はじめに
HeartCore RoboにはOCR機能が搭載されております。OCRツールはTesseractで、別途インストールが必要になります。ダウンロード方法及びインストール方法については製品ダウンロード時に梱包されているセットアップガイドを参照下さい。
留意点:
Windows版Tesseractは不定期にバージョンアップされるので都度下記サイトで最新バージョンのチェックが必要になります。
https://digi.bib.uni-mannheim.de/tesseract/
HeartCore RoboにおけるOCRについて
HeartCore RoboからTesseractのコントロール(起動・パラメータ指定)を行いOCRを実行します。OCR結果はHeartCore Roboのシステム変数に文字列として格納されるので、スクリプトによる修正・置換が可能です(例:値段についている¥マークを除く)。
OCR読取→データ修正→別システムへのデータエントリーの一連の流れをHeartCore Roboでコントロール出来るのが最大のメリットです。
HeartCore RoboにおけるOCRの基本動作について
読み取り対象ファイル(PDF・TIFF等)を開いてデスクトップ画面に表示する必要があります。ファイル全体を一気にOCR実行するのではなく、四角形の範囲を指定したピンポイントOCR実行を行います。
ピンポイントOCRのメリットは、OCR不要な箇所を排除することでノイズを削減する事と、OCR対象に応じたパラメータ設定(例:日本語の箇所・金額の箇所によってOCRパラメータを変更)を行う事により、より高いOCR精度が期待出来ます。
ピンポイントOCR実行対象例:
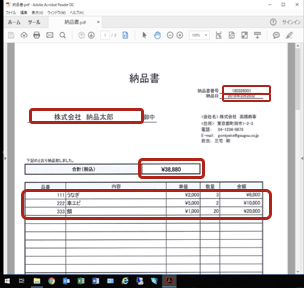
宛名、納品書番号、納品日、合計金額、明細行だけをOCR実行します。OCRが必要無い書類のテンプレート部分(納品書や「下記の通り納品いたしました」の文言)を外す事でOCRの読取り時間も短縮出来ます。
HeartCore RoboからOCRを実行してみよう
以下にHeartCore RoboからOCRを実行する方法を記載します。本記事のサンプルは、実際に紙でプリントアウトしたものをスキャンして取込み、PDF形式で保存したファイルを使用しています。
事前準備:
OCR対象のファイル(PDF)を用意の上画面に開く(倍率は100%)
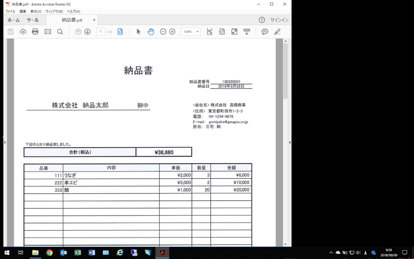
*上記のサンプルはAcrobat ReaderでPDFファイルを開いています*
-
スクリプト画面で Report “results.xml” とある行の冒頭でEnterを押して空白行を追加
-
空白部分を右クリック > コマンドを作成 > Click -File > Comparetoを選択

-
プロパティ画面が開くので比較メソッド > tocrを選択
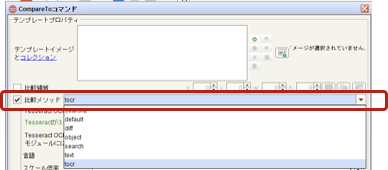
-
比較領域にチェック
-
紫色のアイコンをクリック

-
領域指定画面が開くのでOCR対象範囲指定(下記の例では「御中」の左横部分) > 決定をクリック
決定アイコン:
留意点:領域指定の際には下線や罫線を入れないようにします。下線や罫線がOCR対象に入ると、文字として認識される場合があります。
-
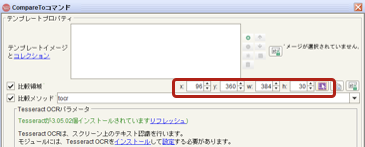
比較領域の左上のXY座標(x:/y:)と幅高さ(w:/ h:)の値が取得されたのを確認
-
比較(シミュレーション)を実行

