こちらのウォークスルーです。まずは本当に一通り動かすところまでです。
エンべディングモデルの登録とサービング
ここではOSSのエンべディングモデルを使います。
このノートブックでは、Vector Searchで使用できるモデルサービングエンドポイントでe5-small-v2のオープンソーステキストエンべディングモデルをセットアップします。
- Hugging Face Hubからモデルをダウンロード
- MLflowモデルレジストリへの登録
- モデルがサーブされるモデルサービングエンドポイントを起動
モデルe5-small-v2は右で公開されています: https://huggingface.co/intfloat/e5-small-v2
- MITライセンス
- 派生系:
これはDBR 13.2 MLでテストされていますが、他のバージョンでも動くはずです。特定のライブラリバージョンについては、DBR 13.2 ML release notesをご覧ください。
Databricks python SDKのインストール
サービングエンドポイントを操作するためにPythonクライアントを使用します。
%pip install -U databricks-sdk
dbutils.library.restartPython()
モデルのダウンロード
# sentence_transformersライブラリを用いたモデルのダウンロード
from sentence_transformers import SentenceTransformer
source_model_name = 'intfloat/e5-small-v2' # Hugging Face Hubにおけるモデル名
model = SentenceTransformer(source_model_name)
# 動作確認のためにモデルをテスト
sentences = ["This is an example sentence", "Each sentence is converted"]
embeddings = model.encode(sentences)
print(embeddings)
[[-7.24058524e-02 4.72473949e-02 1.45743387e-02 -3.30961198e-02
-4.54308167e-02 2.82988641e-02 1.07215106e-01 -3.77488472e-02
9.86611657e-03 3.15312035e-02 3.53261307e-02 -3.10433619e-02
-4.09466177e-02 4.39202003e-02 1.54092228e-02 -5.30367047e-02
-1.00718113e-02 5.08562103e-02 -1.31060824e-01 1.89213548e-02
8.88702646e-02 -6.99376166e-02 5.36029600e-03 -5.79565428e-02
-2.11174395e-02 5.67687815e-03 6.33126823e-03 9.21319053e-02
-1.43286828e-02 -8.07622373e-02 -4.14064080e-02 -8.48542550e-05
5.25100119e-02 -3.95204611e-02 6.05509654e-02 -2.89479122e-02
-4.94688265e-02 1.98759101e-02 2.70234849e-02 2.00989563e-02
MLflowにモデルを登録
# MLflowのモデル名: モデルレジストリではこのモデル名を使用します
registered_model_name = 'taka-e5-small-v2'
import mlflow
# 入力/出力スキーマの計算
signature = mlflow.models.signature.infer_signature(sentences, embeddings)
print(signature)
inputs:
[string]
outputs:
[Tensor('float32', (-1, 384))]
params:
None
model_info = mlflow.sentence_transformers.log_model(
model,
artifact_path="model",
signature=signature,
input_example=sentences,
registered_model_name=registered_model_name)
モデルが記録されます。
# これによって、プログラムから登録したモデルのバージョンを取得します。
# 実際には、使用する前にモデルを"Productions"のステージにプロモーションすることでしょう。
mlflow_client = mlflow.MlflowClient()
models = mlflow_client.get_latest_versions(registered_model_name, stages=["None"])
model_version = models[0].version
model_version
バージョン1のモデルが記録されています。
'1'
モデルサービングエンドポイントの作成
詳細については、モデルサービングエンドポイントの作成および管理をご覧ください。
警告: このサンプルでは0にまでスケールダウンするsmallなCPUエンドポイントを作成します。より現実的なユースケースでは以下を必要とするかもしれません:
- 高速な計算のためのGPUエンドポイント
- (モデルサービングエンドポイントのコールドスタートにはある程度の起動時のオーバーヘッドがあるため)頻繁なクエリーが予測される場合には0にスケールダウンしないように
endpoint_name = "taka-e5-small-v2" # 作成するエンドポイント名
Databricks SDKワークスペースクライアントの作成
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput
w = WorkspaceClient()
エンドポイントの作成
endpoint_config_dict = {
"served_models": [
{
"name": f'{registered_model_name.replace(".", "_")}_{1}',
"model_name": registered_model_name,
"model_version": model_version,
"workload_type": "CPU",
"workload_size": "Small",
"scale_to_zero_enabled": True,
}
]
}
endpoint_config = EndpointCoreConfigInput.from_dict(endpoint_config_dict)
# エンドポイントの準備ができるまでには数分を要します
w.serving_endpoints.create_and_wait(name=endpoint_name, config=endpoint_config)
