42Tokyo Advent Calendar 2025 Day #2 としての投稿です。
はじめに
「英語が喋れない。」
これが私のスペックです。そんな私が、アジア5カ国から集まったエンジニアと42時間戦い、優勝しました。
ただし、これは私一人の力ではありません。正直に言えば、私はチームメイトに助けられてばかりでした。42コミュニティには多様なバックグラウンドを持つメンバーが集まっており、英語が堪能なメンバーが私の弱点を完全にカバーしてくれました。彼らがいなければ、私は現地で何もできなかったでしょう。本当に感謝しています。チームの多様性で補い合えること——これこそが42の強みだと実感したハッカソンでした。
この記事でわかること
- 42コミュニティで開催されるハッカソンイベント
- 英語が苦手なエンジニアがどう立ち回り、どう貢献したか
- LLMの公開API禁止縛りでの開発戦略
- 高精度OCRモデル:
Paddle OCRのユースケース - Cloud Runの第1世代 vs 第2世代の罠
この記事で触れないこと
- 42Tokyoの詳細説明、カリキュラム
- Piscineでの体験
「英語が話せない自分が、ハッカソンで本当に役に立てるのか?」、「英語が苦手だから海外イベントは無理」と思っている方に、私の経験をベースに少しでも勇気を届けられれば嬉しいです。
42 Tokyo
42 Tokyoは、フランス発の革新的なエンジニア養成機関「42」の東京校です。教師や教科書がなく、学生同士で学び合う「ピアラーニング」方式が特徴で、多様なバックグラウンドを持つメンバーが集まるコミュニティです。詳細は公式サイトをご覧ください。
立ち位置としては教育機関ですが、私はオフラインのエンジニアコミュニティとして認識しています。
アドベントカレンダーでその他の42Tokyoのメンバーが、カリキュラムや体験記を投稿すると思うので、興味がある方は覗いてみてください。
自己紹介
GawinGowin、もといintra名sarakiです。
普段はSREとして働いており、クラウドインフラの設計・構築やKubernetesを活用したコンテナオーケストレーション、そして生成AI利活用のためのコンサルティング業務などを行っています。業務を通じてLLMの可能性に触れる機会が増え、現在はLLMについてより深く理解するために勉強を進めています。
42Tokyoでは最終課題を突破済みで、現在 Level.10 に到達しています。最終のExamの受験のみを残しているため、一応First Circle(Common Core) の学生であり、Second Circle(Advanced)のカリキュラムを開始するタイミングを伺っています。
今回私は、一部バックエンド機能(PIIのマスキング)、LLM、クラウドインフラを担当いたしました。

現在の課題進捗、ノード一つ一つが課題。将来的な課題のアップデートにより、異なる形になるかも
42 Asia Hackathon 2025 とは
42 Asia Hackathonは、アジア地域の42キャンパス間の連携強化と交流促進を目的としたハッカソンイベントです。今年度の参加校は以下の5キャンパスで、各校から5名の学生が参加していました。
- 42 Seoul(韓国)
- 42 Singapore(シンガポール)
- 42 Tokyo(日本)
- 42 Bangkok(タイ)
- 42 Amman(ヨルダン)
イベントは42時間のハッカソンを中心に構成されており、スポンサー企業から提供されたテーマに沿ってチームで開発を行います。ハッカソン以外にも、現地の見学ツアーや他キャンパスの学生とのネットワーキングの機会が設けられています。
前回は42 Bangkokのチームが優勝したため、第2回の開催地となったようです。
参加経緯
42Tokyoの別の参加者に声をかけてもらったのがきっかけでした。海外でのハッカソンということで単純に楽しそうだなと思いましたし、ちょうど有給も余っていたので、良い機会だと思って参加を決めました。
ただ、応募した時点では土日を挟む日程だろうと勝手に思い込んでいたのですが、蓋を開けてみたら月曜〜金曜のフル平日開催でした。本業の調整はなかなか大変でしたが、なんとか5日間の有給を取ることができました。快く送り出してくれた会社には感謝しています。
スケジュール概要
イベントは2025年11月10日〜14日の5日間で開催されました。私は前日の8日(土曜)の午後にバンコク入りし、14日(金曜)の夜に帰国する1週間の渡航でした。
Day 1(11月10日)- ハッカソン開始
| 時間 | 内容 |
|---|---|
| 13:00 | 受付 |
| 13:30 | オリエンテーション |
| 15:00 | ハッカソン開始 |
| 20:00 | Tech Advisories |
Day 2(11月11日)- 開発
| 時間 | 内容 |
|---|---|
| 09:30 | チェックイン |
| 10:00 | Tech Advisories |
| 12:00 | ランチ |
| 16:00 | ディナー |
| 20:00 | Tech Advisories |
| 21:00 | Zoomセッション(Home Team) |
Day 3(11月12日)- 発表・表彰
| 時間 | 内容 |
|---|---|
| 10:00 | 提出締め切り |
| 10:30 | ピッチ・審査 |
| 13:00 | 表彰式 |
| 15:00〜 | 市内観光、ディナークルーズ |
Day 4-5は42 Bangkokキャンパスツアー、CDGオフィス見学、振り返りセッションなどが行われました。
ハッカソン本番
Day1の15:00からDay3の10:00までがハッカソン本番として設けられており、実際の開発期間は42にちなんで42時間でした。

