その界隈の方にぶっ叩かれそうなタイトルですね。「意識」について色々と妄想し、手を動かした記録をここに残しておこうと思います。(アイアンマンに出てくるJ.A.R.V.I.S.というAIを作るために考えました。)
成果物
「意識」がどうとか言う前にできたものを見せましょう。実装は本当に大変でした。
- ソースコード(かなり雑ですがお許しください。)
https://github.com/Geson-anko/JARVIS3
理論
ここから先は私の研究室のボスに提出したものをそのままコピペしているので口調が変わります。
「意識」とは何か、定義しながら行きましょう。(イキって論文チックにしようとしていますが生暖かい目で見てやってください)
1. 初めに
人間は意識を持っている。意識的に歩くことができるし、話すこともできる。それはとても当たり前であるが、現代の機械を使ってその意識そのものを実装したケースを私は知らない。
意識を形作るためのパーツとして記憶があると考えている。意識があるときに記憶は存在しており、意識がない時には記憶は存在しないからである。また記憶は計算機上で概念的にも物理的にも実装されて久しく、記憶をもとに意識を作ることができれば計算機上で意識を実装しやすくなるだろう。
ここでは意識をもつ機械(モデルマシン)についていくつかの具体的な例を用いて提案する。
2.定義から始まり意識を定義するために必要なことを定義したのち、3.アルゴリズム で2.定義によっておこる具体的な状態の変化を3つの例題を用いて説明する。
2. 定義
2. 1. 情報 i
画像や音声などの構造を持った物理データ。実装上はTensorである。しかしTensor自体は音や光の情報を同時に組み込むことができるため、情報 $i$ を特定の物理データに制限する必要はない。
2. 2. 事象 A
事象は様々な情報 i を要素とする集合である。
ある事象 $A$ から光に関する情報 $i_p$ のみを取り出した事象 $A_p$ と、同様にして音に関する $A_w$ を作ると以下の式が成り立つ。
$$ A⊃(A_p∪A_w) $$
つまり、事象 $A$ が無限集合だった場合に複数の有限集合に分けて近似することができる。
$$ A ≃A_1∪A_2∪… ∪A_n | n∈N,A_n⊂A \land A_n は有限集合 $$
2. 3. 記憶シンボル M
記憶シンボル $M$ (以下より単に記憶と呼ぶ)は、ある事象 $A$ の写像である。記憶 $M$は事象 $A$ に対しおおよそ一意に定まり全く違う事象に対しては違う記憶が与えられる。
2. 4. 事象→記憶 を行う E_θ と逆関数 D_θ
ある事象 $A$ を記憶 $M$ に変換する関数を$E_θ$ とする。逆関数は $D_θ$ とする。
$$ E_θ (A)=M,D_θ (M)=A $$
2. 5. 一時記憶集合 W
一時的に記憶を要素としてそれを保持しておく要素数 $α$ の有限集合。$W$の要素数が $α$ の時に要素を追加する場合、$W$ の中の要素のどれかがランダムに選ばれ上書きされる。要素数$k | k≤ α$の$W$と記憶を要素とする要素数 $l | l≤ α $個の集合と結合する場合、$W$ の中から $k+l- α$ 個の要素がランダムに選ばれ上書きされる。
以降では単に一時記憶と呼ばれる。
2. 6. 記憶辞書 Dict
記憶から別の記憶への写像を生成する関数である。記憶辞書はそのつながりを保存する。そのつながり方には4つの例が存在する。実装上の観点から基本的には例1を使用する。
