はじめに
GANs:敵対的生成ネットワークは本物の画像を学習することで、偽物の画像を生成する技術です。日々新しい技術が生み出されており、計算資源に糸目をつけなければ偽物とわからない画像を生成することができるようになっています。
今回はつい最近(2020/3/25)発表された単一画像のみで学習を行うSingle GANから派生したConcurrent Single GAN(略称Con SinGAN)の論文要約を行いました。実装については次回まとめたいと思います。
著者はドイツの大学で研究者をされている方のようです。
Improved Techniques for Training Single-Image GANs
https://arxiv.org/abs/2003.11512
https://github.com/tohinz/ConSinGAN
本論文の要約
- 生成する画像について、多様性(いろいろな種類が生まれる)と適合性(教師画像に似ていること)はトレードオフの関係
- 本技術は、中間ステージで画像を生成するわけではなく、次のステージ(stage)へ続ける際に画像の特徴を広げる
- 以前の技術(SinGAN)よりも少ない訓練で実行できる方法を開発した
- 事前に訓練されたモデルを元にした、最適訓練(fine-tuning phase)を紹介する
アルゴリズムについて
多段階訓練
このアルゴリズムの特徴は、どの繰り返し訓練ステージであっても最初はノイズ画像のみから始めるところです。さらに、SinGANでは常にその計算する繰り返し訓練ステージにおいて、訓練を行います。また、前の繰り返し訓練ステージにおけるパラメータは固定になります。
著者らはすべての繰り返し訓練ステージで過学習させることで、生成器が多様性なしに元の画像を生成させることができることを見出しました。
この過学習は通常、モデルの損失関数における学習率を低下させることによって防ぎます。代わりに、著者らは低い繰り返し訓練ステージにおいて低い学習率を使っている間で同時(Concurrent)に多くの繰り返し訓練ステージを訓練させることを提案しました。
ConSinGANの訓練アルゴリズムを下記に示します。
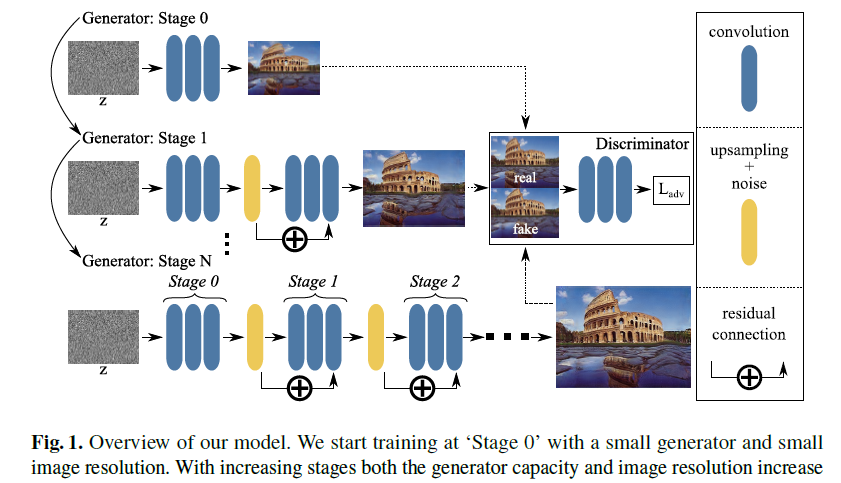
ConSinGANは荒いノイズ画像を入力させて学習を開始します(SinGANと同じ)。一度畳み込み層を経ると、次の繰り返し訓練ステージへ続きます。SinGANでは、ここで前の訓練ステージと区別します。しかし、ConSinGANでは前の訓練ステージも引き続き用いて計算を行います。
また、SinGANと同じように多様性をもたせるために各ステージごとにノイズを追加しています。
(私感)前のステージのニューラルネットワークも使用して計算するとのことで、訓練時間は必然的に長くなるように思いましたが、実際のところSinGANよりも計算時間は早いです。250ピクセル×141ピクセル画像の訓練をSinGANでは20~30分程度かかりましたが、同様の時間で600ピクセル×400ピクセルの画像の訓練を終えることができました(Google ColabのGPU使用)。素敵ですね。
(用語:繰り返し訓練ステージ(stage)は、畳み込みニューラルネットによってノイズ画像から偽物画像を生成する一連の段階を示します。)
損失関数
損失関数はSinGANと同じ考え方を適用しています。
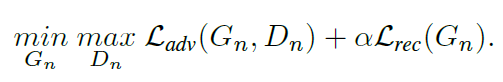
左の項$L_{adv}$はいわゆるGANで使用されるGenerator(生成器)とDiscriminator(識別器)の性能を上げさせるAdversarial(敵対的)項です。生成器は本物と見分けがつかないようなものを作らせるために、その見分けが難しくなる方向(=損失関数の値を最小化)させ、識別器は本物と見分けがつく方向にいかせます(=損失関数の最大化)。
右の項$L_{rec}$は、入力した画像を再構築できるようにするための損失です。一意に画像を作っていくのではなく、ノイズを入れることで多様性ある画像を作るためです。係数の$\alpha$を調整することでモデル訓練の安定性を確保します。今回は$\alpha=10$が経験上最も安定する値であったとのことです。
計算条件について
- Iterationsは2000(SinGANと同じ)
- 最適化手法は ADAM
- Batch Normalization(ミニバッチごとに平均が0で分散が1となるように正規化)はなし
⇒収束に影響を与えずに訓練速度の時間を速くすることが可能 - 活性化関数はLeakyReLUを用いた
- NVIDEA GeForce GTX 1080Tiにて訓練時間は20~30分(SinGANは120~140分)
結果
無制限に画像を生成する(Unconditional Image Generation)
無作為に生成するベクトルから画像を生成します。著者らのアルゴリズムでは全て畳み込みで行うため、初期条件を変えることで幅広い画像を生成させることが可能になります。それを示す図が下記です。

