動画
Generalization and Equilibrium in Generative Adversarial Nets (GANs)
torch7のpix2pix
torch7がオリジナル
http://qiita.com/masataka46/items/3d5a2b34d3d7fd29a6e3
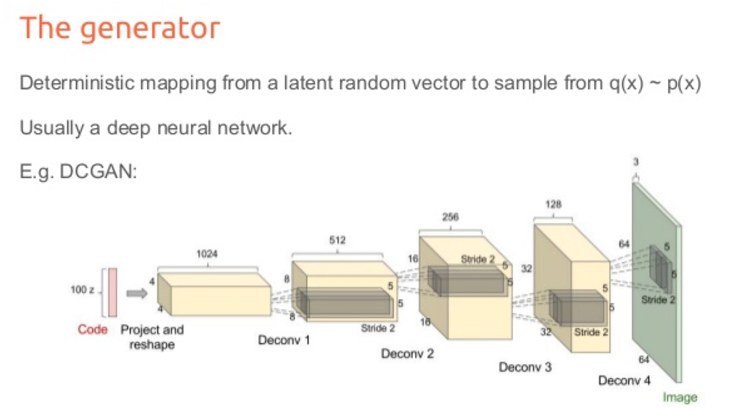
DCGAN
DCGANアーキテクチャ
https://www.slideshare.net/xavigiro/deep-learning-for-computer-vision-generative-models-and-adversarial-training-upc-2016
https://blog.openai.com/generative-models/
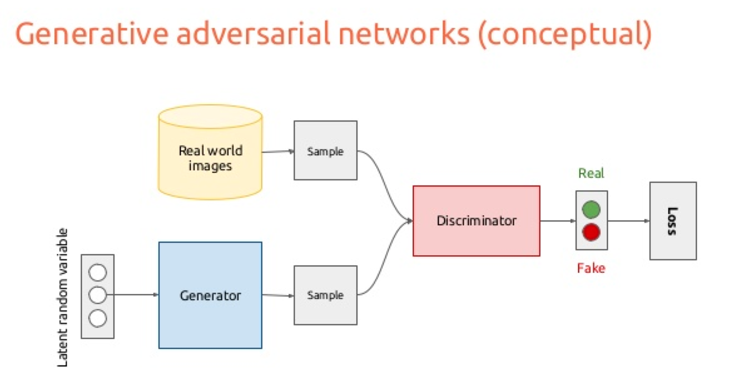
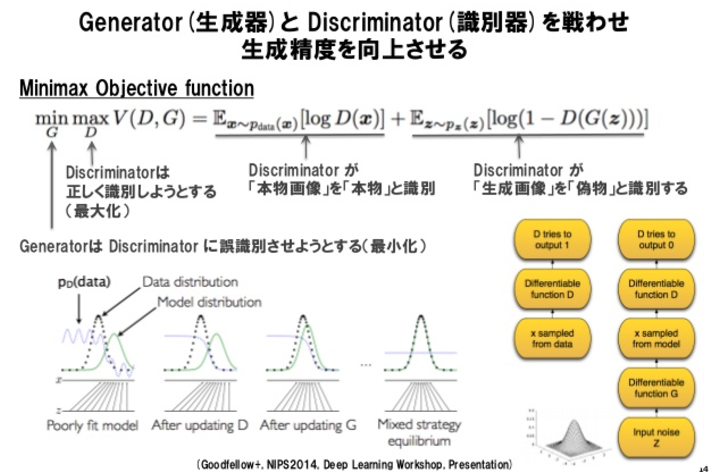
敵対生成で画像を生成する。ノイズを入力し、ジェネレーターで偽の画像を生成。ディスクリミネータで本物の画像を判定する。
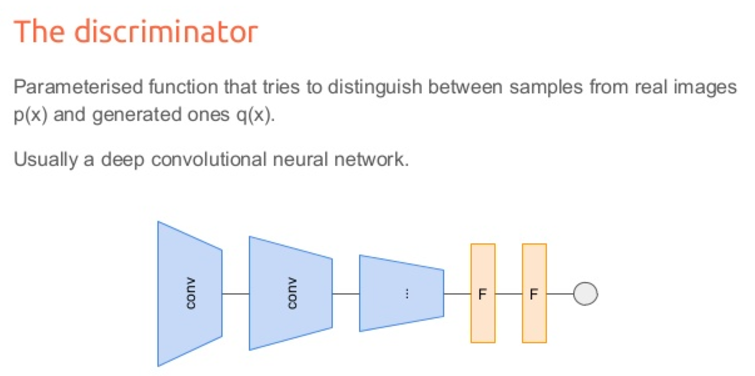
ジェネレータで画像の確率分布を出力。ディスクリミネータで本物ぽいかを判定。
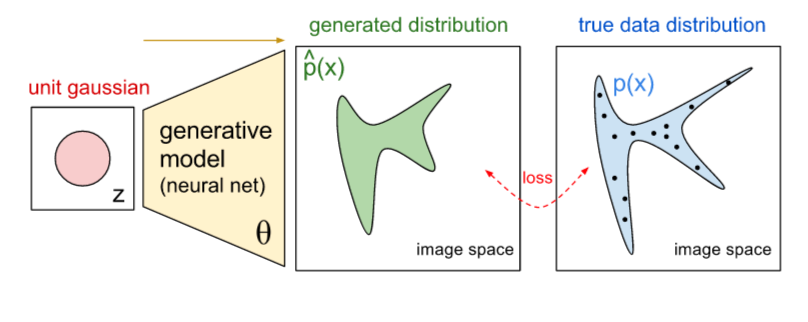
損失関数のわかりやすい説明
eshare.net/hamadakoichi/laplacian-pyramid-of-generative-adversarial-networks-lapgan-nips2015-reading-nipsyomi
DCGANのkerasでの実装 その1
ソース
https://github.com/jacobgil/keras-dcgan
上から定義を見ていく。
生成用のジェネレータ
def generator_model():
model = Sequential()
model.add(Dense(input_dim=100, output_dim=1024))
model.add(Activation('tanh'))
model.add(Dense(128*7*7))
model.add(BatchNormalization())
model.add(Activation('tanh'))
model.add(Reshape((128, 7, 7), input_shape=(128*7*7,)))
model.add(UpSampling2D(size=(2, 2)))
model.add(Convolution2D(64, 5, 5, border_mode='same'))
model.add(Activation('tanh'))
model.add(UpSampling2D(size=(2, 2)))
model.add(Convolution2D(1, 5, 5, border_mode='same'))
model.add(Activation('tanh'))
return model
判定用のディスクリミネータ
def discriminator_model():
model = Sequential()
model.add(Convolution2D(
64, 5, 5,
border_mode='same',
input_shape=(1, 28, 28)))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(128, 5, 5))
model.add(Activation('tanh'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation('tanh'))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
ジェネレータとディスクリミネータを繋いだモデル
誤差伝搬時に使う。
def generator_containing_discriminator(generator, discriminator):
model = Sequential()
model.add(generator)
discriminator.trainable = False
model.add(discriminator)
return model
出力結果を1画像に纏めて保存する関数。
def combine_images(generated_images):
num = generated_images.shape[0]
width = int(math.sqrt(num))
height = int(math.ceil(float(num)/width))
shape = generated_images.shape[2:]
image = np.zeros((height*shape[0], width*shape[1]),
dtype=generated_images.dtype)
for index, img in enumerate(generated_images):
i = int(index/width)
j = index % width
image[i*shape[0]:(i+1)*shape[0], j*shape[1]:(j+1)*shape[1]] = \
img[0, :, :]
return image
学習の定義。
mnistデータを取得。
画像を正規化してX_trainに入れ直す。
ジェネレータとディスクリミネータと2つを結合したモデルを定義。
ジェネレータとディスクリミネータと2つを結合したモデル用の最適化関数をSGDで定義。
バッチサイズ分のノイズを作成。
ノイズをジェネレータに入力。
generated_images = generator.predict(noise, verbose=0)
元画像と出力した画像を結合してXとする。
X = np.concatenate((image_batch, generated_images))
ディスクリミネータにXとyを入力し学習し誤差を出す。
d_loss = discriminator.train_on_batch(X, y)
2つのモデルを結合したモデルの学習をし誤差をだす。
g_loss = discriminator_on_generator.train_on_batch(noise, [1] * BATCH_SIZE)
def train(BATCH_SIZE):
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = (X_train.astype(np.float32) - 127.5)/127.5
X_train = X_train.reshape((X_train.shape[0], 1) + X_train.shape[1:])
discriminator = discriminator_model()
generator = generator_model()
discriminator_on_generator = \
generator_containing_discriminator(generator, discriminator)
d_optim = SGD(lr=0.0005, momentum=0.9, nesterov=True)
g_optim = SGD(lr=0.0005, momentum=0.9, nesterov=True)
generator.compile(loss='binary_crossentropy', optimizer="SGD")
discriminator_on_generator.compile(
loss='binary_crossentropy', optimizer=g_optim)
discriminator.trainable = True
discriminator.compile(loss='binary_crossentropy', optimizer=d_optim)
noise = np.zeros((BATCH_SIZE, 100))
for epoch in range(100):
print("Epoch is", epoch)
print("Number of batches", int(X_train.shape[0]/BATCH_SIZE))
for index in range(int(X_train.shape[0]/BATCH_SIZE)):
for i in range(BATCH_SIZE):
noise[i, :] = np.random.uniform(-1, 1, 100)
image_batch = X_train[index*BATCH_SIZE:(index+1)*BATCH_SIZE]
generated_images = generator.predict(noise, verbose=0)
if index % 20 == 0:
image = combine_images(generated_images)
image = image*127.5+127.5
Image.fromarray(image.astype(np.uint8)).save(