-
例1 記憶 $M_1$ から記憶 $M_2$
$$ Dict(M_1) = M_2 $$ -
例2 記憶 $M_1$ から記憶の集合 ${M_2,M_3,M_4 }$
$$Dict(M_1 )={M_2,M_3,M_4 }$$ -
例3 記憶の集合 ${M_1,M_2,M_3 }$ から記憶 $M_4$
$$Dict(M_1,M_2,M_3 )=M_4$$ -
例4 記憶の集合${M_1,M_2 }$から記憶の集合${M_3,M_4}$
$$Dict(M_1,M_2 )={M_3,M_4}$$
例4の場合、例1~3も同時に定義することができる。
ある記憶 $M$ について記憶辞書のつながりが保存されていない場合、恒等写像とする。
$$Dict(M)= M$$
2. 7. 賞罰者(Rewarder)
事象や記憶に対し賞(0以上の実数)または罰(負の実数)を与える関数とする。ある事象 $A$ から与えるものを $V(A)$ (本能関数 ), 一時記憶 $W $と記憶 $M$ から与えるものを $Q(W,M)$(行動価値関数)と置く。
$Q(W,M)$は出力を完了した $M$ 対して完了した時刻の$V(A)$ を使って更新される。
$$Q(W,M)←V(A)$$
$Q $の初期値は0とする。
2. 8. 集めること
ある事象 $A$ を取得し、 $E_θ $ を使って記憶シンボル $M$ へ変換すること。非常に似た事象同士に対して同じ記憶シンボルを与えても良い。またある二つの事象同士の距離をそれぞれの記憶シンボルの間に反映させてもよい。
2. 9. 繋ぐこと
記憶同士を結び、記憶辞書に保持すること。ある1つのつながりにおいて、$M_1 →M_2$といった向きが存在する。
2. 10. 辿ること
記憶辞書を使ってある記憶 $M_1$ につながっている記憶 $M_2$ を取り出すこと。またそれを再帰的に繰り返すこと。
2. 11. 発すること
ある記憶 $M$から対応する事象 $A$ に $D_θ$ を使って変換し、その事象そのものか近い事象を発生させること。
行動価値関数$Q$ が負の値をとる場合、第2引数の記憶$M$ は発しない。また発生させる事象数に限りがある場合は、$Q$の値が最も大きい記憶が事象に変換される。
2. 12. 意識
記憶を集めること、繋ぐこと、辿ること、発することを行って情報を処理することを意識とする。
3. アルゴリズム
ここでは次のことを定義する。
時刻 $T$
事象 $A_1$ : リンゴの景色
事象 $A_2$ : 「リンゴ」という声
事象 $A_3$ : 「ぶどう」という声
$A_1,A_2,A_3$ それぞれに対応する記憶を $M_1,M_2,M_3$ とする。
入力事象集合 $I_A$
入力記憶集合 $I_M $または $I$
出力事象集合 $O_A$
出力記憶集合 $O_M$ または $O$
一時記憶 $W (α=3)$
記憶辞書 $D$ : 2. 6. の例1の場合を採用する。また表中では$Dict$ではなく$D$とする。
賞は$1$, 罰は$-1$とする。
本能関数$ V(A)$ : 今回は引数の事象については考えず、罰または賞を与える。
行動価値関数 $Q(W,M)$
次の3.1, 3.2, 3.3の中で登場する表の時刻の変化はすべて左から右へ進む。
「…」と書いた場合は前の時刻の状態と等しいことを示す。
ここでの$I_A,I_M,O_A,O_M$の最大要素数を$1$とする。
アルゴリズムの例を作るために、状態の遷移律を定義する。
