DCGANでFashion-MNISTに近い画像が徐々に生成されていく様子。
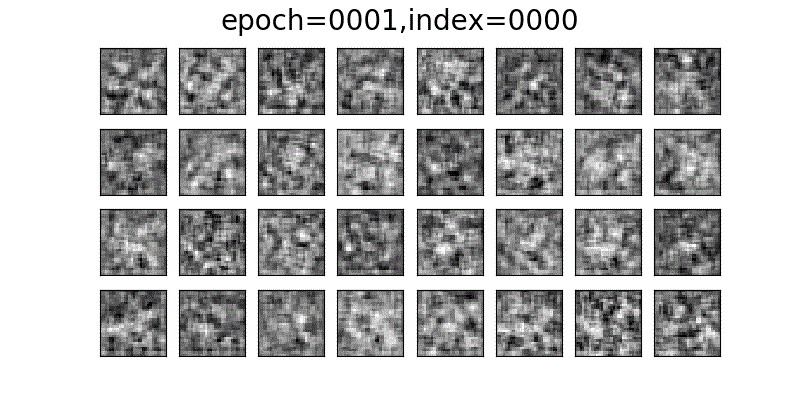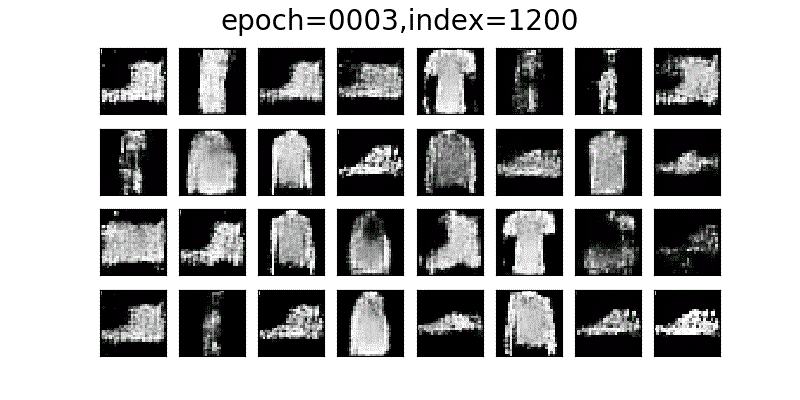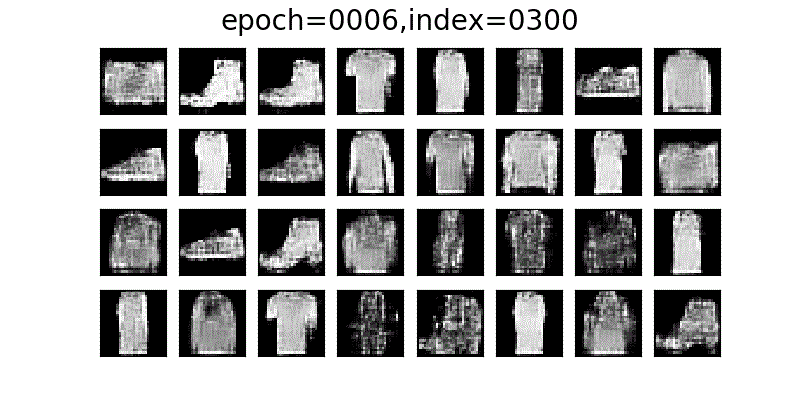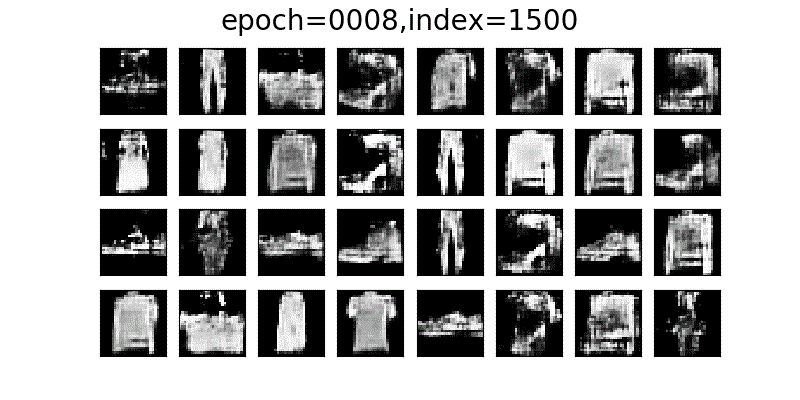

データセットとして提供されているFashion-MNISTの画像がこちら

データセットの画像と比べてDCGANで生成された画像は、少し粗が目立ちますが、かなり近いかたちの画像が生成されていると思います。
GAN(Generative Adversarial Networks)とは
今回の実装にあたって、こちらの記事を参考にさせていただきました。
はじめてのGAN
詳しい解説などは元記事を参照ください。
ここでは、おおまかなGANの仕組みをつかんで、Kerasで実装したいとおもいます。
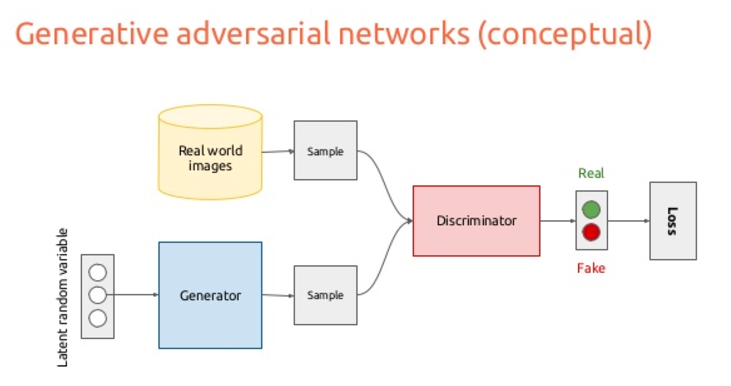
GANではまず、Generatorによってノイズから作った画像のミニバッチと、データセットから作ったミニバッチを用意します。
これをDiscriminatorを通して、Generatorによって生成された画像なのか、データセットの画像なのかを判断させます。
Generatorはなるべく、データセットにありえそうな画像を生成するように学習することで、Discriminatorを騙そうとします。
最終的にこの繰り返しによってGeneratorはデータセットに似たような画像を生成することができるようになります。
これがGANの考え方のようです。
Kerasで実装する
GANをさらに発展させた仕組みとしてDCGAN(Deep Convolutional GAN)があります。
これは画像関連で高い特徴抽出ができる畳み込みネットワークをGANに応用したものです。
今回の実装にあたって元記事:はじめてのGANから以下の3点を変更させていただきました。
1.MNISTではなくFsahion-MNISTを利用
2.channels_first形式からchannels_last形式へ
3.画像表示にmatplotlibを利用
元記事のほうでは、channels_first形式になっていましたが、Kerasのデフォルトはchannels_lastであり、大半の人はそっちだと思うので、channels_last形式用に調整しました。
ライブラリのインポートとモデルの構築
from keras.models import Sequential
from keras.layers import Dense, Activation, Reshape
from keras.layers.normalization import BatchNormalization
from keras.layers.convolutional import UpSampling2D, Convolution2D
import os
from keras.datasets import fashion_mnist
from keras.optimizers import Adam
import numpy as np
from keras.layers.advanced_activations import LeakyReLU
from keras.layers import Flatten, Dropout
import matplotlib.pyplot as plt
BATCH_SIZE = 32
NUM_EPOCH = 20
GENERATED_IMAGE_PATH = 'generated_images_fashion_mnist/' # 生成画像の保存先
def generator_model():
model = Sequential()