-
「以下のテキストが認識されました・・」の箇所でOCR結果を確認
-
OKをクリック
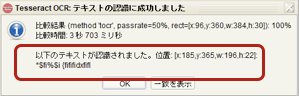
この時点で期待するOCR結果は出ていません
OCRの結果が思わしくない場合の原因
- OCR対象言語が指定されていない(デフォルトは英語)→今回の原因
- 最適なOCRパラメータが設定されていない
- 範囲指定が正しくない
- 対象フォントが小さい・クリアで無い・歪んでいる
- OCRフォントライブラリに無いフォントを対象としている
- OCR対象文字数が少ない(3文字以上が望ましい)
OCRのパラメータ調整を行ってみる
OCRには様々なパラメータが用意されています。HeartCore Roboのシュミレーター機能を使用しながら最適な結果が得られる設定を調整します。
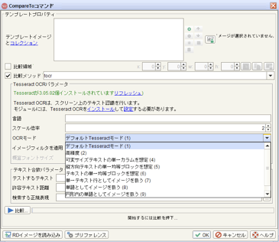
上記の宛名を読み込む例では、日本語用OCR設定を行っていないため、日本語部分の結果が思わしくありませんでした。下記が日本語をOCR実行する際の手順です。
-
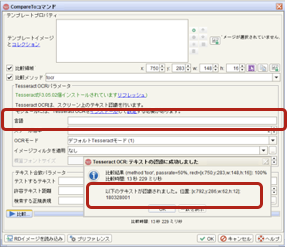
プロパティ画面上の言語に”jpn”と入力(=日本語フォント指定)
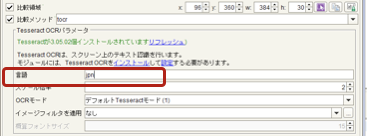
-
比較()を実行
-
「以下のテキストが認識されました・・」の箇所でOCR結果を確認
-
今回は画面に表示されている日本語表記と同様の結果が取得されたのを確認
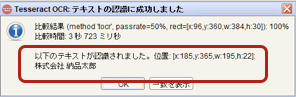
-
シミュレーション結果画面のOKをクリック
-
プロパティ画面のOKをクリック
-
OCR実行スクリプトが追加された事を確認
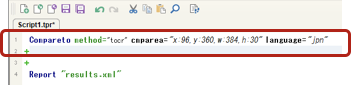
OCRコマンドの例:
Compareto method="tocr" cmparea="x:77,y:360,w:402,h:33" language="jpn"
説明:
Compareto method="tocr" cmparea="x:{OCR対象領域左上X座標},y:{OCR対象領域左上Y座標},w:{OCR対象領域幅},h:{OCR対象領域高さ}" language="{言語}"
{言語}:Tesseractをインストールする際に追加指定した言語を3文字で指定します。日本語の場合は”jpn”を指定します。指定しない場合は英語の"eng"となります。
OCRの実行結果を取得してみる
OCRの実行結果はHeartCore Roboシステム変数に文字列として格納されます。シミュレーションだけではOCR結果が格納されないので、実際にロボットを実行する必要があります。
-
追加されたスクリプトを実行

-
実行が完了するとHeartCore Robo画面に戻るので、変数タブを選択
-
実行変数タブ > _TOCR_TEXT > OCR結果が格納されているのを確認
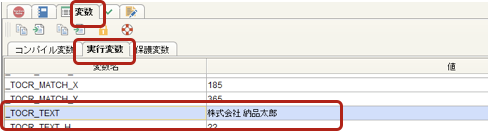
変数の説明:
{_TOCR_TEXT}
実行したOCR結果(読み取り結果)が文字列として格納されるシステム変数
-
_TOCR_TEXT変数上で右クリック > 変数名をクリップボードへコピーを選択
-
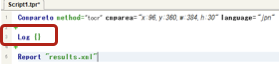
スクリプト画面空白行にログ出力コマンドLog {}と入力
-
中括弧内{}にて右クリック > CTRL+Vを押して変数名( _TOCR_TEXT)をコピー

-
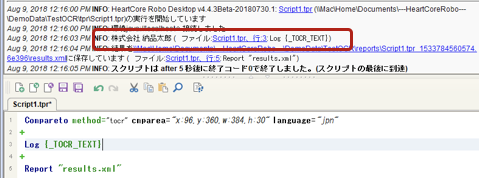
スクリプト実行
-
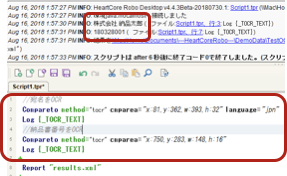
OCR実行結果がログに出力されているのを確認
他の箇所もOCR実行してみて下さい。
下記の例では、納品書番号の記載箇所を対象としています。
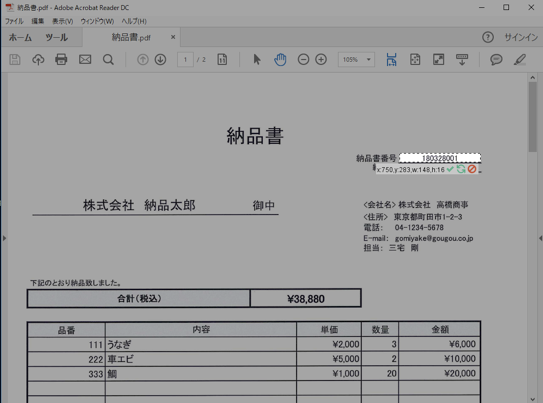
↓
今回のOCR対象は数字のみのため、言語を日本語指定しなくとも期待したOCRの結果が得られていますが、数字をOCRした場合、数字の1をアルファベットの"I"かLの小文字”l”として認識される場合があります。もし想定した結果が得られない場合は、OCRモードを「高精度」に変更したり、

スケール倍率(フォントの拡大率:デフォルトは2)を高めた設定でシミュレーションを繰り返してみます。

実行の結果例:
次回について
今回はOCR対象領域(デスクトップ上の座標と高さと幅)を絶対値で指定した上での実行でしたが、次回はHeartCore Roboの特徴である画像認識(イメージ検索)を応用して、「OCRの対象が画面上の何処にあっても実行できる」ように対象領域を相対的に指定して処理を行う方法をカバーします。