$S_1$ : $I_A $に追加された事象$ A $は2.8.集めること により記憶 $M $に変換され、$I_M$に移される。
$S_2$ : $O_M$に追加された記憶$M$ は2.11.発することより事象$A $に変換され、$O_A$に移される。
$S_3$ : $I_M$に追加された記憶$M$は一時記憶$W$に移される。
$S_4$ : 一時記憶$W$が前時刻と異なる場合、$W$を使って2.9.繋ぐこと を行う。
$S_5$ : 2.10.辿ること の定義に従って一時記憶$W$からつながりを取り出し、$W$に追加する。
$S_6$ : $W$の中にある出力される記憶$M$は2.11.発すること の定義に従って$O_A$ へ複製される。
$S_7$ : 2.7.賞罰者 の定義従い、本能関数$Q$を更新する。
3. 1. 例題1 学習フェーズ
初めてリンゴを見て、「リンゴ」という声を聴き、それらを記憶に変換しつなぐ場合を考える。
わかりやすさのため、$O_A,O_M,V,Q$は省略する。
-
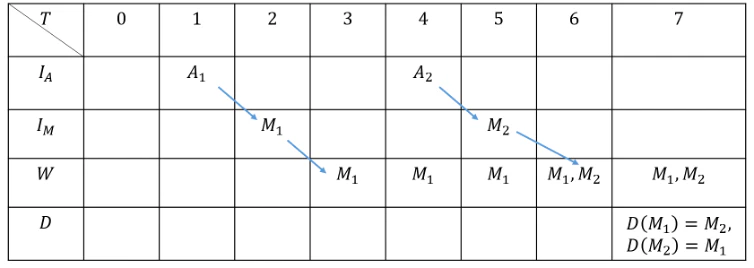
表1 例題1の状態変化
-
表1説明
$T=0$(以下$T=0$を初期状態と呼ぶ)では事象や記憶、記憶のつながりを保持していないとする。
$T=1$では「りんご」という事象が入力されている。
$T=2$で$S_1$より事象は記憶へ変換される。
$T=3$で$S_3$より入力記憶は一時記憶に格納される。辞書に登録されていないため、恒等写像となり変化しない。
$T=4-6$では$T=1-3$と同様の処理が行われている。
$T=7$ で$S_4$より一時記憶の中から記憶のペアが選ばれ、辞書に登録される。ここでアルゴリズムは終了する。
3. 3. 例題2 推論フェーズ
リンゴ見て、記憶を辿り、「リンゴ」という声を発する場合を考える。
わかりやすさのため、$V,Q$は省略する。
-
表2 例題2の状態変化

-
表2説明
初期状態では例題1の $T=7$の記憶辞書$D$を持ち、そのほかに事象や記憶は持たない。
$T=1-3$では$S_1,S_3$より事象を受け取り記憶に変換し一時記憶に格納している。
$T=4$では$S_5$より記憶辞書$Dict$を参照し、その値を取り出している。
$T=5$では$S_6$より出力記憶集合に$T=4$で取り出された記憶を複製している。
$T=6$では$S_2$より出力する記憶を事象に変換し、「リンゴ」と発している。
※補足 上記のアルゴリズムにのっとると$T=4$以降 $M_1$も出力され続けるが、省略している。
3. 3. 例題3 行動の促進・抑制
ここでは4つのステップに分けて賞罰による行動の変化を考える。
わかりやすさのため、$I_A,O_A$は省略する。
3. 3. 1. ステップ1
リンゴを見て、「ぶどう」という声を発し、罰を受ける場合を考える。
-
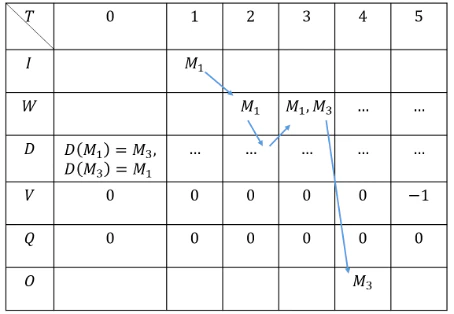
表3 ステップ1の状態変化
-
表3説明
初期状態ではリンゴの景色の記憶と「ぶどう」という声の記憶のつながりのみを持っている。
$T=1-3$では$S_3,S_5$より記憶が入力され記憶辞書を参照して取り出した記憶を一時記憶に格納している。
$T=4$では$S_6$より記憶を出力記憶集合へ複製している。
$T=5$では$S_7$より本能関数が罰を与え、$T=3$の時の一時記憶を使って行動価値関数を次のように更新している。
$$Q(W,M_3 )← -1 | W={M_1,M_3} $$
