これは初めて日本語を使用してブログを書きます。間違いところはぜひお教えください。
理解するのが非常に難しいと感じたら、お知らせください。
本当にごめんなさい![]()
最近色々EngineはGPU Driven関するテクノロジーを実装しました。
- Ubisoft: [Siggraph15] GPU-Driven Rendering Pipelines
- Frostbite: Optimizing the Graphics Pipeline with Compute
自分も興味が持っているから、簡単な部分を実装しました。
動機
今はGPUの機能が高いです。そしてGPUメモリサイズも大いになります。
しかし、以前のGPUはグラフィックプロセッサーだけです。CPUでデータを準備した後、GPUメモリへ送り込みます。GPUはそのデータを変わりなく、簡単にレンダリングします。GPUのテスクを減少するために、CPUはカメラが見えないものを削除します。それはCPU Drivenと呼びます。
CPUのパラレル能力は少し弱いですから、多い物がある場合は遅いです。「GPUも少し手伝いではいいじゃない?」と思います。それから、GPUがデプステクスチャを作成した後、CPUがそのものを使用してカリングする技術もあります。DirectX11にCompute Shaderがありますから、GPUで実行もできます。それはHierarchical Z-Buffer Occlusion Cullingです。
今はRTX時代です。Raytracingを使用すれば、カメラ見えないものも影響を与えるかもしれません。それから、全てデータはGPUメモリに置きなければならないです。でもそれじゃCPUでカリングするは無理です。「GPU→CPU→GPU」この転送速度はあまり遅いです。GPUでカリングする技術は必要になります。
でもGPU Drivenはカリングだけではなく、色々技術があります。例えば、Virtual Texture。今回は視錐台カリングだけを説明します。
CPUからGPUまで
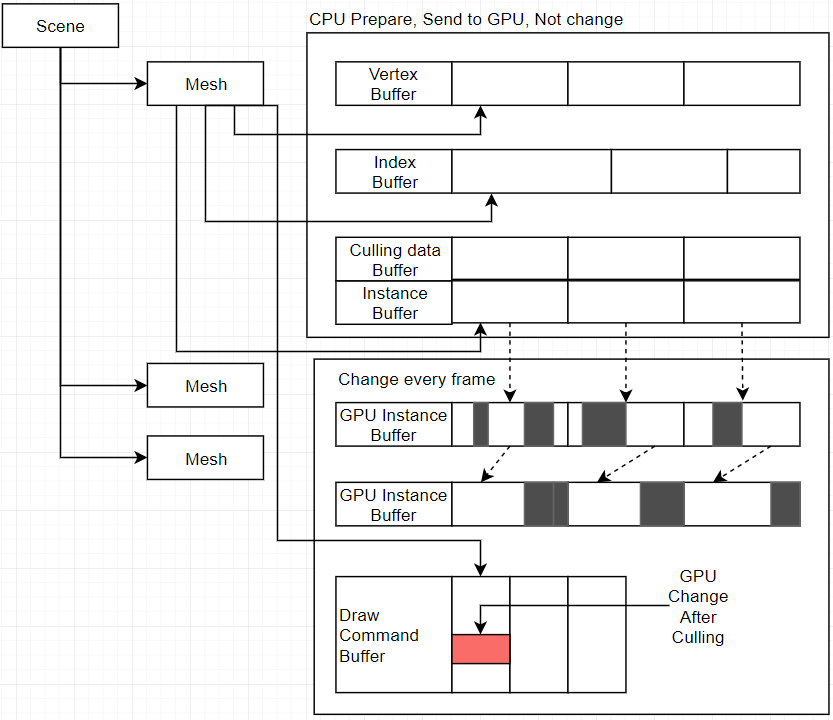
最初のバージョン
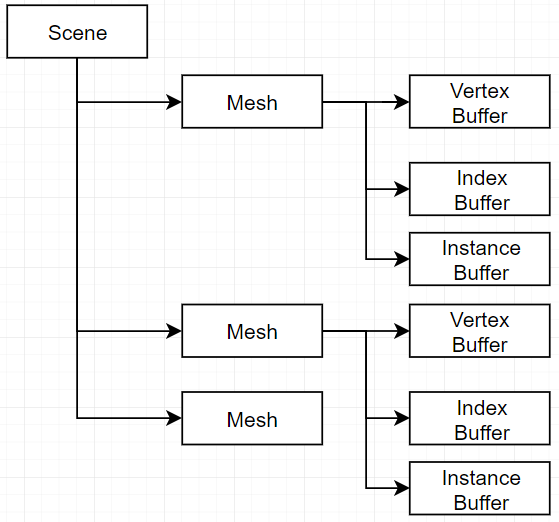
これは最初のバージョンです。初めてDXを勉強する人が好きなアーキテクチャです。Meshは自分のBufferを持っています。バッファ管理は簡単です。でもこのアーキテクチャは遅いです。Meshのレンダリングは毎回バッファポインターを設定するから、Draw Callは高いです。
実は僕のVertex Structure(InputLayout)とInstance Structureは同じです。 それから全てMeshのバッファは同じ場所になることができます。
同じバッファバージョン
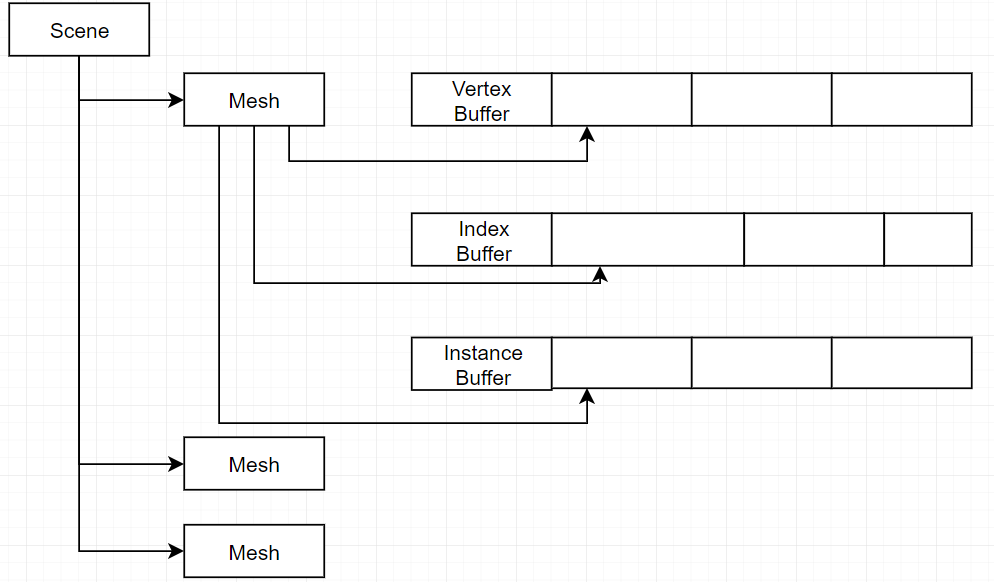
次はこれです。初期化の時大いバッファを準備しました。その後、新しいMeshを生成する時バッファのオフセットを記録します。そして、Meshデータが同じ場合はInstanceを記録するだけです。これは自動的にMergeです。Draw Callの数量を減少します。
しかし、カリングも遅くになります。CPUでカリングする後GPUのメモリに更新します。そのメモリ転送はあまり遅いですから、避けたいです。
