はじめに
前回 は、HeartCore RoboにおけるOCRの基本動作と、画面上のOCR対象領域を絶対値で指定するOCRの方法について記載しました。今回は画像認識(イメージ検索)を組み合わせて、OCR対象領域を相対的に指定してOCRを実行する記載します。
画像認識を用いる事で、「OCR対象範囲の座標決め打ち指定」を避ける事が出来ます。また取引先毎に異なるフォーマットの請求書・見積書なども対応が可能になります。例えば、取引先の書類レイアウトから会社A、会社Bと判別してから、それぞれ会社A、B用のOCR読み込みロボットの実行が可能になります。
(留意点)
今回は変数操作を多用するため、ある程度のプログラム知識がある方を対象としております。
画像認識を用いたOCRとは
OCR対象となる紙・イメージに必ず表示される箇所(例:納品書における「御中」や相手先企業のロゴ等のいわゆるテンプレート箇所)をOCR対象領域の「アンカー」としてHeartCore Roboのイメージテンプレートに登録しておきます。
OCR実行にあたり、イメージが表示されている箇所のアンカー座標(XY値)を取得、アンカー座標を元にOCR起点座標(OCR対象領域の左上)を決定させます。幅と高さは固定値を指定してOCR対象範囲の絞り込みを行います。
例1:アンカーとOCR対象起点が別の場合
「御中」を宛先取得用のアンカーイメージとして使用する。OCR対象の宛先は「御中」より左にあるので別途OCR起点座標を取得する必要がある。

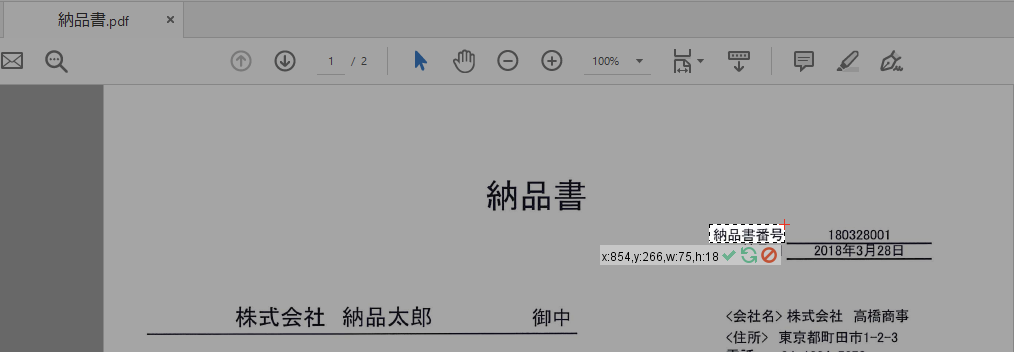
例2:アンカーとOCR対象起点が同じ場合
「納品書番号」を番号取得用のアンカーイメージとして使用する。OCR対象は右にあるのでアンカー座標とOCR起点座標は同じに出来る。

画像認識を用いたOCRを実行してみよう
事前準備
OCR対象のファイル(PDF)を用意の上画面に開く(倍率は100%)。前回使用したサンプルを今回も使用します。
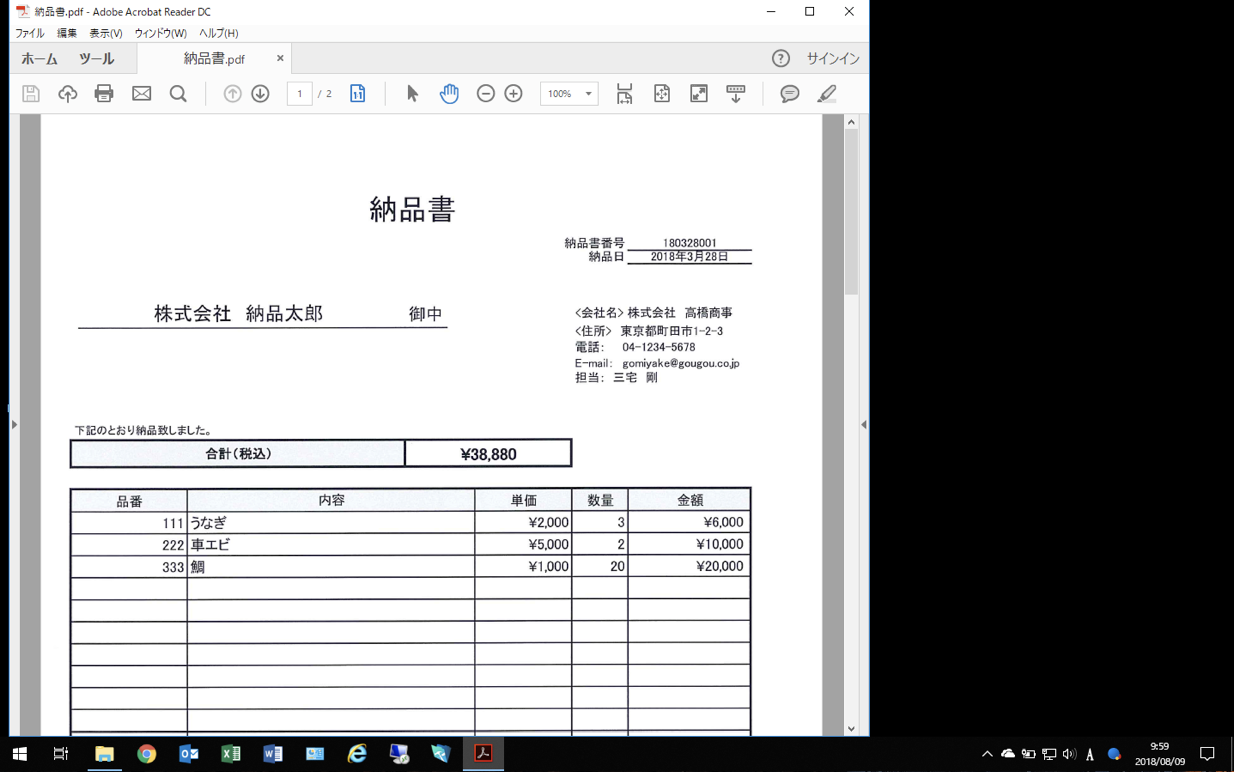
今回OCR対象は以下の赤枠で囲ったエリアです。
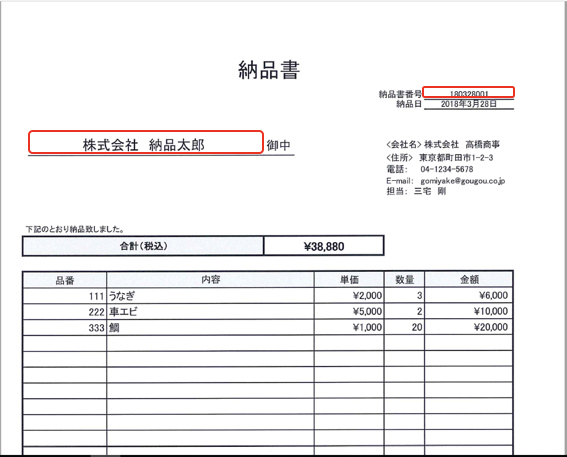
前回を参考にして上記赤枠をエリア指定してOCR実行、所定の結果が出ることを確認します。留意点は下部線に引っかからない・他のエリアに被らないように範囲指定を行います。