現実的に見えるような全体的な特徴を捉えた画像を生成することができました。ストーンヘッジの例(画像の2列目)をみると、画像の幅が増えたときに岩も増やすことができました。幅や高さに応じた適切な像を追加することができています。
ConSinGANとSinGANを比較した図を下記に示します。

SinGANは像の顔がはっきり見えにくいものが生成されています。しかし、ConSinGANではより顔がはっきり分かるように生成されています。これは、モデルの多段階訓練による効果により全体的な構造を捉えることができた効果です。
(私感)先の多段階訓練のアルゴリズムが、全体的な構造を捉えることに繋がる理屈が小職自身理解不足で出来ていません。。
画像の調和(Image Harmonization)
次に、画像の調和機能について例を示します。

訓練ステージは3つ。ステージごとに1000回計算を行っており、新しい訓練画像を得るためにオーギュメント技術(画像を回転等させて訓練画像を増やす技術)を行っています。
ConSinGANモデルでこの調和訓練を行うと、250ピクセルであれば10分以内で終えることができます。さらにファインチューニングであれば数分でモデルの修正を行うことができます。対照的に、SinGANモデルは120分かかりました。
また、たった3ステージでSinGANと同等の画像を作ることができました。
結論

上記画像はこのモデルにおける失敗したケースです。元々の訓練画像から学ぶべき多くの特徴がまだまだあることが分かります。これら訓練画像な全体的な配置を(global)モデルへ反映させることはできないものの、代わりに個々の部分に着目してつなげることはできます。
訓練モデルを用いて画像が示す多様性を我々自身が決めることができます。
おわりに(所感)
今回、ConSinGANというSinGANの改良したモデルの紹介を行いました。
結論の項で現実的ではないエッフェル塔の画像が載せられていました。これは一つの画像から多様性ある偽の画像を作る難しさを示したものだと思います。
アルゴリズム内の議論がまだまだできないところが多くあるため、GANの経緯についてもっと学ぶ必要があることを再認識しました。
GANについてはkoshian2さんのこちらの本で学んでおります。畳み込みニューラルネットの考えや実装から丁寧に解説されており非常にわかりやすいです。
Inpaintingからディープラーニング、最新のGAN事情について学べる本を書いた
https://qiita.com/koshian2/items/aefbe4b26a7a235b5a5e