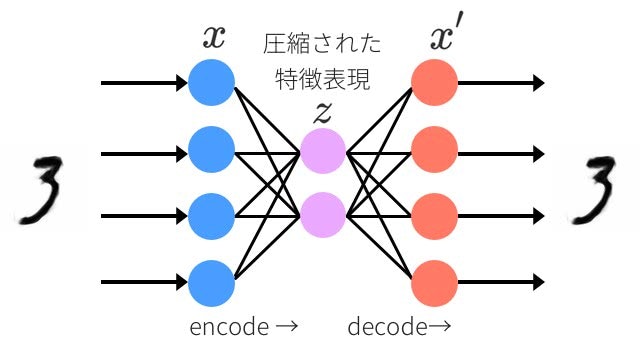
オートエンコーダ:抽象的な特徴を自己学習するディープラーニングの人気者
Unity ML-Agentsで、カメラから得た画像をオートエンコーダで次元圧縮し、強化学習してみました。
なぜオートエンコーダを使うのかを説明する前に、まず基本的な強化学習の形とその問題点について解説します。
基本的な強化学習の形とその問題点
強化学習の目的は、ある環境において、ある状態 s のとき最適な行動 a をとる方策 π(a|s) を見つけることです。
強化学習入門 Part2 - TensorflowとKerasとOpenAI GymでPolicy Gradientを実装してみよう!
状態sが 0,1,2,3,... のように離散値であれば、状態・行動の表を作って方策 π を表現することができます。
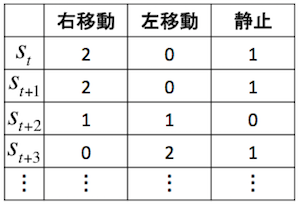
DQNをKerasとTensorFlowとOpenAI Gymで実装する
しかし、状態 s が連続値になれば、方策 π を上のような表で表現することはできないので、何かしらの関数近似器を使って近似する必要があります。
この関数近似器にディープラーニングを使ったものが深層強化学習と呼ばれます。
また、状態 s が画像であれば、画像の特徴抽出に良い結果を出している畳み込み層を組み込むのがいいでしょう。
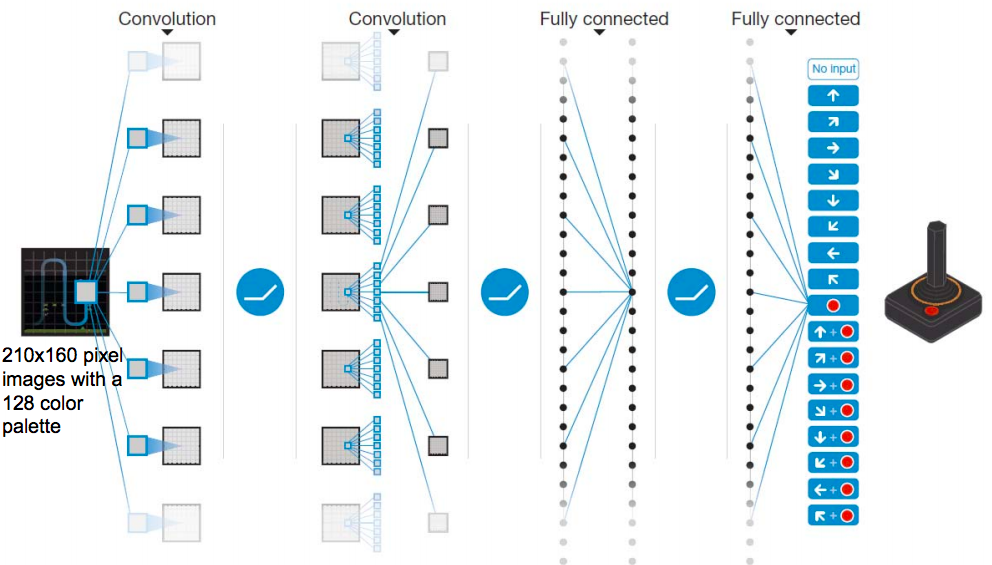
Human-level control through deep reinforcement learning(2015/02)
方策 π をこのように畳み込み層 + 全結合層で表現したものをここでは一体型モデルと呼ぶことにします。
この一体型モデルでももちろん強化学習はうまくいきます。実際、有名なDQNがそうですし、Unity ML-Agentsのデフォルトのモデル構造もこの一体型モデルであり、例えば、サンプルの VisualPushBlock などをやってみるとちゃんと学習がうまくいくことがわかります。