ServingEndpointDetailed(config=EndpointCoreConfigOutput(config_version=1, served_models=[ServedModelOutput(creation_timestamp=1701671794000, creator='takaaki.yayoi@databricks.com', environment_vars=None, instance_profile_arn=None, model_name='taka-e5-small-v2', model_version='1', name='taka-e5-small-v2_1', scale_to_zero_enabled=True, state=ServedModelState(deployment=<ServedModelStateDeployment.DEPLOYMENT_READY: 'DEPLOYMENT_READY'>, deployment_state_message=''), workload_size='Small', workload_type='CPU')], traffic_config=TrafficConfig(routes=[Route(served_model_name='taka-e5-small-v2_1', traffic_percentage=100)])), creation_timestamp=1701671794000, creator='takaaki.yayoi@databricks.com', id='4d471313a0fa41d6bd9da6a586768b01', last_updated_timestamp=1701671794000, name='taka-e5-small-v2', pending_config=None, permission_level=<ServingEndpointDetailedPermissionLevel.CAN_MANAGE: 'CAN_MANAGE'>, state=EndpointState(config_update=<EndpointStateConfigUpdate.NOT_UPDATING: 'NOT_UPDATING'>, ready=<EndpointStateReady.READY: 'READY'>), tags=None)
エンべディングモデルをサービングするエンドポイントが作成されます。

(準備ができたら)エンドポイントへのクエリー
上のcreate_and_waitコマンドは、エンドポイントが準備できるまで待つはずです。サービングエンドポイントの準備状態に関しては、DatabricksのUIでチェックすることもできます。
詳細はサービングエンドポイントへのスコアリングリクエストの送信をご覧ください。
import time
start = time.time()
# (準備ができていないエンドポイントから)タイムアウトエラーを受け取る際には、待ってから以下を再実行します
endpoint_response = w.serving_endpoints.query(name=endpoint_name, dataframe_records=['Hello world', 'Good morning'])
end = time.time()
print(endpoint_response)
print(f'Time taken for querying endpoint in seconds: {end-start}')
QueryEndpointResponse(predictions=[[-0.009296439588069916, 0.06918294727802277, 0.036366499960422516, 0.0034117570612579584, -0.015888312831521034, -0.015289321541786194, 0.06358581781387329, -0.08108192682266235, -0.0022949744015932083, 0.04259680584073067, 0.0557326041162014, 0.01342878770083189, -0.03011913038790226, 0.04097330570220947, 0.0466892383992672, -0.047855935990810394, 0.011086142621934414, 0.010089868679642677, -0.14671120047569275, 0.02561090514063835, 0.05807391181588173, -0.04596301168203354, -0.010017135180532932, -0.045596107840538025, -0.03825042396783829, -0.01948373019695282, 0.026301827281713486, 0.04099428281188011, -0.05741281434893608, -0.12793973088264465, -0.046298056840896606, -0.0011654832633212209, 0.05256413668394089, -0.029035048559308052, 0.045775555074214935, -0.042124878615140915, 0.022786177694797516, 0.02557487040758133, 0.01801937073469162,
:
:
Time taken for querying endpoint in seconds: 0.16251897811889648
これでエンべディングを返却するモデルサービングエンドポイントが起動しました。
Vector Search Python SDK活用のサンプル
このノートブックでは、Vector Searchを操作する際の主要なAPIとしてのVectorSearchClientを提供するVector Search Python SDKの使用方法をデモンストレーションします。
あるいは、直接REST APIを呼び出すことができます。
前提条件: このノートブックではエンべディングモデルのモデルサービングエンドポイントがすでに作成されていることを前提としています。以下のembedding_model_endpointとエンドポイント作成の関連ノートブックをご覧ください。
%pip install --upgrade --force-reinstall databricks-vectorsearch
dbutils.library.restartPython()
from databricks.vector_search.client import VectorSearchClient
vsc = VectorSearchClient()
help(VectorSearchClient)
Help on class VectorSearchClient in module databricks.vector_search.client:
class VectorSearchClient(builtins.object)
| VectorSearchClient(workspace_url=None, personal_access_token=None, service_principal_client_id=None, service_principal_client_secret=None, azure_tenant_id=None, azure_login_id=None, disable_notice=False)
|
| Methods defined here:
|
| __init__(self, workspace_url=None, personal_access_token=None, service_principal_client_id=None, service_principal_client_secret=None, azure_tenant_id=None, azure_login_id=None, disable_notice=False)
| Initialize self. See help(type(self)) for accurate signature.
