What’s Retrieval Augmented Generation (RAG) ‘s position
Deploying GenAI can be done in multiple ways:
- Prompt engineering on public APIs (e.g. Databricks DBRX Instruct, LLama 2, openAI): answer from public information, retail (think ChatGPT)
- Retrieval Augmented Generation (RAG): specialize your model with additional content. This is what we'll focus on in this demo
- OSS model Fine tuning: when you have a large corpus of custom data and need specific model behavior (execute a task)
- Train your own LLM: for full control on the underlying data sources of the model (biomedical, Code, Finance...)
What is Retrieval Augmented Generation (RAG) for LLMs?
RAG is a powerful and efficient GenAI technique that allows you to improve model performance by leveraging your own data (e.g., documentation specific to your business), without the need to fine-tune the model. This reduces hallucination and allows the LLM to produce results that provide company-specific data, without making any changes to the original LLM.
Deploy Your LLM Chatbots With the Data Intelligence Platform and DBRX Instruct
Implementing RAG with Databricks AI Foundation models
1/ Ingest data and create your Vector Search index
The first step is to use the Data Engineering Lakehouse capabilities to ingest our documentation pages, split them into smaller chunks, compute the chunk embeddings and save them as a Delta Lake table before we can make use of our Vector Search index.
2/ Deploying a RAG chatbot endpoint with Databricks DBRX Instruct Foundation Endpoint
The second step is to create a langchain model with an augmented prompt, accessing the Databricks DBRX Instruct model, finding documentation related to our user question by Vector Search Index
(Hands on)Ingesting and preparing PDF for LLM and Self Managed Vector Search Embeddings
Prequest
Install sample notebook
%pip install dbdemos
import dbdemos
dbdemos.install('llm-rag-chatbot', catalog='catalog_george', schema='pdf_matching')
Create vector search endpoint
config
There is a limit to the number of Vector Search endpoints that can be created later, so change VECTOR_SEARCH_ENDPOINT_NAME to one that can be used.
Open the 01-PDF-Advanced-Data-Preparation
Ingesting pdf documents as source for our retrieval process.
Install required external libraries
%pip install transformers==4.30.2 "unstructured[pdf,docx]==0.10.30" langchain==0.1.5 llama-index==0.9.3 databricks-vectorsearch==0.22 pydantic==1.10.9 mlflow==2.10.1
dbutils.library.restartPython()
%run ../PDF_LLM/llm-rag-chatbot/_resources/00-init-advanced $reset_all_data=false
Ingesting Databricks ebook PDFs and extracting their pages
First, We'll use Databricks Autoloader to incrementally ingest our PDFs as a Delta Lake table.Autoloader easily ingests our unstructured PDF data in binary format.
%sql
CREATE VOLUME IF NOT EXISTS volume_databricks_documentation;
or directly upload
Ingesting PDF files as binary format using Databricks cloudFiles (Autoloader) or directly upload
df = (spark.readStream
.format('cloudFiles')
.option('cloudFiles.format', 'BINARYFILE')
.option("pathGlobFilter", "*.pdf")
.load('dbfs:'+volume_folder+"/profile"))
# Write the data as a Delta table
(df.writeStream
.trigger(availableNow=True)
.option("checkpointLocation", f'dbfs:{volume_folder}/checkpoints/raw_docs')
.table('pdf_raw').awaitTermination())
%sql SELECT * FROM pdf_raw LIMIT 2
Extracting our PDF content as text and Splitting them in smaller chunks
1)PDFs are hard to work with, so that we'll need an OCR to convert the PDF documents bytes to text by using the Unstructured library within a Spark UDF.
2)some PDFs are very large, with a lot of text.We'll extract the content and then use llama_index SentenceSplitter, and ensure that each chunk isn't bigger than 500 tokens.
The chunk size and chunk overlap depend on the the PDF files.
