皆さんこんにちは!先回は簡単なGPU Driven Cullingの原理を説明しましたが、ComputeShaderの部分は難しいですから、説明しない。今回は先回解釈しないCompute Shader部分を説明します。
Compute Shader
先ずComputeShaderというのもを説明します。ComputeShaderは通用計算のシェーダーです。テクスチャだけではなく、普通なバッファの訪問もできます。特別な関数もあります。
GPUには、たくさんコロールがあります。それから、パラレルでComputeShaderを実行することができます。ComputeShaderは対応のスレッドに実行するが、全て1回実行するわけではないです。GPUはスレッドをグループに入れって、たくさんグループをパラレル実行します。しかし、全てグループを一回だけに実行するもわけではない。それは注意点です。スレッドの詳しい実行方法はこちらです。
Compact
先回の問題また説明します。
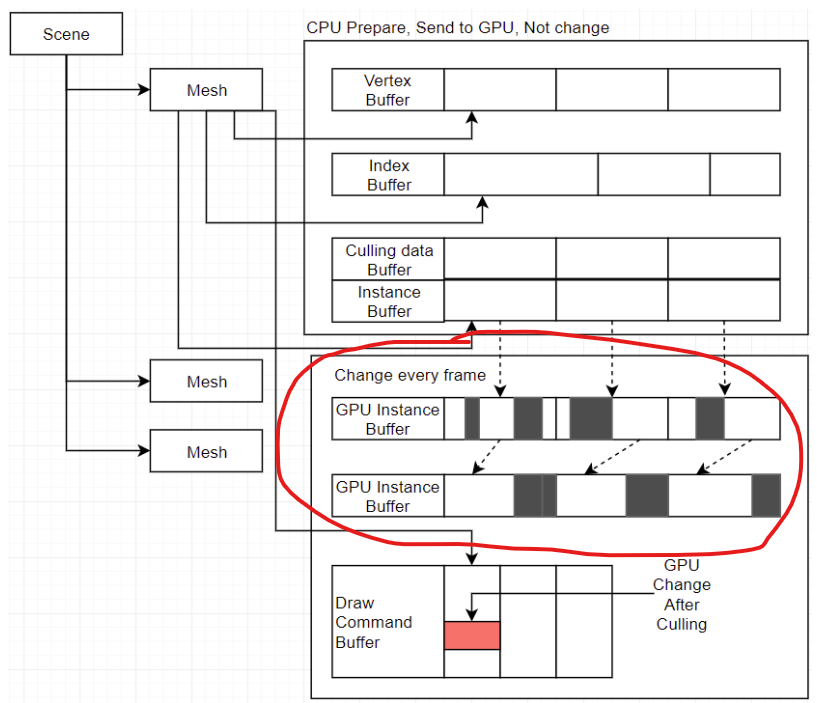
今回の問題点はどのようなComputeShaderを使用してコンパクトします。説明は簡単になるために、会社の役割分担プランを使用して説明します。
まず皆さんは自分の対応の仕事をしました。その後はコンパクトします。つまり、皆さんが確認した書類をまとめます。
リーダー
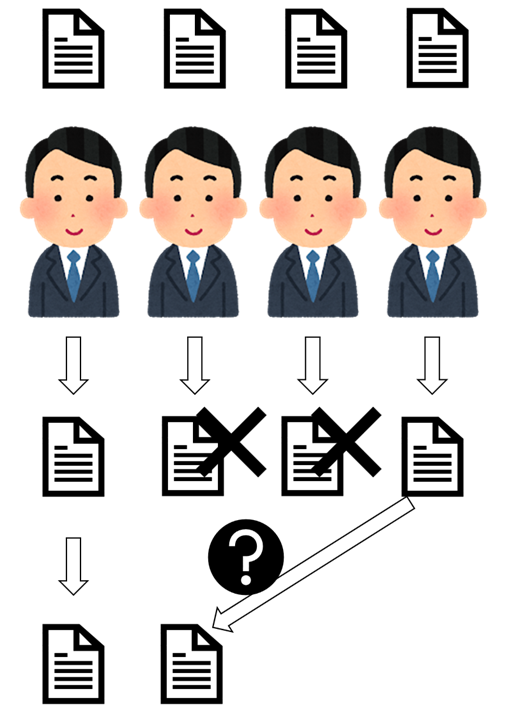
簡単な方法は、リーダーさんはその後、一々でまとめます。他の社員さんは何もしない、休みます。
リーダーさんは「重い仕事ですね!」と思います。優しい先輩ですが、遅いです。そして、書類数量は多い場合は、あまり遅いです。
少し考えました、問題点は書類の転送です。皆さん、助けてください!!!