model.add(Dense(input_dim=100, output_dim=1024))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(128*7*7))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Reshape((7, 7, 128), input_shape=(128*7*7,)))
model.add(UpSampling2D((2, 2)))
model.add(Convolution2D(64, (5,5), border_mode='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(UpSampling2D((2, 2)))
model.add(Convolution2D(1, (5,5), border_mode='same'))
model.add(Activation('tanh'))
return model
def discriminator_model():
model = Sequential()
model.add(Convolution2D(64, 5, 5,
subsample=(2, 2),
border_mode='same',
input_shape=(28, 28, 1)))
model.add(LeakyReLU(0.2))
model.add(Convolution2D(128, 5, 5, subsample=(2, 2)))
model.add(LeakyReLU(0.2))
model.add(Flatten())
model.add(Dense(256))
model.add(LeakyReLU(0.2))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
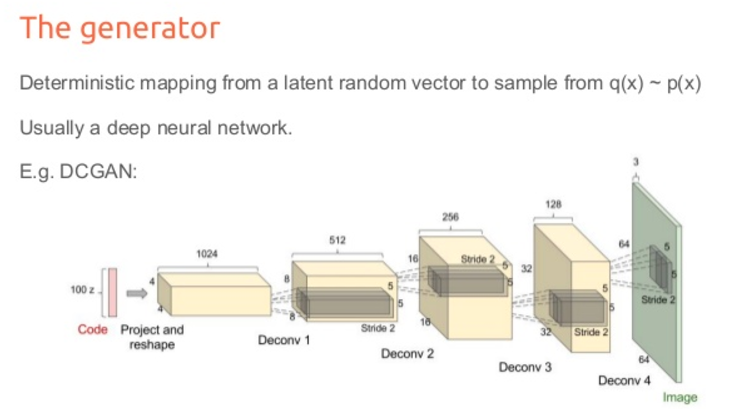
100次元の乱数を作り、それをGeneratorの入力にします。2回のUpSamplingによって28x28の画像が得られます。出力にはtanh。
上の画像がイメージ図(数字は違う)
Discriminatorは一般的なCNNに近いかたち。
活性化関数にLeakyReLu、プーリングの代わりに畳み込みを利用しているようです。
学習する
def train():
(X_train, y_train), (_, _) = fashion_mnist.load_data()
X_train = (X_train.astype(np.float32) - 127.5)/127.5
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], X_train.shape[2],1)
print(X_train.shape)
discriminator = discriminator_model()
d_opt = Adam(lr=1e-5, beta_1=0.1)
discriminator.compile(loss='binary_crossentropy', optimizer=d_opt)
# generator+discriminator (discriminator部分の重みは固定)
discriminator.trainable = False
generator = generator_model()
dcgan = Sequential([generator, discriminator])
g_opt = Adam(lr=2e-4, beta_1=0.5)
dcgan.compile(loss='binary_crossentropy', optimizer=g_opt)
num_batches = int(X_train.shape[0] / BATCH_SIZE)
print('Number of batches:', num_batches)