str(epoch)+"_"+str(index)+".png")
X = np.concatenate((image_batch, generated_images))
y = [1] * BATCH_SIZE + [0] * BATCH_SIZE
d_loss = discriminator.train_on_batch(X, y)
print("batch %d d_loss : %f" % (index, d_loss))
for i in range(BATCH_SIZE):
noise[i, :] = np.random.uniform(-1, 1, 100)
discriminator.trainable = False
g_loss = discriminator_on_generator.train_on_batch(
noise, [1] * BATCH_SIZE)
discriminator.trainable = True
print("batch %d g_loss : %f" % (index, g_loss))
if index % 10 == 9:
generator.save_weights('generator', True)
discriminator.save_weights('discriminator', True)
生成部分の定義。学習時にsave_weightsしてるので、load_weightsする。
niceはデフォルトで実行するとFalse。niceを指定すると良い推定値の画像がソートされて纏めて保存される。
def generate(BATCH_SIZE, nice=False):
generator = generator_model()
generator.compile(loss='binary_crossentropy', optimizer="SGD")
generator.load_weights('generator')
if nice:
discriminator = discriminator_model()
discriminator.compile(loss='binary_crossentropy', optimizer="SGD")
discriminator.load_weights('discriminator')
noise = np.zeros((BATCH_SIZE*20, 100))
for i in range(BATCH_SIZE*20):
noise[i, :] = np.random.uniform(-1, 1, 100)
generated_images = generator.predict(noise, verbose=1)
d_pret = discriminator.predict(generated_images, verbose=1)
index = np.arange(0, BATCH_SIZE*20)
index.resize((BATCH_SIZE*20, 1))
pre_with_index = list(np.append(d_pret, index, axis=1))
pre_with_index.sort(key=lambda x: x[0], reverse=True)
nice_images = np.zeros((BATCH_SIZE, 1) +
(generated_images.shape[2:]), dtype=np.float32)
for i in range(int(BATCH_SIZE)):
idx = int(pre_with_index[i][1])
nice_images[i, 0, :, :] = generated_images[idx, 0, :, :]
image = combine_images(nice_images)
else:
noise = np.zeros((BATCH_SIZE, 100))
for i in range(BATCH_SIZE):
noise[i, :] = np.random.uniform(-1, 1, 100)
generated_images = generator.predict(noise, verbose=1)
image = combine_images(generated_images)
image = image*127.5+127.5
Image.fromarray(image.astype(np.uint8)).save(
"generated_image.png")
引数の定義。
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str)
parser.add_argument("--batch_size", type=int, default=128)
parser.add_argument("--nice", dest="nice", action="store_true")
parser.set_defaults(nice=False)
args = parser.parse_args()
return args
実行する。学習の時はtrain。推定の場合はgenerate。
if __name__ == "__main__":
args = get_args()
if args.mode == "train":
train(BATCH_SIZE=args.batch_size)
elif args.mode == "generate":
generate(BATCH_SIZE=args.batch_size, nice=args.nice)
Contact GitHub API Training Shop Blog About
DCGANのkerasでの実装 その2
ちょっと書き方が違うだけです。
ソース
https://github.com/tdeboissiere/DeepLearningImplementations/tree/master/GAN
こっちのコードでは一度画像データをHDF5に変換してから学習するコーディングになってる。
//変換
python make_dataset.py --img_size 64
//学習
python main.py --img_dim 64
train_GAN.pyの中のtrainが呼び出されてるだけ。
import os
import argparse
def launch_training(**kwargs):
# Launch training
train_GAN.train(**kwargs)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Train model')
parser.add_argument('--backend', type=str, default="theano", help="theano or tensorflow")
parser.add_argument('--generator', type=str, default="upsampling", help="upsampling or deconv")
parser.add_argument('--dset', type=str, default="mnist", help="mnist or celebA")
parser.add_argument('--batch_size', default=32, type=int, help='Batch size')
parser.add_argument('--n_batch_per_epoch', default=200, type=int, help="Number of training epochs")
parser.add_argument('--nb_epoch', default=400, type=int, help="Number of batches per epoch")
parser.add_argument('--epoch', default=10, type=int, help="Epoch at which weights were saved for evaluation")
parser.add_argument('--nb_classes', default=2, type=int, help="Number of classes")
parser.add_argument('--do_plot', default=False, type=bool, help="Debugging plot")
parser.add_argument('--bn_mode', default=2, type=int, help="Batch norm mode")
parser.add_argument('--img_dim', default=64, type=int, help="Image width == height")
parser.add_argument('--noise_scale', default=0.5, type=float, help="variance of the normal from which we sample the noise")
