデックス登録
2.3. Azure AI Searchの利用
2.4. Azure Web Serviceの利用
2.5. DBとの連携
2.6. Azure Functionsの利用
2.7. Azureのコスト - コーディング
3.1. フロントエンド
3.2. バックエンド : 一連の会話を行う
3.3. バックエンド : 価格シミュレーター - 終わりに
1. リポジトリの全体構成
こちらがGitHubのリポジトリになります。色々と粗はあるのですが、参考になれば幸いです。
2. 利用したAzureのサービス
今回は参考にしたものがAzureをがっつり利用していたのでそれに倣い、私もAzureを利用しました。利用したサービスは以下のとおりです。
- Azure OpenAI
- Azure AI Search
- Document Intelligence
- Cosmos DB
- 関数アプリ
- Azure App Service
2.1. Azure OpenAIの利用
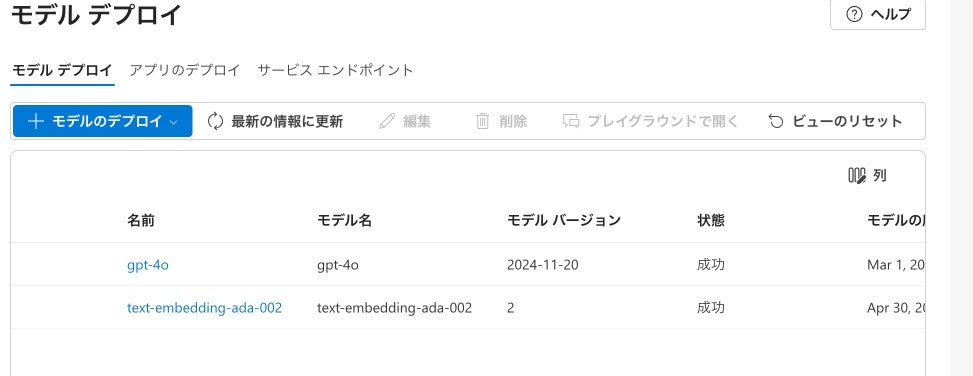
今回はLLMとしてgpt-4o, 埋め込みベクトル作成のためにtext-embedding-ada-002を利用しました。gpt-4oは複雑な問いにも正確に応答できるよう、回答精度の高さとコストを比較して、text-embedding-ada-002は既存のドキュメントの埋め込みベクトル化において、処理速度とコスト効率のバランスが優れているため採用しました。
2.2. Azure AI Search の利用
RAGにおいてはAI Searchは非常に重要な役割を果たします。というのもクエリをもとに情報源からどの情報が相応しいかを選択してLLMに渡す装置であるからです。今回はセマンティック・ハイブリッド検索という手法を選択しました。セマンティック・ハイブリッド検索は以下3つの検索方法を行うものです。セマンティックの有無による検索結果の違いについては後で後述します。
- 全文検索
- ベクトル検索
- セマンティック検索
インデクサーとインデックスの登録
この検索対象を作るためには情報源を適切な形でクラウドに格納する必要があります。今回はローカルにインデクサーを用意してクライアントを作成して、AI Searchにインデックスを格納しました。今回格納する情報の種類を以下に示します。
| インデックス名 | doc_type | 情報の種類について |
|---|---|---|
hpcontents |
--- | pdfファイル |
aistidea |
page_section_markdown |
HPに記載されている文章 |
aistidea |
fact_card |
会社の住所などの固定情報 |
aistidea |
faq_pair |
よくある質問のようなFAQ |
大きく分けて二つあり、ホームページの内容がhpcontentと、ホームページ中にリンクとして貼り付けられている約款等のpdfファイルはaistideaに格納しました。さらにhpcontentにはdoc_typeが3種類あります。情報を複数の種類に分けることで、検索の速度や正確性が向上すると考えています。
こちらはhpcontentsインデックス中のmarkdown_sections, faq_pair, fact_cardのdoc_typeのフィールド一覧になります。○はそのフィールに値が入ること(doc_typeは具体的な名前を記載している)を示し、空欄はNoneになることを示しています。
| フィールド | 型 / 属性 | 役割・使い方 | markdown_sections | faq_pair | fact_card |
|---|---|---|---|---|---|
id |
Edm.String, key
|
一意ID(sourceId#type#seq など) |
○ | ○ | ○ |
doc_type |
Edm.String, filterable/facetable
|
page_section_markdown / faq_pair / fact_card
|
markdown_sections |
faq_pair |
fact_card |
sourceId |
Edm.String, filterable
|
同一ページ/ドキュメント束ね用。ページ単位の親IDであり、一意にページを識別するラベル | ○ | ○ | ○ |
url |
Edm.String, retrievable
|
出典表示・重複検知 | ○ | ○ | ○ |
lang |
Edm.String, filterable/facetable
|
言語ルーティング(ja等) |
○ | ○ | ○ |
title |
Edm.String, searchable
|
見出し(BM25高重み) | ○ | ○ | ○ |
headingPath |
Collection(Edm.String), filterable/facetable
|
パンくず・絞り込み。ページ内の位置 | ○ | ||
content |