for epoch in range(NUM_EPOCH):
for index in range(num_batches):
noise = np.array([np.random.uniform(-1, 1, 100) for _ in range(BATCH_SIZE)])
image_batch = X_train[index*BATCH_SIZE:(index+1)*BATCH_SIZE]
generated_images = generator.predict(noise, verbose=0)
# 生成画像を出力
if index % 500 == 0:
# generate images and shape
generated_images_plot = generated_images.astype('float32') * 127.5 + 127.5
generated_images_plot = generated_images_plot.reshape((BATCH_SIZE, 28, 28))
plt.figure(figsize=(8, 4))
plt.suptitle('epoch=%04d,index=%04d' % (epoch, index), fontsize=20)
for i in range(BATCH_SIZE):
plt.subplot(4, 8, i + 1)
plt.imshow(generated_images_plot[i])
plt.gray()
# eliminate ticks
plt.xticks([]), plt.yticks([])
# save images
if not os.path.exists(GENERATED_IMAGE_PATH):
os.mkdir(GENERATED_IMAGE_PATH)
filename = GENERATED_IMAGE_PATH + "MNIST_%04d_%04d.png" % (epoch,index)
plt.savefig(filename)
# discriminatorを更新
X = np.concatenate((image_batch, generated_images))
y = [1]*BATCH_SIZE + [0]*BATCH_SIZE
d_loss = discriminator.train_on_batch(X, y)
# generatorを更新
noise = np.array([np.random.uniform(-1, 1, 100) for _ in range(BATCH_SIZE)])
g_loss = dcgan.train_on_batch(noise, [1]*BATCH_SIZE)
print("epoch: %d, batch: %d, g_loss: %f, d_loss: %f" % (epoch, index, g_loss, d_loss))
generator.save_weights('generator_fashion_mnist.h5')
discriminator.save_weights('discriminator_fashion_mnist.h5')
train()
構築したGeneratorとDiscriminatorを学習させます。
(X_train, y_train), (_, _) = fashion_mnist.load_data()
X_train = (X_train.astype(np.float32) - 127.5)/127.5
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], X_train.shape[2],1)
print(X_train.shape)
loadした画像は0-1でクリップするのではなく、-1から1でクリップするのがGANでは一般的なようです。
なので、/255.0ではなく、127.5を引いてから/127.5します。