parser.add_argument('--label_smoothing', action="store_true", help="smooth the positive labels when training D")
parser.add_argument('--use_mbd', action="store_true", help="use mini batch disc")
parser.add_argument('--label_flipping', default=0, type=float, help="Probability (0 to 1.) to flip the labels when training D")
args = parser.parse_args()
assert args.dset in ["mnist", "celebA"]
# Set the backend by modifying the env variable
if args.backend == "theano":
os.environ["KERAS_BACKEND"] = "theano"
elif args.backend == "tensorflow":
os.environ["KERAS_BACKEND"] = "tensorflow"
# Import the backend
import keras.backend as K
# manually set dim ordering otherwise it is not changed
if args.backend == "theano":
image_dim_ordering = "th"
K.set_image_dim_ordering(image_dim_ordering)
elif args.backend == "tensorflow":
image_dim_ordering = "tf"
K.set_image_dim_ordering(image_dim_ordering)
import train_GAN
# Set default params
d_params = {"mode": "train_GAN",
"dset": args.dset,
"generator": args.generator,
"batch_size": args.batch_size,
"n_batch_per_epoch": args.n_batch_per_epoch,
"nb_epoch": args.nb_epoch,
"model_name": "CNN",
"epoch": args.epoch,
"nb_classes": args.nb_classes,
"do_plot": args.do_plot,
"image_dim_ordering": image_dim_ordering,
"bn_mode": args.bn_mode,
"img_dim": args.img_dim,
"label_smoothing": args.label_smoothing,
"label_flipping": args.label_flipping,
"noise_scale": args.noise_scale,
"use_mbd": args.use_mbd,
}
# Launch training
launch_training(**d_params)
trainではモデルが呼び出されるので先にモデルを見ておく。
デフォルトの設定でupsamplingが選択されてるのでupsamplingを見る。
def generator_upsampling(noise_dim, img_dim, bn_mode, model_name="generator_upsampling", dset="mnist"):
"""
Generator model of the DCGAN
args : img_dim (tuple of int) num_chan, height, width
pretr_weights_file (str) file holding pre trained weights
returns : model (keras NN) the Neural Net model
"""
s = img_dim[1]
f = 512
if dset == "mnist":
start_dim = int(s / 4)
nb_upconv = 2
else:
start_dim = int(s / 16)
nb_upconv = 4
if K.image_dim_ordering() == "th":
bn_axis = 1
reshape_shape = (f, start_dim, start_dim)
output_channels = img_dim[0]
else:
reshape_shape = (start_dim, start_dim, f)
bn_axis = -1
output_channels = img_dim[-1]
gen_input = Input(shape=noise_dim, name="generator_input")
x = Dense(f * start_dim * start_dim, input_dim=noise_dim)(gen_input)
x = Reshape(reshape_shape)(x)
x = BatchNormalization(mode=bn_mode, axis=bn_axis)(x)
x = Activation("relu")(x)
# Upscaling blocks
for i in range(nb_upconv):
x = UpSampling2D(size=(2, 2))(x)
nb_filters = int(f / (2 ** (i + 1)))
x = Convolution2D(nb_filters, 3, 3, border_mode="same")(x)
x = BatchNormalization(mode=bn_mode, axis=1)(x)
x = Activation("relu")(x)
x = Convolution2D(nb_filters, 3, 3, border_mode="same")(x)
x = Activation("relu")(x)
x = Convolution2D(output_channels, 3, 3, name="gen_convolution2d_final", border_mode="same", activation='tanh')(x)
generator_model = Model(input=[gen_input], output=[x], name=model_name)
return generator_model
ディスクリミネータ。
def DCGAN_discriminator(noise_dim, img_dim, bn_mode, model_name="DCGAN_discriminator", dset="mnist", use_mbd=False):
"""
Discriminator model of the DCGAN
args : img_dim (tuple of int) num_chan, height, width
pretr_weights_file (str) file holding pre trained weights
returns : model (keras NN) the Neural Net model
"""
if K.image_dim_ordering() == "th":
bn_axis = 1
else:
bn_axis = -1
disc_input = Input(shape=img_dim, name="discriminator_input")
if dset == "mnist":
list_f = [128]
else:
list_f = [64, 128, 256]
# First conv
x = Convolution2D(32, 3, 3, subsample=(2, 2), name="disc_convolution2d_1", border_mode="same")(disc_input)
x = BatchNormalization(mode=bn_mode, axis=bn_axis)(x)
x = LeakyReLU(0.2)(x)
# Next convs
for i, f in enumerate(list_f):
name = "disc_convolution2d_%s" % (i + 2)
x = Convolution2D(f, 3, 3, subsample=(2, 2), name=name, border_mode="same")(x)
x = BatchNormalization(mode=bn_mode, axis=bn_axis)(x)
x = LeakyReLU(0.2)(x)
x = Flatten()(x)
def minb_disc(x):
diffs = K.expand_dims(x, 3) - K.expand_dims(K.permute_dimensions(x, [1, 2, 0]), 0)
abs_diffs = K.sum(K.abs(diffs), 2)