Edm.String, searchable
|
表示/引用用本文(下記の連結文字列) | ○ | ○ | ○ |
contentVector |
Collection(Single), vector
|
埋め込み(content用) |
○ | ○ | |
| 埋め込みいる? | ○ | ○ | |||
chunkIndex |
Edm.Int32, filterable/sortable
|
チャンク順 | ○ | ○ | ○ |
faqQuestion |
Edm.String, searchable
|
FAQの質問(ない場合は空) | ○ | ||
faqAnswer |
Edm.String, searchable
|
FAQの答え(Markdown可、ない場合は空) | ○ | ||
faqTags |
Collection(Edm.String), filterable/facetable
|
タグ(ない場合は空配列) | ○ | ||
factSubject |
Edm.String, searchable/filterable
|
主語(製品名等) | ○ | ||
factPredicate |
Edm.String, filterable/facetable
|
述語(latest_version等) |
○ | ||
factValue |
Edm.String, searchable
|
値(表示用) | ○ | ||
factValueNum |
Edm.Double, filterable/sortable
|
数値クエリ用 | ○ | ||
asOfDate |
Edm.DateTimeOffset, filterable/sortable
|
“いつ時点” | ○ | ||
docCreatedAt |
Edm.DateTimeOffset, filterable/sortable
|
取り込み時刻等 | ○ | ○ | ○ |
これらの情報はdata>HP_contentdataの中にファイルを分けて格納しています(リポジトリ中には著作権を考慮して少量のダミーしか格納されていません)。scripts>indexer_HP.pyを使用することでこれらのファイルをAI Searchにインデックスとして格納することができます。
aistideaインデックスは1つのpdfからのインデックス登録ということもあり、もっとシンプルなフィールドでインデックスに格納することとしました。(著作権を考慮して現状のリポジトリは空ですが)データはdata>pdfの中に格納し、scripts>indexer_pdf.pyを使用することでこれらのファイルをAI Searchにインデックスとして格納することができます。以下が上記の情報を格納した結果になります。
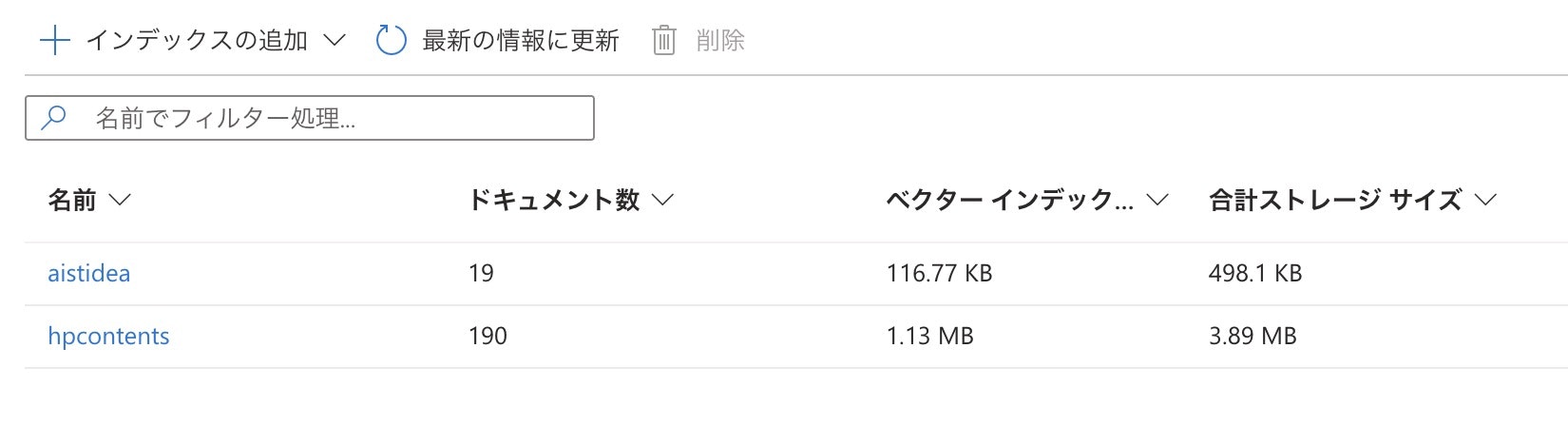
AI Searchはプランによって作成できるインデックスの数等に制限があるため、ご自身のプランに沿ったインデックスの設定が重要かと思います。
セマンティック検索 vs ノンセマティック検索
とある質問Aに対するノンセマンティック検索(ハイブリッド検索だけ)の検索結果
titleおよびcontent(本文)は隠しております。
| ID | doc_type | title | content(本文) | @search.score |
|---|---|---|---|---|
| 14 | faq_pair |
--- | --- | 0.03333 |
| 3 | faq_pair |
--- | --- | 0.03278 |
| 9 | faq_pair |
--- | --- | 0.03128 |
| 108 | fact_card |
--- | --- | 0.03333 |
| 146 | fact_card |
--- | --- | 0.03225 |
| 112 | fact_card |
--- | --- | 0.03088 |
| 49 | page_section_markdown |
--- | --- | 0.03333 |
| 80 | page_section_markdown |
--- | --- | 0.03252 |
| 43 | page_section_markdown |
--- | --- | 0.032 |
とある質問Aに対するセマンティック検索(セマンティックハイブリッド検索)の検索結果
| ID | doc_type | title | content(本文) | @search.score | @search.reranker_score |
|---|---|---|---|---|---|
| 3 | faq_pair |
--- | --- | 0.03278 | 2.453 |
| 9 | faq_pair |
--- | --- | 0.03128 | 2.238 |
| 14 | faq_pair |
--- | --- | 0.03333 | 2.004 |
| 108 | fact_card |