サンプルコード:
//宛名をOCR
Compareto method="tocr" cmparea="x:84,y:356,w:384,h:29" language="jpn"
Log {_TOCR_TEXT}
//納品書番号をOCR
Compareto method="tocr" cmparea="x:727,y:280,w:142,h:18"
Log {_TOCR_TEXT}
Report "results.xml"
画像認識を利用してアンカー座標を取得する - 上記例1のパターン
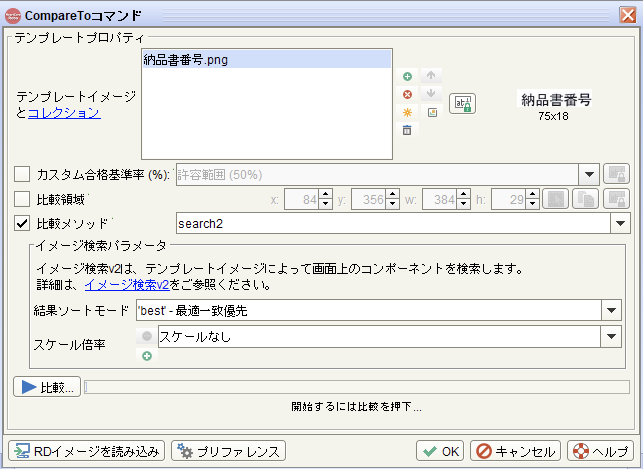
アンカー座標を取得するにもまずはCompartoコマンドでイメージ指定を行います。
イメージ指定する際のComparetoコマンドの基本的な動作
-
OCR実行行の直前に空白行を追加
-
右クリック > コマンドを作成 > Broswer -File > Comparetoを選択

-
緑十字ボタン(新規テンプレートイメージを作成または・・)をクリック
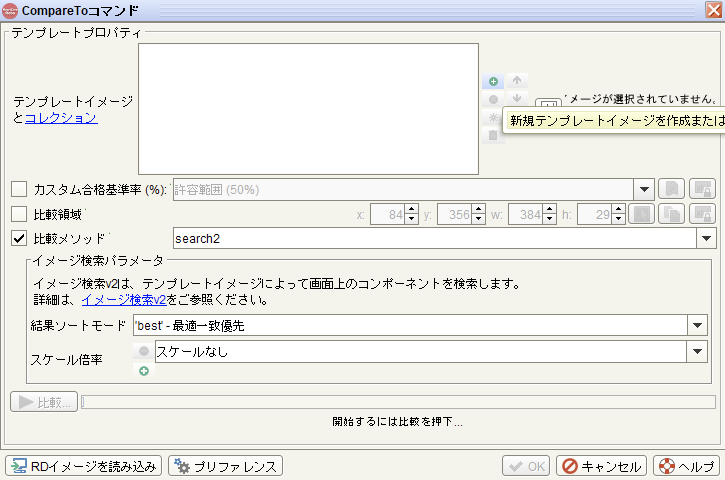
-
ファイル名にアンカーイメージ名を指定(例:御中.png) > 開く
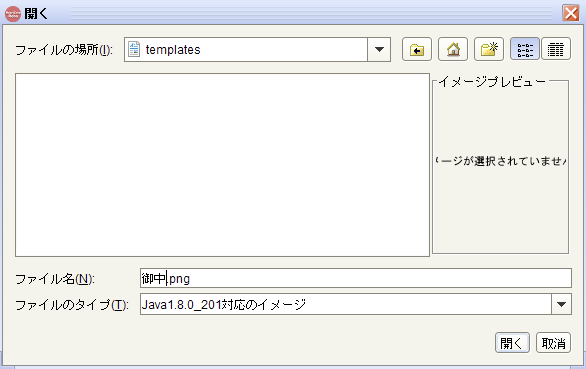
-
「御中」イメージを範囲指定 > クリックポイント(赤十字)を指定範囲左上に指定 > 決定

ポイント1:イメージ左上に指定したクリックポイントをアンカー座標として使用します -
イメージを取得 > 比較をクリック > 「検索一致あり」と表示される事を確認 > 一致を表示をクリック
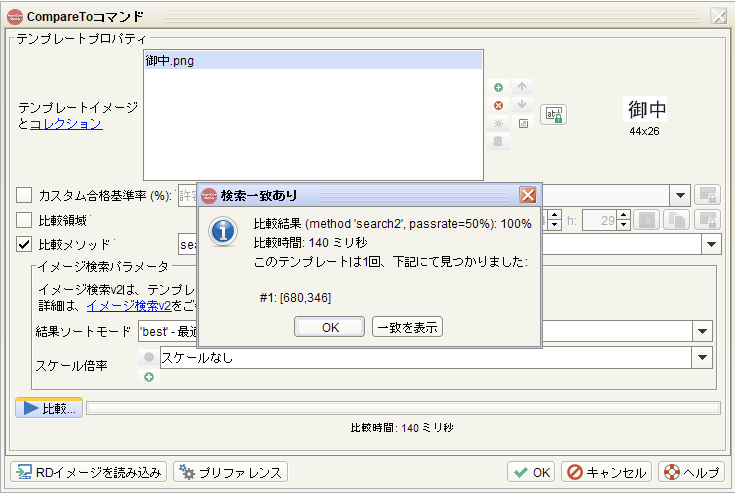
-
HeartCore Roboが「御中」の箇所を認識(赤線で表示)している事を確認 > 右上のxボタンで確認画面をクローズ
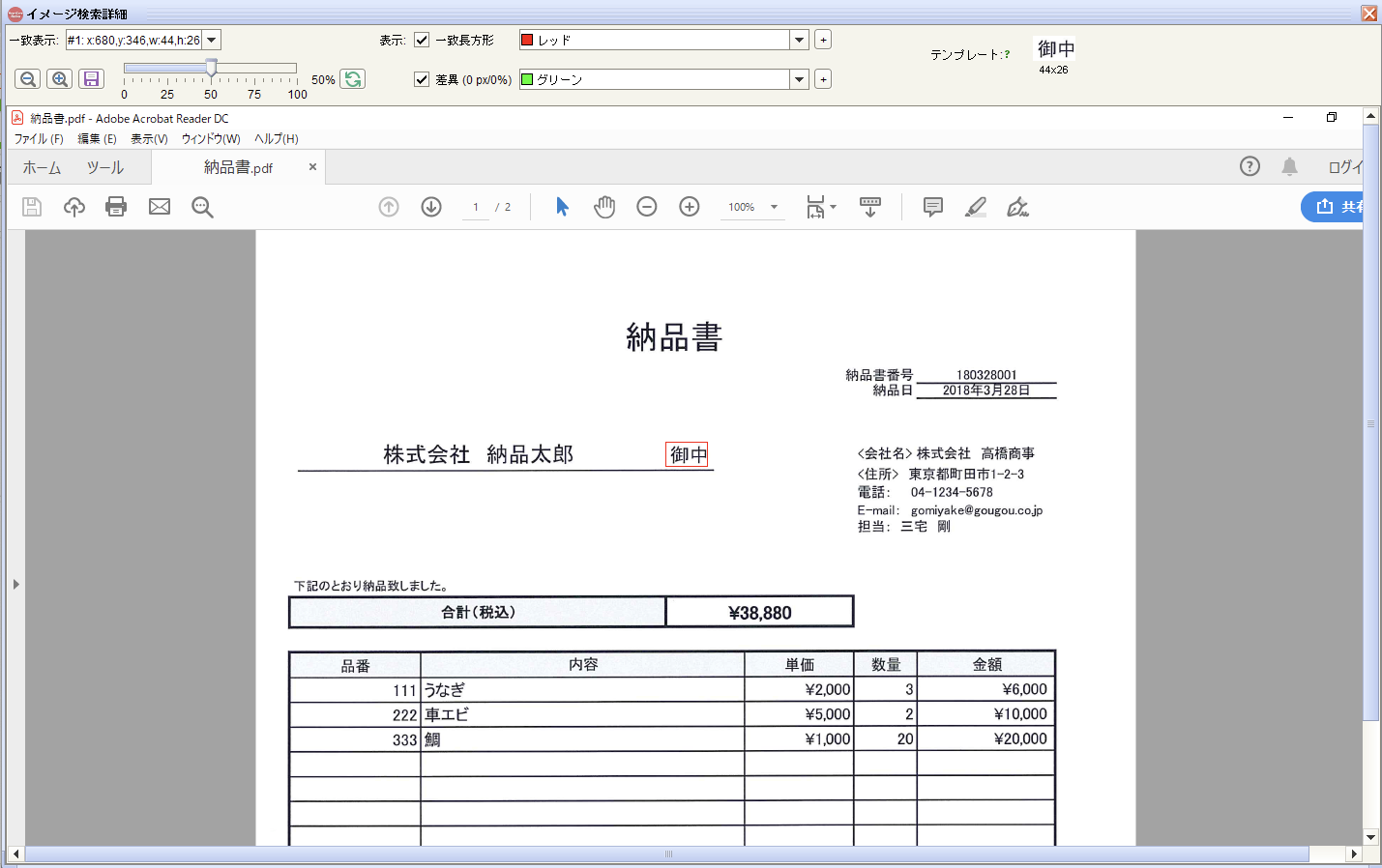
-
プロパティ画面のOKをクリック
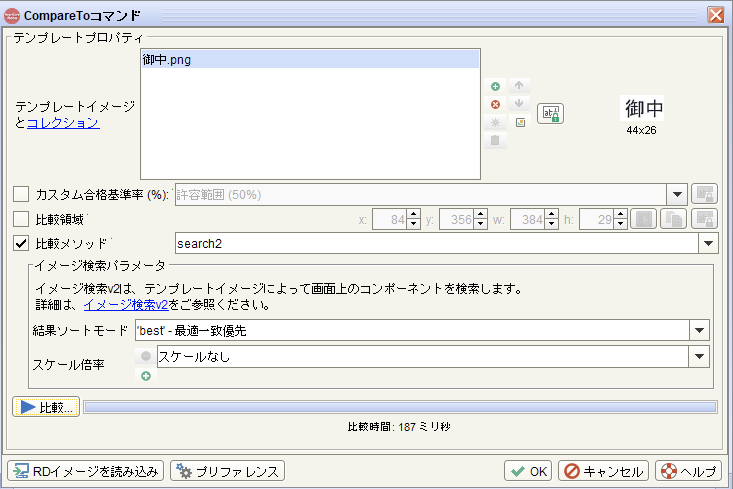
-
Compareto... method="search2"コマンドが追加されたのを確認