GPU カリング
GPUでカリングするために、GPUバッファは準備しなければならない。それじゃこのバージョンになります。
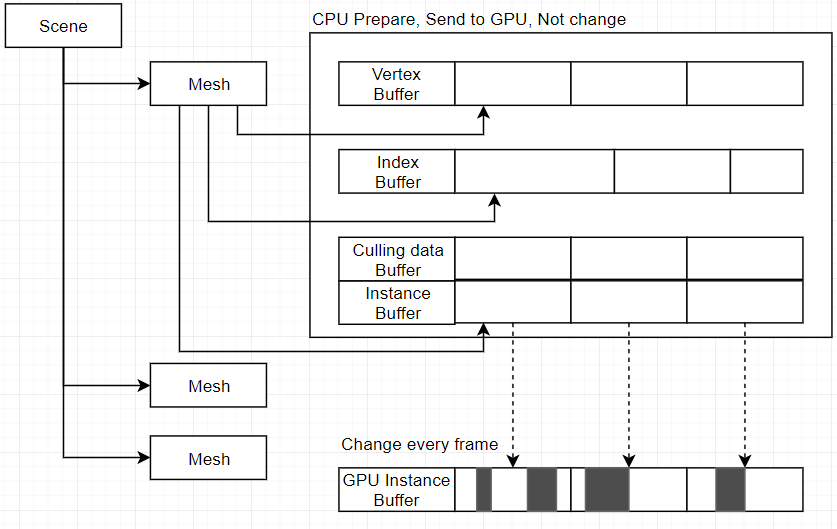
CPUはカリングする必要なデータを準備して、GPUメモリへ転送します。CPU準備するデータは一回だけです。新しいMeshを生成する時以外更新しません。GPUはカメラに基づいて見えないものを削除します。見えるものはGPU Instance Bufferに書きます。それは白い部分です。
問題来臨
実はこのバージョンが実行できません。2つ問題があります。
Indirect Draw
先ず、CPUは白い部分の数量をわからない、最大限数量をレンダリングと請求します。それじゃカリングの意味は無し。GPUから新しい数量を転送するも遅いです。
これはDrawIndexedInstancedIndirectを使用する場合です。
普通なDrawIndexedInstancedはこの引数を使用します:
deviceContext->DrawIndexedInstanced(
indexCount,
instanceCount,
indexStart,
vertexStart,
instanceStart
);
でもDrawIndexedInstancedIndirectは、GPUバッファを使用します。あのバッファに普通なDrawIndexedInstancedと同じ引数データを置きます。CPUはバッファを準備した後、GPUがカリングして新しいInstance数量は更新します。
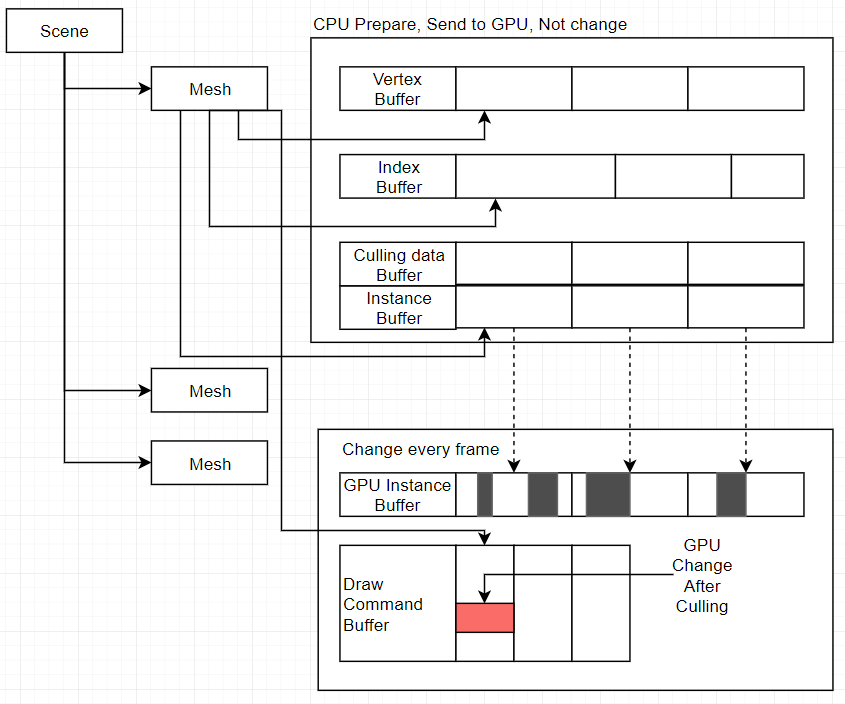
Compute Shader Compact
でも、DrawIndexedInstancedは、バッファの最先端から、instanceCount枚数量のInstanceをレンダリングします。黒いInstanceはバッファの最後に転送しなけねばならない。
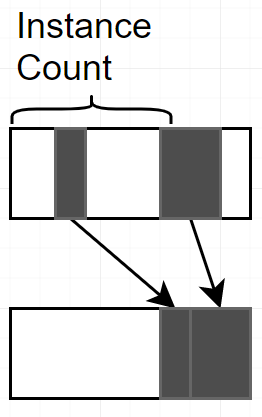
このタスクはGPUで実行しなけねばならない。Compute Shader Compactと呼びます。僕のCompute ShaderはカリングしてCompactします。内容はこれ
struct InstanceType
{
//D3DXVECTOR3 Position;
float4x4 ObjectTransformMatrix;
};
struct CullingType
{
float Radius;
unsigned int DrawIndex;
};
struct DrawArgs
{
unsigned int IndexCountPerInstance;
unsigned int InstanceCount;
unsigned int StartIndexLocation;
unsigned int BaseVertexLocation;
unsigned int StartInstanceLocation;
};
cbuffer CS_CONSTANT_BUFFER : register(b0)
{
float4 m_planes[6];
float4x4 worldMatrix;
unsigned int IndexCountPerInstance;
unsigned int InstanceCount;