オープニングセッション
テーマと課題
今回のハッカソンのテーマは、タイのスポンサー企業であるCDG社から提供された「AI-Powered Document Management for Smart Governance(スマートガバナンスのためのAI駆動型文書管理)」です。CDG Groupはタイ政府・公共セクター向けのITソリューションを50年以上提供している企業で、今回のテーマも同社が実際に取り組んでいる行政文書管理の課題を反映しています。
課題の背景
CDG社が提示した課題の背景には、現在の行政文書管理における深刻な課題(Pain Points)が存在します。
- 手作業による時間損失: 文書処理業務の30〜40%が手作業に費やされている
- 高いエラー率: 手入力による10〜15%のエラー発生
- 検索性とプライバシーの問題: 文書の検索が困難で、個人情報保護の課題も存在
- 文書量の増加: 年間30%以上のペースで文書量が増加し続けている
これらの課題を解決するために、AI技術とOCR(光学文字認識)を活用して文書のデジタル化、分類、抽出、要約を行い、行政サービスの迅速化、透明性の向上、機関間連携の強化を目指す——それが今回の開発テーマです。
技術要件
技術面では以下の要素が推奨されています。
- オープンソースのAI/OCR技術の活用
- 文書分類のためのAIエージェントの実装
- Docker/Kubernetes(K8s)によるコンテナ化されたデプロイメント
課題設定の自由度
42の普段の課題と同様に、今回のハッカソンでも 必須実装要件(Mandatory) と ボーナス要件(Bonus) が設けられています。ただし、具体的にどの機能をどのように実装するかは各チームの裁量に委ねられており、課題設定は比較的自由度が高いものです。
審査はコア機能40%、イノベーション20%、ボーナス機能15%、プレゼンテーション15%、パフォーマンス10%という配点で行われます。コア機能の完成度が最重視される一方、独自の工夫や発表の質も評価対象となるため、42時間の中で開発とデモ準備のバランスが大切です。
最終的な成果物はソースコードのリポジトリとテストデータの入力に対しての構造化結果としてのjsonを提出します。
必須実装要件(Mandatory)
必須要件として、以下の3つの機能が求められています。
1. 文書分類(Document Classification)
あらかじめ用意されたドキュメント群を、5種類の文書タイプ
- passport (パスポート):
.png - invoice (請求書):
.pdf - resume (履歴書):
.pdf - purchase order (発注書):
.pdf - customs form (申告書):
.pdf
を正確に分類する機能。システムはレイアウト、テキスト内容、視覚的な手がかりに基づいて文書タイプを自動的に識別する必要があります。
invoiceの例(ダミーデータ)
2. OCR抽出(OCR Extraction)
主に英語で書かれた文書に対してOCR処理を行い、手書き文字を含むテキストを抽出する機能。
3. 構造化データ抽出(Structured Data Extraction)
文書タイプ(例:請求書や領収書)について、主要な情報をJSONのような構造化フォーマットで抽出する機能。単なるテキスト要約よりも、構造化されたデータ出力の方が実用的で価値が高いとされています。
{
"vendor": "Company A",
"invoice_date": "2025-08-19",
"total_amount": 1500.75,
"currency": "THB"
}
ボーナス要件(Bonus)
ボーナス要件として、以下の4つの追加機能が提示されていました。
- 多言語対応(Expanded Language Support)
- 複雑な文書や長文の文書の要約機能(Advanced Summarization)
- 検索・インデックス機能(Search & Indexing)、抽出したデータをElasticsearchやOpenSearchなどの検索エンジンでインデックス化できる形式で出力する機能
- コンプライアンス機能、PII(個人を特定できる情報)のマスキング
開発アプローチ
LLM禁止?
今回の製作物において、一番重要なレギュレーションとして、LLMの公開API(ChatGPT,Gemini等)をアプリから利用してはいけない というものがあります。
今回扱うデータは、非常に機密性の高い文書(という想定)です。これを外部にリークさせることがないようなアプリケーションを作る必要がありました。ですので、データをマルチモーダルモデルに渡して、分類, 構造化出力, 要約して終わり、というわけにはいきません。
ハッカソンスタートの際に提示された情報として、上記の5種類の文書タイプのファイルがそれぞれ2000個程度配布されました。ですので、これらを訓練データとした小規模の機械学習モデルを作ることもアプローチの一つとして考えられます。
単に分類するだけであればそれでよいのですが、OCRや構造化出力を行うことを考えた場合に、行き詰ってしまうでしょう。
タブレットPCでの参戦
個人的な事情ですが、私がタイに持参したPCはスマートフォン用のCPUを搭載したタブレットPCです。普段の開発は会社のPCで行っているため、私用PCはこれしかありません。すべてのエンジニアの私用PCが強いというわけではありません。

Macに囲まれ、ひとりタブレットで開発している図
一応、複数同時にコンテナを動かす程度のことは出来ますし、NPUも入っているので機械学習的なこともできる(?)と思うのですが、重たい処理をローカルで動かしたくないということを頭の中で考えていました。
テーマは与えられていますが、具体的にどのようなストーリー、どのような業務の場面で活用できるアプリケーションにするのか。42時間という限られた時間でどこに焦点を置くのかといったポイントが普段の42の課題とは大きく異なるポイントであり、面白いポイントでした。
製作物
ローカルLLMという抜け道
製作開始の序盤から、LLMを利用することはチーム内でも一致していました。しかし、公開API(ChatGPT,Gemini等)は利用できません。そこで、ローカルLLMをセルフホストして、バックエンドに組み込むことにしました。複雑な課題設定をGPUとLLMの力をコアロジックとして解決するアプローチです。
運営への問い合わせで、20B以下程度のモデルであれば使用可能、かつ、アプリケーションのインフラを提供するためであればAWS, Google Cloud 等のプロバイダを利用することができるとの旨の回答をいただいたのでHuggingFaceからQwen, DeepSeekのファミリーを中心に軽量モデルを探し、LLMはクラウド上でホストする方針にしました。
最終的にはNVIDIA L4 GPUで十分にホストでき、構造化出力が安定して行える点から、google/gemma-2-2b-itを利用しました。このモデルをアプリケーションのコアとして活用します。
LLMをvllmのサーバーモードでホストし、ChatGPTのAPI互換のAPIとして利用できるようにしました。
しかし、このモデルはマルチモーダルではありません。OCRを担うコンポーネントを別途用意する必要があります。
高精度OCRモデル: Paddle OCR
そこで利用したのがPaddlePaddleというOSSです。韓国チームの方から教えていただきました。
PaddlePaddleはOCRに特化した形で学習されたモデルです。PaddlePaddleには大きなメリットが2つあります。第一に、OCRの性能が非常に高いという点です。公開されているモデルをそのまま利用するだけで以下の出力が得られます。
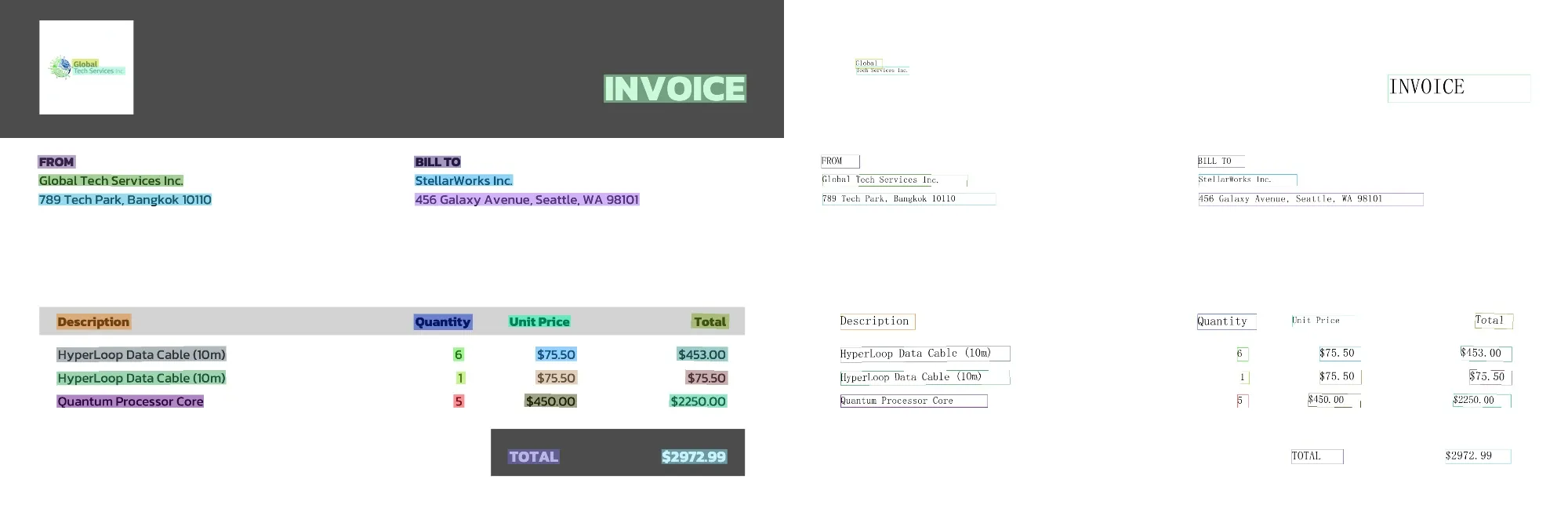
上記ドキュメントをOCRした例
そして第二に、このモデルがCPUで動くということです。LLMとは別にもう一台GPUを用意する必要がありません。