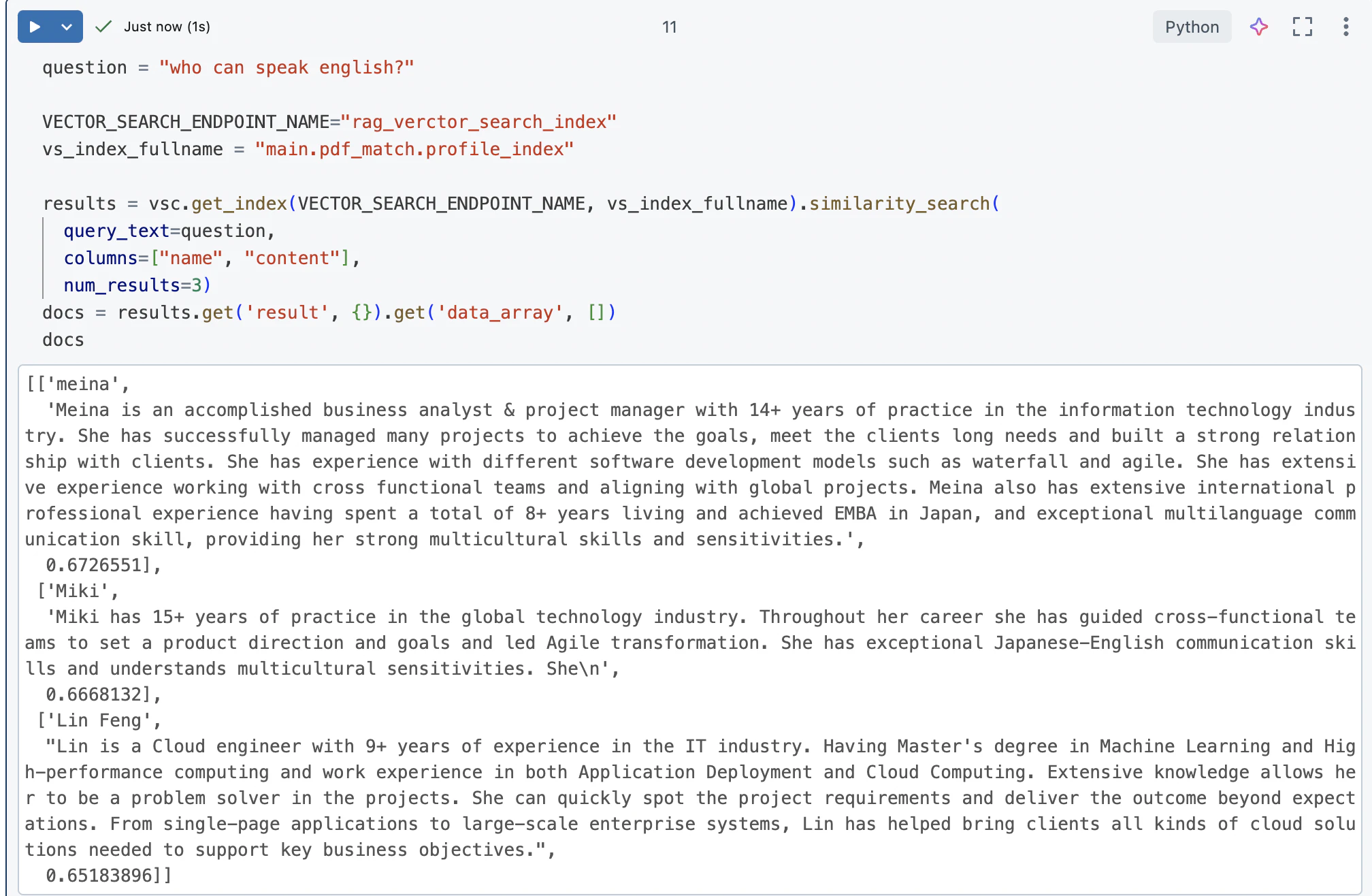
The main content can refer to the content in reference 1 advance.
After completing it, you can get the following content
Reference
1.LLM Chatbot With Retrieval Augmented Generation (RAG) and DBRX
https://notebooks.databricks.com/demos/llm-rag-chatbot/index.html#
2.DatabricksにおけるRAGの実践(前編)
3.DatabricksにおけるRAGの実践(後編)
4.DatabricksにおけるRetrieval Augmented Generation(RAG)
https://qiita.com/taka_yayoi/items/1f7825b06c16e8b721da
5.RAGによる社内ナレッジを活用したチャットボットの構築
https://qiita.com/Mitsuhiro_Itagaki/items/be256775a8ce4b725827
6.How to create and query a Vector Search index
https://docs.databricks.com/en/generative-ai/create-query-vector-search.html
7.Vector Searchを動かしてみる
https://qiita.com/taka_yayoi/items/3bdffae4bd040d25ee60