一体型モデルでも学習はうまくいきますが、いくつか問題点があります。
問題点 1 : 強化学習で畳み込み層を学習させる必要がある
強化学習を使って畳み込み層を学習させることになりますが、これが効率的かといわれるとビミョーなところです。
なぜなら、強化学習の目的は「最適な方策 π を見つけること」であって、「画像から特徴を抽出すること」ではないからです。
なのでこの二つは分けて、それぞれ独立に学習させたほうが合理的な気がします。
問題点 2 : 過学習を起こしやすい
例えば、一面雪景色のゲームで強化学習することを考えてみましょう。

このようなゲームから入ってくる映像は基本的に白くのっぺりとしたものになります。なので、畳み込み層もそのような白くのっぺりしたものに反応するように学習されます。
このモデルで次にジャングルが主戦場のゲームをやったら、全く違う光景なので、方策 π と合わせて画像抽出の学習もまた一から全部学習し直すことになるでしょう。

アマゾン熱帯雨林サバイバル『Green Hell』ゲームプレイ映像! 孤独が心身を蝕む…
問題 3 : 畳み込み層を学習させるのには多くの時間がかかる
個人的に一番ネックに感じるのが計算コストです。
cifar10などの32x32RGB画像でもCNNで学習させるにはそれなりの時間がかかります。
強化学習では、試行錯誤を通じて方策 π を学習させるのは時間がかかりますが、それに加えてCNNも学習させるとなると結構な計算量になります。
順伝播型でも結構なものですが、RNNなどを使った再帰型になれば凄まじい計算量になるでしょう。
VAEを使った強化学習
これらの問題点を解決するために VAE(Variational AutoEncoder) を使って強化学習を行いました。
あらかじめ学習させた VAE を特徴抽出器として使い、 PPO アルゴリズムで強化学習するといった流れです。
VAE はオートエンコーダの潜在変数 z に確率分布を仮定したモデルです。
通常の AE に比べて潜在変数 z が扱いやすくなり、より汎用性があるモデルといえそうです。

実験
今回は、Unity ML-Agentsのサンプルである PushBlock を使って実験しました。

青いブロックがエージェントで、前進・後進・左回転・右回転の4つの行動ができます。エージェントはオレンジブロックをゴールまで持っていくのが目標です。
目標を達成するとプラス報酬が与えられます。また、行動を促すため、毎秒小さなマイナス報酬が与えられます。