--- | --- | 0.03333 | 2.431 |
| 134 | fact_card |
--- | --- | 0.0147 | 2.163 |
| 112 | fact_card |
--- | --- | 0.02938 | 1.962 |
| 49 | page_section_markdown |
--- | --- | 0.3333 | 2.691 |
| 65 | page_section_markdown |
--- | --- | 0.01562 | 2.6 |
| 67 | page_section_markdown |
--- | --- | 0.01639 | 2.572 |
ノンセマンティック検索で選ばれた各情報源のseacrh scoreのばらつきはかなり小さいことがわかります。一方で、セマンティック検索で各情報源のseacrh reranker scoreはばらつきがあります。そして今回の質問Aを回答するにあたり重要な情報源のIDは14, 3, 49です。ノンセマンティック検索もセマンティック検索もともにこれらの3つの情報源を含むものの、最重要情報源である49に関してセマンティック検索が最高値のseacrh reranker scoreを与えたことは評価できるように思われます。また、別の質問でも同様の比較を行ったのだが、短めの情報源(今回でいうところのhpcontentsのインデックスの情報)よりもpdf文章をチャンクに分けたような長めの情報源(今回でいうところのaistideaのインデックスの情報)においてセマンティック検索のrerank能力が反映されたように感じました。ただ総じて検索結果そのものが大差あるわけではない、つまりノンセマンティック検索でもある程度回答ができるため費用と相談をしてどちらにするのかを決めた方がいいように思います。セマンティック検索をするためにはAI Searchを無料版から基本版にする必要があり、個人開発ではこちらの費用は決して安くないためです。
2.3. DBとの連携
チャットボットのセッション管理において、ユーザーとの会話履歴を最新の質問と合わせてLLMに送る設計しました。この目的のため、同じブラウザからの利用で、最終質問から5分以内の会話を一つの独立したセッションとして定義しDBにて保存するようにし、そして5分を超えると新しいセッションとして扱わるようにしました。Cookieの利用も検討しましたが、今回はセッションの識別のためだけの利用となることからユーザー保護の観点で煩わしいCookieの利用は見送ることにしました。その代わりもっと単純に、フロントエンドからのhttpリクエストのヘッダーからセッションIDの有無とセッションIDを入手してDBから当該レコードを検索して会話履歴を取得するという流れを採用しました。
# DBに以下のものを格納する
{
"id": session_id,
"session_id": session_id,
"active": True, #ここがFalseの場合そのセッションはそれ以上更新されず、新しいセッションが作られる
"issued_at": now.isoformat(),
"last_seen_at": now.isoformat(),
"expires_at": (now + SOFT_TTL).isoformat(),
"history": [] # ここに会話履歴を追加していく
}
2.4. 関数アプリの利用
Python v2 モデルでは、1つの FunctionApp オブジェクトに、デコレータで“関数”を登録していく形式になっています。関数を記述したバックエンドのpythonファイルだけでなく、関数アプリ全体(ホスト)” の挙動を決めるJSONファイルと必要なライブラリ環境を記述したtxtファイルも一緒に関数アプリへ渡してあげる必要があります。
├── function_app.py # ここで app = func.FunctionApp() を作り、関数を登録
├── host.json # 関数アプリ全体(ホスト)” の挙動を決める設定ファイル
├── requirements.txt
└── (任意の) モジュール群
ランタイムはプロジェクト直下の function_app.py を探し、その中で作成した app = func.FunctionApp() に対して@app.function_name(...) などのデコレータで登録された関数が、起動時に自動認識されます。
@app.function_name(name="GenerateAnswerWithAOAI_2")
このnameがポータルやログに表示される“関数名”になり、デプロイ後「関数一覧」にこの名前が出てくれば、ランタイムが関数を無事に認識したということになります。
@app.route(route="GenerateAnswerWithAOAI_2", auth_level=func.AuthLevel.ANONYMOUS)
def GenerateAnswerWithAOAI_2(req: func.HttpRequest) -> func.HttpResponse:
...