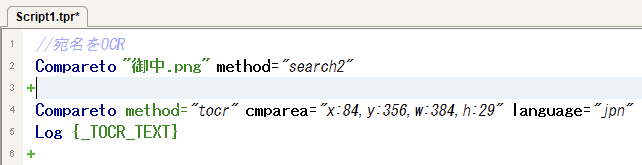
Compareto method="search2"と指定された場合はイメージ検索になります
Compareto method="tocr"と指定された場合はOCRが実行されます -
追加されたCompareto ..method="search2"コマンド1行のみをドラッグしてハイライト > メニュー部分の「選択」から選択したコードを実行
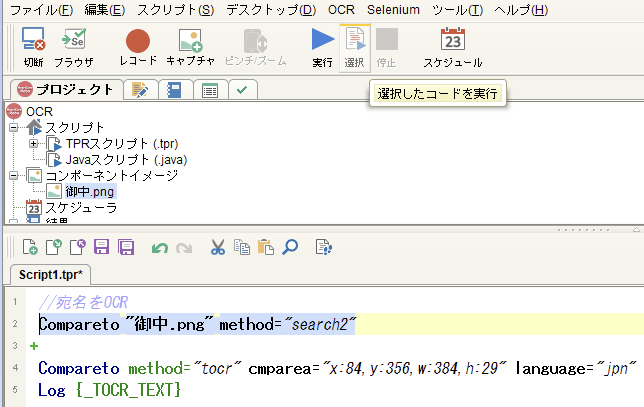
イメージ検索とアンカー座標取得のみ行われてOCRは実行されません -
「実行ログ」とあるタブの2つ右横の変数タブ(カーソルを合わせると「現在のスクリプトのコンパイルまたは実行によって作成された変数を表示」と表示されるタブ)をクリック
-
実行変数タブをクリック > 現在表示されている画面内のアンカーイメージと座標(クリックポイント)が変数("_COMPARETO_CLICK_X"と"_COMPARETO_CLICK_Y")に取得されているのを確認
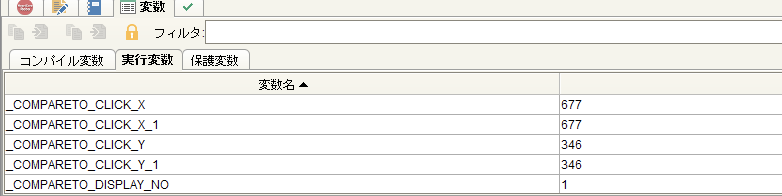
-
直下のCompareto method="tocr"のOCR行 > OCR範囲を絞り込むcmparea=引数内のx:で指定されている座標値を選択

-
選択したx:座標値を削除 > 変数名*"_COMPARETO_CLICK_X"*を選択 > 右クリック > 変数名をアクティブエディタへコピーを選択
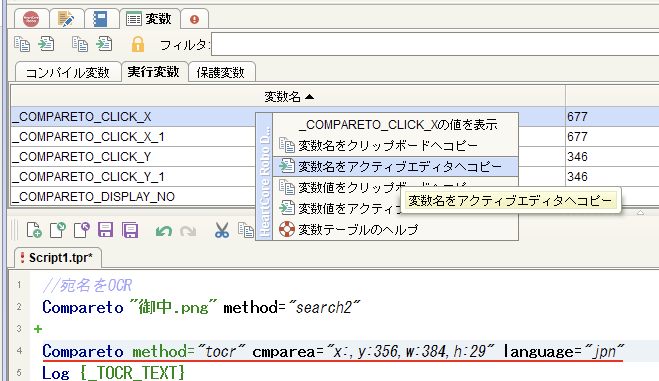
選択したx:座標値を削除して暫くするとCompareto method="tocr"行に赤線が表示されますが、これは本来あるべきx座標が指定されていないシンタックスエラーを動的に検知してアラート表示される機能です -
変数名がエディタ(スクリプト部分)のx:座標値部分へコピーされたのを確認
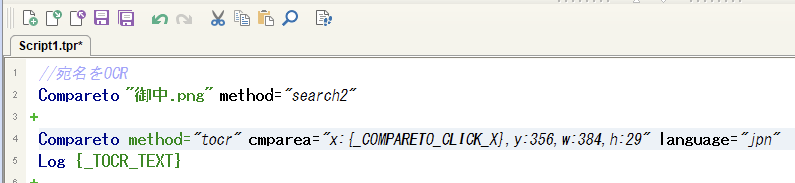
-
同様にcmparea=引数内のy:へ変数名*"_COMPARETO_CLICK_Y"*をコピー
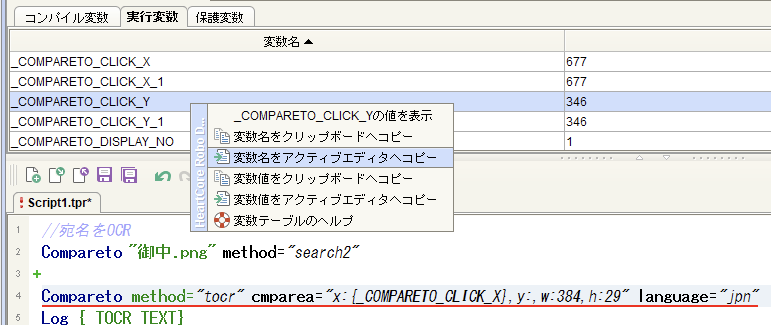
↓
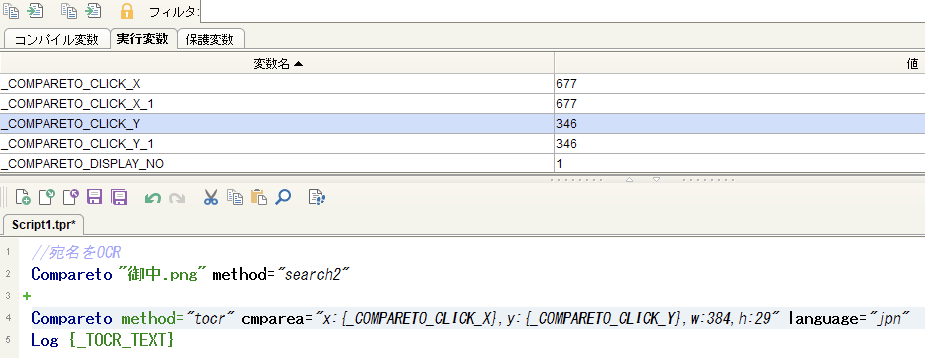