x = K.sum(K.exp(-abs_diffs), 2)
return x
def lambda_output(input_shape):
return input_shape[:2]
num_kernels = 100
dim_per_kernel = 5
M = Dense(num_kernels * dim_per_kernel, bias=False, activation=None)
MBD = Lambda(minb_disc, output_shape=lambda_output)
if use_mbd:
x_mbd = M(x)
x_mbd = Reshape((num_kernels, dim_per_kernel))(x_mbd)
x_mbd = MBD(x_mbd)
x = merge([x, x_mbd], mode='concat')
x = Dense(2, activation='softmax', name="disc_dense_2")(x)
discriminator_model = Model(input=[disc_input], output=[x], name=model_name)
return discriminator_model
2つのモデルを結合した。
def DCGAN(generator, discriminator_model, noise_dim, img_dim):
noise_input = Input(shape=noise_dim, name="noise_input")
generated_image = generator(noise_input)
DCGAN_output = discriminator_model(generated_image)
DCGAN = Model(input=[noise_input],
output=[DCGAN_output],
name="DCGAN")
return DCGAN
loadで呼び出せるようになってる。
def load(model_name, noise_dim, img_dim, bn_mode, batch_size, dset="mnist", use_mbd=False):
if model_name == "generator_upsampling":
model = generator_upsampling(noise_dim, img_dim, bn_mode, model_name=model_name, dset=dset)
print model.summary()
from keras.utils.visualize_util import plot
plot(model, to_file='../../figures/%s.png' % model_name, show_shapes=True, show_layer_names=True)
return model
if model_name == "generator_deconv":
model = generator_deconv(noise_dim, img_dim, bn_mode, batch_size, model_name=model_name, dset=dset)
print model.summary()
from keras.utils.visualize_util import plot
plot(model, to_file='../../figures/%s.png' % model_name, show_shapes=True, show_layer_names=True)
return model
if model_name == "DCGAN_discriminator":
model = DCGAN_discriminator(noise_dim, img_dim, bn_mode, model_name=model_name, dset=dset, use_mbd=use_mbd)
model.summary()
from keras.utils.visualize_util import plot
plot(model, to_file='../../figures/%s.png' % model_name, show_shapes=True, show_layer_names=True)
return model
学習の方を見ていく。
trainがmain.pyから呼ばれていたが、全処理がtrainに書かれている。
その1の実装とほぼ変わらない。
import models_GAN as modelsのmodelsからDCGANを持ってくる。
二つのモデルを結合した。
DCGAN_model = models.DCGAN(generator_model, discriminator_model, noise_dim, img_dim)
ディスクリミネータを学習。
disc_loss = discriminator_model.train_on_batch(X_disc, y_disc)
2つ結合したモデルを学習。
gen_loss = DCGAN_model.train_on_batch(X_gen, y_gen)
def train(**kwargs):
"""
Train model
Load the whole train data in memory for faster operations
args: **kwargs (dict) keyword arguments that specify the model hyperparameters
"""
# Roll out the parameters
batch_size = kwargs["batch_size"]
n_batch_per_epoch = kwargs["n_batch_per_epoch"]
nb_epoch = kwargs["nb_epoch"]
generator = kwargs["generator"]
model_name = kwargs["model_name"]
image_dim_ordering = kwargs["image_dim_ordering"]
img_dim = kwargs["img_dim"]
bn_mode = kwargs["bn_mode"]
label_smoothing = kwargs["label_smoothing"]
label_flipping = kwargs["label_flipping"]
noise_scale = kwargs["noise_scale"]
dset = kwargs["dset"]
use_mbd = kwargs["use_mbd"]
epoch_size = n_batch_per_epoch * batch_size
# Setup environment (logging directory etc)
general_utils.setup_logging(model_name)
# Load and rescale data
if dset == "celebA":
X_real_train = data_utils.load_celebA(img_dim, image_dim_ordering)
if dset == "mnist":
X_real_train, _, _, _ = data_utils.load_mnist(image_dim_ordering)
img_dim = X_real_train.shape[-3:]
noise_dim = (100,)
try:
# Create optimizers
opt_dcgan = Adam(lr=1E-3, beta_1=0.5, beta_2=0.999, epsilon=1e-08)
opt_discriminator = SGD(lr=1E-3, momentum=0.9, nesterov=True)
# Load generator model
generator_model = models.load("generator_%s" % generator,
noise_dim,
img_dim,
bn_mode,
batch_size,
dset=dset,
use_mbd=use_mbd)
# Load discriminator model
discriminator_model = models.load("DCGAN_discriminator",
noise_dim,
img_dim,
bn_mode,
batch_size,
dset=dset,
use_mbd=use_mbd)
generator_model.compile(loss='mse', optimizer=opt_discriminator)
discriminator_model.trainable = False
DCGAN_model = models.DCGAN(generator_model,
discriminator_model,
noise_dim,
img_dim)
loss = ['binary_crossentropy']
loss_weights = [1]
DCGAN_model.compile(loss=loss, loss_weights=loss_weights, optimizer=opt_dcgan)