@app.route で HTTP トリガーを定義してrouteでURLパスをauth_levelで認証レベルを指定します。今回は社外の方が問い合わせるということを想定して誰でもアクセスできるfunc.AuthLevel.ANONYMOUSを採用しました。
2.5. Azure App Serviceの利用
フロントエンド部分のデプロイ先としてApp Serviceを使用しました。無料版では開発者ツールが使えず、エラーの要因を特定できなかったので(なかなかデプロイがうまくいかなかった、、)今回は少し高いプランであるBasicを採用しました。
2.6. Azureの1ヶ月のコスト(円)
| サービス | コスト | 詳細 |
|---|---|---|
| OpenAI | 671 | 概算だが200往復の会話を実行 |
| AI Search | 14178 | セマンティックができるプランだと高額 |
| App Service (フロントエンド) | 2022 | これもBasicプランなので高くなっている |
| Cosmos DB | 0.48 | --- |
| App Service (関数) | 1540 | --- |
コストに関してあまり深く考えずにした結果およそ18000/月という出費になってしまいました。内訳を見てみると、AI Searchがやはり高いです。セマンティック検索の必要性が薄い場合、これをAI Searchを無料版にしてノンセマンティック検索で頑張るというのも手だと思います。また、私は開発者ツールでエラーの元を特定したいという思いからApp Service (フロントエンドの実行環境)をBasicにしたがこちらもダウングレードの余地は大いにあるかと思います。Azureでちゃんとサービスを運用するならコストに関してもっと理解を深め繊細にならねばと身に沁みて感じました。
3. コーディング
全体像のツリー図
3.1. フロントエンド
フロントエンドは Zenn の[Azure] OpenAI Service で AI チャットボットを作ってみようをベースに Streamlit で実装しつつ、会話ごとにセッションIDを付与して履歴を分離しています。初回の会話開始時は st.session_state["lec_session_id"] が None のため、ヘッダにセッションIDを付けずに Azure Functions へ POST します。Functions 側は新しいセッションIDを発行して Cosmos DB に対応する履歴ドキュメントを作成し、その ID をレスポンスヘッダ x-session-id(または JSON)で返します。クライアントは _apply_session_from_response() でこの ID を st.session_state["lec_session_id"] に保存します。
2回目以降のやり取りでは、保存したセッションIDをヘッダ x-session-id に付けて送信します。サーバは受け取ったIDで Cosmos DB の履歴を読み出し、TTL を延長しつつ、蓄積された履歴を踏まえて応答を生成します。もしセッションの有効期限が切れている、あるいは何らかの理由で新規発行が必要な場合は、サーバ側で新しいセッションIDを払い出し、再びヘッダで返却します。クライアントは受け取った新IDでローカルの session_state を上書きし、以降はそのIDで会話を継続します。
