前回Unity ML-Agentsを使ってDQNアルゴリズムを実装しました。
参考1:【強化学習】UnityとPythonを使ってDQNアルゴリズム実装してみた
今回はPPOアルゴリズムを実装したいと思います。
PPOはDQNに比べると、LSTMが使えたり、学習の速度・安定性で優れており、次世代の強化学習アルゴリズムとして期待されています。
OpenAIでは、PPOを拡張したOpenAI Fiveというアルゴリズムで様々な強化学習をしているようです。
またUnity ML-Agentsのデフォルトで実装されているのもPPOです。
実装
ではさっそく実装していきましょう。
環境として倒立振子を使います。
Unity側での実装はこちらで解説したものと同じものになります。

エージェントの数はなんでもいいですが、今回は4つにしました。
そしたらBrainTypeをExternalにしておきます。
前回のDQNの記事ではML-Agents v0.3を使用しており、UnityをPythonフォルダにビルドして学習をしていましたが、v0.4になって、ビルドしなくてもUnityEditorで学習ができるようになりました。
参考3:【新ver】Unity ML-Agents v0.4.0の新機能など
せっかくなので今回はそちらの方法でやっていきたいと思います。
Pythonフォルダに次のようなテストファイルを書いて実行します。
import numpy as np
from unityagents import UnityEnvironment
# 環境を構築
env=UnityEnvironment()
BRAIN_NAME=env.brain_names[0] #ブレインの名前
# 環境リセット
info=env.reset(train_mode=False)[BRAIN_NAME]
NUM_AGENTS=len(info.agents) #エージェントの数
for step in range(1000):
#ランダム行動
action=np.random.randint(0,2,NUM_AGENTS)
#step
new_info=env.step(vector_action=action)[BRAIN_NAME]
#表示
print('\n ===== {} step ======'.format(step))
print('\nstate=', new_info.vector_observations) # 状態
print('\naction=', action) #アクション
print('\nreward=', new_info.rewards) #報酬
print('\ndone=', new_info.local_done) #終了条件
print('\nmax_reach=', new_info.max_reached) #max_step数に達したか
# 環境終了
env.close()
実行すると待機モードになるので、UnityEditorで実行ボタンを押します。




UnityとPythonで画像のようになるとおもいます。
次は、実際にPPOを使って強化学習を行います。
今回ML-Agents v0.1.1を参考にして同じものを再現しました。
1ファイルでシンプルになるようにしましたが、アルゴリズムやハイパーパラメータの設定などは同じです。
import numpy as np
import tensorflow as tf
from unityagents import UnityEnvironment
class PPOModel():
def __init__(self,num_agents=1,s_dim=3,a_dim=2,c_vf=1.0,beta=1e-3,epsilon=0.2,lr=3e-4,h_dim=64,
gamma=0.99,lambd=0.95,time_horizon=2048,buffer_size=2048,batch_size=64,num_epoch=5):
# General parameters
self.num_agents=num_agents #Number of agents
self.s_dim=s_dim #State size
self.a_dim=a_dim #Action size
# Algorithm-specific parameters for tuning
self.c_vf=c_vf # Coefficient of Value Function Loss
self.beta=beta # Strength of entropy regularization
self.epsilon=epsilon # Acceptable threshold around ratio of old and new policy probabilities
self.lr=lr # Model learning rate
self.h_dim=h_dim # Number of units in hidden layer
self.gamma=gamma # Reward discount rate
self.lambd=lambd # GAE weighing factor
self.time_horizon=time_horizon # How many steps to collect per agent before adding to buffer
self.buffer_size=buffer_size # How large the experience buffer should be before gradient descent
self.batch_size=batch_size # How many experiences per gradient descent update step
self.num_epoch=num_epoch # Number of gradient descent steps per batch of experiences
#placeholder
self.state = tf.placeholder(tf.float32, shape=(None, self.s_dim)) #buffer['states']
