今取り掛かっているCTR予測にとって役に立ちそうな論文「Practical Lessons from Predicting Clicks on Ads at Facebook」があったので、重要かと思った点をメモ書きしました。
時間なかったので、私の直近の仕事に関係ありそうな点を雑に書いています。
知らなかったことが多く、勉強になりました。
ABSTRACT
モデル種類
In this paper we introduce a model which combines decision trees with logistic regression, outperforming either of these methods on its own by over 3%
決定木とロジスティック回帰の組み合わせで他手法より優れた結果を出した。
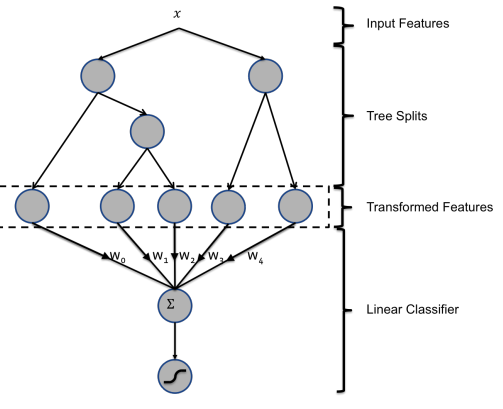
最重要ポイント
the most important thing is to have the right features: those capturing historical information about the user or ad dominate other types of features.
最も重要だったのは正しい特徴量を使ったこと。ユーザと広告の履歴に関する特徴量。
改善ポイント
Picking the optimal handling for data freshness, learning rate schema and data sampling improve the model slightly, though much less than adding a high-value feature, or picking the right model to begin with.
正しい特徴量・モデル種類以外に以下の事項も改善に一定程度寄与。
- データの新鮮さ
- 学習率のschema(schemaは学習率の調整方法)
- データサンプリング
1. INTRODUCTION
「ABSTRACT」と同じこと書かれていたけど割愛。
目的
The goal of this paper is to share insights derived from experiments performed with these requirements in mind and executed against real world data.
この論文の目的は実世界のデータに対する取り組みに対する洞察を共有すること
対象
In order tackle a very large number of candidate ads per request, where a request for ads is triggered whenever a user visits Facebook, we would first build a cascade of classifiers of increasing computational cost. In this paper we focus on the last stage click prediction model of a cascade classifier, that is the model that produces predictions for the final set of candidate ads.
大量の広告候補に対応するために複数の分類器を直列でつなげている。この論文では最終段階での予測モデルについて言及。
章のアウトライン
2章
We begin with an overview of our experimental setup in Section 2.
2章では実験的なセットアップについて。
3章
In Section 3 we evaluate different probabilistic linear classifiers and diverse online learning algorithms. In the context of linear classification we go on to evaluate the impact of feature transforms and data freshness. Inspired by the practical lessons learned, particularly around data freshness and online learning, we present a model architecture that incorporates an online learning layer, whilst producing fairly compact models.
3章では、異なる確率的線形分類器とオンライン学習アルゴリズムについて評価。線形分類器では、特徴量変換とデータ鮮度の評価。データ鮮度とオンライン学習に関してコンパクトなモデルを生成しながら、オンライン学習層を組み込んだモデルアーキテクチャを提示します。
4章
Section 4 describes a key component required for the online learning layer, the online joiner, an experimental piece of infrastructure that can generate a live stream of real-time training data.
4章ではオンライン学習層に必要なonline joiner(リアルタイムストリームデータを生成するインフラ)について。
5, 6章
Lastly we present ways to trade accuracy for memory and compute time and to cope with massive amounts of training data.
最後に正確性と大量の訓練データに対応するメモリ・処理時間について。
In Section 5 we describe practical ways to keep memory and latency contained for massive scale applications and in Section 6 we delve into the tradeoff between training data volume and accuracy.
5章で大規模スケールできるアプリケーションのためのメモリとレイテンシーを保つ実践的な方法。6章ではデータボリュームと正確性のトレードオフにてうい。
2. EXPERIMENTAL SETUP
- 実験用のセットアップとして、(ストリーミングではなく)オフラインデータを使って訓練・評価。
- 関心は機械学習モデルに与える影響にあったため、(利益や売上でなく)予測精度を評価指標に設定。Normalized Entropy(正規化エントロピー)とcalibrationを主な評価指標に設定。
Normalized Entropy(正規化エントロピー)
Normalized Entropyは他記事でも説明少ししましたが、以下の計算式。
※論文内は$y_i \in \{-1, +1\}$で、ラベルが0/1でないので、計算式が微妙に違う。
{\frac{LogLoss}{- (p * log (p) + (1-p) * log (1-p) )}
= \frac{- \frac{1}{N} \sum_{i=1}^{N} y_i log (p_i) + (1 - y_i) log (1 - p_i)}{- (p * log (p) + (1-p) * log (1-p) )}
}
Calibration
予測平均CTRと実際のCTRとの割合。計算式は以下。1だと最高精度で、1から遠くなるほど悪化。
\frac{TP + FP}{TP + FN} = \frac{予測クリック数}{実クリック数}
We only report calibration in the experiments where it is non-trivial.