なんとこの精度のOCRがGPUなしで利用できます!
このライブラリとFastAPIを組み合わせて、画像をOCRする専用のAPIとして立てて、こちらもバックエンドから利用する形にしました。
最終的に
- 画像をアップロード
-
Paddle OCRがMarkdownに文字起こし - 文字レイアウトに応じてルールベースで文章分類
-
google/gemma-2-2b-itがMarkdownを受け取る、そして分類結果に対応する構造体に合わせて構造化出力 - DBに保存
というロジックを持ったWebアプリケーションを作成しました。

OCRとLLMのコンポーネントは計算機リソースとして重たいため, Cloud Runを用いて外部にホスト、ローカルにフロントエンドやバックエンド、DBをDocker Compose で構築することで成果物のアプリケーションとしています。
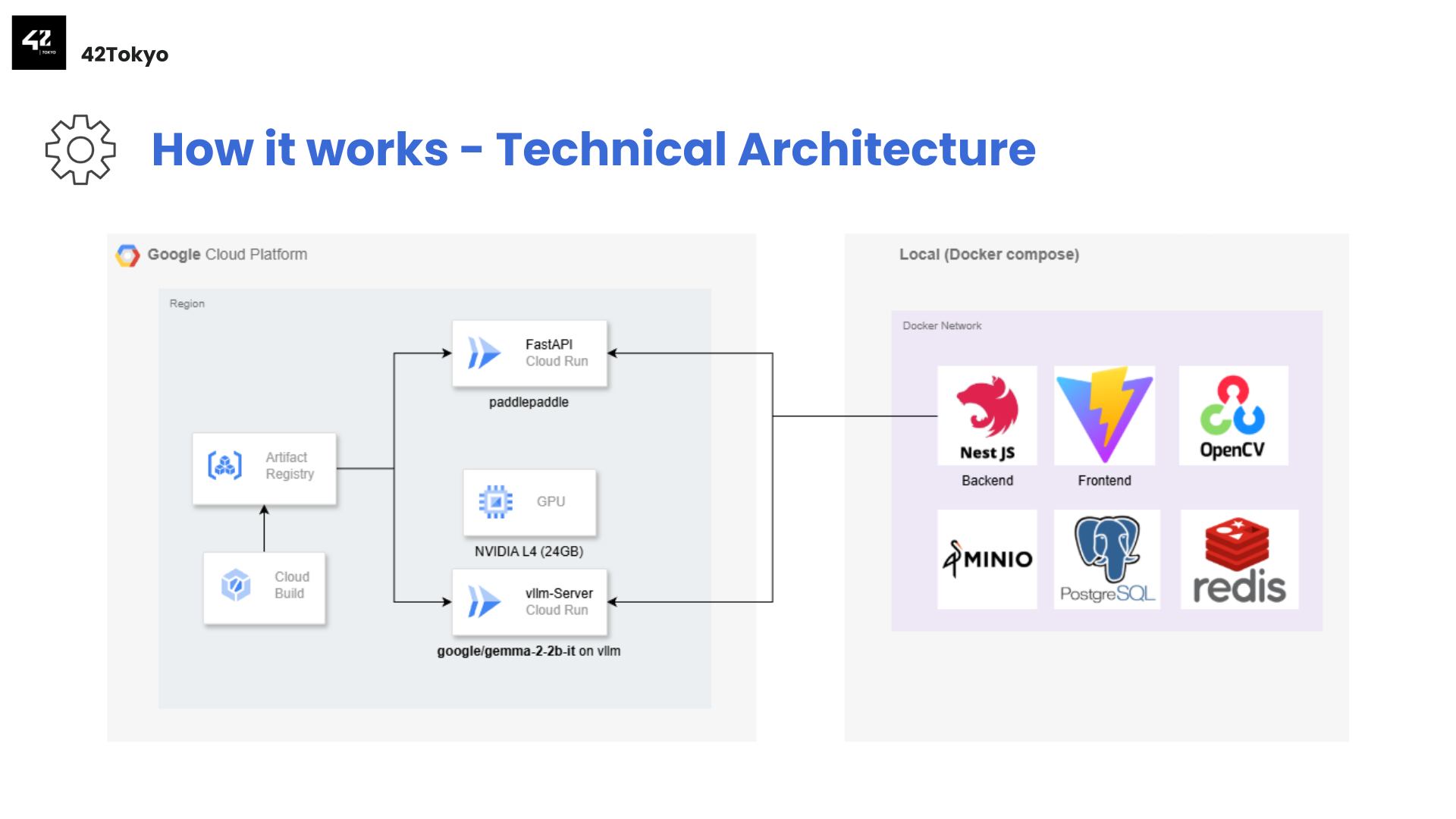
PCスペックに余裕のない私でも安心の構成です。また、審査の過程で提出したソースコードで検証されたのですが、重たい処理が外部化されているため審査員のPCスペックを懸念する必要もありません。
スクリーンショット
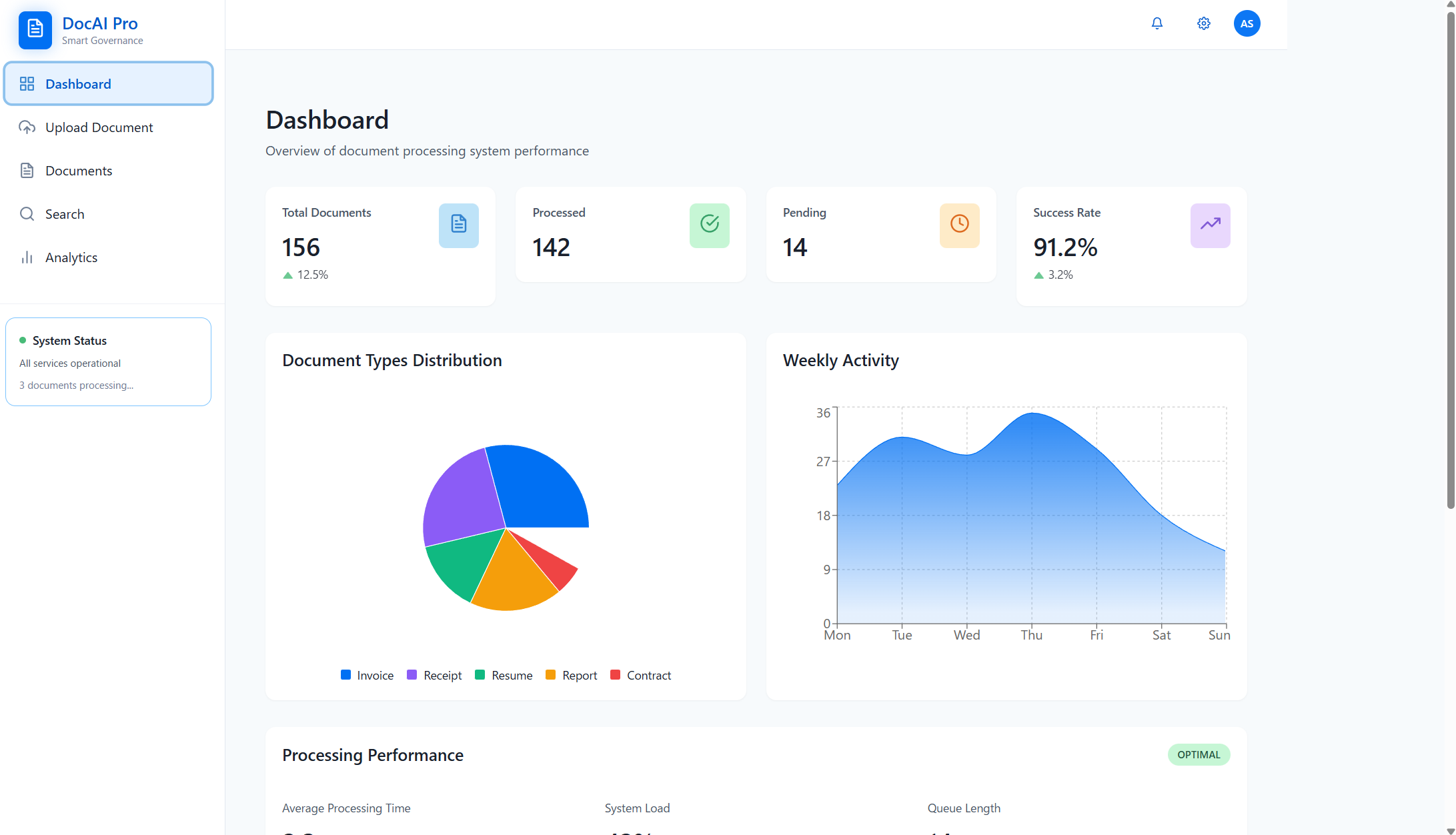
作成したアプリUI
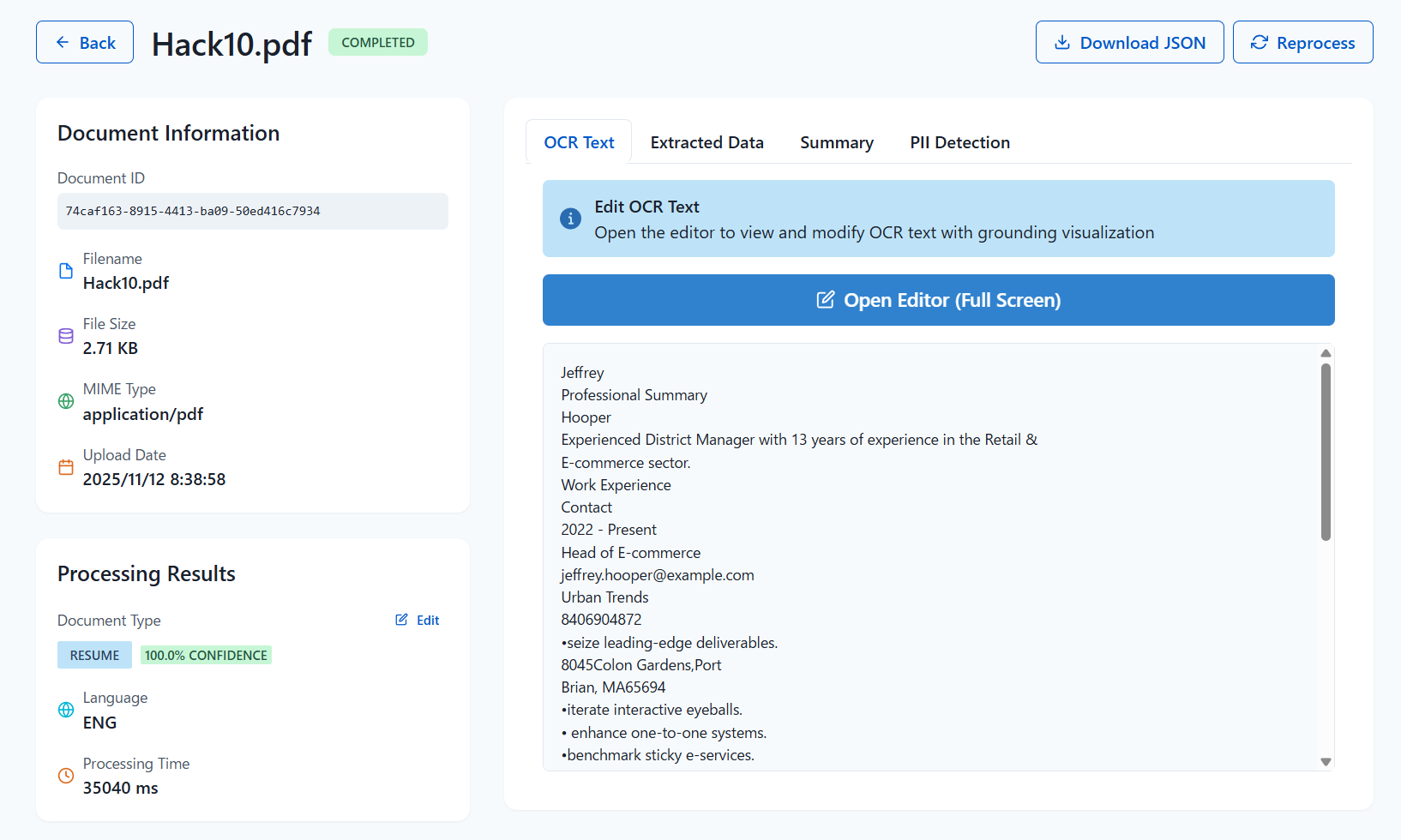
OCRの結果

