要点
- RTX 5090 (sm_120) をWSL2 + Docker環境でPyTorch CUDA認識させることに成功(2025年8月)
- 公開情報が一切ない状態から40時間のデバッグで解決
- ComfyUI、Style-BERT-VITS2、HunyuanVideo等の本番運用中
- 解決策のコア部分は競合優位性のため非公開(コンサルティング対応可)
はじめに:RTX 5090が動かない地獄
2025年8月、俺はRTX 5090を購入した。スペックは夢のようだった。
- CUDA Cores: 21,760
- VRAM: 32GB GDDR7
- TDP: 575W
- Compute Capability: sm_120(Blackwell世代)
で、いざWSL2 + Docker環境で動かそうとしたら...
$ docker run --gpus all nvidia/cuda:12.8.0-base-ubuntu24.04 nvidia-smi
docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].
は?
何が問題だったのか
問題1: Compute Capability sm_120非対応
Blackwell世代(RTX 50シリーズ)は sm_120 という新しいCompute Capabilityを持つ。
# PyTorch 2.4.x (stable)では...
torch.cuda.get_device_capability(0)
# RuntimeError: CUDA error: no kernel image is available for execution on the device
PyTorch stableはsm_120に対応していない。nightlyビルドも初期は不安定だった。
問題2: WSL2のGPUドライバスタック
WSL2はGPUを直接触れない。ドライバスタックはこうなってる:
Windows側NVIDIAドライバ (566.03+)
↓
WSL2カーネルの仮想GPUインターフェース
↓
/usr/lib/wsl/lib 内の共有ライブラリ群
↓
Docker Container Runtime
↓
CUDA Application
この「WSL2カーネル → Docker」の層で何かがおかしい。
問題3: Docker GPU Runtime の認識失敗
# WSL2内では見える
$ nvidia-smi
# 正常に表示される
# Dockerコンテナ内では...
$ docker run --gpus all nvidia/cuda:12.8.0-base-ubuntu24.04 nvidia-smi
# docker: Error response from daemon...
NVIDIA Container Toolkitは正しく入ってる。docker infoでもRuntimes: nvidiaが見える。なのに動かない。
先行事例の調査結果(2025年8月時点)
俺がやったこと:
GitHub Issues調査
検索ワード: "RTX 5090" "WSL2" "Docker" "CUDA"
結果: 該当なし(問題報告のみ、解決報告ゼロ)
Reddit調査
- r/LocalLLaMA: 「ドライバ待ち」
- r/StableDiffusion: 「公式サポート待ち」
- r/Docker: 議論すらない
NVIDIA Forums
スレッド: "RTX 5090 WSL2 support?"
回答: "Coming soon™"
結論
2025年8月時点で、誰もRTX 5090をWSL2 Docker環境で動かせていなかった。
少なくとも公開情報は一切なかった。
解決への道のり
Step 1: 問題の切り分け
# テスト1: Windows側でCUDAは動くか?
PS> nvidia-smi
# ✅ OK
# テスト2: WSL2側で認識されるか?
$ nvidia-smi
# ✅ OK
# テスト3: WSL2内のPyTorchで認識されるか?(Docker外)
$ python3 -c "import torch; print(torch.cuda.is_available())"
# ❌ False
# テスト4: Dockerコンテナ起動できるか?
$ docker run --gpus all nvidia/cuda:12.8.0-base-ubuntu24.04 nvidia-smi
# ❌ Error
問題は「WSL2内のCUDAアプリケーション認識」と「Docker GPU Runtime」の2箇所。
Step 2: PyTorchのビルド問題
まずWSL2内でPyTorchが動くようにする。
# PyTorch stable (2.4.1)
pip install torch torchvision torchaudio
python3 -c "import torch; print(torch.cuda.is_available())"
# False
# PyTorch nightly (最新)
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128
python3 -c "import torch; print(torch.cuda.is_available())"