discriminator_model.trainable = True
discriminator_model.compile(loss='binary_crossentropy', optimizer=opt_discriminator)
gen_loss = 100
disc_loss = 100
# Start training
print("Start training")
for e in range(nb_epoch):
# Initialize progbar and batch counter
progbar = generic_utils.Progbar(epoch_size)
batch_counter = 1
start = time.time()
for X_real_batch in data_utils.gen_batch(X_real_train, batch_size):
# Create a batch to feed the discriminator model
X_disc, y_disc = data_utils.get_disc_batch(X_real_batch,
generator_model,
batch_counter,
batch_size,
noise_dim,
noise_scale=noise_scale,
label_smoothing=label_smoothing,
label_flipping=label_flipping)
# Update the discriminator
disc_loss = discriminator_model.train_on_batch(X_disc, y_disc)
# Create a batch to feed the generator model
X_gen, y_gen = data_utils.get_gen_batch(batch_size, noise_dim, noise_scale=noise_scale)
# Freeze the discriminator
discriminator_model.trainable = False
gen_loss = DCGAN_model.train_on_batch(X_gen, y_gen)
# Unfreeze the discriminator
discriminator_model.trainable = True
batch_counter += 1
progbar.add(batch_size, values=[("D logloss", disc_loss),
("G logloss", gen_loss)])
# Save images for visualization
if batch_counter % 100 == 0:
data_utils.plot_generated_batch(X_real_batch, generator_model,
batch_size, noise_dim, image_dim_ordering)
if batch_counter >= n_batch_per_epoch:
break
print("")
print('Epoch %s/%s, Time: %s' % (e + 1, nb_epoch, time.time() - start))
if e % 5 == 0:
gen_weights_path = os.path.join('../../models/%s/gen_weights_epoch%s.h5' % (model_name, e))
generator_model.save_weights(gen_weights_path, overwrite=True)
disc_weights_path = os.path.join('../../models/%s/disc_weights_epoch%s.h5' % (model_name, e))
discriminator_model.save_weights(disc_weights_path, overwrite=True)
DCGAN_weights_path = os.path.join('../../models/%s/DCGAN_weights_epoch%s.h5' % (model_name, e))
DCGAN_model.save_weights(DCGAN_weights_path, overwrite=True)
except KeyboardInterrupt:
pass
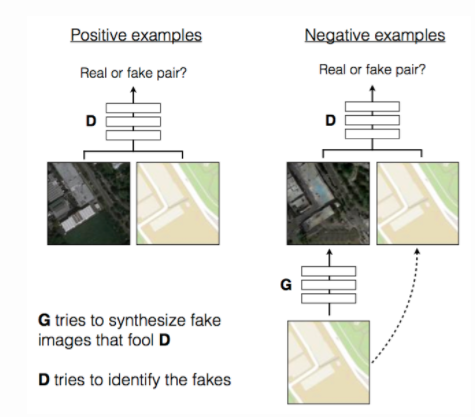
pix2pix
pix2pixアーキテクチャ
ジェネレータにノイズではなく画像を入れる。学習とテスト時にドロップアウトを入れることでノイズとする。
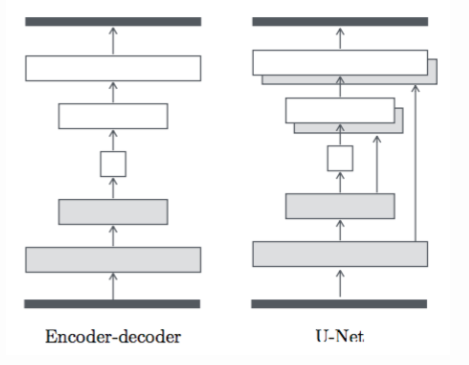
ジェネレータはu-netといいエンコーダデコーダを飛ばして結合する。
pix2pixのkerasでの実装
ソース
https://github.com/tdeboissiere/DeepLearningImplementations/tree/master/pix2pix
DCGANの実装その2とほぼ同じ構成で書かれている。
main.pyはtrain.pyのtrainが呼ばれてる。
import os
import argparse
def launch_training(**kwargs):
# Launch training
train.train(**kwargs)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Train model')
parser.add_argument('patch_size', type=int, nargs=2, action="store", help="Patch size for D")
parser.add_argument('--backend', type=str, default="theano", help="theano or tensorflow")
parser.add_argument('--generator', type=str, default="upsampling", help="upsampling or deconv")
parser.add_argument('--dset', type=str, default="facades", help="facades")
parser.add_argument('--batch_size', default=4, type=int, help='Batch size')
parser.add_argument('--n_batch_per_epoch', default=100, type=int, help="Number of training epochs")
parser.add_argument('--nb_epoch', default=400, type=int, help="Number of batches per epoch")
parser.add_argument('--epoch', default=10, type=int, help="Epoch at which weights were saved for evaluation")
parser.add_argument('--nb_classes', default=2, type=int, help="Number of classes")
parser.add_argument('--do_plot', action="store_true", help="Debugging plot")
parser.add_argument('--bn_mode', default=2, type=int, help="Batch norm mode")
parser.add_argument('--img_dim', default=64, type=int, help="Image width == height")
parser.add_argument('--use_mbd', action="store_true", help="Whether to use minibatch discrimination")
parser.add_argument('--use_label_smoothing', action="store_true", help="Whether to smooth the positive labels when training D")
parser.add_argument('--label_flipping', default=0, type=float, help="Probability (0 to 1.) to flip the labels when training D")
args = parser.parse_args()
# Set the backend by modifying the env variable
if args.backend == "theano":
os.environ["KERAS_BACKEND"] = "theano"