-
OCR起点座標調整のために*"_COMPARETO_CLICK_X"*で格納されているx座標値から対象の幅(w:で指定されている値)を引く

-
宛名部分OCRの3行をハイライト > 選択実行
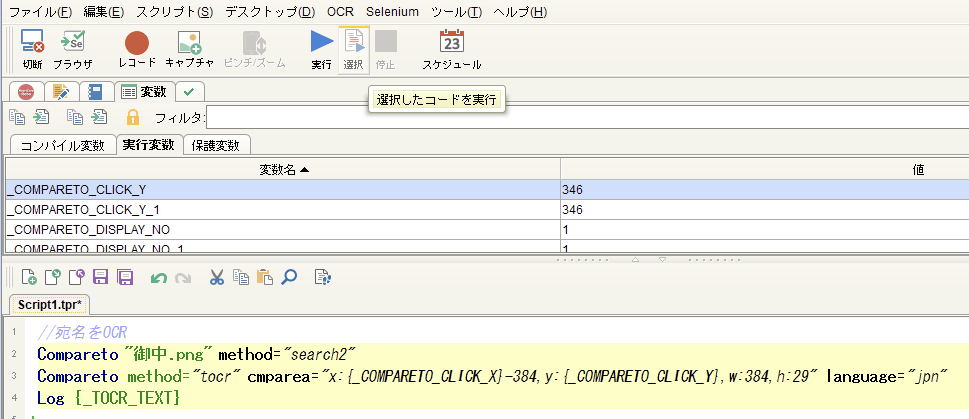
-
実行したOCR結果(読み取り結果)が文字列として格納されるシステム変数*"_TOCR_TEXT"*に結果が格納されているのを確認

注: 2019年8月時点での最新Tesseractは4.xであり、結果の末尾には"↑"が出力されるようになっています。切り取るにはString trimを使用します
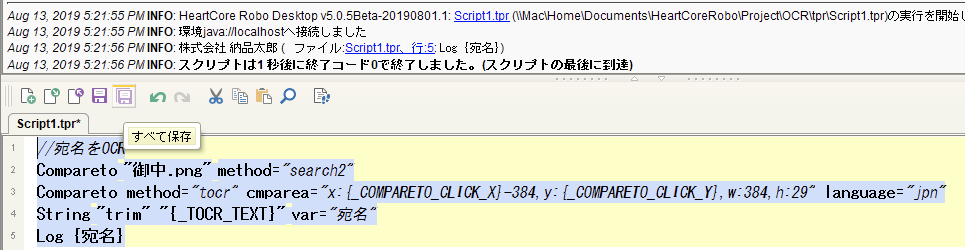
以下結果を"宛名"変数に格納するサンプルスクリプト
//宛名をOCR
Compareto "御中.png" method="search2"
Compareto method="tocr" cmparea="x:{_COMPARETO_CLICK_X}-384,y:{_COMPARETO_CLICK_Y},w:384,h:29" language="jpn"
String "trim" "{_TOCR_TEXT}" var="宛名"
Log {宛名}
画像認識を利用してアンカー座標を取得する - 上記例2のパターン
-
Compareto method="search2"を追加 > 「納品書番号」の右上をアンカー座標として指定
↓
-
直下のCompareto method="tocr"のOCR行 > x:とy:座標値を上記例1と同様に"*_COMPARETO_CLICK_X"と"_COMPARETO_CLICK_Y"*に置き換え
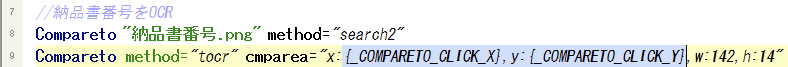
今回のアンカー座標はOCR範囲の左側なのでX:座標の調整は必要ありません -
納品書番号部分OCRの3行をハイライト > 選択実行 > 結果確認
//納品書番号をOCR
Compareto "納品書番号.png" method="search2"
Compareto method="tocr" cmparea="x:{_COMPARETO_CLICK_X},y:{_COMPARETO_CLICK_Y},w:142,h:18"