ボス
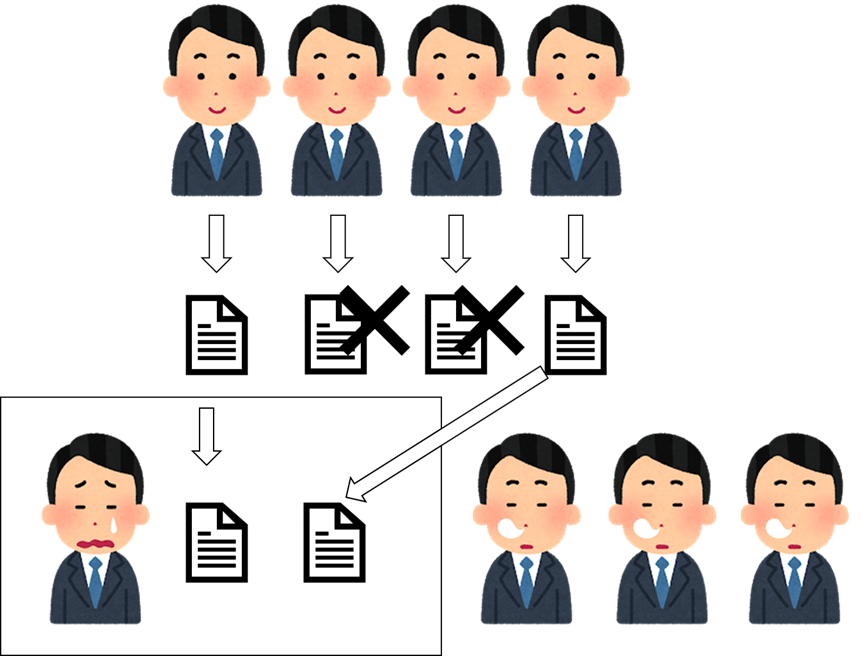
最近、先輩はボスになります。それから、働く方法も変えます。書類の番号を付けていれば、社員さんは自らによる書類を転送するもできます!
今回ボスの仕事は「計数」だけです。それは「ビッグボス」です。
平等主義
最近は「社内平等」と考える社員も多いです。GPUのスレッドも平等です。ボスような人物はない。それから、ボススレッドは計数の仕事をしているでも、普通な社員の仕事も担当します。
じゃ、少し整理しましょう!
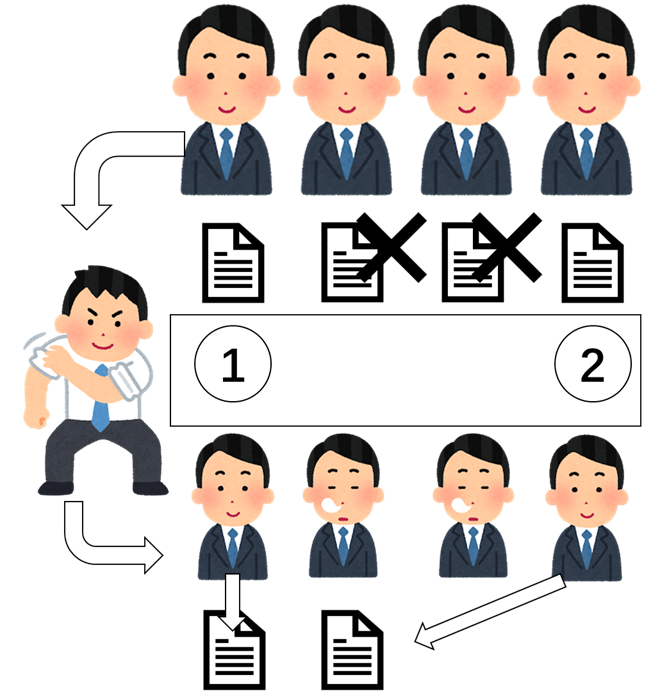
1. 皆さんは書類をチェックして、結果は自分に持っています。
2. スレッド0は、ボスになります。他のスレッドは待ちます。
3. ボスさんは、書類を統計して、番号を決まります。
4. 皆さんは、自分の番号をもらって、書類を転送します。
??主義
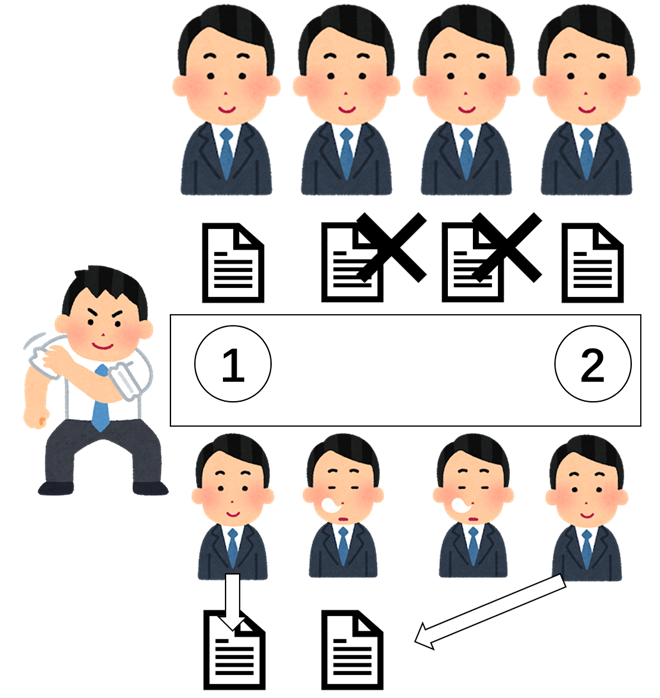
でも、今のGPUは、「Interlock」オペレーションをサポートしました。ボスじゃない場合も、役割はできます。
以前の場合は、たくさんスレッドは同じ場所のデータを変わりますと、間違ったデータを見ました。それはポピュリズムです。
でも「Interlock」では、実行のスレッドはいつだけです。データを変わって、そのデータの改変前の内容ももらいました。
それでは、皆さん同じ場所に「InterlockedAdd」して、番号も決まります。
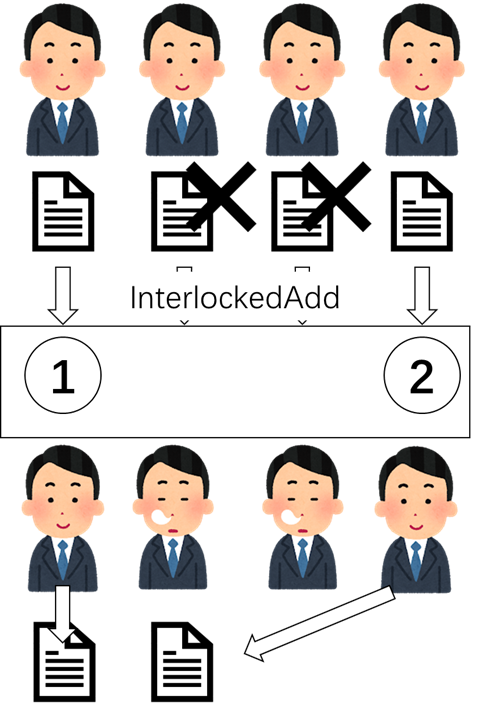
グループ
でも、実はGPUの全てスレッドは同じ場所のデータを改変することが少し無理です。
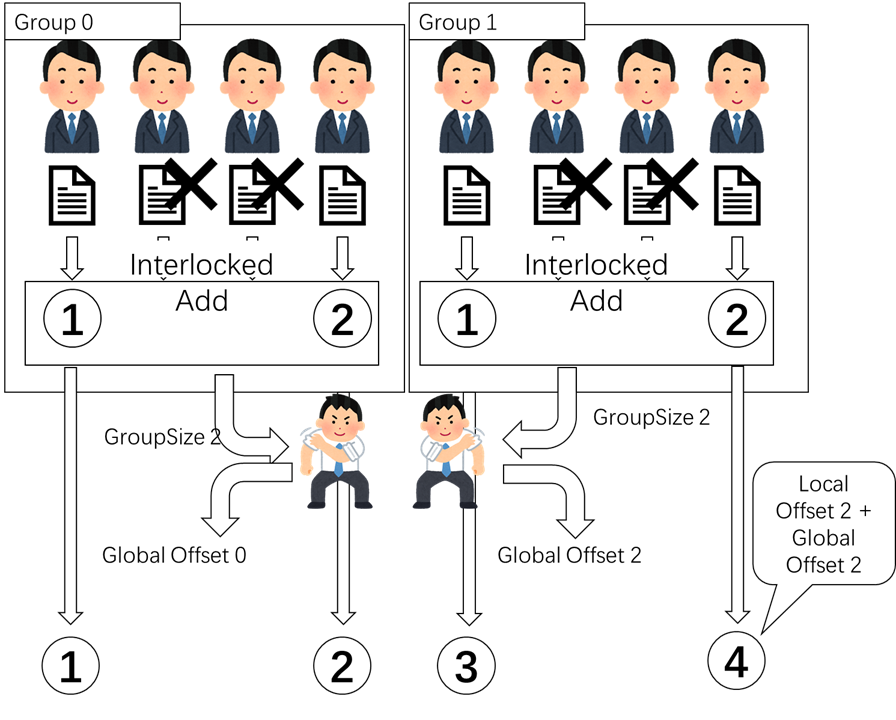