エージェントにはカメラがつけられており、このカメラからの映像を 96x96 RGB に変換したものをモデルの入力とします。
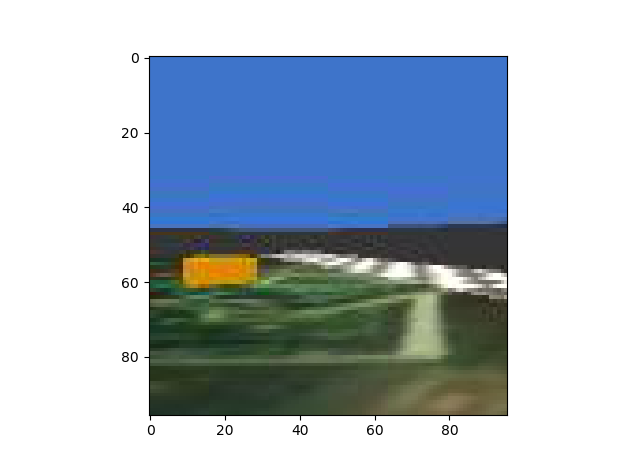
この画像をまず、次のような VAE を使って低次元の潜在変数に圧縮します。
self.img_size=96
self.z_dim=256
with tf.variable_scope('encoder'):
self.conv1 = tf.layers.conv2d(self.input, filters=32, kernel_size=3,
strides=1, padding='same', activation=tf.nn.relu, name='conv1')
self.conv2 = tf.layers.conv2d(self.conv1, filters=32, kernel_size=3,
strides=1, padding='same', activation=tf.nn.relu, name='conv2')
self.max_pooling1 = tf.layers.max_pooling2d(self.conv2, pool_size=2, strides=2)
self.conv3 = tf.layers.conv2d(self.max_pooling1, filters=64, kernel_size=3,
strides=1, padding='same', activation=tf.nn.relu, name='conv3')
self.conv4 = tf.layers.conv2d(self.conv3, filters=64, kernel_size=3,
strides=1, padding='same', activation=tf.nn.relu, name='conv4')
self.max_pooling2 = tf.layers.max_pooling2d(self.conv4, pool_size=2, strides=2)
self.flatten = c_layers.flatten(self.max_pooling2)
self.z_mean = tf.layers.dense(self.flatten, self.z_dim, name='z_mean')
self.z_log_var = tf.layers.dense(self.flatten, self.z_dim, name='z_log_var')
self.epsilon = tf.random_normal(shape=[tf.shape(self.z_mean)[0], self.z_dim])
self.z = self.z_mean + tf.exp(self.z_log_var) * self.epsilon
with tf.variable_scope('decoder'):
self.hidden_d1 = tf.layers.dense(self.z, int(self.img_size / 4) * int(self.img_size / 4) * 64,
activation=tf.nn.relu, name='hidden_d1')
self.decoder_input = tf.reshape(self.hidden_d1, (-1, int(self.img_size / 4), int(self.img_size / 4), 64))
self.deconv1 = tf.layers.conv2d_transpose(self.decoder_input, filters=64, kernel_size=3,
strides=2, padding='same', activation=tf.nn.relu,
name='deconv1')
self.deconv2 = tf.layers.conv2d(self.deconv1, filters=32, kernel_size=3, strides=1,
padding='same', activation=tf.nn.relu, name='deconv2')
self.deconv3 = tf.layers.conv2d_transpose(self.deconv2, filters=32, kernel_size=3,
strides=2, padding='same', activation=tf.nn.relu,
name='deconv3')
self.deconv4 = tf.layers.conv2d(self.deconv3, filters=3, kernel_size=3, strides=1,
padding='same', activation=tf.nn.sigmoid, name='deconv4')
エンコーダは畳み込み4層 + 全結合1層で潜在変数を出力します。デコーダはエンコーダを逆にしたものです。
VAE の学習にはスタンフォード大が公開しているデータセット STL-10 を使いました。
STL-10 のラベルなし10万枚で学習させ、テスト画像を復元してみます。

テスト画像

z 128次元

z 256次元

z 512次元
もちろん強化学習に使うのは潜在変数 z のほうで、復元画像はあくまでイメージです。
潜在変数が大きくなるほど、保存できる情報が増えます。一方で情報が増える分、強化学習で学習させる時間も増えます。
何かしらの問題を強化学習させる場合、画像のすべての情報はいらない場合がほとんどで、画像の中の大まかな特徴さえあれば、たいていの問題は解けるはずです。
今回は 128, 256, 512 次元のすべてで何回か試しましたが、PushBlock ではどれもうまく学習させることができました。また、次元が増えるごとに学習の収束にかかる時間も伸びていきました。
強化学習アルゴリズムには PPO を使います。 PPO のニューラルネットは、潜在変数 z を入力として、全結合3層から policy, value を出力します。
self.state_holder=tf.placeholder(tf.float32, shape=[None, z_dim]) # 128 or 256 or 512
self.a_dim=4
with tf.variable_scope('RL'):
self.hidden1 = tf.layers.dense(self.state_holder, 128, activation=tf.nn.relu, name='hidden1')
self.hidden2 = tf.layers.dense(self.hidden1, 128, activation=tf.nn.relu, name='hidden2')
self.policy = tf.layers.dense(self.hidden2, self.a_dim,
activation=None, use_bias=None, name='policy')
self.value = tf.layers.dense(self.hidden2, 1,
activation=None, use_bias=None, name='value')