|
| create_delta_sync_index(self, endpoint_name, index_name, primary_key, source_table_name, pipeline_type, embedding_dimension=None, embedding_vector_column=None, embedding_source_column=None, embedding_model_endpoint_name=None)
|
| create_direct_access_index(self, endpoint_name, index_name, primary_key, embedding_dimension, embedding_vector_column, schema)
|
| create_endpoint(self, name, endpoint_type='STANDARD')
|
| delete_endpoint(self, name)
トイデータセットをソースDeltaテーブルにロード
# 以下のソースDeltaテーブルを作成します
source_catalog = "quickstart_catalog_taka"
source_schema = "vector_search"
source_table = "en_wiki"
source_table_fullname = f"{source_catalog}.{source_schema}.{source_table}"
source_df = spark.read.parquet("dbfs:/databricks-datasets/wikipedia-datasets/data-001/en_wikipedia/articles-only-parquet").limit(10)
display(source_df)

source_df.write.format("delta").option("delta.enableChangeDataFeed", "true").saveAsTable(source_table_fullname)
display(spark.sql(f"SELECT * FROM {source_table_fullname}"))
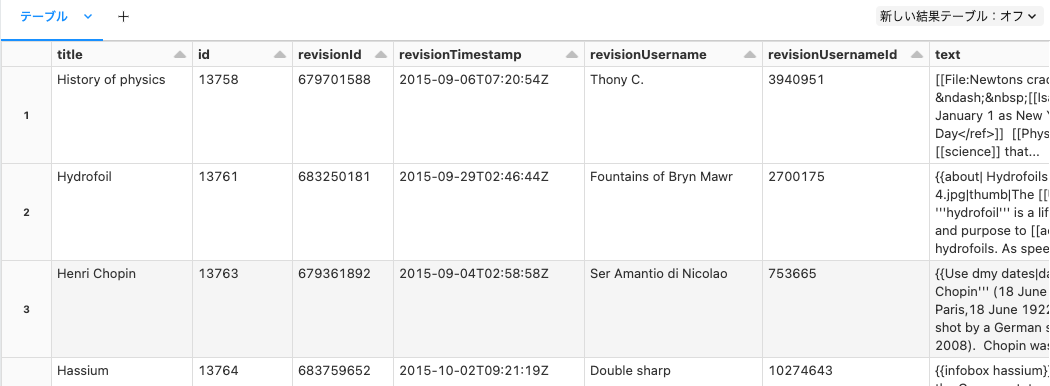
カタログエクスプローラにもテーブルが表示されます。
Vector Searchエンドポイントの作成
vector_search_endpoint_name = "taka-vector-search-demo-endpoint"
vsc.create_endpoint(
name=vector_search_endpoint_name,
endpoint_type="STANDARD"
)
{'name': 'taka-vector-search-demo-endpoint',
'creator': 'takaaki.yayoi@databricks.com',
'creation_timestamp': 1701673189267,
'last_updated_timestamp': 1701673189267,
'endpoint_type': 'STANDARD',
'last_updated_user': 'takaaki.yayoi@databricks.com',
'id': '0657e36c-652f-4036-8046-27ba3aabc3fa',
'endpoint_status': {'state': 'PROVISIONING'}}
しばらくすると、Vector Searchのエンドポイントが作成されます。
Vectorインデックスの作成
# Vectorインデックス
vs_index = "en_wiki_index"
vs_index_fullname = f"{source_catalog}.{source_schema}.{vs_index}"
embedding_model_endpoint = "taka-e5-small-v2"
index = vsc.create_delta_sync_index(
endpoint_name=vector_search_endpoint_name,
source_table_name=source_table_fullname,
index_name=vs_index_fullname,
pipeline_type='TRIGGERED',
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name=embedding_model_endpoint
)
index.describe()
Vectorインデックスの取得
# Vectorインデックスの取得
## Vectorインデックス名を用いてVector indexオブジェクトを取得するために get_index() メソッドを使用
index = vsc.get_index(endpoint_name=vector_search_endpoint_name, index_name=vs_index_fullname)
## インデックスの設定情報のサマリーを参照するためにインデックスオブジェクトに対して describe() を使用
index.describe()
{'name': 'quickstart_catalog_taka.vector_search.en_wiki_index',
'endpoint_name': 'taka-vector-search-demo-endpoint',
'primary_key': 'id',
'index_type': 'DELTA_SYNC',
'delta_sync_index_spec': {'source_table': 'quickstart_catalog_taka.vector_search.en_wiki',
'embedding_source_columns': [{'name': 'text',
'embedding_model_endpoint_name': 'taka-e5-small-v2'}],
'pipeline_type': 'TRIGGERED',
'pipeline_id': 'ede5fde5-869c-41e7-96aa-4ea1132283a3'},
'status': {'detailed_state': 'ONLINE_NO_PENDING_UPDATE',
'message': 'Index creation succeeded using Delta Live Tables: https:xxxxx#joblist/pipelines/ede5fde5-869c-41e7-96aa-4ea1132283a3/updates/0c3fafd9-105c-4fe7-8674-e6d5f1d2f9db',
'indexed_row_count': 10,
'triggered_update_status': {'last_processed_commit_version': 0,
'last_processed_commit_timestamp': '2023-12-04T06:56:05Z'},
'ready': True,
'index_url': 'xxxx/api/2.0/vector-search/endpoints/taka-vector-search-demo-endpoint/indexes/quickstart_catalog_taka.vector_search.en_wiki_index'},
'creator': 'takaaki.yayoi@databricks.com'}
カタログエクスプローラにVector Search Indexが表示されます。しばらくすると、Data IngestのUpdate statusが完了になります。

類似検索
類似ドキュメントを特定するためにVector Indexをクエリーします!