self.action = tf.placeholder(tf.float32, shape=(None, self.a_dim)) #buffer['actions']
self.old_probs=tf.placeholder(tf.float32,shape=(None,self.a_dim)) #buffer['policy']
self.returns=tf.placeholder(tf.float32,shape=(None,1)) #buffer['discounted_returns']
self.advantage=tf.placeholder(tf.float32,shape=(None,1)) #buffer['advantage']
self.model=self.build_model()
self.graph=self.build_graph()
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
#buffer
self.buffer_keys=['states', 'actions', 'rewards', 'policies', 'value_estimates',
'advantages', 'discounted_returns']
self.local_buffer = {}
for i in range(self.num_agents):
self.local_buffer[i]=self.empty_buffer()
self.global_buffer = self.empty_buffer()
def empty_buffer(self):
# Dictionary of agent experience history
buffer = {}
for key in self.buffer_keys:
buffer[key] = []
return buffer
def build_model(self):
W_d1 = tf.Variable(tf.truncated_normal([self.s_dim, self.h_dim], stddev=0.01))
b_d1 = tf.Variable(tf.zeros(self.h_dim))
h_d1 = tf.nn.elu(tf.matmul(self.state, W_d1) + b_d1)
W_d2 = tf.Variable(tf.truncated_normal([self.h_dim, self.h_dim], stddev=0.01))
b_d2 = tf.Variable(tf.zeros(self.h_dim))
h_d2 = tf.nn.elu(tf.matmul(h_d1, W_d2) + b_d2)
#output policy
W_out_policy = tf.Variable(tf.truncated_normal([self.h_dim, self.a_dim], stddev=0.01))
b_out_policy = tf.Variable(tf.zeros(self.a_dim))
self.policy=tf.nn.softmax(tf.matmul(h_d2,W_out_policy)+b_out_policy)
#output value
W_out_value=tf.Variable(tf.truncated_normal([self.h_dim,1],stddev=0.01))
b_out_value=tf.Variable(tf.zeros(1))
self.value=tf.matmul(h_d2,W_out_value)+b_out_value
def build_graph(self):
#Current policy entropy
entropy=-tf.reduce_sum(self.policy*tf.log(self.policy+1e-10),axis=1)
pi=tf.reduce_sum(self.policy*self.action,axis=1) #Current policy probabilities
old_pi=tf.reduce_sum(self.old_probs*self.action,axis=1) #Past policy probabilities
#Cliping rθ,and use the smaller
r_theta=pi/old_pi
p_opt_a=r_theta*self.advantage
p_opt_b=tf.clip_by_value(r_theta,1-self.epsilon,1+self.epsilon)*self.advantage
self.policy_loss=-tf.reduce_mean(tf.minimum(p_opt_a,p_opt_b))
self.value_loss=tf.reduce_mean(tf.squared_difference(self.returns,tf.reduce_sum(self.value,axis=1)))
self.loss=self.policy_loss+self.c_vf*self.value_loss-self.beta*tf.reduce_mean(entropy)
optimizer=tf.train.AdamOptimizer(learning_rate=self.lr)
self.update_batch=optimizer.minimize(self.loss)
def get_GAE(self,r, v, v_next):
'''
Computes generalized advantage estimate for use in updating policy.
:param r: list of rewards for time-steps t to T.
:param v: list of value estimates for time-steps t to T.
:param v_next: Value estimate for time-step T+1.
:return: list of advantage estimates for time-steps t to T.