補足として、Streamlit の session_state はブラウザのタブ単位で独立しているため、タブごとに別のセッションID・会話履歴が維持されます。また、フロントからレスポンスヘッダの x-session-id を読めるように、サーバは Access-Control-Expose-Headers: x-session-id を返す前提です。全体として、「初回はIDなし → サーバが発行 → 以降はヘッダで提示 → TTL延長 → 失効時は再発行」というシンプルな流れでセッション管理を実現しています。
3.2. バックエンド
backend/appの中に各機能を実装した.pyファイルが存在してこれらをbackend/fuction_app.pyが活用して関数を定義していると言う構造になっています。user_dict.csvは質問の正規化において活用するものになっています。
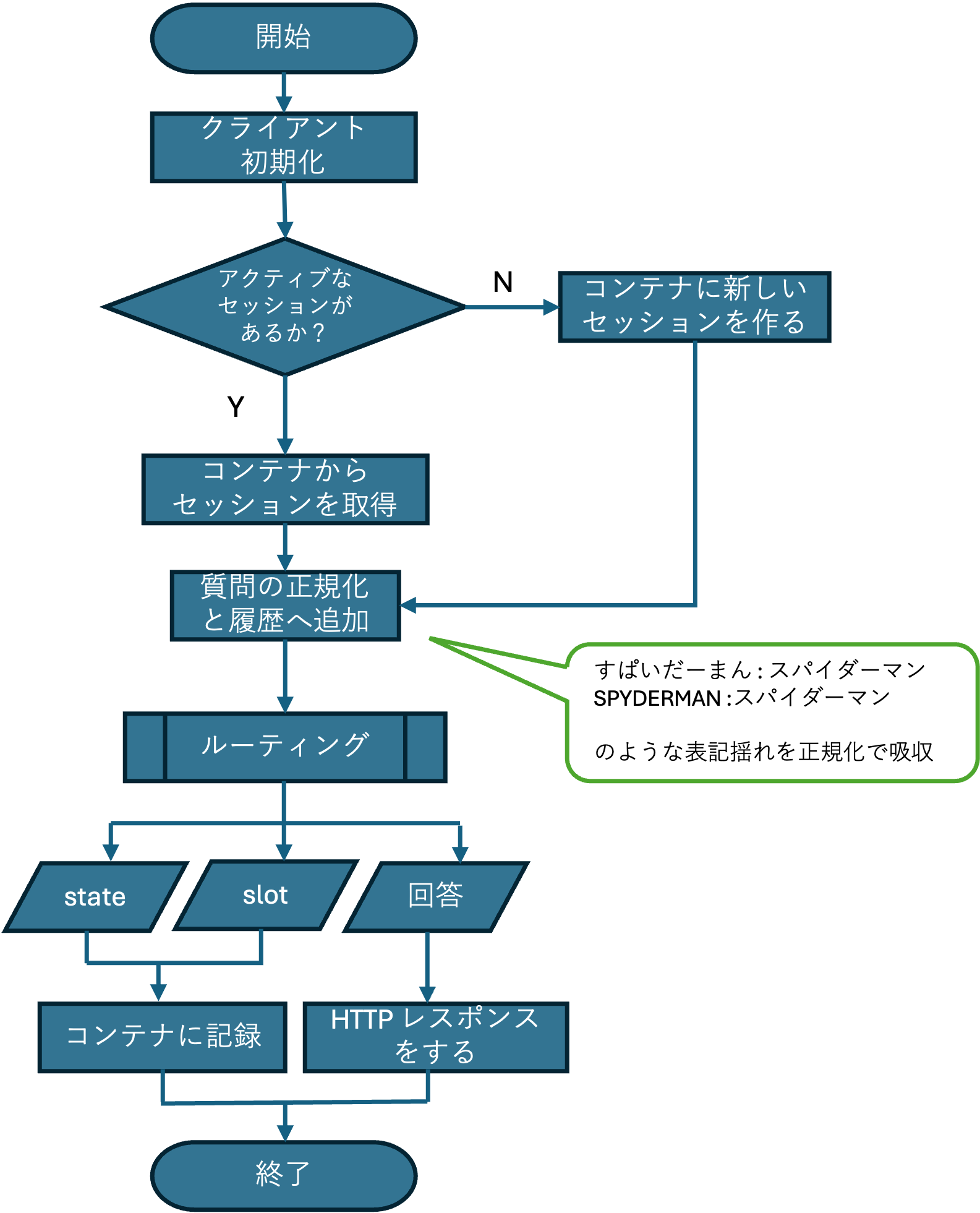
フロントエンドよりユーザーによりインプットした質問文がHTTP POSTされた時にこの関数は始動します。まずはOpenAI, AI Search, Cosmos DBなどのAzureの各サービスのクライアントが初期化されます。ユーザーの質問に会話の履歴を加えてOpen AIに送るので、各セッションの履歴を独立して保存する必要が生じます。そこで、各ブラウザからの一定時間以内のアクセスを同一セッションと仮定して、セッションを管理することとしました。今回は違うブラウザからのアクセスや、リロードや、最後の会話から5分以上経った場合は別のセッションとして扱い、コンテナに新規でセッションを作ることにしました。
次に質問を正規化して、履歴がある場合はこれに追加します。質問の正規化とは図中のように表記揺れを吸収するような実装になります。このようにして得た履歴つきの質問をルーティングに通して、回答とstate, slotを得るという流れになります。stateとslotは価格のシミュレーションに必要なものです。
私が最も工夫した点は価格シミュレータを実装したところになります。私がインターンをしていた企業ではデータベースやソフトウェアの料金体系がややこしく、ここに関しての問い合わせ対等に時間がかかっていました。料金体系をそのままインデックスに入れただけで、RAGがそれを活用して正しく見積もりすると言うことは希望的観測であり、期待しないほうがいいと思います。そこで、見積もりに必要な情報をslotと言う形でまとめ、そのslotの情報を1つ1つ入手していく段階を認識する術としてstateを導入しました。回答のみをHTTPレスポンスに含めて、stateとslotはユーザーに直接見せる必要がないため、こちらには含めず、コンテナに記録します。
3.2.1 ルーティング (価格シミュレータ部分)
 終了マークをつけそびれていた、、、
終了マークをつけそびれていた、、、
最初LLMに質問を分析してもらい、見るべきインデックスと全文検索で必要になってくるクエリとタスクタイプを決定してもらいます。それぞれについて少しだけ説明をすると、今回はインデックスを一般的な会社やサービスにまつわる情報(ホームページの情報)と約款などが記載されている細かめな情報(主にPDF)の二つに分けました。質問の内容から見るべきインデックスをまずは決定してもらいます。次のクエリの生成ですが、これは全文検索の時に使うワードをいくつか作ってもらうと言うものです。3つ目のタスクタイプが今回の肝になります。一般的な質問の他に、価格の見積もりをすることができる機能を今回実装しました。価格の見積もりには様々な情報が必要となってきます。このような必要となる情報をslotで管理して、今どの情報を尋ねているのかを認識するためにstateで状態を把握するように設計しました。
slotとstateに関しては以下のように設計しました。