String "trim" "{_TOCR_TEXT}" var="納品書番号"
Log {納品書番号}
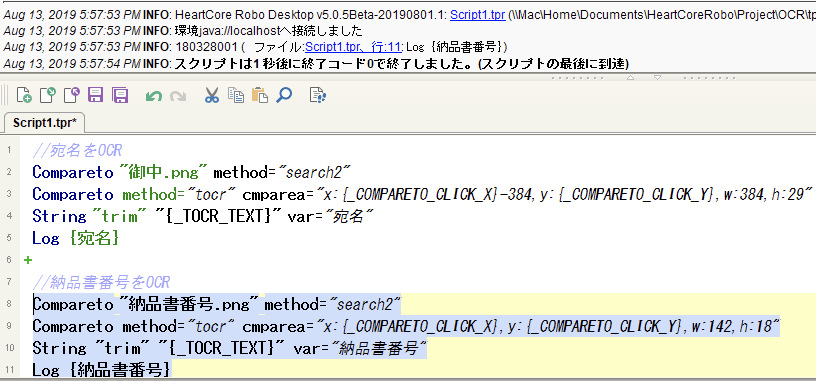
アンカーイメージ使用した場合のOCR結果が思わしくない場合
アンカーイメージを起点としたOCR範囲指定を調整する必要があります。例えば対象範囲の文字が見切れる状態でOCRを掛けた場合には結果が大きく異なります。
例:
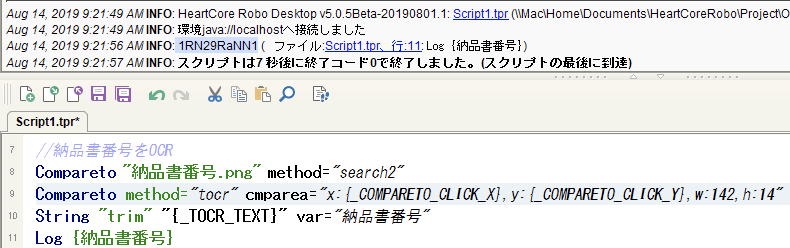
「見積書番号」に対してOCR実行したが、"180328001"ではなく"1RN29RaNN1"と結果が帰ってきた。
原因:
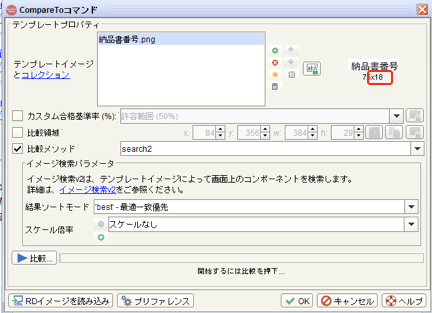
Compareto method="tocr"で指定しているOCR範囲の高さ(h:の値)が小さいため。
アンカーイメージ(納品書.png)の高さが18にも関わらず、OCR範囲の高さが14であるのが原因です。

対応:
Compareto method="tocr"で指定しているOCR範囲の高さ(h:の値)をアンカーイメージと同じ程度の値に調整します。
h:14→h:18へ変更

↓
想定通りの結果になります
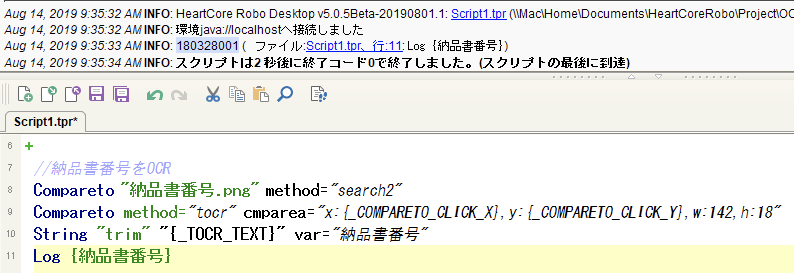
また、HeartCore RoboにあるScreenshotコマンドを使用してデバッグ的にOCRの範囲を確認する事が可能です。Screenshotコマンドは範囲指定によるピンポイントなスクリーンショット取得が可能なので、OCR範囲指定と同じ方法で範囲指定します。

//納品書番号をOCR
Compareto "納品書番号.png" method="search2"
//OCR範囲のスクリーンショット取得
Screenshot "納品書番号OCR範囲.jpeg" area="x:{_COMPARETO_CLICK_X},y:{_COMPARETO_CLICK_Y},w:145,h:18"
Compareto method="tocr" cmparea="x:{_COMPARETO_CLICK_X},y:{_COMPARETO_CLICK_Y},w:142,h:18"
String "trim" "{_TOCR_TEXT}" var="納品書番号"