重要でない場でのみCalibrationを報告。
AUC(ROC AUC)
Note that, Area-Under-ROC (AUC) is also a pretty good metric for measuring ranking quality without considering calibration. In a realistic environment, we expect the prediction to be accurate instead of merely getting the optimal ranking order to avoid potential under-delivery or over-delivery. NE measures the goodness of predictions and implicitly reflects calibration. For example, if a model overpredicts by 2x and we apply a global multiplier 0.5 to fix the calibration, the corresponding NE will be also improved even though AUC remains the same.
Calibrationを考慮しないが、ランキングの品質を計測するための良い指標。
※現実的には、最適なランキングの代わりに正確な予測を期待します。Normalized Entoropyは暗黙的なCalibrationを反映させるのに非常に良い指標。
3. PREDICTION MODEL STRUCTURE
3.1 Decision tree feature transforms
There are two simple ways to transform the input features of a linear classifier in order to improve its accuracy.
2種類の線形分類器に対するシンプルな特徴量変換方法があり。
For continuous features, a simple trick for learning non-linear transformations is to bin the feature and treat the bin index as a categorical feature. The linear classifier effectively learns a piece-wise constant non-linear map for the feature. It is important to learn useful bin boundaries, and there are many information maximizing ways to do this.
Continuous featureに対しては、非線形変換学習のシンプルな方法としてビニングがある。
The second simple but effective transformation consists in building tuple input features. For categorical features, the brute force approach consists in taking the Cartesian product, i.e. in creating a new categorical feature that takes as values all possible values of the original features. Not all combinations are useful, and those that are not can be pruned out. If the input features are continuous, one can do joint binning, using for example a k-d tree.
2つ目のシンプルだが有効な変換はタプル形式への特徴量変換。カテゴリカル特徴量に対してデカルト積での力まかせ探索を実施。ただ、すべての組み合わせは有用でない。もし、特徴量がcontinuousの場合は、k-d treeなどを使ったjoint binningが可能。
※joint binningは複数特徴量を1特徴量にbinnig?
参考: k-d tree
We found that boosted decision trees are a powerful and very convenient way to implement non-linear and tuple transformations of the kind we just described. We treat each individual tree as a categorical feature that takes as value the index of the leaf an instance ends up falling in.
上記2つの特徴量変換を決定木を使って実装。個々の木をカテゴリカル特徴量を決定するために使用。
以降は、私の当座の調査目的からずれるので省略。
3.2 Data freshness
訓練データが古いと精度悪化。
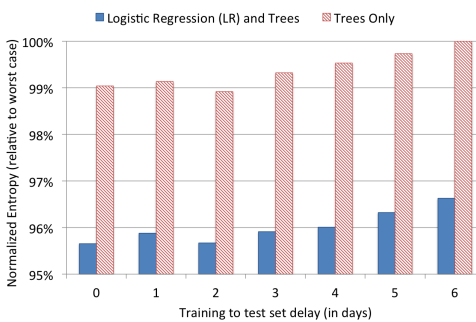
3.3 Online linear classifier
LRとBOPRの比較。
Learning Rate Schemaの比較も。
4. ONLINE DATA JOINER
Onlineでどう学習していくか。あまり見ていない。
5. CONTAINING MEMORY AND LATENCY
5.1 Number of boosting trees
木の数を1から2000まで変化。リーフは12より多くならないように制限。
submodel2 は訓練データ数が少なく、木を増やしたときに過学習を起こしている。
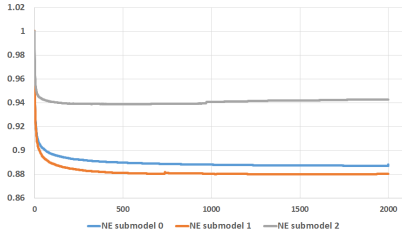
5.2 Boosting feature importance
In order to measure the importance of a feature we use the statistic Boosting Feature Importance, which aims to capture the cumulative loss reduction attributable to a feature.