slots = {"purpose": None, "software": None, "affiliation": None, "database_license_count": None, "software_license_count": None}
class State:
INITIAL = "initial"
ASKING_PURPOSE = "asking_purpose"
ASKING_MiLCA = "asking_software"
ASKING_AFFILIATION = "asking_affiliation"
ASKING_LICENSE_COUNT = "asking_license_count"
INFO_GATHERED = "info_gathered"
これにより、確実に情報を取得しながら見積もりを前に進めると言うことが可能になりました。以下に価格シミュレーションの実際の流れをお見せします。質問+返答で一つの塊だと思ってください。
① 普通の問い合わせをする
こちらは一般的な質問なので、stateとslotは初期状態のままになります。
② 見積もりが開始され、目的を尋ねる
見積もりをしたいなどの文言が確認されると、価格シミュレータが起動します。まずはライセンスの種類を決めるためにどのような目的かを尋ねます。
③ 見積もり途中にわからないことが質問できる
このターンだけ緑枠で囲いましたが、それはこれが質問をしているターンだからです。ライセンスに関する情報を埋める中でわからないことというのは必ず発生すると思われます。その時に聞くことができるというのがこのチャットボットの良さになっています。質問中もstateとslotはそのまま残っており、再度見積もりを進める態勢が維持されているという設計になっています。
④ 目的からライセンスの種類を決定して、Aの購入の有無を尋ねる
目的からライセンスの種類を決定してslotに記録します。その後Aの購入の有無を尋ねます。
⑤ Aの購入の有無を決定して、所属を尋ねる
所属によって価格体系が変化するので、このタイミングで所属を問いかけます。
⑥ 所属を決定して、AとBの希望購入数を尋ねる
最後にAとBをどれだけ購入したいかを問いかけます。
⑦ 金額計算
⑥の段階で、slotが全て埋まるので最後に金額計算をしてその結果をユーザーに返却します。

3.2.2 一般質問の回答 (RAG)
ルーティングで示した、左上の一般の質問への回答にはRAGを使います。今回はハイブリッドセマンティック検索を行い、回答を生成することとしました。以下に一般の質問への回答の流れを示しています。
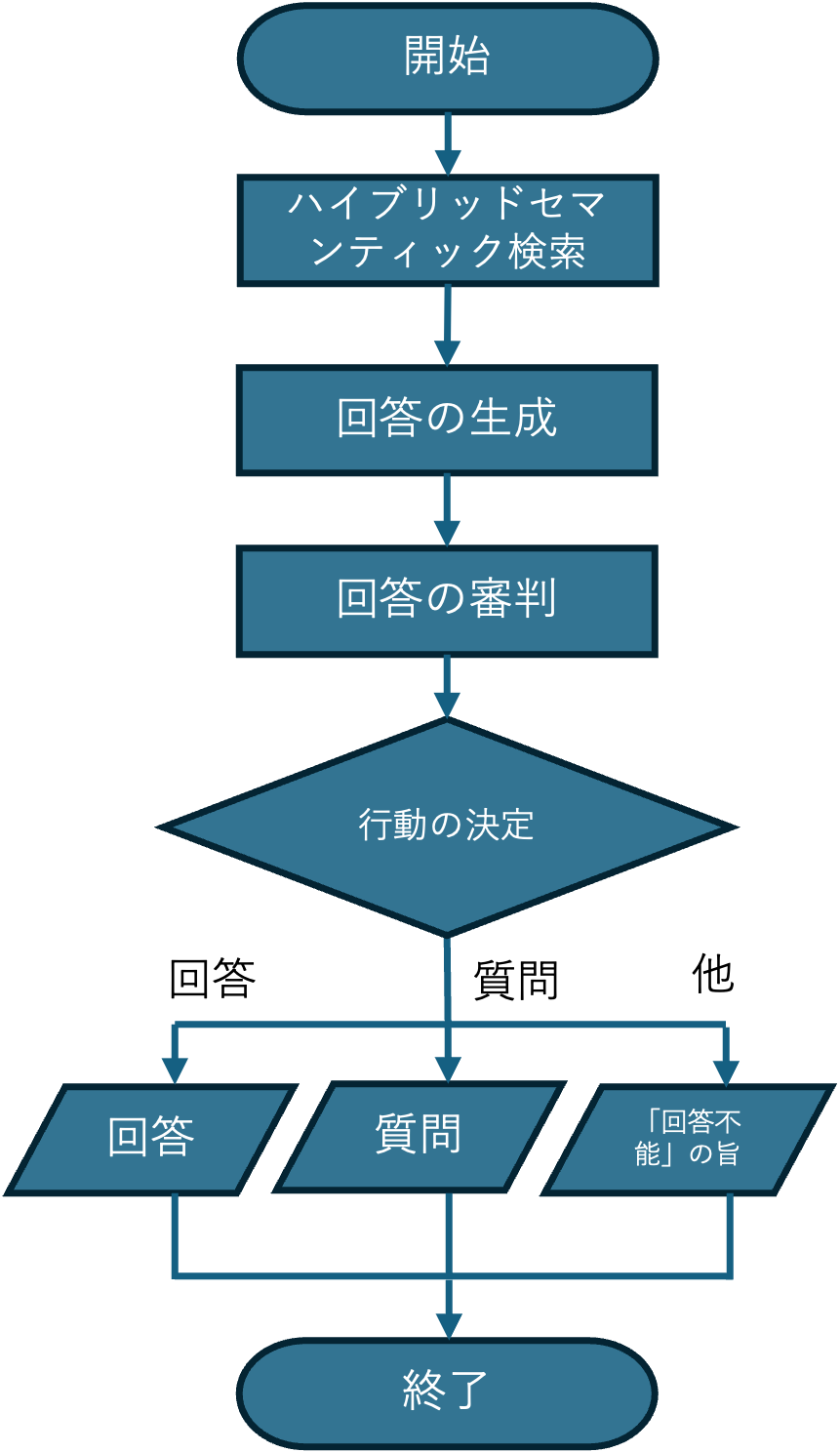
今回のRAGで問題になったのは、「根拠となる情報からそれっぽい回答が無理に作られる」と言うものでした。そこで質問と参照元の情報、さらに回答を照らしあわせてその回答がちゃんと回答になっているのかと言うことを審判すると言う処理を追加しました。
審査項目は以下のようになっており、answerability, groundedness, coverage, specificity, riskの4項目を0~1までの値で評価してもらいます。評価してもらったこれらの値に応じて、actionを ANSWER, ASK, RETRY_RETRIEVEの3種類から選択します。それぞれ回答をそのまま返す、質問を返す、回答不能の旨をユーザーに返します。
JUDGE_USER_TMPL_JA = """
[質問]
{question}
[検索結果]
{retrieved}
[評価ルーブリック]
- draft: 文字列。[質問]と[検索結果]を用いて作成した回答(200語以内)
- scores: 0〜1 (小数). 以下の5項目を必ず返す:
- answerability: 質問に答えているか