'''
v.append(v_next)
running_add = 0.0
advantage = []
for t in reversed(range(0, len(r))):
delta_t = r[t] + self.gamma * v[t + 1] - v[t]
running_add = (self.gamma * self.lambd) * running_add + delta_t
advantage.insert(0, running_add)
v.pop()
return advantage
def process_experiences(self,info):
for i in range(self.num_agents):
if info.local_done[i] or info.max_reached[i] or len(self.local_buffer[i]['actions']) > self.time_horizon:
# decide value_next if terminal
if info.local_done[i] or info.max_reached[i]:
value_next = 0.0
else:
value_next = self.sess.run(self.value, feed_dict={self.state: info.vector_observations[i]})[0, 0]
# conputes generalized advantage and discounted_returns
self.local_buffer[i]['advantages'] = self.get_GAE(r=self.local_buffer[i]['rewards'],
v=self.local_buffer[i]['value_estimates'],
v_next=value_next)
self.local_buffer[i]['discounted_returns'] = np.array(self.local_buffer[i]['advantages']) + \
np.array(self.local_buffer[i]['value_estimates'])
if len(self.global_buffer['actions']) > 0:
# Appends agent experience history to global history buffer
for key in self.buffer_keys:
self.global_buffer[key] = \
np.concatenate([self.global_buffer[key], self.local_buffer[i][key]], axis=0)
else:
# Creates new global_buffer from existing local_buffer
for key in self.buffer_keys:
self.global_buffer[key] = self.local_buffer[i][key]
# clear local buffer
self.local_buffer[i] = self.empty_buffer()
def update_model(self):
if len(PPO.global_buffer['actions']) > self.buffer_size:
# standardization
advantages = np.array(self.global_buffer['advantages'])
self.global_buffer['advantages'] = (advantages - advantages.mean()) / advantages.std()
for k in range(self.num_epoch):
for l in range(len(self.global_buffer['actions']) // self.batch_size):
start = l * self.batch_size
end = (l + 1) * self.batch_size
feed_dict = {self.returns: self.global_buffer['discounted_returns'][start:end],
self.advantage: self.global_buffer['advantages'][start:end],
self.old_probs: self.global_buffer['policies'][start:end],
self.action: self.global_buffer['actions'][start:end],
self.state: self.global_buffer['states'][start:end]}
v_loss, p_loss, _ = self.sess.run([self.value_loss, self.policy_loss, self.update_batch],
feed_dict=feed_dict)
self.global_buffer = self.empty_buffer()
# calculate and save reward
class summary_reward():
def __init__(self,num_agents=1):
self.num_agents=num_agents
self.r_sum_global=[]
self.r_sum_all={'step':[0],'reward':[0.0]}
self.r_sum_local = {}
for i in range(self.num_agents):
self.r_sum_local[i]=0.0
def calculate_reward(self,info,step):
for i in range(self.num_agents):
self.r_sum_local[i] += info.rewards[i]
if info.local_done[i] or info.max_reached[i]:
self.r_sum_global.append(self.r_sum_local[i])
self.r_sum_local[i] = 0.0
if len(self.r_sum_global) > self.num_agents:
r_mean = np.mean(self.r_sum_global)
self.r_sum_all['step'].append(step)
self.r_sum_all['reward'].append(r_mean)
self.r_sum_global.clear()
# Main==========================================================================
if __name__=='__main__':
# General parameters
env = UnityEnvironment()
BRAIN_NAME = env.brain_names[0]