3. 3. 2. ステップ2
リンゴを見て、「ぶどう」という声を発さない場合を考える。
- 表4 ステップ2の状態変化

- 表4の説明
初期状態ではステップ1の$T=5$の記憶辞書$Dict$, 行動価値関数$Q$のみを持つ。
$T=1-3$では$S_3,S_5$より記憶が入力され記憶辞書を参照して取り出した記憶を一時記憶に格納している。
$T=4$では$S_7$より$Q(W,M_3 )= -1$ のため、$M_3$は出力記憶集合に複製されず、$T=5$では発さない。
3. 3. 3. ステップ3
リンゴを見て「リンゴ」という声を聞き、賞をもらう場合を考える。
- 表5 ステップ3の状態変化

- 表5説明
初期状態ではステップ1の$T=5$の記憶辞書$Dict$, 行動価値関数$Q$のみを持つ。
$T=1-3$では$S_3,S_5,S_6$より記憶が入力され記憶辞書を参照して取り出した記憶を一時記憶に格納している。また行動価値関数が負のため「ぶどう」の声の記憶$M_3$は発しない。
$T=4-5$では$S_3$より新しく「りんご」の声の記憶$M_2$を集め、一時記憶集合に格納している。
$T=6$では$S_4$より新しい記憶によって記憶辞書$Dict$が更新される。表5にはその例を示す。
$T=7$では$S_6$と$T=6$の$M_2$の行動価値関数の値より、「りんご」と発す。
$T=8$では$S_7$より本能関数が賞を与え、$T=6$の時の一時記憶を使って行動価値関数を次のように更新している。
$$Q(W,M_2 )← 1 | W={M_1,M_2,M_3} $$
3. 3. 4. ステップ4
リンゴを見て、「ぶどう」という声を発さず「リンゴ」という声を発する場合を考える。
-
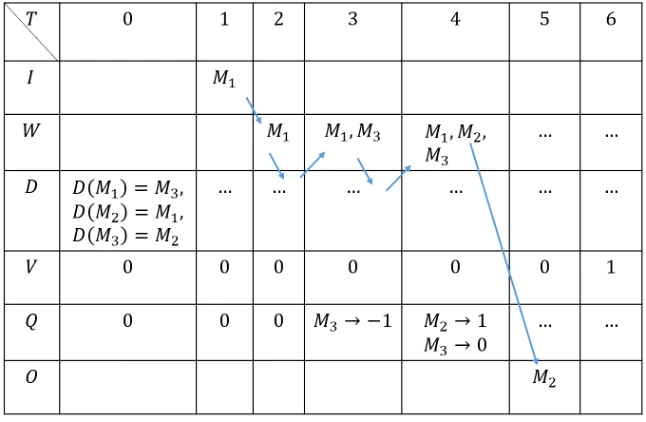
表6 ステップ4の状態変化
-
表6説明
初期状態ではステップ3の$T=8$記憶辞書$Dict$, 行動価値関数$Q$のみを持つ。
$T=1-3$では$S_3,S_5,S_6$記憶が入力され記憶辞書を参照して取り出した記憶を一時記憶に格納している。また行動価値関数が負のため「ぶどう」の声の記憶$M_3$は発しない。
$T=4$では$Q(W,M_2 )=1$をとる。また一時記憶の中身が異なるため、$Q(W,M_3)$は初期値$0$をとる。一時記憶の小さな差異による問題は実装上の工夫によって解決することができる。
$T=5$では$S_6$より$T=4$の行動価値関数の値が$M_3$よりも$M_2$の方が大きいため、「りんご」という声の記憶$M_2$を発する。
$T=6$では$S_7$より本能関数が賞を与え、$T=4$の時の一時記憶を使って行動価値関数を次のように更新している。
$$ Q(W,M_2 )← 1 | W={M_1,M_2,M_3} $$
4. まとめ
ここまでで「意識」とそれに必要なことを定義し、それらに基づいていくつかのアルゴリズムを考えた。
今回提案したアルゴリズムは、ほとんどを深層ニューラルネットワークによって実装することができる。事象から記憶への変換はクラスタリングをすればよく、記憶辞書はWord2Vecのように記憶同士の共起確率を計算すればよい。本能関数は定義する必要があるが、行動価値関数はTransformerを用いたモデルによって簡潔に書くことができる。次はこれらの具体的な実装方法を書く予定だ。
最後に
自分でもびっくりするほど妄想が膨らんで大変でした。それでも一応成果物?としてまとまったので良しとしましょう。