noise = np.array([np.random.uniform(-1, 1, 100) for _ in range(BATCH_SIZE)])
image_batch = X_train[index*BATCH_SIZE:(index+1)*BATCH_SIZE]
generated_images = generator.predict(noise, verbose=0)
-1から1までの100次元の乱数をBATCH_SIZE(=32)個生成します。これがGeneratorの入力になります。shape=(32,100)
データセットの方からも32枚の画像を抽出します。
generated_imagesがGeneratorによって生成された画像です。
if index % 500 == 0:
# generate images and shape
generated_images_plot = generated_images.astype('float32') * 127.5 + 127.5
generated_images_plot = generated_images_plot.reshape((BATCH_SIZE, 28, 28))
plt.figure(figsize=(8, 4))
plt.suptitle('epoch=%04d,index=%04d' % (epoch, index), fontsize=20)
for i in range(BATCH_SIZE):
plt.subplot(4, 8, i + 1)
plt.imshow(generated_images_plot[i])
plt.gray()
# eliminate ticks
plt.xticks([]), plt.yticks([])
# save images
if not os.path.exists(GENERATED_IMAGE_PATH):
os.mkdir(GENERATED_IMAGE_PATH)
filename = GENERATED_IMAGE_PATH + "MNIST_%04d_%04d.png" % (epoch,index)
plt.savefig(filename)
Generatorによって生成された32枚の画像をmatplotlibを使って表示し、保存します。
X = np.concatenate((image_batch, generated_images))
y = [1]*BATCH_SIZE + [0]*BATCH_SIZE
d_loss = discriminator.train_on_batch(X, y)
データセットの画像とGeneratorの生成画像にラベルを付け訓練します。
noise = np.array([np.random.uniform(-1, 1, 100) for _ in range(BATCH_SIZE)])
g_loss = dcgan.train_on_batch(noise, [1]*BATCH_SIZE)
print("epoch: %d, batch: %d, g_loss: %f, d_loss: %f" % (epoch, index, g_loss, d_loss))
Generatorにより生成された画像を本物として扱うことでDiscriminatorを騙そうとしているようです。
学習初期においてgeneratorから生成された画像はかなり質が低いため、簡単にdiscriminatorに見破られてしまいます。少しパラメーターを変えてもどれも見破られてしまうため、どのような変更を加えたらdiscriminatorをだませるような画像を生成できるのか分かりにくい状態にあります。言い換えると、学習初期には勾配が小さくなりがちです
引用:はじめてのGAN
勾配を大きくすることで、詰まりやすい学習初期をスムーズに進められるということですね。
まとめ
GANの生成過程はとてもおもしろいです。まだまだ私は仕組みがよくわかっていないので、今後勉強していきたいところ。