unsigned int DrawArgsCount;
unsigned int Flag;
unsigned int Misc[4];
}
//StructuredBuffer<InstanceType> srcInstances : register(t0);
Buffer<float4> srcInstances : register(t0);
StructuredBuffer<CullingType> srcCullings : register(t1);
Buffer<uint> srcCommand : register(t2);
RWBuffer<float4> outInstances : register(u0);
RWBuffer<uint> outCommand : register(u1);
InstanceType ProcessInstance(InstanceType data)
{
return data;
}
float D3DXPlaneDotCoord(float4 p, float3 v)
{
return dot(p.xyz, v) + p.w;
}
bool FrustumCullingSphere(InstanceType instance, float radius)
{
int i = 0;
bool result = true;
float4 pos = float4(instance.ObjectTransformMatrix._41, instance.ObjectTransformMatrix._42, instance.ObjectTransformMatrix._43, 1.0f);
if (Flag == 1)
{
pos.y = 0.0f;
}
pos = mul(worldMatrix, pos);
[unroll(6)]
for(i =0; i< 6; i++)
{
if (D3DXPlaneDotCoord(m_planes[i], pos.xyz) < -radius)
{
result = false;
}
}
return result;
}
static uint g_CommandCount;
groupshared uint localValidInstances;
groupshared uint globalSlots;
groupshared uint globalSlot;
[numthreads(256, 1, 1)]
void main(uint dispatchThreadID : SV_DispatchThreadID , uint threadId : SV_GroupThreadID)
{
float4x4 identityMatrix =
{
1.0f ,0.0f ,0.0f , 0.0f,
0.0f ,1.0f ,0.0f , 0.0f,
0.0f ,0.0f ,1.0f , 0.0f,
0.0f ,0.0f ,0.0f , 1.0f
};
uint index = dispatchThreadID;
bool Inside, NeedCulling = true;
bool Invalid = false;
uint localSlot = 0;
//.x + dispatchThreadID.y * 32 * 32;
DrawArgs args;