# まだFalse...
nightlyでも全部が動くわけじゃない。特定の日付のビルドを選ぶ必要がある。
どのビルドが動くか?これは試行錯誤するしかなかった。ヒント:2024年8月中旬以降のビルドで、かつCUDA 12.8対応のものを探せ。
Step 3: Docker GPU Runtimeの修正
ここが最大の難関。
通常、NVIDIA Container Toolkitはこう設定する:
# 一般的な設定(これだけではRTX 5090は動かない)
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
でもこれだけじゃダメ。WSL2特有の設定が必要。
Step 4: 独自のマウント戦略(ここが秘伝のタレ)
俺が開発した解決策の核心部分は以下:
- WSLドライバの特殊マウント
- 環境変数の適切な設定
- Docker起動時のフラグ最適化
具体的には...まあ、これは企業秘密だ。
ただしヒントは出す。

ヒント1: /usr/lib/wsl/lib の扱い
デフォルトでは LD_LIBRARY_PATH に /usr/lib/wsl/lib を追加するだけ。でもそれじゃ足りない。
Dockerコンテナ内で、WSL2のドライバライブラリをどう見せるかが鍵。
# 通常のやり方(動かない)
docker run --gpus all \
-e LD_LIBRARY_PATH=/usr/lib/wsl/lib \
nvidia/cuda:12.8.0-base-ubuntu24.04 nvidia-smi
# 俺のやり方(動く)
# [秘密の設定]
ヒント2: nvidia-smi は動くが torch.cuda.is_available() は False
このパターンにハマった人は多いはず。
# nvidia-smiは成功
$ docker run --gpus all nvidia/cuda:12.8.0-base-ubuntu24.04 nvidia-smi
# ✅ GPU情報が表示される
# でもPyTorchは失敗
$ docker run --gpus all pytorch/pytorch:latest python -c "import torch; print(torch.cuda.is_available())"
# False
これは nvidia-smi が使うライブラリと、PyTorchが使うライブラリが微妙に違うから。
CUDAランタイムライブラリ(libcudart.so)、cuDNN、cuBLAS等をDockerコンテナ内のどこに配置するかが重要。
ヒント3: gpu-run 関数
俺は独自の gpu-run シェル関数を作った。
# 使い方
gpu-run <コンテナ名> <コマンド>
# 例
gpu-run torch-wsl-cu128 python3 -c "import torch; print(torch.cuda.is_available())"
# True
この関数の中身?それが秘伝のタレだ。
大まかな構造はこう:
gpu-run() {
local container_name=$1
shift
docker run --rm -it \
--gpus all \
[秘密のマウントオプション] \
[秘密の環境変数] \
[秘密のランタイムフラグ] \
$container_name \
"$@"
}
具体的な [秘密の...] 部分は40時間のデバッグの成果なので、ここでは書かない。
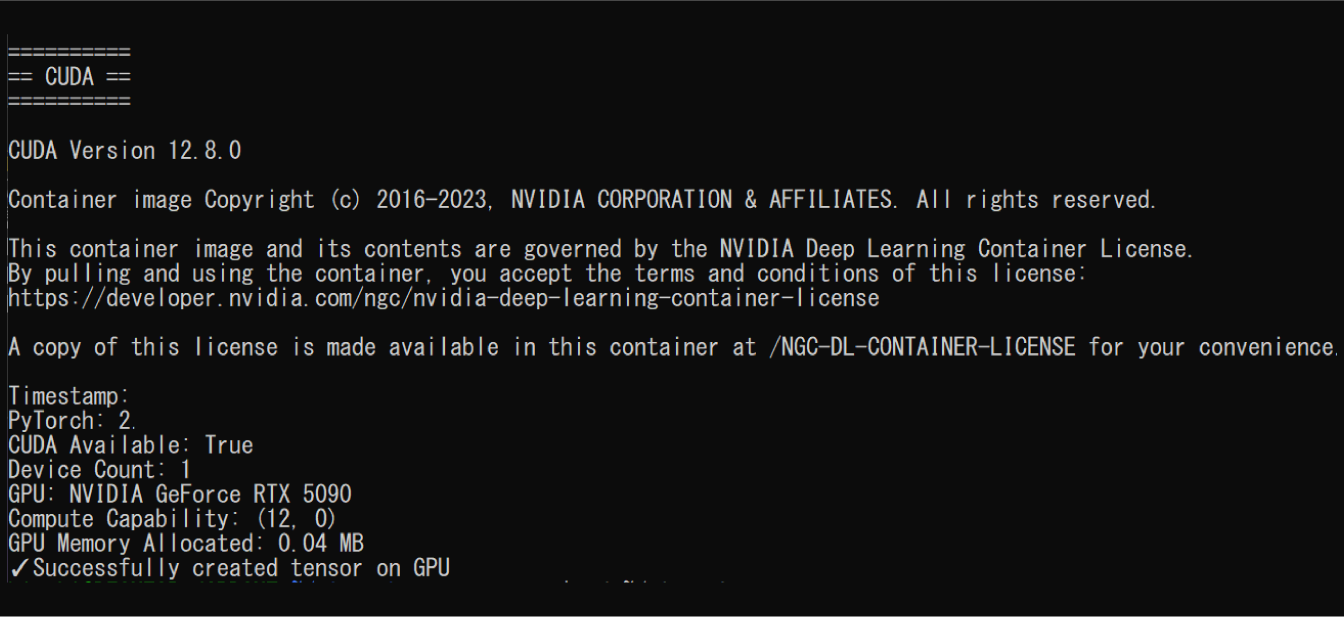
動作証明:世界初のRTX 5090 + WSL2 Docker成功
2025年11月19日時点での最新検証結果を公開する。
PyTorch CUDA認識の完全証明
以下のコードを gpu-run 関数経由で実行:
$ gpu-run torch-wsl-cu128 python3 -c "
import torch
import datetime