elif args.backend == "tensorflow":
os.environ["KERAS_BACKEND"] = "tensorflow"
# Import the backend
import keras.backend as K
# manually set dim ordering otherwise it is not changed
if args.backend == "theano":
image_dim_ordering = "th"
K.set_image_dim_ordering(image_dim_ordering)
elif args.backend == "tensorflow":
image_dim_ordering = "tf"
K.set_image_dim_ordering(image_dim_ordering)
import train
# Set default params
d_params = {"dset": args.dset,
"generator": args.generator,
"batch_size": args.batch_size,
"n_batch_per_epoch": args.n_batch_per_epoch,
"nb_epoch": args.nb_epoch,
"model_name": "CNN",
"epoch": args.epoch,
"nb_classes": args.nb_classes,
"do_plot": args.do_plot,
"image_dim_ordering": image_dim_ordering,
"bn_mode": args.bn_mode,
"img_dim": args.img_dim,
"use_label_smoothing": args.use_label_smoothing,
"label_flipping": args.label_flipping,
"patch_size": args.patch_size,
"use_mbd": args.use_mbd
}
# Launch training
launch_training(**d_params)
モデルを見てみる。
ジェネレータ。DCGANと比べてu-netに変わってる。
def generator_unet_upsampling(img_dim, bn_mode, model_name="generator_unet_upsampling"):
nb_filters = 64
if K.image_dim_ordering() == "th":
bn_axis = 1
nb_channels = img_dim[0]
min_s = min(img_dim[1:])
else:
bn_axis = -1
nb_channels = img_dim[-1]
min_s = min(img_dim[:-1])
unet_input = Input(shape=img_dim, name="unet_input")
# Prepare encoder filters
nb_conv = int(np.floor(np.log(min_s) / np.log(2)))
list_nb_filters = [nb_filters * min(8, (2 ** i)) for i in range(nb_conv)]
# Encoder
list_encoder = [Convolution2D(list_nb_filters[0], 3, 3,
subsample=(2, 2), name="unet_conv2D_1", border_mode="same")(unet_input)]
for i, f in enumerate(list_nb_filters[1:]):
name = "unet_conv2D_%s" % (i + 2)
conv = conv_block_unet(list_encoder[-1], f, name, bn_mode, bn_axis)
list_encoder.append(conv)
# Prepare decoder filters
list_nb_filters = list_nb_filters[:-2][::-1]
if len(list_nb_filters) < nb_conv - 1:
list_nb_filters.append(nb_filters)
# Decoder
list_decoder = [up_conv_block_unet(list_encoder[-1], list_encoder[-2],
list_nb_filters[0], "unet_upconv2D_1", bn_mode, bn_axis, dropout=True)]
for i, f in enumerate(list_nb_filters[1:]):
name = "unet_upconv2D_%s" % (i + 2)
# Dropout only on first few layers
if i < 2:
d = True
else:
d = False
conv = up_conv_block_unet(list_decoder[-1], list_encoder[-(i + 3)], f, name, bn_mode, bn_axis, dropout=d)
list_decoder.append(conv)
x = Activation("relu")(list_decoder[-1])
x = UpSampling2D(size=(2, 2))(x)
x = Convolution2D(nb_channels, 3, 3, name="last_conv", border_mode="same")(x)
x = Activation("tanh")(x)
generator_unet = Model(input=[unet_input], output=[x])
return generator_unet
ディスクリミネータ。
def DCGAN_discriminator(img_dim, nb_patch, bn_mode, model_name="DCGAN_discriminator", use_mbd=True):
"""
Discriminator model of the DCGAN
args : img_dim (tuple of int) num_chan, height, width
pretr_weights_file (str) file holding pre trained weights
returns : model (keras NN) the Neural Net model
"""
list_input = [Input(shape=img_dim, name="disc_input_%s" % i) for i in range(nb_patch)]
if K.image_dim_ordering() == "th":
bn_axis = 1
else:
bn_axis = -1
nb_filters = 64
nb_conv = int(np.floor(np.log(img_dim[1]) / np.log(2)))
list_filters = [nb_filters * min(8, (2 ** i)) for i in range(nb_conv)]
# First conv
x_input = Input(shape=img_dim, name="discriminator_input")
x = Convolution2D(list_filters[0], 3, 3, subsample=(2, 2), name="disc_conv2d_1", border_mode="same")(x_input)
x = BatchNormalization(mode=bn_mode, axis=bn_axis)(x)
x = LeakyReLU(0.2)(x)
# Next convs
for i, f in enumerate(list_filters[1:]):
name = "disc_conv2d_%s" % (i + 2)
x = Convolution2D(f, 3, 3, subsample=(2, 2), name=name, border_mode="same")(x)
x = BatchNormalization(mode=bn_mode, axis=bn_axis)(x)
x = LeakyReLU(0.2)(x)
x_flat = Flatten()(x)
x = Dense(2, activation='softmax', name="disc_dense")(x_flat)
PatchGAN = Model(input=[x_input], output=[x, x_flat], name="PatchGAN")
print("PatchGAN summary")
PatchGAN.summary()
x = [PatchGAN(patch)[0] for patch in list_input]
x_mbd = [PatchGAN(patch)[1] for patch in list_input]
if len(x) > 1:
x = merge(x, mode="concat", name="merge_feat")
else:
x = x[0]
if use_mbd:
if len(x_mbd) > 1:
x_mbd = merge(x_mbd, mode="concat", name="merge_feat_mbd")
else:
x_mbd = x_mbd[0]
num_kernels = 100
dim_per_kernel = 5
M = Dense(num_kernels * dim_per_kernel, bias=False, activation=None)
MBD = Lambda(minb_disc, output_shape=lambda_output)
x_mbd = M(x_mbd)
x_mbd = Reshape((num_kernels, dim_per_kernel))(x_mbd)
x_mbd = MBD(x_mbd)
x = merge([x, x_mbd], mode='concat')
x_out = Dense(2, activation="softmax", name="disc_output")(x)
discriminator_model = Model(input=list_input, output=[x_out], name=model_name)
return discriminator_model
2つのモデルの結合。
def DCGAN(generator, discriminator_model, img_dim, patch_size, image_dim_ordering):
gen_input = Input(shape=img_dim, name="DCGAN_input")
generated_image = generator(gen_input)
if image_dim_ordering == "th":
h, w = img_dim[1:]
else:
h, w = img_dim[:-1]
ph, pw = patch_size
list_row_idx = [(i * ph, (i + 1) * ph) for i in range(h / ph)]
list_col_idx = [(i * pw, (i + 1) * pw) for i in range(w / pw)]
list_gen_patch = []
for row_idx in list_row_idx:
for col_idx in list_col_idx:
if image_dim_ordering == "tf":
x_patch = Lambda(lambda z: z[:, row_idx[0]:row_idx[1], col_idx[0]:col_idx[1], :])(generated_image)
else:
x_patch = Lambda(lambda z: z[:, :, row_idx[0]:row_idx[1], col_idx[0]:col_idx[1]])(generated_image)
list_gen_patch.append(x_patch)
DCGAN_output = discriminator_model(list_gen_patch)
DCGAN = Model(input=[gen_input],
output=[generated_image, DCGAN_output],
name="DCGAN")
return DCGAN
main.pyから呼ぶ用のload。
def load(model_name, img_dim, nb_patch, bn_mode, use_mbd, batch_size):
if model_name == "generator_unet_upsampling":
model = generator_unet_upsampling(img_dim, bn_mode, model_name=model_name)
print model.summary()
from keras.utils.visualize_util import plot
plot(model, to_file='../../figures/%s.png' % model_name, show_shapes=True, show_layer_names=True)
return model
if model_name == "generator_unet_deconv":
model = generator_unet_deconv(img_dim, bn_mode, batch_size, model_name=model_name)
print model.summary()
from keras.utils.visualize_util import plot
plot(model, to_file='../../figures/%s.png' % model_name, show_shapes=True, show_layer_names=True)
return model
if model_name == "DCGAN_discriminator":
model = DCGAN_discriminator(img_dim, nb_patch, bn_mode, model_name=model_name, use_mbd=use_mbd)
model.summary()
from keras.utils.visualize_util import plot
plot(model, to_file='../../figures/%s.png' % model_name, show_shapes=True, show_layer_names=True)
return model
if __name__ == '__main__':
# load("generator_unet_deconv", (256, 256, 3), 16, 2, False, 32)
load("generator_unet_upsampling", (256, 256, 3), 16, 2, False, 32)
2つを結合。
DCGAN_model = models.DCGAN(generator_model, discriminator_model, img_dim, patch_size, image_dim_ordering)
ディスクリミネータを学習。
disc_loss = discriminator_model.train_on_batch(X_disc, y_disc)
2つ結合したモデルを学習。
gen_loss = DCGAN_model.train_on_batch(X_gen, [X_gen_target, y_gen])
import os
import sys
import time
import numpy as np
import models
from keras.utils import generic_utils
from keras.optimizers import Adam, SGD
import keras.backend as K
# Utils
sys.path.append("../utils")
import general_utils
import data_utils
def l1_loss(y_true, y_pred):
return K.sum(K.abs(y_pred - y_true), axis=-1)
def train(**kwargs):
"""
Train model
Load the whole train data in memory for faster operations
args: **kwargs (dict) keyword arguments that specify the model hyperparameters
"""
# Roll out the parameters
batch_size = kwargs["batch_size"]
n_batch_per_epoch = kwargs["n_batch_per_epoch"]
nb_epoch = kwargs["nb_epoch"]
model_name = kwargs["model_name"]
generator = kwargs["generator"]
image_dim_ordering = kwargs["image_dim_ordering"]
img_dim = kwargs["img_dim"]
patch_size = kwargs["patch_size"]
bn_mode = kwargs["bn_mode"]
label_smoothing = kwargs["use_label_smoothing"]
label_flipping = kwargs["label_flipping"]
dset = kwargs["dset"]
use_mbd = kwargs["use_mbd"]
epoch_size = n_batch_per_epoch * batch_size
# Setup environment (logging directory etc)
general_utils.setup_logging(model_name)