同じグループのスレッドはできます。少し残念ですね。この場合は、本社と分部の関係ようなものです。
それじゃ、グループのリーダーを選びます。リーダーさんは本社に会議を参加します。グループの中には、「Interlock」を使用して、自らによる番号を決めます。その後、リーダーさんは自分のグループの最大番号を持って本社の会議を参加します。本社は、Globalのオフセットを計算します。リーダーさんは本社の結果を持って、自分のグループを説明します。その後、スレッドはグローボとグループの番号に基づいて最後の番号を計算します。
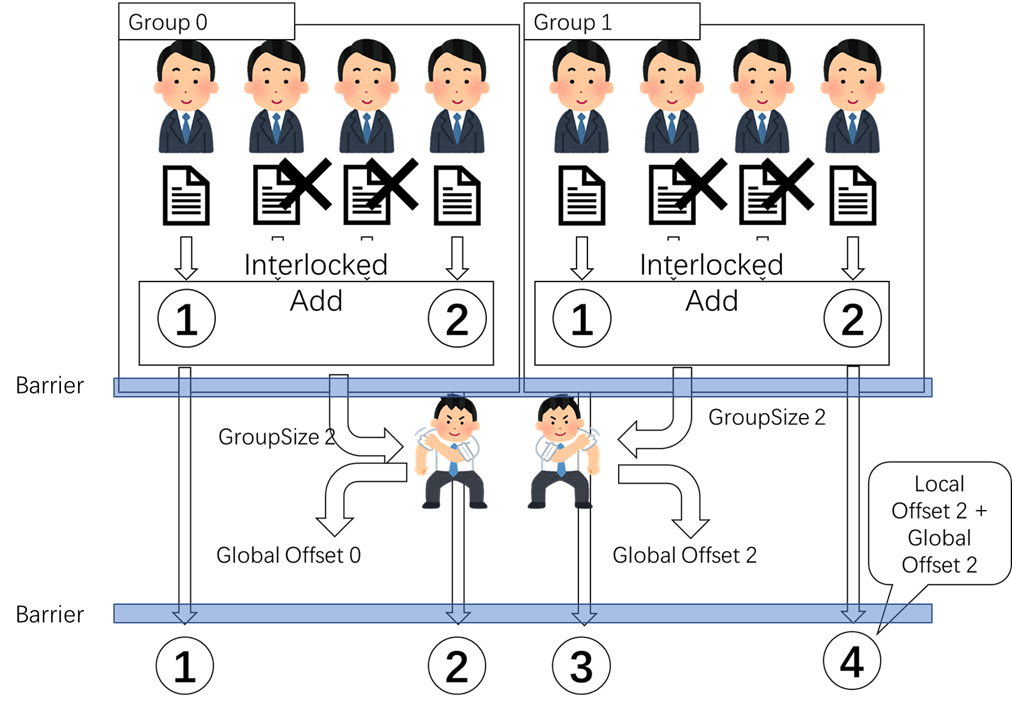
メモリバリア
でも、スレッドはリーダーを会社へ帰ることを待っていない、勝手に自分の番号を計算してデータを転送すれば、結果は間違いです。それからメモリバリアを使用します。
メモリバリアは、全てスレッドがここまで実行完成じゃないでは、この場所に待っています。メモリバリアを付けていれば、この感じです
それは最後のバージョンです。対応のコードはこれです
GroupMemoryBarrierWithGroupSync();
if (Invalid == false && NeedCulling)
{
if (cullingData.Radius < 0.0f)
{
Inside = true;
}
else
{
Inside = FrustumCullingSphere(InputInstance, cullingData.Radius);
}
}
if (Invalid == false)
{
if (Inside || NeedCulling == false)
{
InterlockedAdd(localValidInstances, 1, localSlot);
}
}
GroupMemoryBarrierWithGroupSync();
if (threadId == 0 && Invalid == false)
{
InterlockedAdd(
outCommand[DrawArgsCount * 5 + 1],
localValidInstances,
globalSlot
);
}
GroupMemoryBarrierWithGroupSync();
//if (index == 0)
//{
// outCommand[DrawArgsCount * 5 + 1] = g_CommandCount;
//}
if (Invalid)
{
return;
}
if (NeedCulling == false || Inside)
{
uint target_pos = args.StartInstanceLocation + globalSlot + localSlot;
outInstances[target_pos * 4] = srcInstances[RealInstanceIndex * 4];
outInstances[target_pos * 4 + 1] = srcInstances[RealInstanceIndex * 4 + 1];
outInstances[target_pos * 4 + 2] = srcInstances[RealInstanceIndex * 4 + 2];
outInstances[target_pos * 4 + 3] = srcInstances[RealInstanceIndex * 4 + 3];
}
コードは少ないでも、原理は難しいそうです。じゃ、今回はそれそれです。
みんなさん、本当にありがとうございます!!!
参考資料
Life of a triangle - NVIDIA's logical pipeline
https://www.irasutoya.com/