8個のエージェントを使って学習します。それぞれ床の模様を変えていますが、ゲーム性にはとくに関係なく、ただの視覚的ノイズです。
結果

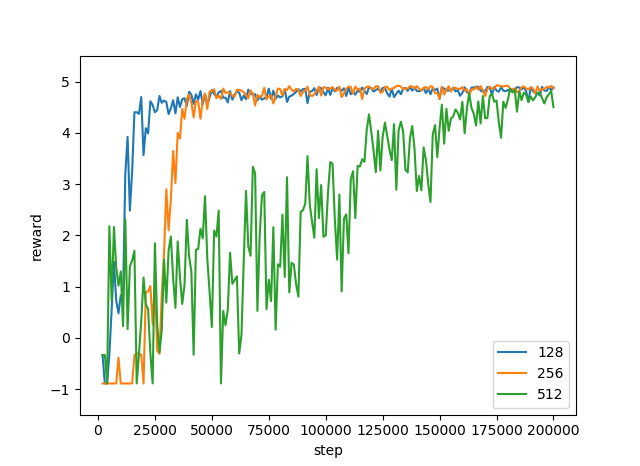
報酬は 4.8 あたりが上限になります。 潜在変数の次元が 128, 256, 512 と増えていくにつれて、学習の収束に時間がかかります。何回か試したんですが、1回分しか記録していないので、グラフは1回分のものです。
また、比較用に一体型モデルでもやってみました。
self.state_holder=tf.placeholder(tf.float32, shape=[None, 96, 96, 3])
self.a_dim=4
with tf.variable_scope('RL'):
self.conv1 = tf.layers.conv2d(self.state_holder, filters=32, kernel_size=3,
strides=1, padding='same', activation=tf.nn.relu, name='conv1')
self.conv2 = tf.layers.conv2d(self.conv1, filters=32, kernel_size=3,
strides=1, padding='same', activation=tf.nn.relu, name='conv2')
self.max_pooling1 = tf.layers.max_pooling2d(self.conv2, pool_size=2, strides=2)
self.conv3 = tf.layers.conv2d(self.max_pooling1, filters=64, kernel_size=3,
strides=1, padding='same', activation=tf.nn.relu, name='conv3')
self.conv4 = tf.layers.conv2d(self.conv3, filters=64, kernel_size=3,
strides=1, padding='same', activation=tf.nn.relu, name='conv4')
self.max_pooling2 = tf.layers.max_pooling2d(self.conv4, pool_size=2, strides=2)
self.flatten = c_layers.flatten(self.max_pooling2)
self.hidden1 = tf.layers.dense(self.flatten, 128, activation=tf.nn.relu, name='hidden1')
self.hidden2 = tf.layers.dense(self.hidden1, 128, activation=tf.nn.relu, name='hidden2')
self.hidden3 = tf.layers.dense(self.hidden2, 128, activation=tf.nn.relu, name='hidden3')
self.policy = tf.layers.dense(self.hidden3, self.a_dim, activation=None, use_bias=None)
self.value = tf.layers.dense(self.hidden3, 1, activation=None, use_bias=None)
モデルの構造は VAE を使ったモデルと同じです。
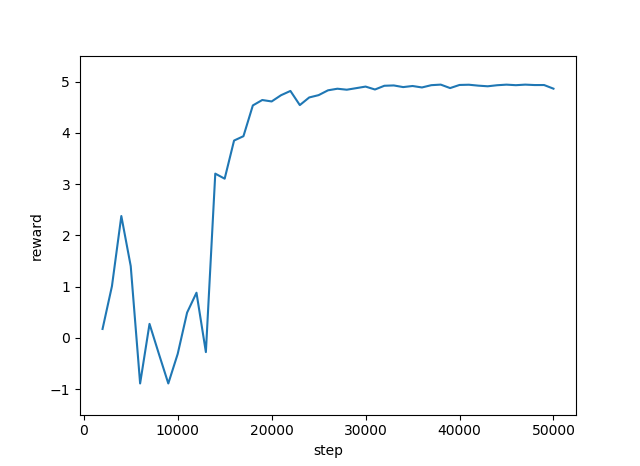
2万回の実行で学習はおおよそ収束し安定しています。ただし、5万回の実行にかかった時間は約95分でした。
一方 VAE を使ったモデルは5万回の実行にかかった時間は約35分でした。
一体型モデルに比べて VAE を使ったモデルは計算時間が約 1/3 という結果です。
今回のモデルは順伝播型ですが、 RNN などを組み込んだ再帰型であれば、この差はもっと大きくなると思います。
VAE を使うことで計算時間を大幅に短縮することができるようになったので次は、 RNN を使って強化学習してみたいと思っています![]()