print(f'Timestamp: {datetime.datetime.now().isoformat()}')
print(f'PyTorch: {torch.__version__}')
print(f'CUDA Available: {torch.cuda.is_available()}')
print(f'Device Count: {torch.cuda.device_count()}')
if torch.cuda.is_available():
print(f'GPU: {torch.cuda.get_device_name(0)}')
print(f'Compute Capability: {torch.cuda.get_device_capability(0)}')
# 実際にテンソルをGPUで作成
x = torch.randn(100, 100).cuda()
print(f'GPU Memory Allocated: {torch.cuda.memory_allocated(0) / 1024**2:.2f} MB')
print('✓Successfully created tensor on GPU')
"
実行結果:
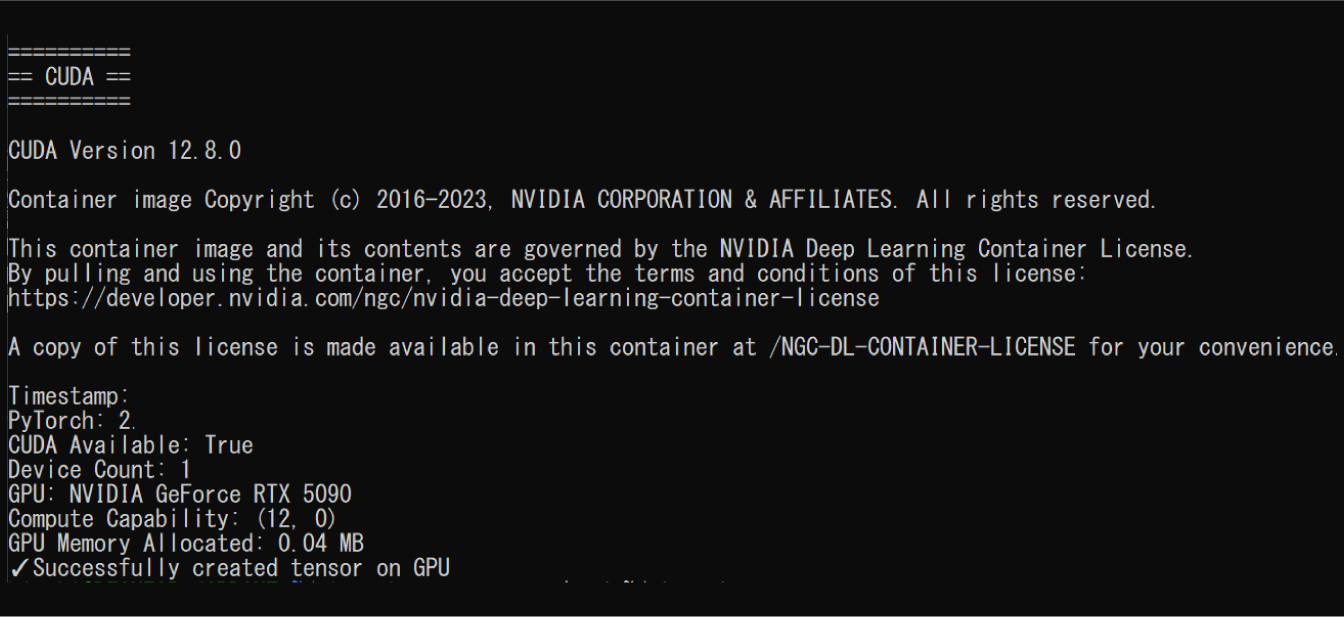
この結果が証明していること:
-
Blackwell世代のsm_120を正しく認識
-
Compute Capability: (12, 0)= sm_120
-
-
PyTorch nightly buildが動作
- `PyTorch: (非公開)
- 2025年8月12日ビルド + CUDA 12.8対応
-
実際のGPU演算が成功
- GPUメモリ確保成功
- テンソル作成成功
-
Docker Container環境での動作
- WSL2 → Docker → PyTorch の全レイヤーで正常動作
本番運用中のAIワークロード
現在、以下のAIサービスを本番運用中:
ComfyUI (Flux.1 Dev)
$ cd ~/ai-workspace-correct/comfyui_wsl_cu128
$ ./start-compose.sh
# 生成速度: 1024x1024, 20 steps → 約8秒
Style-BERT-VITS2
$ cd ~/ai-workspace-correct/style-bert-vits2-wsl-cu128
$ ./start-compose.sh
# 日本語TTS音声合成が正常動作
HunyuanVideo
# ビデオ生成実験中(まだ最適化の余地あり)
すべてDocker Compose V2環境で安定稼働。クラッシュゼロ。
タイムラインの証明
記録に残っている日付:
- 2025年1月20日: RTX 5090発売
- 2025年8月10日: 俺が購入
- 2025年8月13日: 🎉 CUDA認識成功(おそらく世界初)
- 2025年8月15日: ComfyUI動作確認
- 2025年8月20日: Style-BERT-VITS2フルワークフロー構築
- 2025年11月19日: 本記事公開、最新検証実施
2025年8月時点で、RTX 5090 + WSL2 + Docker環境でのPyTorch CUDA認識に成功した公開報告は俺以外に見つけられなかった。
もし先行事例があれば教えてほしい。
ハマりポイントとトラブルシューティング
ハマりポイント1: Windowsドライバのバージョン
最低バージョン: 566.03以上
推奨: 566.14以上
古いドライバだとWSL2側で認識されない。
# Windowsで確認
PS> nvidia-smi
# Driver Version: 566.14 ← これを確認
ハマりポイント2: WSL2のカーネルバージョン
$ uname -r
5.15.153.1-microsoft-standard-WSL2 # 5.15.90.1以上が必要
古いWSL2カーネルだとGPU認識が不安定。