処理結果のアプリ上での表示
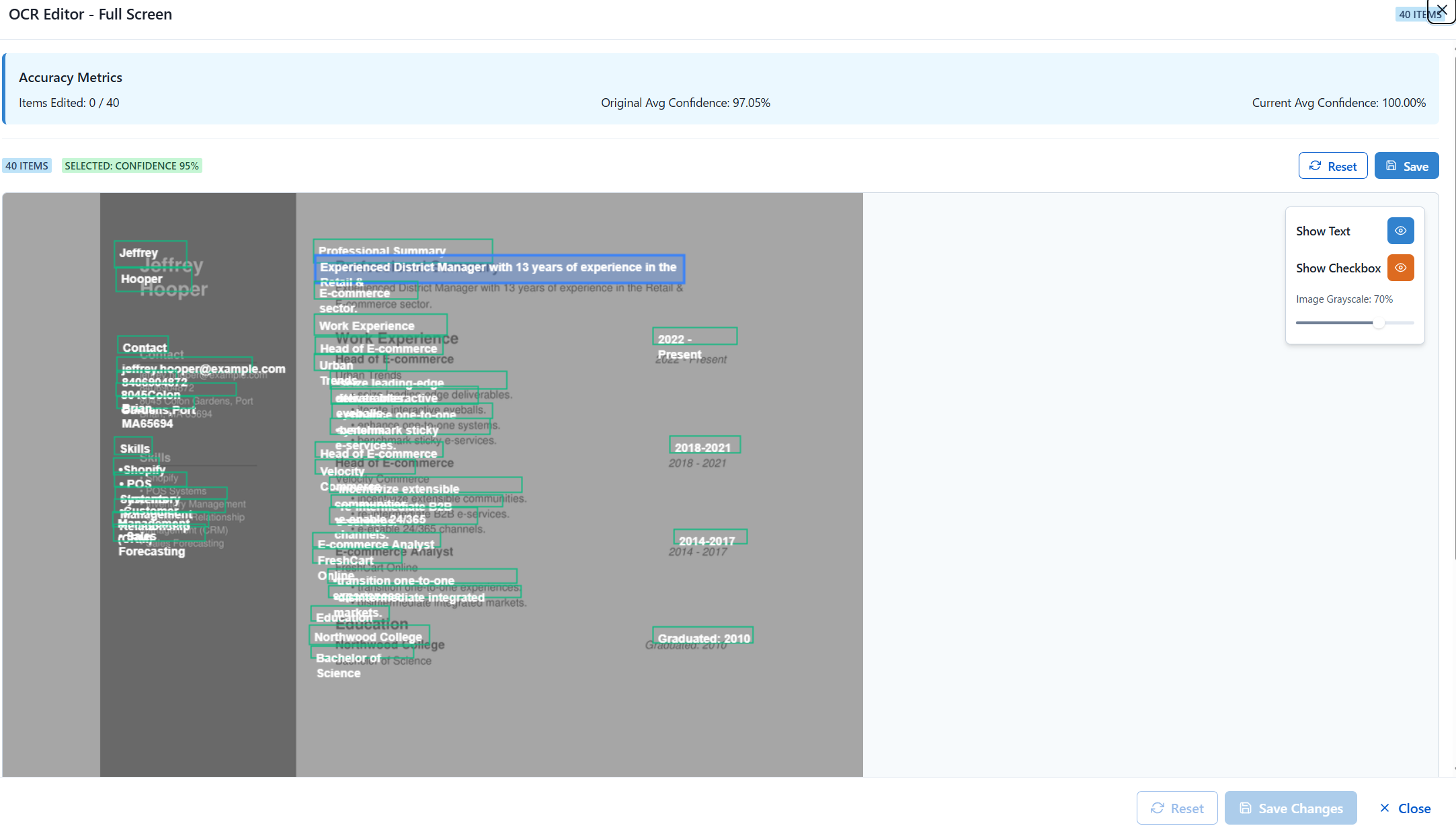
読み取り結果にオーバーレイでテキストを表示

ボックスをクリックすることで読み取り結果を修正できる

アップロードされたドキュメントのリスト
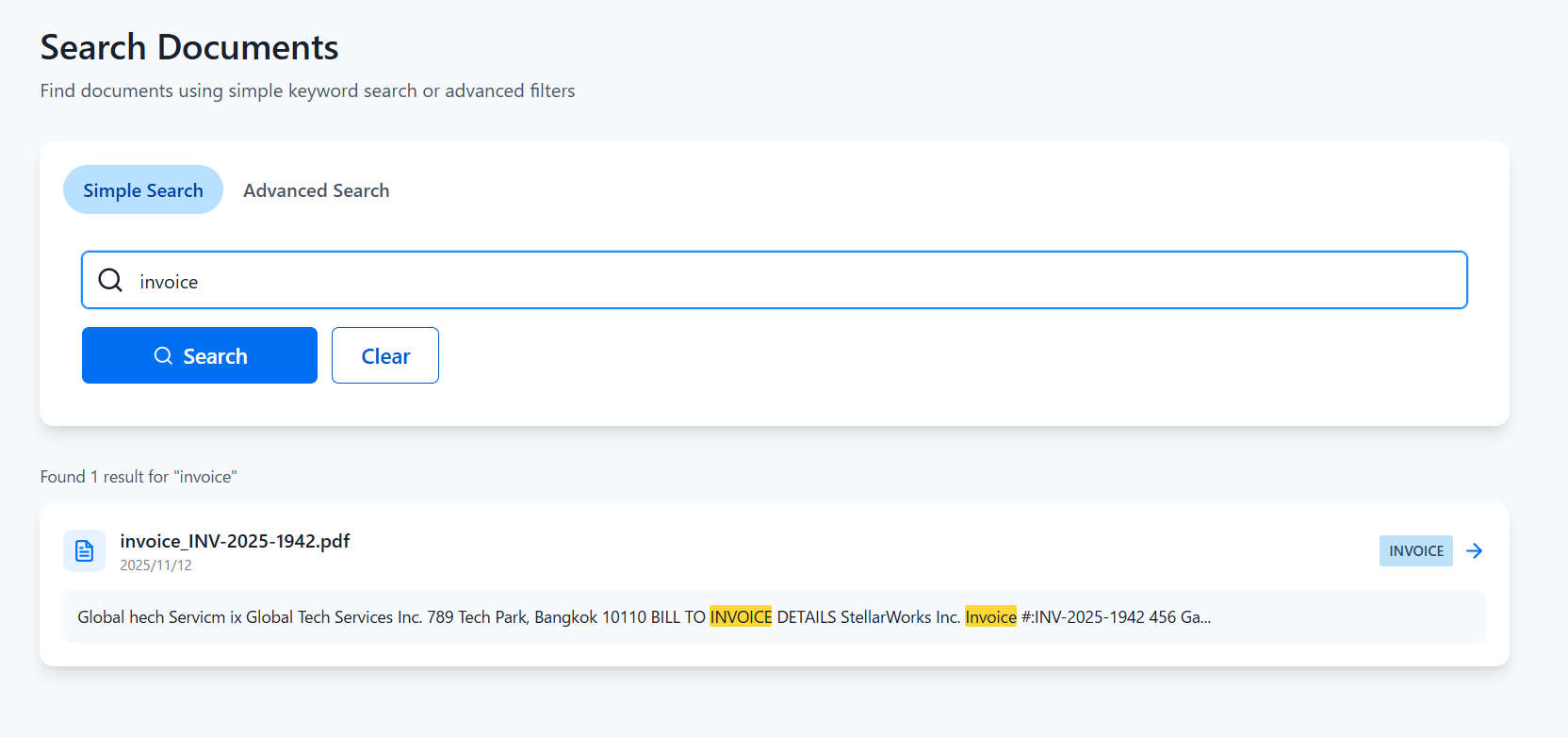
検索機能
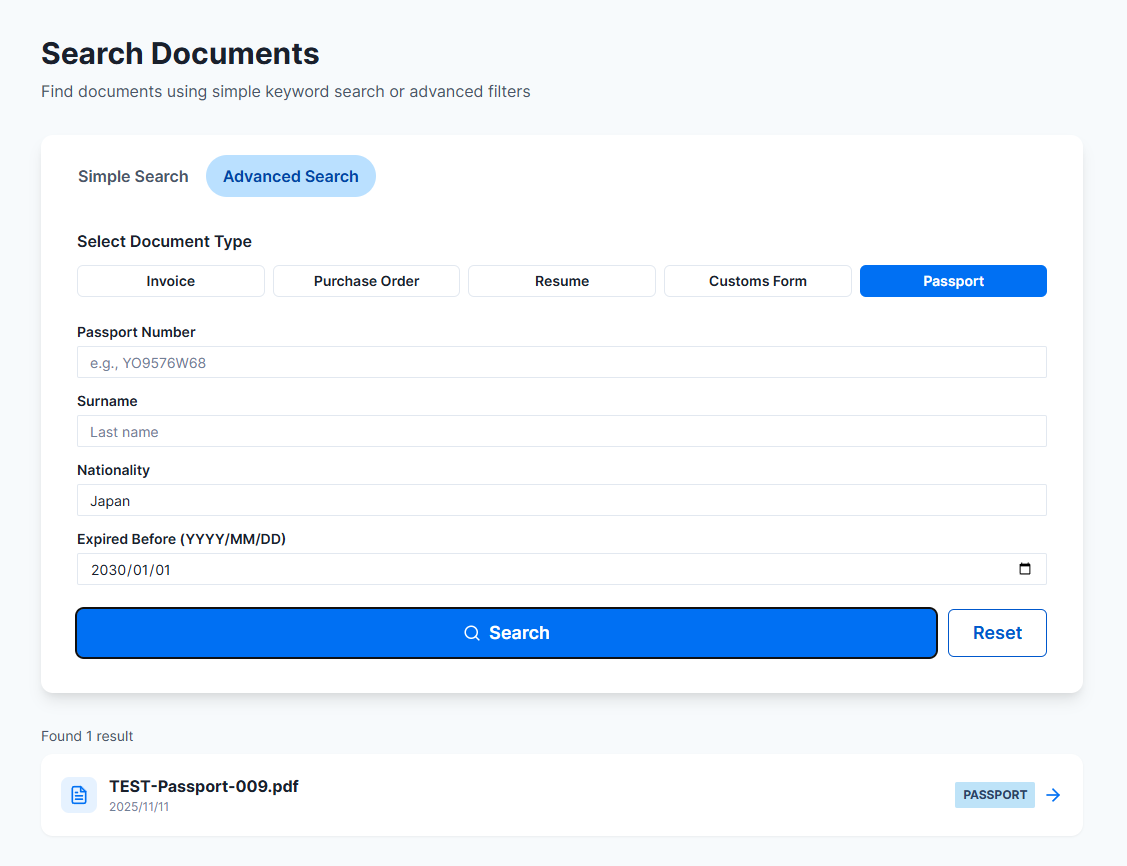
詳細検索機能
検討したもの
DeepSeek OCR
2025年10月21日にディープシークから発表された新しいOCRモデルです。より少ないビジョントークンでの画像認識が可能であり、パラメータ数も3B程度。NVIDIA L4 GPUを利用してホストすることが可能でした。
非常にタイムリーな技術だったので是非とも利用したかったのですが、論文の内容ほど十分な精度でのOCRを行うことができず、時間が限られた中で、デプロイの設定やパラメータを見直す時間がありませんでした。そんな時、PaddlePaddleを知り、これを利用したほうが容易でかつ、リソースも少なく済むと判明したため、使用は見送りました。
発生したトラブル
PaddlePaddleが死んだ夜
Day 2の深夜、突然PaddlePaddleのサービスが再起動ループに陥りました。
「え、嘘でしょ...」
PaddlePaddleのCloud Runが脈絡なく異常終了しました。通常Cloud Runは異常終了すると自動的に再起動するのですが、それを契機に二度と正常に動作しなくなりました。新しいサービスとして、同様のコマンド、設定で再び立ち上げ、動作させることができるのですが、数時間後に同様の再起動ループに陥ってしまいます。
このハッカソンで一番のピンチでした。最も基盤となる処理を担うコンポーネントですので、この機能が変わってしまうと、後半の実装部分が作り直しになってしまいます。