# Load and rescale data
X_full_train, X_sketch_train, X_full_val, X_sketch_val = data_utils.load_data(dset, image_dim_ordering)
img_dim = X_full_train.shape[-3:]
# Get the number of non overlapping patch and the size of input image to the discriminator
nb_patch, img_dim_disc = data_utils.get_nb_patch(img_dim, patch_size, image_dim_ordering)
try:
# Create optimizers
opt_dcgan = Adam(lr=1E-3, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
# opt_discriminator = SGD(lr=1E-3, momentum=0.9, nesterov=True)
opt_discriminator = Adam(lr=1E-3, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
# Load generator model
generator_model = models.load("generator_unet_%s" % generator,
img_dim,
nb_patch,
bn_mode,
use_mbd,
batch_size)
# Load discriminator model
discriminator_model = models.load("DCGAN_discriminator",
img_dim_disc,
nb_patch,
bn_mode,
use_mbd,
batch_size)
generator_model.compile(loss='mae', optimizer=opt_discriminator)
discriminator_model.trainable = False
DCGAN_model = models.DCGAN(generator_model,
discriminator_model,
img_dim,
patch_size,
image_dim_ordering)
loss = [l1_loss, 'binary_crossentropy']
loss_weights = [1E1, 1]
DCGAN_model.compile(loss=loss, loss_weights=loss_weights, optimizer=opt_dcgan)
discriminator_model.trainable = True
discriminator_model.compile(loss='binary_crossentropy', optimizer=opt_discriminator)
gen_loss = 100
disc_loss = 100
# Start training
print("Start training")
for e in range(nb_epoch):
# Initialize progbar and batch counter
progbar = generic_utils.Progbar(epoch_size)
batch_counter = 1
start = time.time()
for X_full_batch, X_sketch_batch in data_utils.gen_batch(X_full_train, X_sketch_train, batch_size):
# Create a batch to feed the discriminator model
X_disc, y_disc = data_utils.get_disc_batch(X_full_batch,
X_sketch_batch,
generator_model,
batch_counter,
patch_size,
image_dim_ordering,
label_smoothing=label_smoothing,
label_flipping=label_flipping)
# Update the discriminator
disc_loss = discriminator_model.train_on_batch(X_disc, y_disc)
# Create a batch to feed the generator model
X_gen_target, X_gen = next(data_utils.gen_batch(X_full_train, X_sketch_train, batch_size))
y_gen = np.zeros((X_gen.shape[0], 2), dtype=np.uint8)
y_gen[:, 1] = 1
# Freeze the discriminator
discriminator_model.trainable = False
gen_loss = DCGAN_model.train_on_batch(X_gen, [X_gen_target, y_gen])
# Unfreeze the discriminator
discriminator_model.trainable = True
batch_counter += 1
progbar.add(batch_size, values=[("D logloss", disc_loss),
("G tot", gen_loss[0]),
("G L1", gen_loss[1]),
("G logloss", gen_loss[2])])
# Save images for visualization
if batch_counter % (n_batch_per_epoch / 2) == 0:
# Get new images from validation
data_utils.plot_generated_batch(X_full_batch, X_sketch_batch, generator_model,
batch_size, image_dim_ordering, "training")
X_full_batch, X_sketch_batch = next(data_utils.gen_batch(X_full_val, X_sketch_val, batch_size))
data_utils.plot_generated_batch(X_full_batch, X_sketch_batch, generator_model,
batch_size, image_dim_ordering, "validation")
if batch_counter >= n_batch_per_epoch:
break
print("")
print('Epoch %s/%s, Time: %s' % (e + 1, nb_epoch, time.time() - start))
if e % 5 == 0:
gen_weights_path = os.path.join('../../models/%s/gen_weights_epoch%s.h5' % (model_name, e))
generator_model.save_weights(gen_weights_path, overwrite=True)
disc_weights_path = os.path.join('../../models/%s/disc_weights_epoch%s.h5' % (model_name, e))
discriminator_model.save_weights(disc_weights_path, overwrite=True)
DCGAN_weights_path = os.path.join('../../models/%s/DCGAN_weights_epoch%s.h5' % (model_name, e))
DCGAN_model.save_weights(DCGAN_weights_path, overwrite=True)
except KeyboardInterrupt:
pass
データを取得する場所がhdf5に変換するようになってる。
chainerのコード
git clone https://github.com/pfnet-research/chainer-pix2pix.git
cd chainer-pix2pix
データセットを落として学習を実行
python train_facade.py -g 0 -i CMP_facade_DB_base/base --out image_out --snapshot_interval 10000
学習済みモデルを読み込んでファインチューニング
python train_facade.py -g 0 -i CMP_facade_DB_base/base --out image_out --snapshot_interval 10000 -r image_out/snapshot_iter_30000.npz