info = env.reset(train_mode=True)[BRAIN_NAME]
NUM_AGENTS = len(info.agents)
S_DIM = 3 # state size
A_DIM = 2 # action size
MAX_STEPS = 100000 # Maximum number of steps to run environment
PPO = PPOModel(num_agents=NUM_AGENTS,s_dim=S_DIM,a_dim=A_DIM)
sum_r = summary_reward(num_agents=NUM_AGENTS)
for step in range(MAX_STEPS + 1):
policy, value = PPO.sess.run([PPO.policy, PPO.value],
feed_dict={PPO.state: info.vector_observations})
# decide discrete action according to policy
a_list = []
a_onehot_list = []
for i in range(NUM_AGENTS):
a = np.random.choice(np.arange(A_DIM), p=policy[i])
a_list.append(a)
# turn action into one-hot representation
a_onehot = np.zeros(A_DIM)
a_onehot[a] = 1
a_onehot_list.append(a_onehot)
new_info = env.step(vector_action=a_list)[BRAIN_NAME]
# add experiences to buffer
for i in range(NUM_AGENTS):
PPO.local_buffer[i]['states'].append(info.vector_observations[i])
PPO.local_buffer[i]['actions'].append(a_onehot_list[i])
PPO.local_buffer[i]['rewards'].append(new_info.rewards[i])
PPO.local_buffer[i]['policies'].append(policy[i])
PPO.local_buffer[i]['value_estimates'].append(value[i])
# update info
info = new_info
# conputes advantage and dicounted_returns
# set experiences of local buffer into global buffer, and clear local buffer
PPO.process_experiences(info=info)
# Perform gradient descent with experience buffer
PPO.update_model()
# calculate reward
sum_r.calculate_reward(info=info, step=step)
# display reward and step
if (step + 1) % 1000 == 0:
print('{} step, {} reward'.format(sum_r.r_sum_all['step'][-1], sum_r.r_sum_all['reward'][-1]))
結果
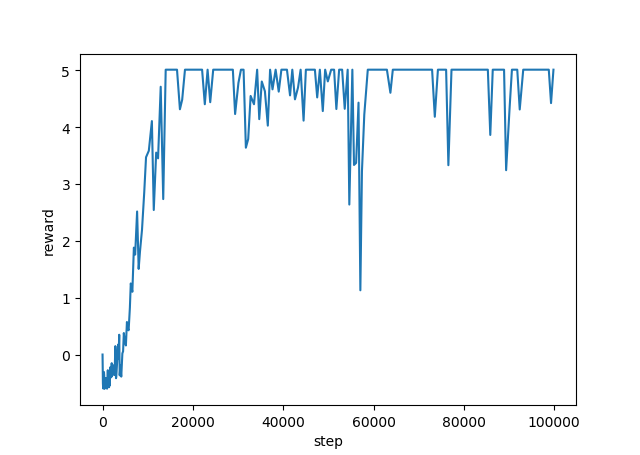

10万回でおおよそ収束すると思います。
解説
Main
まず学習のおおまかな流れについて
if __name__=='__main__':
# General parameters
env = UnityEnvironment()
BRAIN_NAME = env.brain_names[0]
info = env.reset(train_mode=True)[BRAIN_NAME]
NUM_AGENTS = len(info.agents)
S_DIM = 3 # state size
A_DIM = 2 # action size
MAX_STEPS = 100000 # Maximum number of steps to run environment
PPO = PPOModel(num_agents=NUM_AGENTS,s_dim=S_DIM,a_dim=A_DIM)
sum_r = summary_reward(num_agents=NUM_AGENTS)
for step in range(MAX_STEPS + 1):
policy, value = PPO.sess.run([PPO.policy, PPO.value],
feed_dict={PPO.state: info.vector_observations})
# decide discrete action according to policy
a_list = []
a_onehot_list = []
for i in range(NUM_AGENTS):
a = np.random.choice(np.arange(A_DIM), p=policy[i])
a_list.append(a)
# turn action into one-hot representation
a_onehot = np.zeros(A_DIM)
a_onehot[a] = 1
a_onehot_list.append(a_onehot)
new_info = env.step(vector_action=a_list)[BRAIN_NAME]
# add experiences to buffer
for i in range(NUM_AGENTS):
PPO.local_buffer[i]['states'].append(info.vector_observations[i])
PPO.local_buffer[i]['actions'].append(a_onehot_list[i])
PPO.local_buffer[i]['rewards'].append(new_info.rewards[i])
PPO.local_buffer[i]['policies'].append(policy[i])
PPO.local_buffer[i]['value_estimates'].append(value[i])
# update info
info = new_info
# conputes advantage and dicounted_returns
# set experiences of local buffer into global buffer, and clear local buffer
PPO.process_experiences(info=info)
# Perform gradient descent with experience buffer
PPO.update_model()