- groundedness: 主要な主張が抜粋に根拠づけられているか(引用の一致)
- coverage: ユーザーの意図に必要な観点の網羅
- specificity: 具体性(一般論の回避)
- risk: 推測・事実誤り・ポリシー逸脱のリスク(高いほど悪い)
- action: 次のいずれか1つの文字列: ANSWER, ASK, RETRY_RETRIEVE
推奨:
* ANSWER: answerability>=0.7 かつ groundedness>=0.7 かつ risk<=0.3
* ASK: 上記未満で、明確化により改善見込みがある場合(最大2問の質問を提案)
* RETRY_RETRIEVE: 根拠が弱い/見当違い(再検索が妥当)
- clarifying_questions: 1〜2個。短く、選択肢化できるものは括弧内に例示。
- notes: 検索結果等が質問と合致していない場合は、質問が不適切な場合があるので適切な質問をするよう伝える(30語以内)
JSONのみで返してください。"""
これだけではこちらが想定しているJSON形式での出力とならない場合があるので、以下のようなスキーマをもって出力を固定化できるようにしました。
# JSON Schema(Responses API の structured outputs 用)
JUDGE_SCHEMA = {
"name": "JudgeDecisionJa",
"strict": True, # ← ここ(json_schemaの中)
"schema": {
"type": "object",
"properties": {
"draft":{"type":"string"},
"action": {"type":"string","enum":["ANSWER","ASK","RETRY_RETRIEVE"]},
"scores": {
"type":"object",
"properties":{
"answerability":{"type":"number"},
"groundedness":{"type":"number"},
"coverage":{"type":"number"},
"specificity":{"type":"number"},
"risk":{"type":"number"}
},
"required":["answerability","groundedness","coverage","specificity","risk"],
"additionalProperties": False
},
"clarifying_questions": {
"type":"array",
"items":{"type":"string"},
"minItems": 0, "maxItems": 2,
"default": []
},
"notes": {"type":["string","null"], "default": None}
},
"required": ["draft","action","scores","clarifying_questions","notes"],
"additionalProperties": False
}
}
3.4 他
.github/workflows
こちらにはフロントエンド、バックエンド(関数)をAzureの各サービスへとデプロイするためのYAMLファイルが格納ています。Git Hub Actionsでによって、自動的にGit HubにプッシュされたコードがCI/CDされるというものです。
main_func-chatbot : 関数が書かれているファイルをAzure 関数アプリにデプロイするYAMLファイル