# returns [col1, col2, ...]
# これはカラムの任意のサブセットに設定することができます
all_columns = spark.table(source_table_fullname).columns
results = index.similarity_search(
query_text="Greek myths",
columns=all_columns,
num_results=2)
results
結果が返ってきました!
{'manifest': {'column_count': 8,
'columns': [{'name': 'title'},
{'name': 'id'},
{'name': 'revisionId'},
{'name': 'revisionTimestamp'},
{'name': 'revisionUsername'},
{'name': 'revisionUsernameId'},
{'name': 'text'},
{'name': 'score'}]},
'result': {'row_count': 2,
'data_array': [['Hercules',
13770.0,
681213961.0,
'2015-09-15T21:36:46',
'Djkeddie',
1884088.0,
'{{About|Hercules in classical mythology|the Greek divine hero from which Hercules was adapted|Heracles|other uses|Hercules (disambiguation)}} {{pp-semi-indef|small=yes}}{{Infobox deity | type = Roman | name = Hercules | image = Pieter paul rubens, ercole e i leone nemeo, 02.JPG | image_size = | alt = | birth_place = | death_place = | caption = \'\'Hercules fighting the Nemean lion\'\'{{br}}by [[Peter Paul Rubens]] | god_of = | abode = | symbol = | consort = [[Juventas]] | parents = [[Jupiter (mythology)|Jupiter]] and [[Alcmene]] | siblings = | children = | mount = |
結果をLangChainドキュメントに変換
取得された最初のカラムは page_content にロードされ、残りはメタデータにロードされます。
from langchain.schema import Document
def convert_vector_search_to_documents(results) -> list[Document]:
column_names = []
for column in results["manifest"]["columns"]:
column_names.append(column)
langchain_docs = []
for item in results["result"]["data_array"]:
metadata = {}
score = item[-1]
# print(score)
i = 1
for field in item[1:-1]:
# print(field + "--")
metadata[column_names[i]["name"]] = field
i = i + 1
doc = Document(page_content=item[0], metadata=metadata) # , 9)
langchain_docs.append(doc)
return langchain_docs
langchain_docs = convert_vector_search_to_documents(results)
langchain_docs
[Document(page_content='History of physics', metadata={'id': 13758.0, 'revisionId': 679701588.0, 'revisionTimestamp': '2015-09-06T07:20:54', 'revisionUsername': 'Thony C.', 'revisionUsernameId': 3940951.0, 'text': '[[File:Newtons cradle animation book 2.gif|thumb|"If I have seen further, it is only by standing on the shoulders of giants." – [[Isaac Newton]] <ref>Letter to [[Robert Hooke]] (15 February 1676 by Gregorian reckonings with January 1 as New Year\'s Day). equivalent to 5 February 1675 using the [[Julian calendar]] with March 25 as New Year\'s Day</ref>]] [[Physics]] (from the [[Ancient Greek]] φύσις \'\'[[physis]]\'\' meaning "[[nature]]") is the fundamental branch of [[science]] that developed out of the study of nature and [[philosophy]] known, until around the end of the 19th century, as "[[natural philosophy]]". Today, physics is ultimately defined as the study of [[matter]], [[energy]] and the relationships between them.{{citation needed|date=February 2015}}
Vectorインデックスの削除
vsc.delete_index(index_name=vs_index_fullname)
とりあえず動きました!次は日本語で動かしてみます。