Log {納品書番号}
Screenshotコマンドで取得したスクリーンショット画像は、Projectフォルダ直下のReportsフォルダ内、実行時毎に自動で作成されるフォルダから確認出来ます。

↓
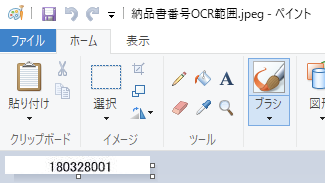
上記のOCR結果が思わしくない場合(h:14と指定した場合)にはOCRの対象が見切れているのが判明します。
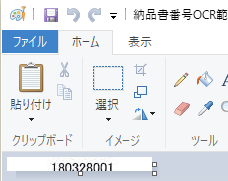
Reportsフォルダの場所は、変数タブ > コンパイル変数から”_PROJECT_REPORT_DIR”変数の値を確認します。
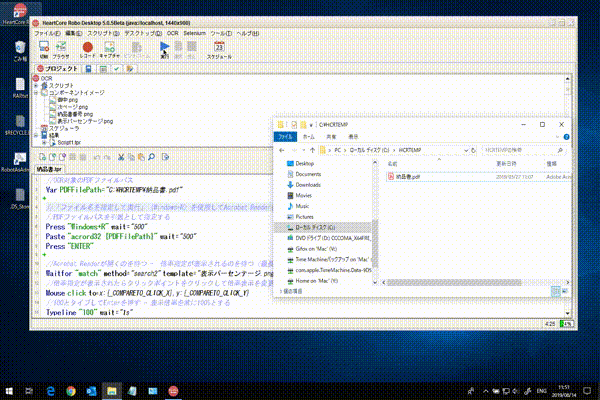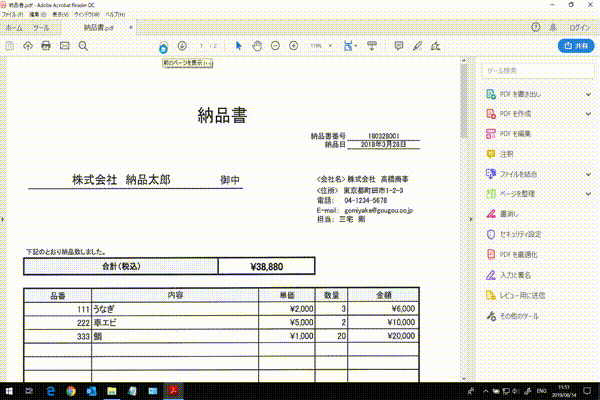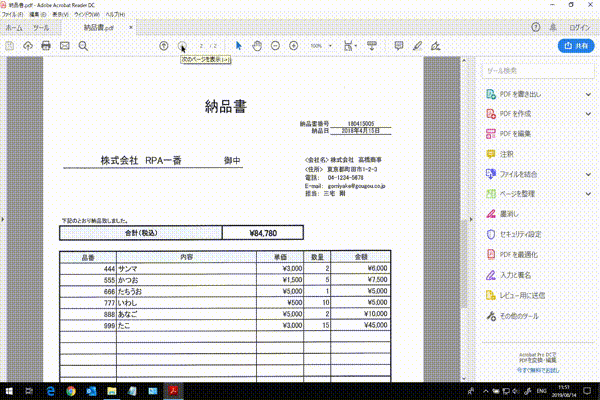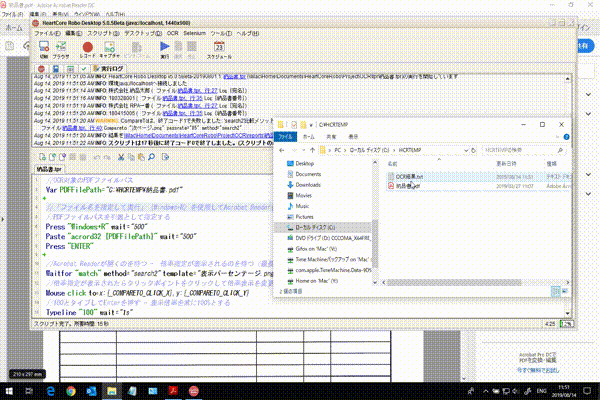
実践版OCRロボットスクリプト
PDFを開いて書類の表示倍率を100%に調整、PDF内にあるページ分OCR処理を行うサンプルスクリプトです。
結果:
2ページ分の「宛先」「納品書番号」OCR結果がテキストファイルに出力されます
事前準備として、Acrobat Readerの倍率指定の箇所のイメージ(表示パーセンテージ.png)と次ページへ遷移させるアイコンイメージ(次ページ.png)を取得します。
以下スクリプト
各コマンドの詳細についてはHeartCore Roboオンラインマニュアルを参照ください。
//OCR対象のPDFファイルパス
Var PDFFilePath="C:\HCRTEMP\納品書.pdf"
//「ファイル名を指定して実行」(Windows+R)を使用してAcrobat Readerを起動
//PDFファイルパスを引数として指定する
Press "Windows+R" wait="500"
Paste "acrord32 {PDFFilePath}" wait="500"
Press "ENTER"
//Acrobat Readerが開くのを待つ ー 倍率指定が表示されるのを待つ(最長30秒)