ログ上部で正常起動、下部で異常終了、以降繰り返し
Cloud Run第1世代 vs 第2世代の罠
これはCloud Runの実行環境に依る問題です。もともとCloud Runの第1世代を利用してサービスを動かしていたのですが、これを第2世代の実行環境に変更することで問題が解消しました。
なぜ、第2世代で解決するのかというと、両者の実行基盤が根本的に異なるためです。第1世代はgVisorというコンテナサンドボックス上で動作しており、システムコールをエミュレーションで処理します。そのため、一部のシステムコールがサポートされておらず、PaddlePaddleのような低レベルのシステムリソースに依存するライブラリでは予期せぬ動作を引き起こすことがあります。
一方、第2世代はLinuxとの完全な互換性を持ち、全てのシステムコール、名前空間、cgroupがネイティブにサポートされています。PaddlePaddleが内部で使用していた特定のシステムコールが第1世代では正常に処理されず、これが再起動ループの原因となっていたと考えられます。第2世代への移行により、この制約が解消され、安定稼働するようになりました。
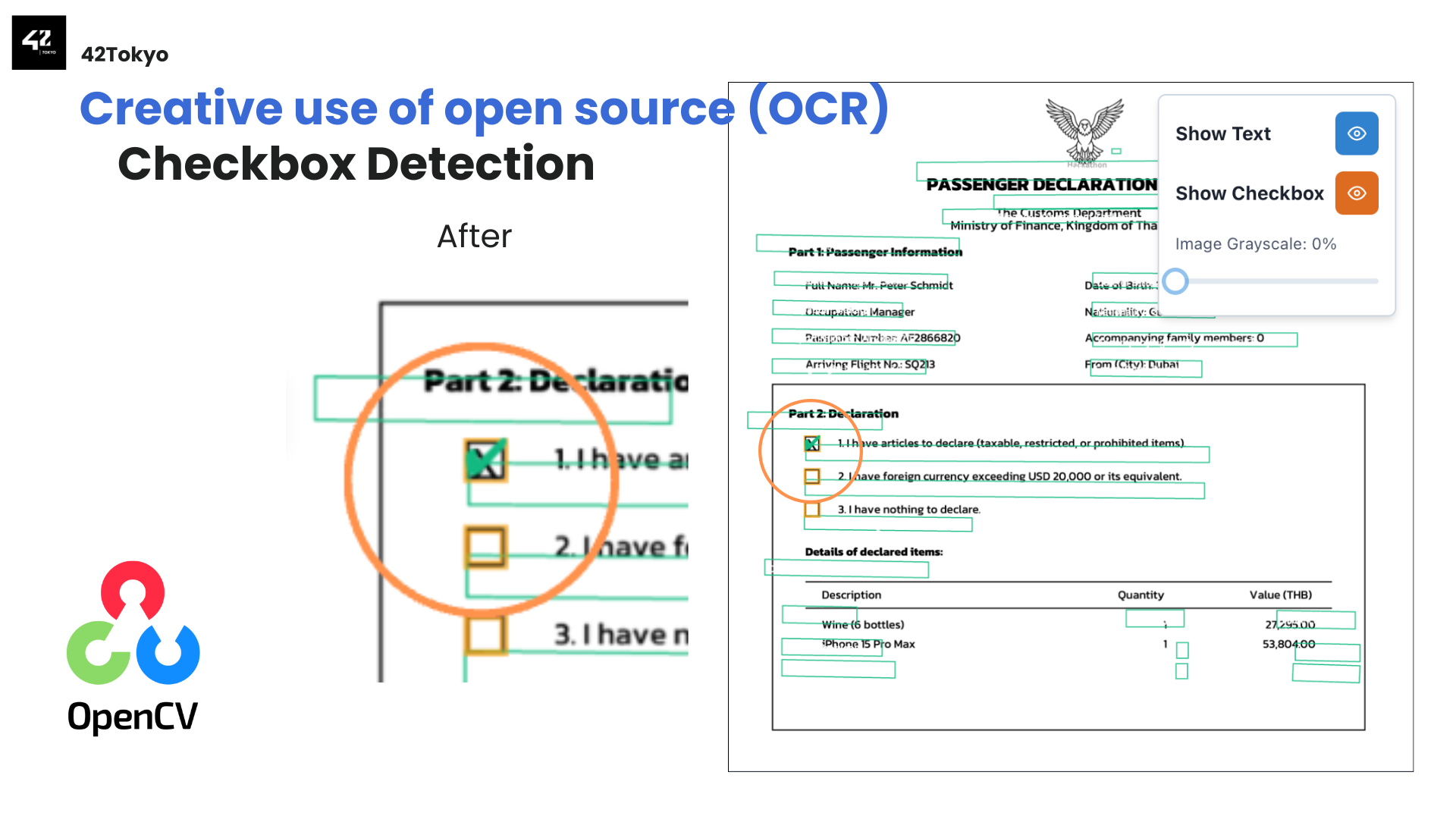
OpenCVでチェックボックス検出を補完
PaddlePaddleのみではチェックボックスの判定精度が非常に悪かったです。そこで、チェックボックスを判定するためだけにOpenCVを利用することで安定したデータ抽出が行えるようになりました。
具体的な実装アプローチは以下の通りです。
- 画像の前処理: 画像をグレースケールに変換し、ガウシアンブラーでノイズを除去
- エッジ検出: Cannyエッジ検出でチェックボックスの輪郭を抽出
- 輪郭の近似と矩形判定: 検出した輪郭を多角形に近似し、4点(矩形)のみを抽出
- サイズとアスペクト比によるフィルタリング: チェックボックスらしいサイズ(15〜50px)かつ、アスペクト比が0.7〜1.3(正方形に近い)ものだけを候補として残す
- チェック状態の判定: 候補領域(ROI)を切り出し、二値化してピクセル密度(暗いピクセルの割合)を計算。密度が40%を超えていれば「チェック済み」と判定
- テキストの関連付け: チェックボックスの右側にある最も近いテキストをPaddleOCRの結果から検索し、そのチェックボックスのラベルとして紐付け
roi = gray[y:y+h, x:x+w]
_, thresh = cv2.threshold(roi, 150, 255, cv2.THRESH_BINARY_INV)
dark_pixels = cv2.countNonZero(thresh)
pixel_density = dark_pixels / roi.size
checked = pixel_density > 0.40 # 密度が40%以上ならチェック済み
このアプローチにより、PaddleOCRが苦手とする小さな正方形のチェックボックスを正確に検出し、チェックの有無も高い精度で判定できるようになりました。OCRはテキスト認識に、OpenCVは図形検出にと、それぞれの得意分野を活かした役割分担が功を奏した形です。
ドキュメントの構造化フォーマットの途中変更による検索機能障害
ドキュメントの処理結果はデータベースに格納しており、特定のカラムがドキュメントの構造化データをJSONB形式で保持しています。
開発途中の段階で、採点に利用される提出データのスキーマと、実際にデータベースに保存している構造化データのスキーマに不一致があることが判明しました。このため、既存のデータ抽出スキーマを提出データの形式に合わせる形でコミット・プッシュしました。
その結果、検索機能に障害が発生しました。
原因は、検索クエリが参照するJSONフィールド名と、新しい抽出スキーマが出力するフィールド名の不一致です。検索クエリのフィールド参照を新しいスキーマに合わせて更新することで復旧しましたが、ギリギリまで対応してくれた担当者には本当に感謝しています。限られた時間の中で黙々と修正作業を進め、無事に機能を復旧させてくれました。この経験から、チーム開発においてはスキーマ変更の影響範囲を事前に把握し、関係者と共有することの重要性を改めて痛感しました。
発表
特にDay 2の夜は過酷で、翌朝10:00の提出締め切りに向けて5人全員が会場に残って徹夜しました。他のチームはホテルに戻って休んでいたようですが、私たちは最後まで会場で粘り続けました。これが日本文化なのか、それとも42Tokyoだけの文化なのかはわかりません。