# calculate reward
sum_r.calculate_reward(info=info, step=step)
# display reward and step
if (step + 1) % 1000 == 0:
print('{} step, {} reward'.format(sum_r.r_sum_all['step'][-1], sum_r.r_sum_all['reward'][-1]))
PPOのモデルから、状態を入力として、policy,valueを計算します。
policyから行動aを決定し、env.step()で実行します。
行動aは後々π(a|s)を計算するため、ワンホット表現にしておきます。
その後、バッファにそれぞれの観測情報を追加。
バッファは個々のエージェントがもつlocal bufferと、local bufferの情報を集めたglobal bufferがあります。
PPO.process_experiences()では、エージェントが終了条件になるか、local bufferの情報が一定数たまったら、advantage,discounted returnsを計算します。
local bufferの情報をglobal bufferに移し、local bufferを空にします。
PPO.update_model()では、global bufferの情報が一定数たまったら、モデルをバッチ更新し、global bufferを空にします。
最後は、エージェントの報酬の計算と記録、表示です。
以上がおおまかな流れになります。
local buffer , global buffer
# buffer
self.buffer_keys=['states', 'actions', 'rewards', 'policies',
'value_estimates', 'advantages', 'discounted_returns']
self.local_buffer = {}
for i in range(self.num_agents):
self.local_buffer[i]=self.empty_buffer()
self.global_buffer = self.empty_buffer()
def empty_buffer(self):
# Dictionary of agent experience history
buffer = {}
for key in self.buffer_keys:
buffer[key] = []
return buffer
local bufferとglobal bufferを用意します。
local bufferはエージェントの数だけ用意します。

build_model()
def build_model(self):
W_d1 = tf.Variable(tf.truncated_normal([self.s_dim, self.h_dim], stddev=0.01))
b_d1 = tf.Variable(tf.zeros(self.h_dim))
h_d1 = tf.nn.elu(tf.matmul(self.state, W_d1) + b_d1)
W_d2 = tf.Variable(tf.truncated_normal([self.h_dim, self.h_dim], stddev=0.01))
b_d2 = tf.Variable(tf.zeros(self.h_dim))
h_d2 = tf.nn.elu(tf.matmul(h_d1, W_d2) + b_d2)
#output policy
W_out_policy = tf.Variable(tf.truncated_normal([self.h_dim, self.a_dim], stddev=0.01))
b_out_policy = tf.Variable(tf.zeros(self.a_dim))
self.policy=tf.nn.softmax(tf.matmul(h_d2,W_out_policy)+b_out_policy)
#output value
W_out_value=tf.Variable(tf.truncated_normal([self.h_dim,1],stddev=0.01))
b_out_value=tf.Variable(tf.zeros(1))
self.value=tf.matmul(h_d2,W_out_value)+b_out_value
状態を入力として、policy,valueを出力します。
隠れ層は2層で、64ユニットです。
build_graph()
def build_graph(self):
#Current policy entropy
entropy=-tf.reduce_sum(self.policy*tf.log(self.policy+1e-10),axis=1)
pi=tf.reduce_sum(self.policy*self.action,axis=1) #Current policy probabilities
old_pi=tf.reduce_sum(self.old_probs*self.action,axis=1) #Past policy probabilities
#Cliping rθ,and use the smaller
r_theta=pi/old_pi
p_opt_a=r_theta*self.advantage
p_opt_b=tf.clip_by_value(r_theta,1-self.epsilon,1+self.epsilon)*self.advantage
self.policy_loss=-tf.reduce_mean(tf.minimum(p_opt_a,p_opt_b))
self.value_loss=tf.reduce_mean(tf.squared_difference(self.returns,tf.reduce_sum(self.value,axis=1)))
self.loss=self.policy_loss+self.c_vf*self.value_loss-self.beta*tf.reduce_mean(entropy)
optimizer=tf.train.AdamOptimizer(learning_rate=self.lr)
self.update_batch=optimizer.minimize(self.loss)



L_CLIPがpolicy_loss, L_VFがvalue_loss, Sがentropyです。
L_CLIP+VF+Sを最大化するようにモデルを更新するのが目標です。
ただ、TensorFlowには勾配を最大化するような方法がないので、マイナスをかけたものを最小化します。なので論文と実装では符号が反転していることに注意が必要です。
参考4:Proximal Policy Optimization Algorithms
参考5:【強化学習】実装しながら学ぶPPO【CartPoleで棒立て:1ファイルで完結】
get_GAE()
def get_GAE(self,r, v, v_next):
'''
Computes generalized advantage estimate for use in updating policy.