args.IndexCountPerInstance = srcCommand[DrawArgsCount * 5 + 0];
args.InstanceCount = srcCommand[DrawArgsCount * 5 + 1];
args.StartIndexLocation = srcCommand[DrawArgsCount * 5 + 2];
args.BaseVertexLocation = srcCommand[DrawArgsCount * 5 + 3];
args.StartInstanceLocation = srcCommand[DrawArgsCount * 5 + 4];
CullingType cullingData = srcCullings[args.StartInstanceLocation + index];
InstanceType InputInstance;
uint RealInstanceIndex = args.StartInstanceLocation + index;
InputInstance.ObjectTransformMatrix = float4x4(srcInstances[(args.StartInstanceLocation + index) * 4], srcInstances[(args.StartInstanceLocation + index) * 4 + 1], srcInstances[(args.StartInstanceLocation + index) * 4 + 2], srcInstances[(args.StartInstanceLocation + index) * 4 + 3]);
if (threadId == 0)
{
localValidInstances = 0;
globalSlot = 0;
g_CommandCount = 0;
}
// Fast path for single Instance
if (args.InstanceCount == 1)
{
outInstances[RealInstanceIndex * 4] = srcInstances[RealInstanceIndex * 4];
outInstances[RealInstanceIndex * 4 + 1] = srcInstances[RealInstanceIndex * 4 + 1];
outInstances[RealInstanceIndex * 4 + 2] = srcInstances[RealInstanceIndex * 4 + 2];
outInstances[RealInstanceIndex * 4 + 3] = srcInstances[RealInstanceIndex * 4 + 3];
if (index == 0)
{
outCommand[DrawArgsCount * 5 + 1] = 1;
}
Invalid = true;
}
else if (index >= args.InstanceCount)
{
Invalid = true;
NeedCulling = false;
}
else if (cullingData.Radius < 0.0f)
{
NeedCulling = false;
}