徹夜明け、仲間の発表を見守る
英語が堪能なメンバー2人が発表を担当してくださいました。
課題設定として、簡単かつ、自動でドキュメントの分類を行うことを強みにした旨の発表です。実際、この2点を意識したWebアプリケーション設計にしており、非常に直感的に操作できるものになっていたと思います。
発表の過程でライブデモも行ったのですが、エラーが発生することもなく完了しました。
振り返りと感想
個人的には、技術スタック自体は42の最終課題や業務で経験があったため比較的スムーズに導入できました。しかし、基礎的な見落としや誤解から生じた些細な問題に時間を要し、自身の知識の定着度に課題が残る結果となりました。
この経験を通じて、「理解したつもり」と「実際に使いこなせる知識」のギャップを痛感しています。
チームとして、このハッカソンが成功した要因は3つあると感じています。
第一に、フルスタックで担当されたメンバーが初日にアプリケーションのプロトタイプとメインロジックの骨子を構築したことです。この初期の成果物が開発の羅針盤となり、チーム全体の共通理解を明確にし、その後の開発プロセスを円滑に進行させました。
続いて、円滑なコミュニケーションを促進するメンバーが、タスクの進捗状況と実装機能の相互理解を徹底させた点です。これにより、不明点の解消と認識のズレを未然に防ぎ、後の手戻りを最小限に抑えた生産性の高い開発につながりました。
そして最後に、各メンバーの高い実装力(実行力)です。個々のタスク解決能力が非常に高く、高い自律性をもって未実装の機能が次々と完了していくスピード感がチームの成功を決定づけました。
そのため、最終的に設定されたMandatoryとBonusの要件をそれぞれ完全に達成する結果となりました。

発表時に意識した通り、私たちのユーザーフレンドリーなUI/UXが「利用者像に最も即している」と高く評価されました。
技術面では、処理速度と、5種類の文書タイプに対するほぼ100%の構造化成功率が決め手になったと感じています。また、OCRの認識ミスがあってもマニュアルで編集できる機能を実装していたため、実運用を見据えた設計として評価されました。
さらに、審査では再現性の高さも重視されていました。私たちは最も再現可能な方法でLLMコンポーネントを用意しており、各種メトリクス(メモリ使用率など)に関する質問にも十分に対応できました。デプロイのためのコマンドやDockerfileも提出リポジトリに含めていたことが、他チームとの差別化につながったと思います。
英語が話せないエンジニアとしての戦い方
ここまで技術的な話を中心に書いてきましたが、記事のタイトルにある通り、私にとってこのハッカソンは「英語が話せないエンジニア」としての挑戦でもありました。
参加前の不安
「英語が話せない自分が、アジア5カ国から集まるハッカソンで本当に貢献できるのか?」
正直に言えば、参加を決めた後もこの不安はずっとありました。コミュニケーションを取る、審査員にプレゼンする。どのシーンを想像しても、英語が絶対に必要になると当初は想像していました。
開発中は意外と英語が必要なかった
結論から言えば、開発フェーズでは英語がほとんど必要ありませんでした。これには3つの理由があります。
理由1: 開発 ~ 発表準備の大部分は日本語で完結
オリエンテーション後の開発42時間はチームに分かれてのもくもく作業です。ですので、Git、Discord、対面でのコミュニケーション、すべて日本語です。
理由2: 英語が必要な場面はチームメイトが完全カバー
英語が必要になるのは、対外的なコミュニケーションの場面だけでした。
課題要件に関しての追加質問の時間が何度か設けられました。チームメンバーで質問内容を決定し、英語が堪能なメンバーに対応していただいたので、私の不得意を完全にカバーしてくださいました。
理由3: 意外な発見 - 聞き取りはできる
私の場合喋るのは苦手ですが、聞き取りはある程度可能でした。これは自分でも意外な発見でした。
スポンサーのプレゼンや審査員の質問も、技術的な文脈があれば、キーワードを拾えば理解できます。「AI」「OCR」「deployment」といった技術用語は世界共通ですし、話の流れを掴めば細かい文法がわからなくても意図は伝わります。
エンジニアとして日頃触れている(英語ドキュメント読解、GitHub Issues)が、実はリスニングにも活きていたのだと実感しました。
交流シーンでの言葉の壁
ただし、正直に言えば、交流会では悔しい思いもしました。
発表後の質疑応答はチームメイトが代弁してくれましたし、表彰式でのスピーチも英語堪能なメンバーが対応してくれました。それ自体はありがたかったのですが、自分の言葉で伝えたかったという思いは残っています。
ハッカソン後の交流会では、英語が喋れないことの壁を痛感しました。他チームのメンバーと技術的な話をしたい、自分たちのアプローチについて伝えたいと思っても、言葉が出てこない。結局、チームメイトに通訳してもらうか、笑顔で頷くしかできませんでした。優勝したのに、自分の言葉で喜びを伝えられないもどかしさは、今でも心残りです。
見学・その他レクリエーションでの写真

お土産の交換、各国の42グッズが集まる

42Bangkok内の様子

42Bangkokに卓球台があったので勝手に遊んでいる42Tokyo組

ハッカソン後の船上交流パーティ
イベント中の食事
イベント中の食事に関しては、なんとありがたいことにお弁当や軽食が食べ放題で用意されていました。朝食、昼食、夕食に加えて、開発中に小腹が空いたときのためのスナックやドリンクも常に補充されていて、食事面では全く困りませんでした。

8割見たことないお菓子、食事のタイミングでここにお弁当が並ぶ
タイ料理を中心としたメニューだったのですが、一つ一つがとてもおいしく、ガパオライスやカオマンガイなど本場の味を楽しむことができました。

デフォルトで辛口、そして食用花
費用など
航空券やホテル代に関しては、42Tokyo校は各人自腹での参加です。
どうやら航空機代など学校が出したチームもあったようで、非常に羨ましかったです。
| 項目 | 費用 |
|---|---|
| 成田空港 - スワンナプーム国際空港 往復 | 約 65,000 円 |
| 1週間のホテル代 | 約 30,000 円 |
| その他観光費用 | 約 20,000 円 |
概算ですが、私の場合は12万円程度かかっていると思います。
来年は東京で会いましょう
私は42Tokyoに入って2年になります。42に入った当初は、というか3、4か月前までタイに行ってハッカソンするなど夢にも思いませんでした。
このハッカソン参加もそうですが、42に属することでこの先も予測不可能な面白い出来事が次々と待ち受けているはずです。
改めて、英語面で完全にカバーしてくれたチームメイトには心から感謝しています。私一人では絶対に成し遂げられなかった結果です。
我々が優勝したので2026年の42 Asia Hackathonは東京開催です。
42Tokyo生はもちろん、42に興味がある方も今のうちにPiscineを突破しておくと参加できるかもしれません。
英語が話せなくても、タブレットPCでも、チームの多様性で勝てる。