:param r: list of rewards for time-steps t to T.
:param v: list of value estimates for time-steps t to T.
:param v_next: Value estimate for time-step T+1.
:return: list of advantage estimates for time-steps t to T.
'''
v.append(v_next)
running_add = 0.0
advantage = []
for t in reversed(range(0, len(r))):
delta_t = r[t] + self.gamma * v[t + 1] - v[t]
running_add = (self.gamma * self.lambd) * running_add + delta_t
advantage.insert(0, running_add)
v.pop()
return advantage
GAE(generalized advantage estimator)

process_experiences()
def process_experiences(self, info):
for i in range(self.num_agents):
if info.local_done[i] or info.max_reached[i] or len(self.local_buffer[i]['actions']) > self.time_horizon:
# decide value_next if terminal
if info.local_done[i] or info.max_reached[i]:
value_next = 0.0
else:
value_next = self.sess.run(self.value, feed_dict={self.state: info.vector_observations[i]})[0, 0]
# conputes generalized advantage and discounted_returns
self.local_buffer[i]['advantages'] = self.get_GAE(r=self.local_buffer[i]['rewards'],
v=self.local_buffer[i]['value_estimates'],
v_next=value_next)
self.local_buffer[i]['discounted_returns'] = np.array(self.local_buffer[i]['advantages']) + \
np.array(self.local_buffer[i]['value_estimates'])
if len(self.global_buffer['actions']) > 0:
# Appends agent experience history to global history buffer
for key in self.buffer_keys:
self.global_buffer[key] = \
np.concatenate([self.global_buffer[key], self.local_buffer[i][key]], axis=0)
else:
# Creates new global_buffer from existing local_buffer
for key in self.buffer_keys:
self.global_buffer[key] = self.local_buffer[i][key]
# clear local buffer
self.local_buffer[i] = self.empty_buffer()
エージェントが終了条件になるか、local bufferの情報がtime_horizon(=2048)を超えたら実行します。
local bufferの情報がt~TのときT+1がvalue_nextです。
advantage,discounted returnsを計算し、local bufferに入れます。
global bufferが空の時は、local bufferをそのままコピーし、空でないときは、追加します。
最後にlocal bufferを空にします。
update_model()
def update_model(self):
if len(PPO.global_buffer['actions']) > self.buffer_size:
# standardization
advantages = np.array(self.global_buffer['advantages'])
self.global_buffer['advantages'] = (advantages - advantages.mean()) / advantages.std()
for k in range(self.num_epoch):
for l in range(len(self.global_buffer['actions']) // self.batch_size):
start = l * self.batch_size
end = (l + 1) * self.batch_size
feed_dict = {self.returns: self.global_buffer['discounted_returns'][start:end],
self.advantage: self.global_buffer['advantages'][start:end],
self.old_probs: self.global_buffer['policies'][start:end],
self.action: self.global_buffer['actions'][start:end],
self.state: self.global_buffer['states'][start:end]}
v_loss, p_loss, _ = self.sess.run([self.value_loss, self.policy_loss, self.update_batch],
feed_dict=feed_dict)
self.global_buffer = self.empty_buffer()
global bufferの情報がbuffer_size(=2048)を超えたら実行します。
advantageは標準化。
global bufferの情報をbatch_size(=64)ずつバッチ更新していきます。
これをnum_epoch(=5)繰り返し、global bufferを空にします。
参考
参考1:【強化学習】UnityとPythonを使ってDQNアルゴリズム実装してみた
参考2:【Unity強化学習】自作ゲームで強化学習
参考3:【新ver】Unity ML-Agents v0.4.0の新機能など
参考4:Proximal Policy Optimization Algorithms
参考5:【強化学習】実装しながら学ぶPPO【CartPoleで棒立て:1ファイルで完結】