if (Invalid == false && index == 0)
{
outCommand[DrawArgsCount * 5 + 1] = 0;
}
GroupMemoryBarrierWithGroupSync();
if (Invalid == false && NeedCulling)
{
if (cullingData.Radius < 0.0f)
{
Inside = true;
}
else
{
Inside = FrustumCullingSphere(InputInstance, cullingData.Radius);
}
}
if (Invalid == false)
{
if (Inside || NeedCulling == false)
{
InterlockedAdd(localValidInstances, 1, localSlot);
}
}
GroupMemoryBarrierWithGroupSync();
if (threadId == 0 && Invalid == false)
{
InterlockedAdd(
outCommand[DrawArgsCount * 5 + 1],
localValidInstances,
globalSlot
);
}
GroupMemoryBarrierWithGroupSync();
//if (index == 0)
//{
// outCommand[DrawArgsCount * 5 + 1] = g_CommandCount;
//}
if (Invalid)
{
return;
}
if (NeedCulling == false || Inside)
{
uint target_pos = args.StartInstanceLocation + globalSlot + localSlot;
outInstances[target_pos * 4] = srcInstances[RealInstanceIndex * 4];
outInstances[target_pos * 4 + 1] = srcInstances[RealInstanceIndex * 4 + 1];
outInstances[target_pos * 4 + 2] = srcInstances[RealInstanceIndex * 4 + 2];
outInstances[target_pos * 4 + 3] = srcInstances[RealInstanceIndex * 4 + 3];
}
}
その部分は少し難しいです。こちらに詳しく紹介します。
最後
最後のバージョンはこのものです
CPU: i7 3770
GPU:HD4000 オンボードGPU
パフォーマンス テスト
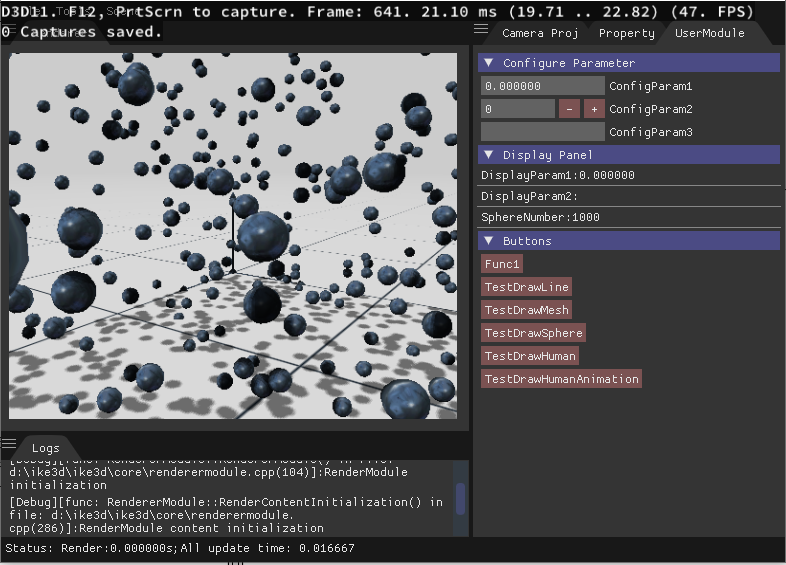
1000枚Sphere
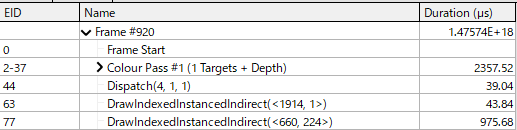
カリング時間は0.04 ms。カリング後数量は224です。
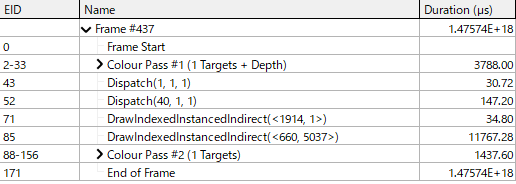
10000枚
カリング時間は0.14 ms。カリング後数量は5037です。
オンボードGPU?
最新のGPUのパフォーマンスは高いですから、スピード差異は小さいです。
そして、研究室のパソコンはオンボードGPUだけです。