main_webapp-chatbot : フロントエンドが書かれているファイルをAzure Web ServiceにデプロイするYAMLファイル
data
HP_opendata : 会社やサービスのホームページより取得したデータ。
pdf : 約款などの細かなことが記載されているpdf (GitHubのリポジトリでは空白となっている)
HP_opendataは3種類の形式を持つように設計しました。
① page_section_markdown
こちらは各ページに書かれているものをそのまま構造化した情報。
[
{
"doc_type": "page_section_markdown",
"title": "ミッション", #ページ内のタイトル
"heading_path": ["ミッション", "MISSION"], #そのページの場所
"lang": "ja",
"body_markdown": "世界平和",
"url": ""
}
]
② page_section_faq_pairs
こちらはFAQを構造化した情報。
[
{
"doc_type": "faq_pair",
"question": "会社概要を教えてください。",
"answer_markdown": "私たちはニューヨークの治安を守っています",
"tags": ["会社情報", "概要"],
"url": ""
}
]
③ page_section_fact_cards
こちらは事実情報を構造化した情報。 〇〇の〇〇は〇〇となるような構造をとっています。
[
{
"doc_type": "fact_card",
"subject": "会社",
"predicate": "名前",
"value": "株式会社スパイダーマン",
"unit": null,
"as_of_date": null,
"url": "",
"evidence": null
}
]
scripts
2.2. RAGのインデックス登録で述べましたが、HPの情報をインデックス登録するindexer_HPとpdfの情報を登録するindexer_pdfの2つが格納されています。
4. 終わりに
webアプリの開発を全くしたことがない初心者がchatGPTを頼りながらなんとか作り上げたチャットボットになります。色々と足りていない部分大いにあるかなと思います。もし何かありましたら、ご意見頂戴できれば幸いです。
インターンの終盤にこのアプリを見せてみたのですが、反応はイマイチでした。その1ヶ月前には社長に直接見せており、完成を楽しみにしているよ〜というお言葉をいただいたのですが、完成時に初めて見せた取締の顔は渋かったのでした。実務を担っているのは社長ではなく、この取締役であるのに私は彼に確認をするということを怠っていたことがこの反応につながったのでした。
取締曰く、性能がどうよりもそもそも需要がないと。導入する意義があまり見当たらないと言われました。私は従来のルールベースのチャットボットよりも柔軟でしかも価格の見積もりまでできるというところでそこそこの自信があったのですが、彼らにしてみれば (素人で学生の私に任せるコスト) > (派遣なりで人手を確保して人力で対応するコスト)でありこれ以上でもこれ以下でもないということでした。
私としては非常に悔しかったわけですが、学ぶこともたくさんありました。以下その一例です。
・需要があると思い込むのは危険。鍵となる人間に直接確かめるのが鍵
・webアプリ開発はかなり大変だということとその一端を理解
・クラウドは便利だけど、料金をちゃんと把握していないと死んでしまう可能性がある
などなどです。
今回はこれを活用してちゃんころを稼ぐことができなかったのですが、せっかく作ったので、自分のポートフォリオとして残しておこうと思います。