特徴量の重要度を測るために、特徴に起因する累積損失削減量を把握することを目的とした統計量Boosting Feature Importanceを使用(Boosting Feature Importanceを初めて聞いた)。
Since a feature can be used in multiple trees, the Boosting Feature Importance for each feature is determined by summing the total reduction for a specific feature across all trees.
1つの特徴量が複数のツリーで使われるのでBoosting Feature Importanceは、全ての木で特定の特徴量に対する損失削減量の合計で計算。
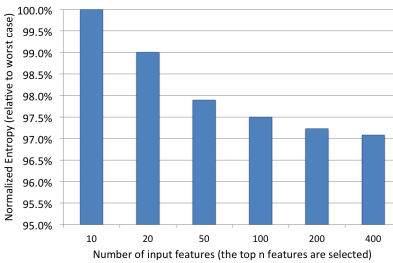
少しの特徴量が大きなポーションを占めている。
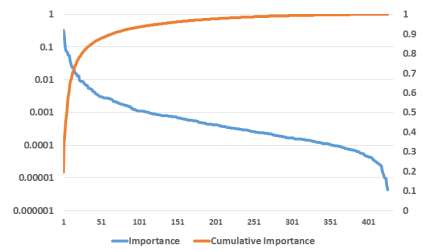
100くらいに特徴量絞ってもいいのでは?と思ったけど、特徴量増やせばNE下がっている
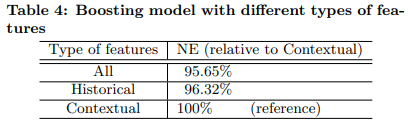
5.3 Historical features
特徴量は以下の2種類。
| 種類 | 内容 | 例 |
|---|---|---|
| Contextual | 現在の情報 | 時刻、デバイス、アクセスしているページ |
| Historical | 過去の情報 | 累積クリック数、先週CTR |
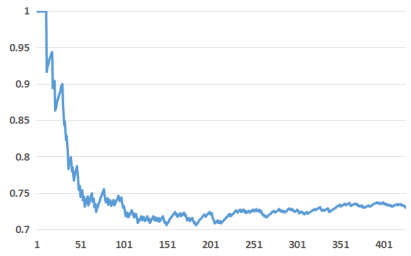
X軸にtop-k特徴量数で、Y軸がそのうちのhistorical featureの割合。明らかにhistorical featureの割合がcontextualより大きい。
特徴量を限定したときのNE比較。
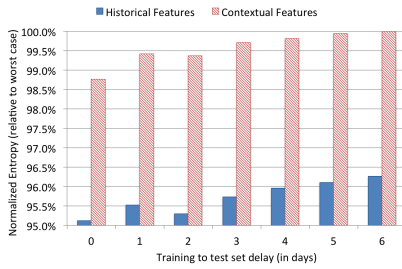
それぞれの特徴量で訓練した場合の訓練データの鮮度とNE。Historicalの方が鮮度の影響を受ける。
6. COPING WITH MASSIVE TRAINING DATA
6.1 Uniform subsampling
一様サブサンプリングとCalibration, NEの比較。10%以上であればCalibration, NEともに大きくは違わない。
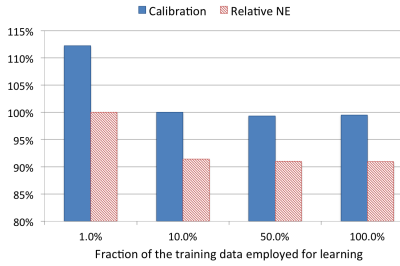
6.2 Negative down sampling
Negative down sampling時の精度推移。Rateが0.025時にNEは最高精度。
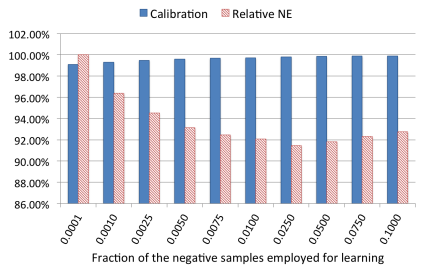
6.3 Model Re-Calibration
Negative down samplingしたらCalibrationしよう。
7. DISCUSSION
- データ鮮度は重要なので最低でも日次で再訓練しよう
- 決定木で特徴量変換して確率的線形分類器で予測するモデルが精度を向上させた
- ロジスティック回帰とper-cordinate 学習率が最良だった
- 決定木の木の数を小さくすることが計算量とメモリを抑えることに役立った
- Boosted decision treeがFeature importanceによる特徴量選択に役立った
- Context featureよりHistorical Featureの方が役に立った