Waitfor "match" method="search2" template="表示パーセンテージ.png" timeout="30s" ontimeout="Exit 1"
//倍率指定が表示されたらクリックポイントをクリックして倍率表示を変更させる
Mouse click to=x:{_COMPARETO_CLICK_X},y:{_COMPARETO_CLICK_Y}
//100とタイプしてEnterを押す - 表示倍率を常に100%とする
Typeline "100" wait="1s"
//OCR出力結果用テキストファイル作成
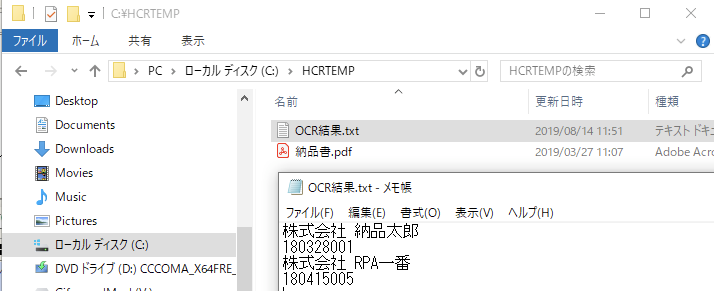
File "create" file="C:\HCRTEMP\OCR結果.txt"
//PDFファイル内のページ分ループ
for (;0==0;) {
//宛名をOCR
Compareto "御中.png" method="search2"
Compareto method="tocr" cmparea="x:{_COMPARETO_CLICK_X}-384,y:{_COMPARETO_CLICK_Y},w:384,h:29" language="jpn"
String "trim" "{_TOCR_TEXT}" var="宛名"
Log {宛名}
//OCR出力結果用テキストファイルへ結果書込
File "append" text="{宛名}\n"
//納品書番号をOCR
Compareto "納品書番号.png" method="search2"
Compareto method="tocr" cmparea="x:{_COMPARETO_CLICK_X},y:{_COMPARETO_CLICK_Y},w:142,h:18"
String "trim" "{_TOCR_TEXT}" var="納品書番号"
Log {納品書番号}
//OCR出力結果用テキストファイルへ結果書込
File "append" text="{納品書番号}\n"
//次ページがあるかのチェック
Compareto "次ページ.png" passrate="85" method="search2"
if ({_EXIT_CODE} == 0) {
//次ページがある場合にはアイコンをクリックして次ページ表示