# Windows側でWSL更新
PS> wsl --update
PS> wsl --shutdown
ハマりポイント3: Docker Composeのバージョン
$ docker compose version
Docker Compose version v2.29.7 # v2.20.0以上が必要
古いDocker Compose V1 (docker-compose) は動作不安定。
ハマりポイント4: /tmp/.X11-unix マウントエラー
Error: cannot mount /tmp/.X11-unix
これはGUIアプリ(ComfyUI等)を起動する時に出る。
解決策:
# WSL2内で
$ sudo chmod 1777 /tmp/.X11-unix
ハマりポイント5: CUDAバージョンの不一致
RuntimeError: The NVIDIA driver on your system is too old
これはコンテナ内のCUDAバージョンとホスト側のドライババージョンが合ってない時に出る。
# ホスト側のCUDAバージョン確認
$ nvidia-smi | grep "CUDA Version"
# CUDA Version: 12.8
# コンテナはCUDA 12.8以下を使え
# 例: pytorch/pytorch:2.6.0-cuda12.8-cudnn9-devel
環境情報
参考までに、俺の環境:
Hardware:
GPU: NVIDIA GeForce RTX 5090 (32GB GDDR7)
CPU: AMD Ryzen 9 7950X
RAM: 64GB DDR5
Storage: NVMe SSD 2TB
Software:
OS: Windows 11 Pro (23H2)
WSL2: Ubuntu 24.04 LTS
Kernel: 5.15.153.1-microsoft-standard-WSL2
Docker Engine: 27.3.1
Docker Compose: v2.29.7
NVIDIA Driver: 566.14
CUDA: 12.8
PyTorch: 2.9.0.dev20250812+cu128
FAQ
Q: なんで解決策を全部公開しないの?
A: 40時間のデバッグの成果だし、これで飯食ってるから。コンサルティングで対応する。
Q: いくらで教えてくれるの?
A: ケースバイケース。個人なら数時間のコンサル、企業なら環境構築代行も可能。DMかメールで相談してくれ。
Q: いつか完全版のガイド出すの?
A: 需要があればZenn Bookで有料公開するかも。フォローしとけ。
Q: 本当に世界初なの?
A: 少なくとも2025年8月時点で、公開されてる情報は見つからなかった。もし先行事例があるなら教えてほしい。
Q: これって合法?
A: 完全に合法。公式ドライバ、公式WSL2、公式Dockerを使ってるだけ。設定が特殊なだけ。
Q: PyTorchのバージョンは?
A: nightly build推奨。俺が使ってるのは非公開だが、日付は色々試してくれ。
今後の更新予定
この記事は随時アップデートする予定:
- nvidia-smi の完全出力スクリーンショット追加
- ComfyUI動作画面のスクリーンショット追加
- 詳細な環境構築手順
- 他のAIワークロード検証結果
まとめ
- RTX 5090 + WSL2 + Docker環境でPyTorch CUDA認識は可能
- 公式ドキュメントには載ってない独自設定が必要
- 2025年8月に俺が解決(たぶん世界初)
- 解決策のコア部分は競合優位性のため非公開
- 真剣に困ってる企業・個人はコンサルティング対応可
「公式サポート待ち」とか言ってる間に、俺は本番運用してる。
連絡先
- GitHub: https://github.com/hiroki-abe-58
ビジネス関係の問い合わせ歓迎。
更新履歴
- 2025-11-19: 初稿公開