Mouse "click" wait="1s" to="x:{_COMPARETO_CLICK_X},y:{_COMPARETO_CLICK_Y}"
} else {
//次ページがない場合(アイコンがグレーアウト)にはループを抜ける
Break
}
}
//OCR出力結果用テキストファイル保存
File "close" save="true"
Report "results.xml"
OCR活用のベストプラクティス
OCRの結果はOCRエンジン(例:Tesseract, ABBYY, Google Vision等)に大きく依存します。インストール型OCRの場合、辞書ファイルをチューニングすることで精度の向上は出来ますが、100%の精度を求めるのは難しいのが現実です。ただある程度のOCRの「クセ」を把握出来れば後続のString replaceでOCR結果を調整することが可能になります。
例1:
数字のみの文字列(商品コード等)対象のOCR結果で"1"がアルファベットLの小文字"l"と認識される場合や、”0"がアルファベットの"O"と認識される場合
String "replace" "{_TOCR_TEXT}" string="l" var="var" replacement="1"
String "replace" "{_TOCR_TEXT}" string="o" var="var" replacement="0"
例2:
平仮名”の"が"@"と認識される場合
String "replace" "{_TOCR_TEXT}" string="@" var="var" replacement="の"
HeartCore Roboの強みである、画像認識を活用しながらノイズ(余計な箇所)が入らないようOCRの範囲をピンポイント指定した上で、その箇所毎に一番精度が出るようOCRオプションを変えてみるのも一つの方法です。
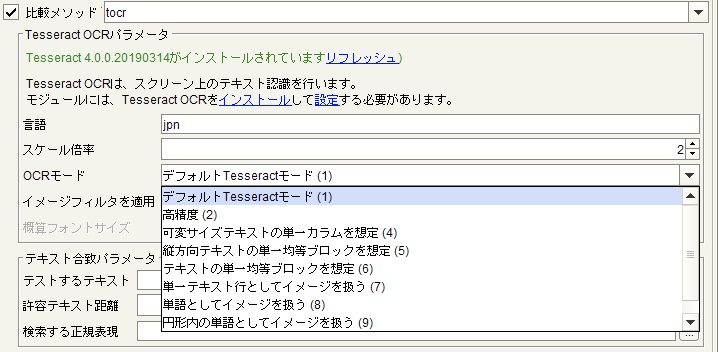
また、表示倍率を上げると潰れたような字や画数が多い文字の認識精度が若干上がる傾向にあります。
OCRについての個人的な考察
OCRの精度を追求すると「ハマる」事が多々あります。ある程度の精度が出た時点で割り切って使用、日々の使用時における誤認識パターンを把握しながら、スクリプトでの修正を追加する継続的なチューニング運用が望ましいと考えています。